[顶会]RRID模型解读(附源码+论文)
这次用的数据集是market1501,这是一个清华校园的数据集,比较小,我们来看一下这个数据集。这个数据集前面的内容截取的不是很好,得往后拖拖,我们来看这个绿色衣服的。首先前面的00000202代表ta的行人ID,一共有1500个ID。后面的0001-0006都是摄像头的编号,一共有6个摄像头。接着摄像头后的编号为当前摄像头下的图像编号。比如00000202_0004_00000003.jpg表示
[顶会]RRID模型解读(附源码+论文)
论文链接:Relation Network for Person Re-identification
官方链接:RRID
总体流程
之前做行人重识别的算法,基本都是通过对图片的整个输入进行特征提取,即利用全局信息。这篇论文的算法则考虑了局部的信息。比如一个人,通常情况下上面是头,下面是脚,中间是身子,很少有人倒立走吧。作者灵机一动,如果将这些信息截出来,做局部的信息提取,然后再将局部的信息融入到全局信息,妙哉。
如下图,一张行人照片传入,经过resnet之后给切成了6份,为啥是6份呢?因为经过实验对比,切成2份、4份、6份,发现6份就是最好的。那么如何切分呢?这个办法很多,比如(1)直接平均切6份(2)用物体检测先检测出图片哪块是头哪块是腿,然后动态的切分(3)先做个姿态识别检测出关节点的位置,然后基于关节点的位置进行切分。方法很多,看你的想象了。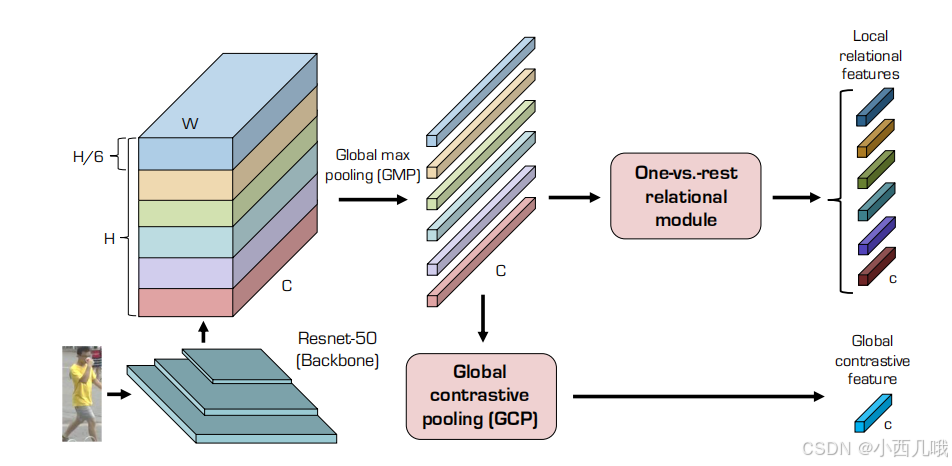
现在切好了如何将信息融合呢?对每份数据进行一个maxpool([C,1/6H,W]->[C,1,1]),然后分了两步走,往下是提取全局信息,往右是提取每块局部特征与全局的关系。
GCP:具体流程如下图。先对这六组数据进行一个全局和局部maxpool,然后进行avgpool。全局maxpool是直接提取了整个图片,因此获得的是全局最核心的信息,局部maxpool分别对6份数据maxpool,提取了局部的核心信息。avgpool=局部maxpool-全局maxpool。为啥要这么做呢?我自己的理解哈,全局maxpool捕捉整张图片的最重要信息,但忽视了细节。局部maxpool强化局部特征,但忽略整体语义关系。avgpool可以理解为局部信息去除了全局最突出的部分,即让局部信息更具有辨别性,而不是被全局最强特征所主导。论文表示这样做,可以在一定程度上去除噪音的干扰(你们可以试试在自己的任务上效果如何)。后面就是进行一些卷积最终获得全局特征,具体在下面的代码里讲解。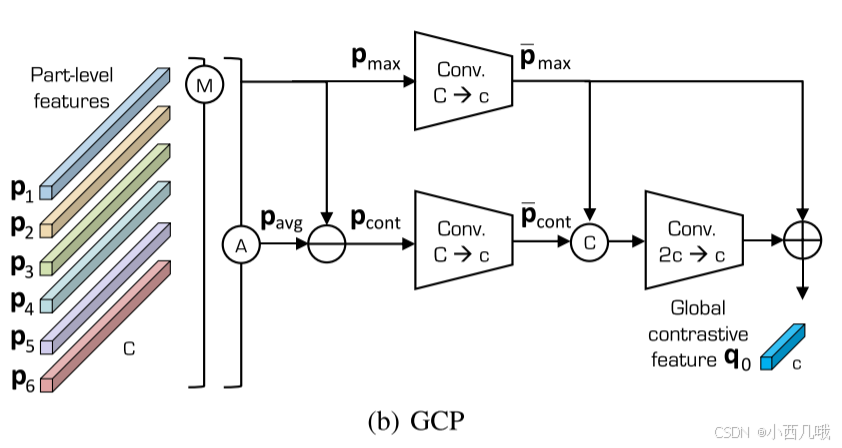
下图就是GCP的一个图片解释吧。以前的行人重识别一般用的GAP(覆盖了人体图像的整个身体部位,但它很容易受到背景杂乱和遮挡的干扰)、或者GMP(获得最具鉴别性的部分聚集特征,同时丢弃背景杂波)、或者GAP和GMP混合(可能会表现更好,但也会受到背景杂波的影响),而GCP则是两者相减(论文中证明比上述的效果都好)。
One-vs-rest relation module:具体流程如下图。这块是为了提取每块局部特征与全局的关系,看的一开始就分了两步走,一条路计算P_1,一条路计算r_1。P_1代表自己的特征,r_1代表剩余的其它特征,比如P_1如果表示p1,那么r_1就表示[p2,p3,p4,p5,p6],都是每组自己maxpool的结果然后组合在一起。以此类推,那么一共有6种组合,每组的含义可以理解为我与其它局部特征的关系。后面也是进行一些卷积,具体在代码里说了。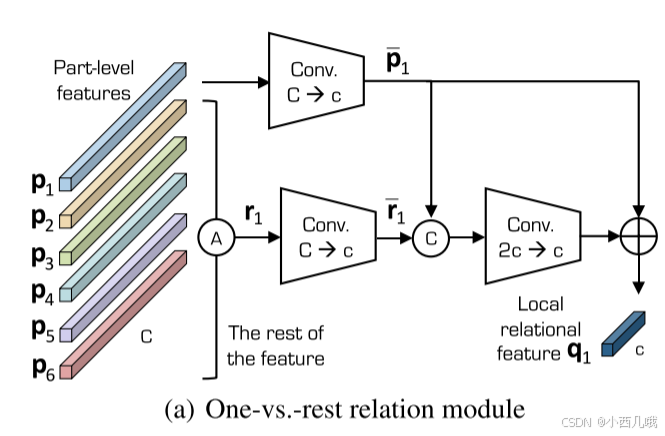
代码
数据集介绍
这次用的数据集是market1501,这是一个清华校园的数据集,比较小,我们来看一下这个数据集。这个数据集前面的内容截取的不是很好,得往后拖拖,我们来看这个绿色衣服的。

首先前面的00000202代表ta的行人ID,一共有1500个ID。后面的0001-0006都是摄像头的编号,一共有6个摄像头。接着摄像头后的编号为当前摄像头下的图像编号。比如00000202_0004_00000003.jpg表示行人ID为202的在第4个摄像头下的第3张图片。
数据处理
数据通常会分批次进行处理,比如batch_size设为64,那么每批数据会随机选取64个样本。不过RRID不同,比如batch_sample设为4,那么每个batch会有16种不同的行人ID,然后从每个ID对应的数据中随机抽取4个样本。
在下面代码中,DataLoader会先执行TripletBatchSampler,再执行Preprocessor。
train_loader = DataLoader(
Preprocessor(train_set, root=dataset.images_dir,
transform=train_transformer),
sampler=TripletBatchSampler(train_set),
batch_size=batch_size, num_workers=workers, pin_memory=False)
TripletBatchSampler
先进入reid/utils/data/sampler.py看一下TripletBatchSampler的__iter__方法。
def __iter__(self):
indices = np.random.permutation(self.num_samples)
for i in indices:
# anchor sample
anchor_index = self.index_map[i]
_, pid, _ = self.data_source[anchor_index]
# positive sample
start, end = self.index_range[pid]
pos_indices = _choose_from(start, end, excluded_range=(i, i), size=self.batch_image)
for pos_index in pos_indices:
yield self.index_map[pos_index]
首先呢,我们随机选取一些索引,然后通过self.data_source得到索引对应的信息,即行人ID。根据这个ID看一下,有多少张这个行人的图像,图像的开始和结束索引为start, end。然后通过_choose_from在这个范围内随机找4张图片。
preprocessor
再进入reid/utils/data/preprocessor.py看一下Preprocessor的__getitem__方法。
def __getitem__(self, indices):
if isinstance(indices, (tuple, list)):
if not self.with_pose:
return [self._get_single_item(index) for index in indices]
else:
return [self._get_single_item_with_pose(index) for index in indices]
if not self.with_pose:
return self._get_single_item(indices)
else:
return self._get_single_item_with_pose(indices)
因为我们没有用关节点的方法切割图片,所以直接进入self._get_single_item处理图片。
def _get_single_item(self, index):
fname, pid, camid = self.dataset[index]
fpath = fname
if self.root is not None:
fpath = osp.join(self.root, fname)
img = Image.open(fpath).convert('RGB')
img = self.transform(img)
return img, fname, pid, camid
传入索引,读取对应的文件名、行人ID和摄像头ID。然后通过路径读取这个图片,顺便做个tranform数据增强。
前向传播
图片数据会先走一波resnet做个特征提取,用的就是pytorch现成的模块,这里不做多解释,直接进入核心内容。
GCP
进入Relation_final_ver_last_multi_scale_large_losses.py的forward中。forward中代码太长了,我分批次截取部分说明。
def forward(self, x): # (b,3,384,128)
criterion = nn.CrossEntropyLoss()
feat = self.base(x) # (b,2048,24,8)
assert (feat.size(2) % self.num_stripes == 0)
stripe_h_6 = int(feat.size(2) / self.num_stripes)
stripe_h_4 = int(feat.size(2) / 4)
stripe_h_2 = int(feat.size(2) / 2)
local_6_feat_list = []
local_4_feat_list = []
local_2_feat_lst = []
final_feat_list = []
logits_list = []
rest_6_feat_list = []
rest_4_feat_list = []
rest_2_feat_list = []
logits_local_rest_list = []
logits_local_list = []
logits_rest_list = []
logits_global_list = []
for i in range(self.num_stripes): # 获得p1-p6的maxpool 为后续p_avg做准备
local_6_feat = F.max_pool2d(
feat[:, :, i * stripe_h_6: (i + 1) * stripe_h_6, :], # 沿图片的高切块
(stripe_h_6, feat.size(-1))) # pool后size为(b,2048,1,1) 2048 = stripe_h_6 × w
local_6_feat_list.append(local_6_feat)
global_6_max_feat = F.max_pool2d(feat, (feat.size(2), feat.size(3))) # p_max:(b,2048,1,1) 全局特征
global_6_rest_feat = (local_6_feat_list[0] + local_6_feat_list[1] + local_6_feat_list[
2] # p_avg:(b,2048,1,1) 局部与全局差异
+ local_6_feat_list[3] + local_6_feat_list[4] + local_6_feat_list[5] - global_6_max_feat) / 5
global_6_max_feat = self.global_6_max_conv_list[0](global_6_max_feat) # (b,256,1,1) 特征维度2048->256
global_6_rest_feat = self.global_6_rest_conv_list[0](global_6_rest_feat) # (b,256,1,1) 特征维度2048->256
global_6_max_rest_feat = self.global_6_pooling_conv_list[0](
torch.cat((global_6_max_feat, global_6_rest_feat), 1)) # (b,512,1,1)->(b,256,1,1)
global_6_feat = (global_6_max_feat + global_6_max_rest_feat).squeeze(3).squeeze(2) # (b,256)
self.base就是resnet,输入数据经过resnet之后得到的特征图feat,size为(b,2048,24,8)。stripe_h_6、stripe_h_4、stripe_h_2分别是将特征图分割为6份、4份、2份的高。
第一个循环,将feat根据stripe_h_6的高度将原图进行分割,然后分别对p1-p6进行maxpool,然后依次存入local_6_feat_list列表,即局部maxpool 。global_6_max_feat是对整个feat进行maxpool,即全局maxpool 。局部maxpool -全局maxpool 得到global_6_rest_feat。
self.global_6_max_conv_list 、self.global_6_rest_conv_list 和self.global_6_pooling_conv_list 都是基本的conv->BN->relu,可以看一下代码。
self.global_6_max_conv_list.append(nn.Sequential(
nn.Conv2d(2048, local_conv_out_channels, 1),
nn.BatchNorm2d(local_conv_out_channels),
nn.ReLU(inplace=True)))
self.global_6_rest_conv_list.append(nn.Sequential(
nn.Conv2d(2048, local_conv_out_channels, 1),
nn.BatchNorm2d(local_conv_out_channels),
nn.ReLU(inplace=True)))
self.global_6_pooling_conv_list.append(nn.Sequential(
nn.Conv2d(local_conv_out_channels*2, local_conv_out_channels, 1),
nn.BatchNorm2d(local_conv_out_channels),
nn.ReLU(inplace=True)))
下面的四行代码分别对应下图的1-4。原本feat的size是(b,2048,24,8),经过maxpool后都转为(b,2048,1,1)。上面的P_max经过第一步卷积后转为(b,256,1,1),下面的P_cont经过第二步卷积后转为(b,256,1,1)。然后将这两个拼接一下得到(b,512,1,1),再经过第三步卷积后转为(b,256,1,1)。最后将结果与上面的P_max相加得到最终的q0。
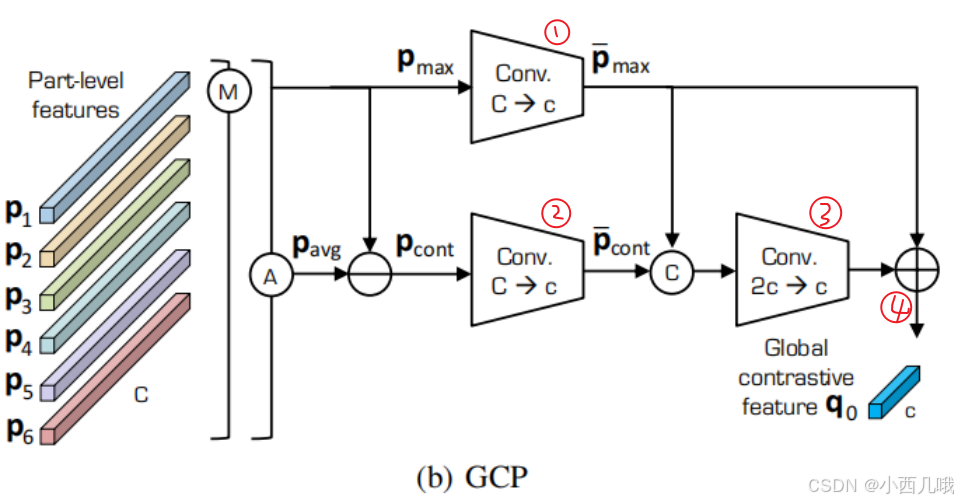
此外作者还做了切割4份和切割2份的实验,代码逻辑与上述一样,就不再展开说明。
One-vs-rest relation module
for i in range(self.num_stripes): # 除去自己,剩下的特征组合在一起
rest_6_feat_list.append((local_6_feat_list[(i + 1) % self.num_stripes]
+ local_6_feat_list[(i + 2) % self.num_stripes]
+ local_6_feat_list[(i + 3) % self.num_stripes]
+ local_6_feat_list[(i + 4) % self.num_stripes]
+ local_6_feat_list[(i + 5) % self.num_stripes]) / 5)
for i in range(self.num_stripes):
local_6_feat = self.local_6_conv_list[i](local_6_feat_list[i]).squeeze(3).squeeze(2) # P_i:(b,256) 特征维度2048->256
input_rest_6_feat = self.rest_6_conv_list[i](rest_6_feat_list[i]).squeeze(3).squeeze(2) # R_i:(b,256) 特征维度2048->256
input_local_rest_6_feat = torch.cat((local_6_feat, input_rest_6_feat), 1).unsqueeze(2).unsqueeze(3) # (b,512,1,1)
local_rest_6_feat = self.relation_6_conv_list[i](input_local_rest_6_feat) # (b,256,1,1) 特征维度512->256 方便后面做加法
local_rest_6_feat = (local_rest_6_feat # (b,256)
+ local_6_feat.unsqueeze(2).unsqueeze(3)).squeeze(3).squeeze(2)
final_feat_list.append(local_rest_6_feat)
if self.num_classes > 0:
logits_local_rest_list.append(self.fc_local_rest_6_list[i](local_rest_6_feat)) # local和rest的分类结果
logits_local_list.append(self.fc_local_6_list[i](local_6_feat)) # local的分类结果
logits_rest_list.append(self.fc_rest_6_list[i](input_rest_6_feat)) # rest的分类结果
第一个for循环是进行分组,毕竟One-vs-rest relation module是计算自己与其它5组的关系。那么rest_6_feat_list的内容就包括[p2,p3,p4,p5,p6]、[p3,p4,p5,p6,p1]、[p4,p5,p6,p1,p2]、[p5,p6,p1,p2,p3]、[p6,p1,p2,p3,p4]、[p1,p2,p3,p4,p5]。
分好组之后就开始卷积,和之前的一样,self.local_6_conv_list 、self.rest_6_conv_list 、self.relation_6_conv_list 都是conv->BN->relu。
第二个for循环是对每个分组进行卷积。下面的五行代码分别对应下图的1-5。举个例子,现在local是p1,rest是[p2,p3,p4,p5,p6],那么上面的p1经过第一步卷积转为(b,256,1,1),下面的[p2,p3,p4,p5,p6]经过第二步卷积转为(b,256,1,1)。第三步将其拼接起来得到(b,512,1,1),并经过第四步卷积得到(b,256,1,1),然后与上面经过卷积的p1相加得到结果q1。过程重复6次,得到最终结果。
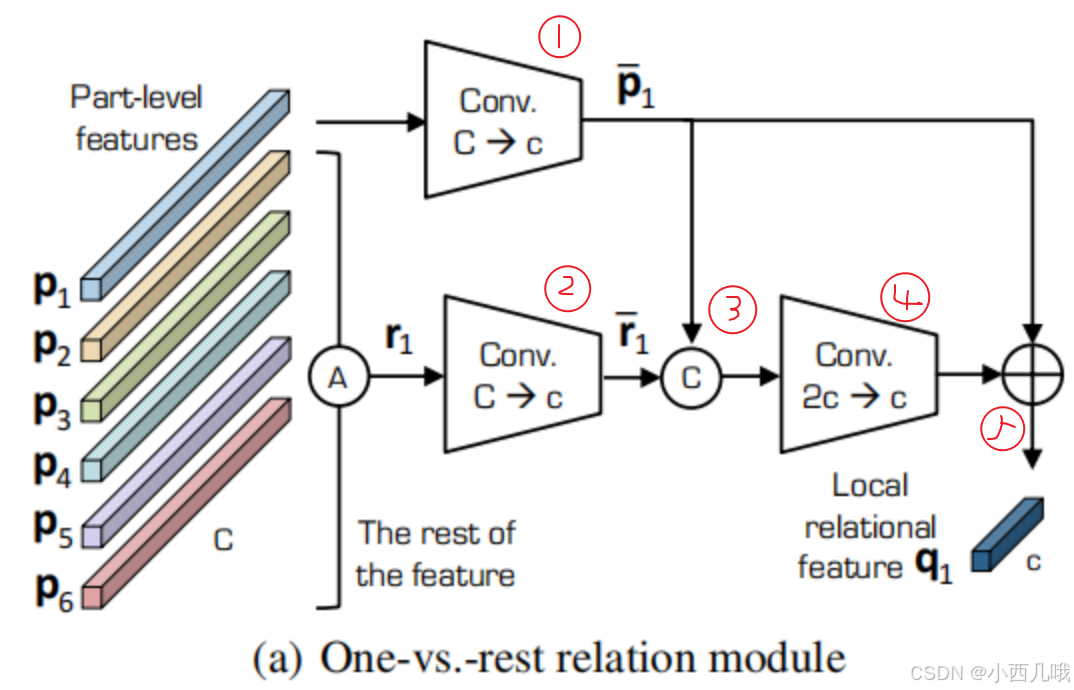
后面经过的self.fc_local_rest_6_list 、self.fc_local_6_list 、self.fc_rest_6_list 都是全连接层,输出每个分类结果的概率。这里也是个实验,分别计算了local+rest的分类结果、local的分类结果、rest的分类结果。
===================================================================================
损失函数部分就不说了,还是分类损失和三元组的损失,这在上一章里有讲过。
看看训练结果
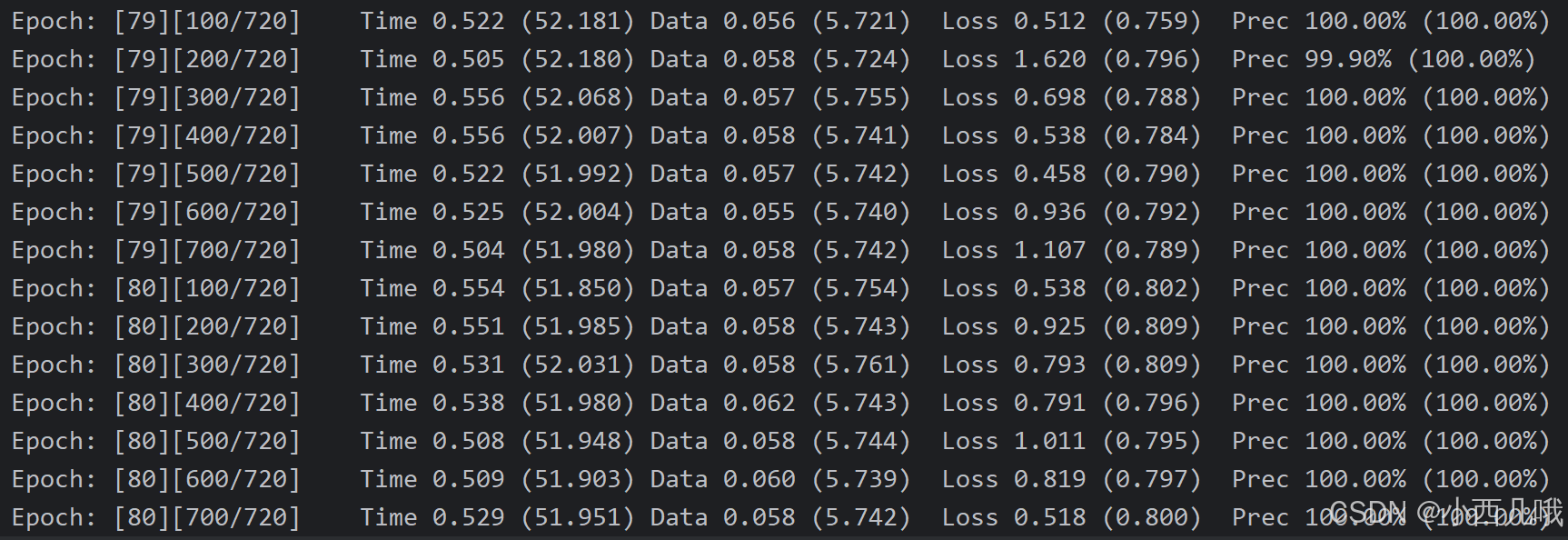
测试结果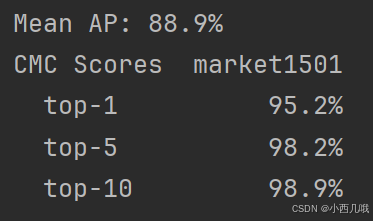

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)