机器学习Day1——机器学习简介
监督学习中提供给算法的示例(数据)要包含正确答案,即正确的标签 Y,通过不断地学习,算法学到X->Y的映射关系。在下图的例子中,给定的数据只有肿瘤大小和患者年龄,无监督学习不是要对这些数据分类,而是从数据中找到一些结构或模式,将数据分成不同的集群或组,这就是无监督学习中的聚类算法。分类问题的预测结果是数字 0,1,2,…此外,还有一些其他常用的无监督学习算法,例如:异常检测(用于检测异常事件,可用
注:本系列带领大家从零基础了解并掌握机器学习,并提供代码示例,干货满满。
1.1机器学习是什么?
机器学习(Machine Learning,ML)的应用在我们的生活中无处不在,当你在百度这一类搜索引擎中搜索怎么做西红柿炒鸡蛋,你会得到一系列的搜索结果,而这些结果的排序使用到了机器学习。当你在购物软件买过或者搜索过某些商品时,软件可能使用机器学习方法向你推荐可能喜欢的东西。当你使用手机上的语音转文字的功能时,那也用到了机器学习。此外,在工业、医疗等领域,都会用到机器学习。
机器学习是一门在没有明确编程的情况下让计算机学习的科学。我们学过的排序算法、最短路径算法等,这些有明确规则的算法,可以根据算法原理去编程实现。但是在一些复杂的领域,比如自动驾驶,我们没有办法去编程实现,所以需要让一台机器自己去学会做这些事。
机器学习的两种主要类型是监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)。强化学习(Reinforcement Learning,RL)是另一种机器学习算法。本次实践主要学习监督学习和无监督学习两类算法。
1.2 监督学习
监督学习是学习X ->Y的映射关系的算法。监督学习中提供给算法的示例(数据)要包含正确答案,即正确的标签 Y,通过不断地学习,算法学到X->Y的映射关系。在使用时算法只接受输入X,给出输出结果 Y 的合理预测。
监督学习主要分为分类(Classification)和回归(Regression)两类。
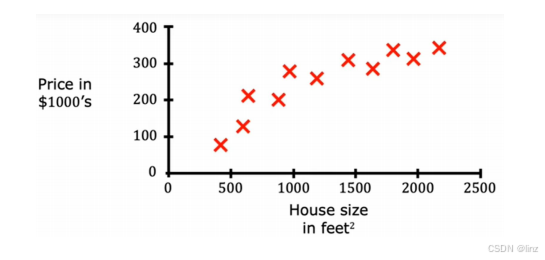
回归案例:下图是一个根据房屋面积预测房屋价格的例子,图中红色的叉是给定的样本数据,它包含房屋面积(X)和房屋价格(Y)。回归指我们试图从无数可能的数字中预测一个数字。
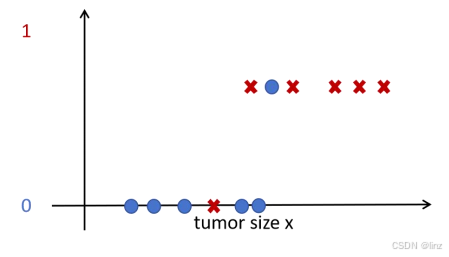
分类案例:下图是一个乳腺癌预测的例子,给定一些数据,这些数据包括肿 瘤的大小(X)和肿瘤的性质(Y,良性/恶性)。分类的输出只有有限种可能, 这个例子只有两种可能。分类问题的预测结果是数字 0,1,2,…有限个数字。
1.3 无监督学习
在无监督学习中,给定的样本数据仅有输入 X 而不包含输出标签 Y,算法必须在数据中找到一些结构或模式。
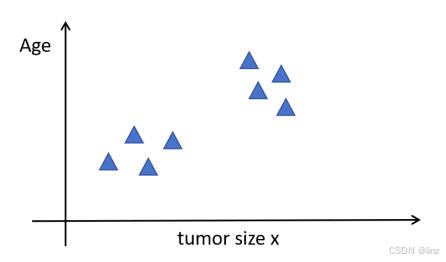
在下图的例子中,给定的数据只有肿瘤大小和患者年龄,无监督学习不是要对这些数据分类,而是从数据中找到一些结构或模式,将数据分成不同的集群或组,这就是无监督学习中的聚类算法。聚类算法将未标记的数据放入不同的集群中。
聚类算法有很多应用,比如 Google News 将每天数十万篇新闻文章的相关内容组合在一起。
此外,还有一些其他常用的无监督学习算法,例如:异常检测(用于检测异常事件,可用于金融系统中的欺诈检测),数据降维(将一个大数据集压缩成一个小得多的数据集,同时丢失尽可能少的信息)。
课后问题:
下面的例子中,哪些要用监督学习解决,哪些要用无监督学习解决?
1.判断一封电子邮件是否是垃圾邮件。
2.从网站上搜索到了一些新闻文章,将相同故事的文章分在同一组。
3.有一些客户数据,将这些客户进行分组。
4.给定一些患者信息,包含他们的诊断信息以及是否患有糖尿病,用这些数据进行学习,然后根据新患者的诊断信息判断该患者是否患有糖尿病。
欢迎大家在评论区回答!
本人目前在读本科,有机器学习相关问题欢迎添加微信与我交流vx:15735002648,或有更好的建议可以提出。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)