以前的BLIP学习笔记
BLIP的主要贡献可以总结为:1.多模态混合架构(MED)实现了理解与生成任务的统一处理,提高了模型的通用性和灵活性2.CapFilt数据增强机制有效解决了网络数据噪声问题,提升了训练数据的质量和数量3.BLIP在多种视觉-语言任务中取得的卓越性能,可以用于后续模型训练数据的生成。
BLIP模型由Salesforce研究团队于2022年提出,旨在解决传统视觉语言预训练(Vision-Language Pre-training, VLP)框架中存在的两个关键问题:
- 一是现有模型大多只能在理解或生成任务中单一表现优秀
- 二是使用网络收集的嘈杂图像-文本对扩展数据集时带来的噪声问题
在BLIP之前,多数模型要么专注于视觉语言理解任务,要么侧重于生成任务,难以同时处理这两类任务。BLIP通过创新的架构设计和预训练方法,成功实现了理解与生成能力的统一,为多模态学习开辟了新的研究方向。BLIP模型在图像-文本检索、视觉问答(VQA)、图像描述生成等任务中均取得了当时最先进的SOTA。
架构设计
BLIP采用了一种创新的多模态混合架构(Multimodal mixture of Encoder-Decoder, MED),这种架构设计使模型能够灵活应对不同类型的视觉-语言任务。我们来看下图:
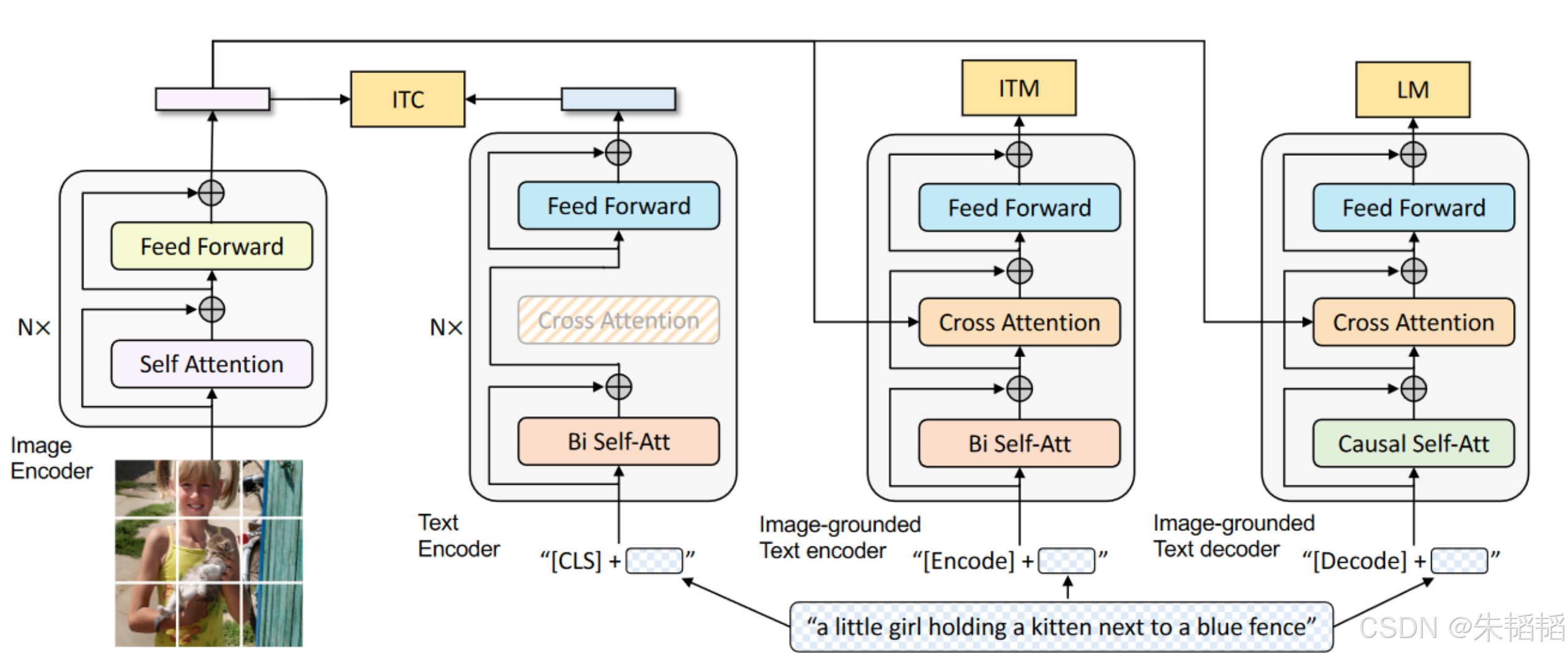
可以看到有:两个单模态编码器、一个融入图像信息的文本编码器以及一个融入图像信息的文本解码器。
图像编码器负责提取输入图像的特征表示,通常采用预训练的视觉Transformer(ViT)模型。该模型将图像分割成一系列固定大小的图像块(patches),并通过多层Transformer结构捕捉图像的全局和局部特征。
文本编码器则负责处理输入的文本信息,通常基于BERT等预训练语言模型实现。通过自注意力机制,文本编码器能够捕捉文本中的语义关系和上下文信息,生成丰富的文本表示。
一个融入图像信息的文本编码器是实现图片理解的关键,以交叉注意力的形式实现的两者的融合。
一个融入图像信息的文本解码器则专注于生成与图像相关的文本内容,如图像描述或问题回答。类似的GPT组件采用自回归生成方式,依次预测输出序列中的每个标记,同时通过交叉注意力机制关注图像特征,确保生成的文本内容与图像语义相符。
注意,后面三个编码器的同颜色的部分是共享权重的,不要以为是独立的。不过由于生成器,即因果解码器,和编码器本质任务不同,所以没有共享权重(绿色部分)。
CapFilt数据增强机制
BLIP的一个重要创新是提出了CapFilt(Captioning and Filtering)数据增强机制,用于解决网络收集的图像-文本对数据中存在的噪声问题。大家可以随便去试试,web上爬下来的图片都caption很可能跟图片内容无关,这是有原因的,因为搜索引擎可以将潜在感兴趣的客户带到这儿来。
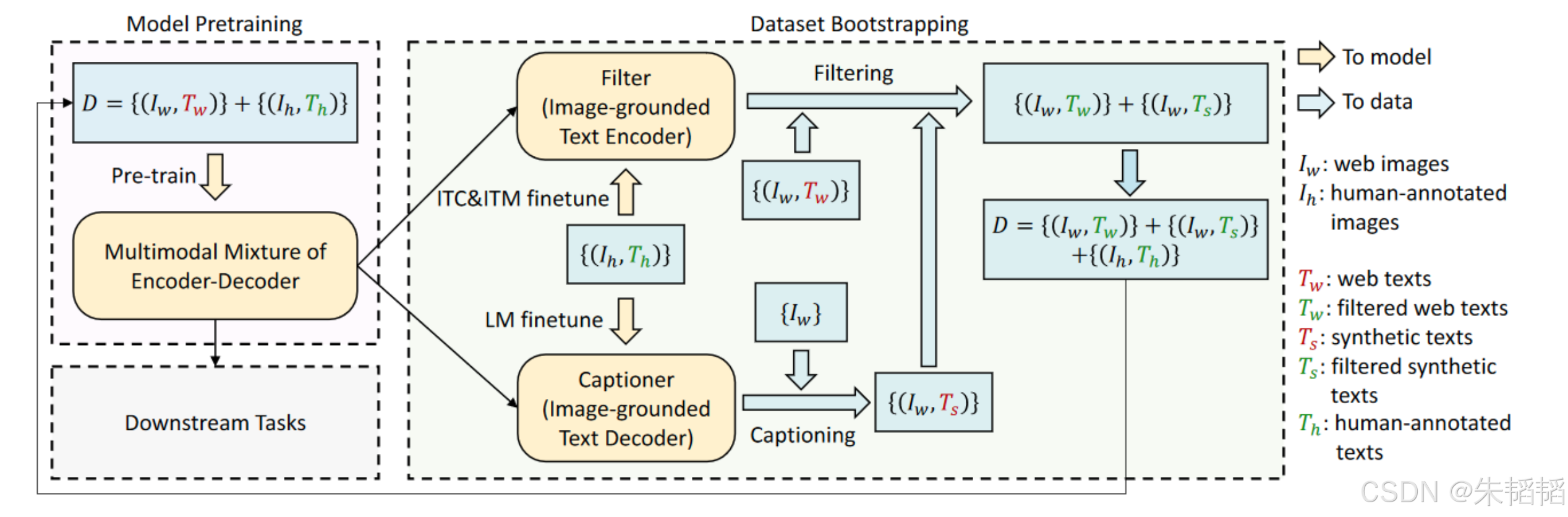
CapFilt机制包含两个主要步骤:首先,使用生成器(Captioner)为网络收集的图像生成高质量的文本描述;其次,使用文本过滤器(Filter)评估现有图像-文本对的质量,筛选出高质量的数据用于模型训练。这种"自举"(bootstrapping)方法使模型能够从原始的嘈杂数据中提取有用信息,同时通过生成新的描述来增强数据集。我们依次来看2个模块。
生成器是CapFilt的第一个关键组件,它在有人类精确标注的数据集上训练后,能够为给定图像生成准确、详细的文本描述。从上图可以看到,它是我们刚刚看到的那个融入图像信息的文本解码器。
过滤器为每个图像-文本对分配一个匹配分数(类似Clip做的事情),代表它们之间的语义相关程度。通过设定适当的阈值,系统可以筛选出高质量的图像-文本对用于后续训练,同时过滤掉那些语义不一致或噪声较大的数据。
拉通流程来看:
首先在模型预训练阶段,利用初始数据集D初步构建一个多模态编码器-解码器结构,该数据集包含来自网络的图像和文本对(I_w, T_w)以及人工标注的图像和文本对(I_h, T_h)。
接下来,在数据集引导阶段,系统利用图像-文本编码器对图像-文本对进行过滤,筛选出高质量的网络图像和文本对,并通过图像描述生成器生成合成文本(T_s),与网络图像建立对应关系。
最终,更新后的数据集D结合了经过过滤的网络图像和文本对、生成的合成文本以及人工标注的图像和文本对,形成一个更加丰富和高质量的数据集,形成良性循环。可以看到,这种流程在训练后期基本可以脱离人工标注。

论文里面的图也能看出,生成器和过滤器分别起到了什么作用。假设生成器整了一个错误的结果,过滤器也可以进行过滤。
性能表现
图像-文本检索包括两个方向:根据文本查找相关图像(Text-to-Image Retrieval)和根据图像查找相关文本(Image-to-Text Retrieval)。在COCO和Flickr30K等标准数据集上的评估结果显示,BLIP在各项指标(Recall@1, Recall@5等)上均优于之前的模型。
视觉问答(Visual Question Answering, VQA)是另一个BLIP表现出色的任务。在VQA任务中,模型需要根据给定的图像回答与图像内容相关的问题。BLIP在VQA v2等数据集上的测试结果表明,它能够准确理解复杂的视觉场景和问题语义,生成符合实际情况的回答,显著优于之前的方法。
在图像描述生成(Image Captioning)任务中,在COCO Caption等标准数据集上的评估显示,BLIP生成的描述在语法正确性、内容准确性和细节丰富度等方面均表现优异,达到了SOTA。
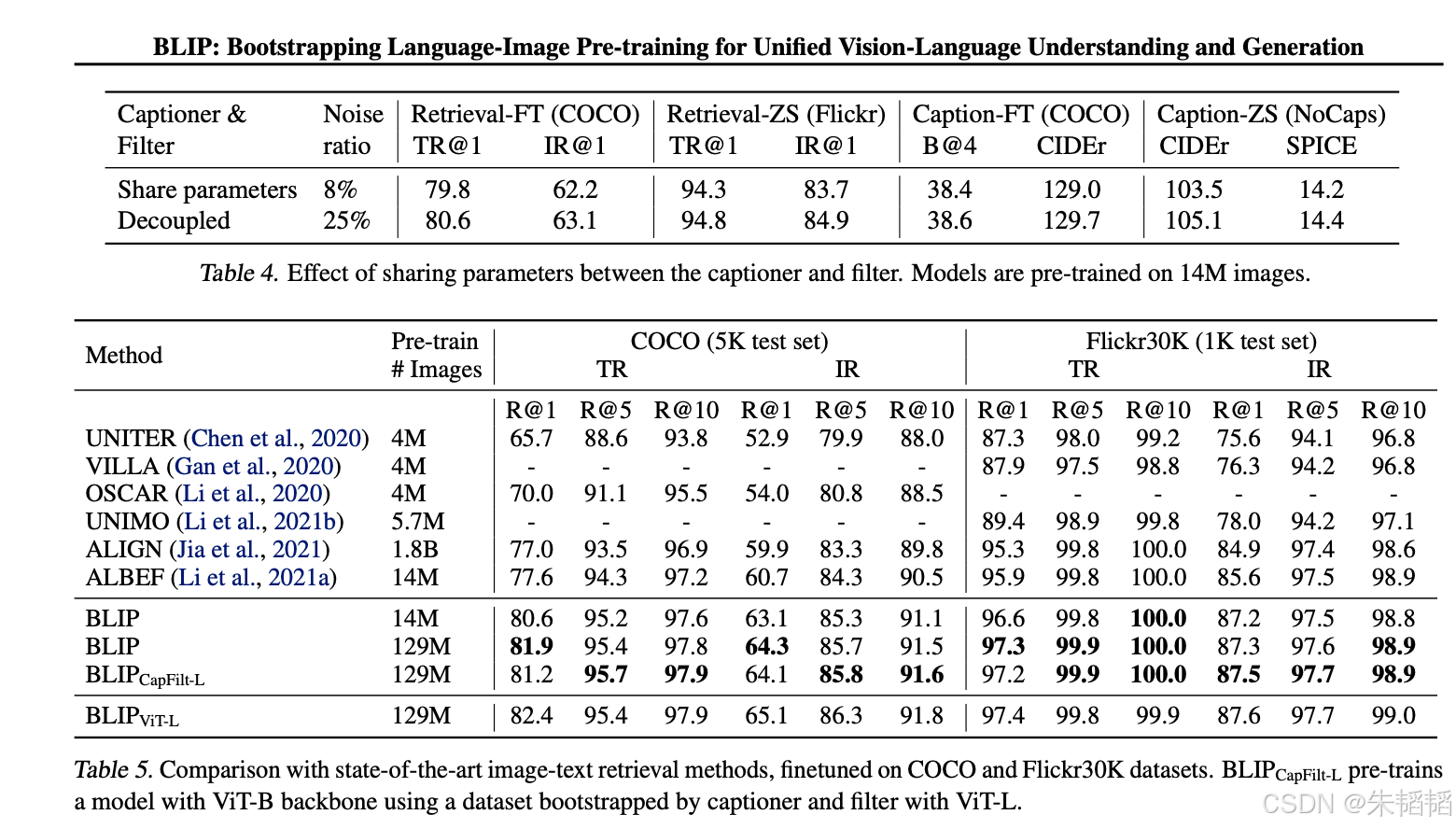
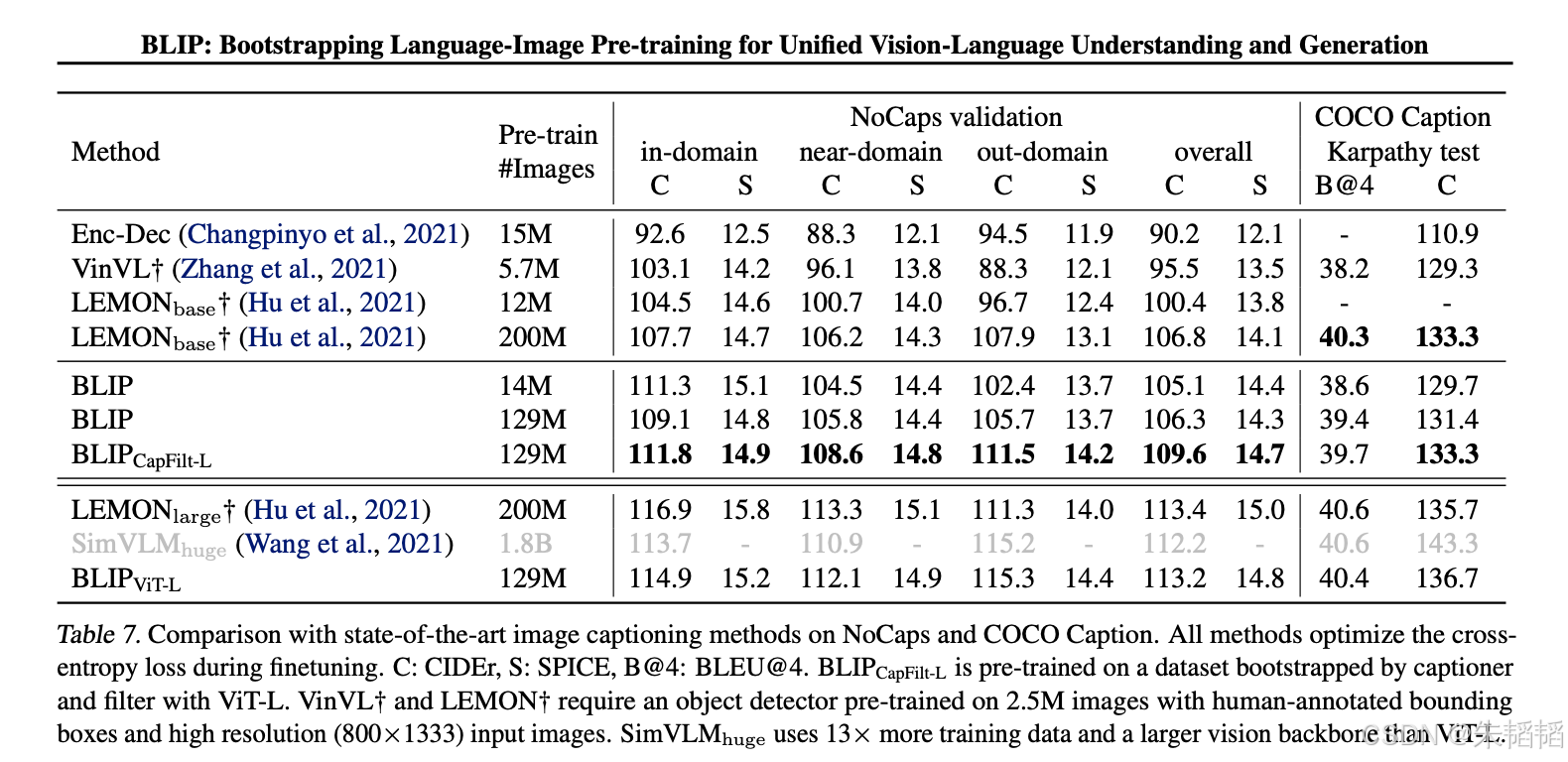
图太多了,就不截了。
总结
BLIP的主要贡献可以总结为:
1.多模态混合架构(MED)实现了理解与生成任务的统一处理,提高了模型的通用性和灵活性
2.CapFilt数据增强机制有效解决了网络数据噪声问题,提升了训练数据的质量和数量
3.BLIP在多种视觉-语言任务中取得的卓越性能,可以用于后续模型训练数据的生成

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)