机器学习课堂3梯度下降法
·
一、批梯度下降法
每次迭代中都使用了训练数据集中的所有训练样本
学习率(Learning Rate)是深度学习中的一个关键超参数,它决定了模型在训练过程中权重更新的速度。学习率的大小直接影响到模型的学习进度,过大可能导致损失值爆炸或振荡,过小则可能导致过拟合或收敛速度慢。因此,合理设置学习率对于模型训练的成功至关重要。
代码计算权重w和偏差b
# 批梯度
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 参数设置
iterations = 20 # 迭代次数
learning_rate = 0.001 # 学习率
m_train = 3000 # 训练样本数量
# 读取数据集
df = pd.read_csv('temperature_dataset.csv')
data = np.array(df)
m_all = np.shape(data)[0] # 样本总数
d = np.shape(data)[1] - 1 # 输入特征的维数
m_test = m_all - m_train # 测试数据集样本数量
# 划分数据集
X_train = data[0:m_train, 1:].T # 训练数据集的输入特征矩阵,d*m
X_test = data[m_train:, 1:].T # 测试数据集的输入特征矩阵,d*m_test
Y_train = data[0:m_train, 0].reshape((1, -1)) # 训练数据集的标注向量,1*m
Y_test = data[m_train:, 0].reshape((1, -1)) # 测试数据集的标注向量,1*m_test
# 初始化
w = np.zeros((d, 1)) # 权重向量,d*1
b = 0 # 偏差(标量)
v = np.ones((1, m_train)) # 1向量,1*m
costs_saved = [] # 用来保存代价函数值
# 迭代循环
for i in range(iterations): # 更新权重与偏差
Y_hat = np.dot(w.T, X_train) + b * v # 训练样本标注的预测值
e = Y_hat - Y_train # 计算误差
b = b - 2. * learning_rate * np.dot(v, e.T) / m_train # 更新偏差
w = w - 2. * learning_rate * np.dot(X_train, e.T) / m_train # 更新权重
print(w, b)
运行结果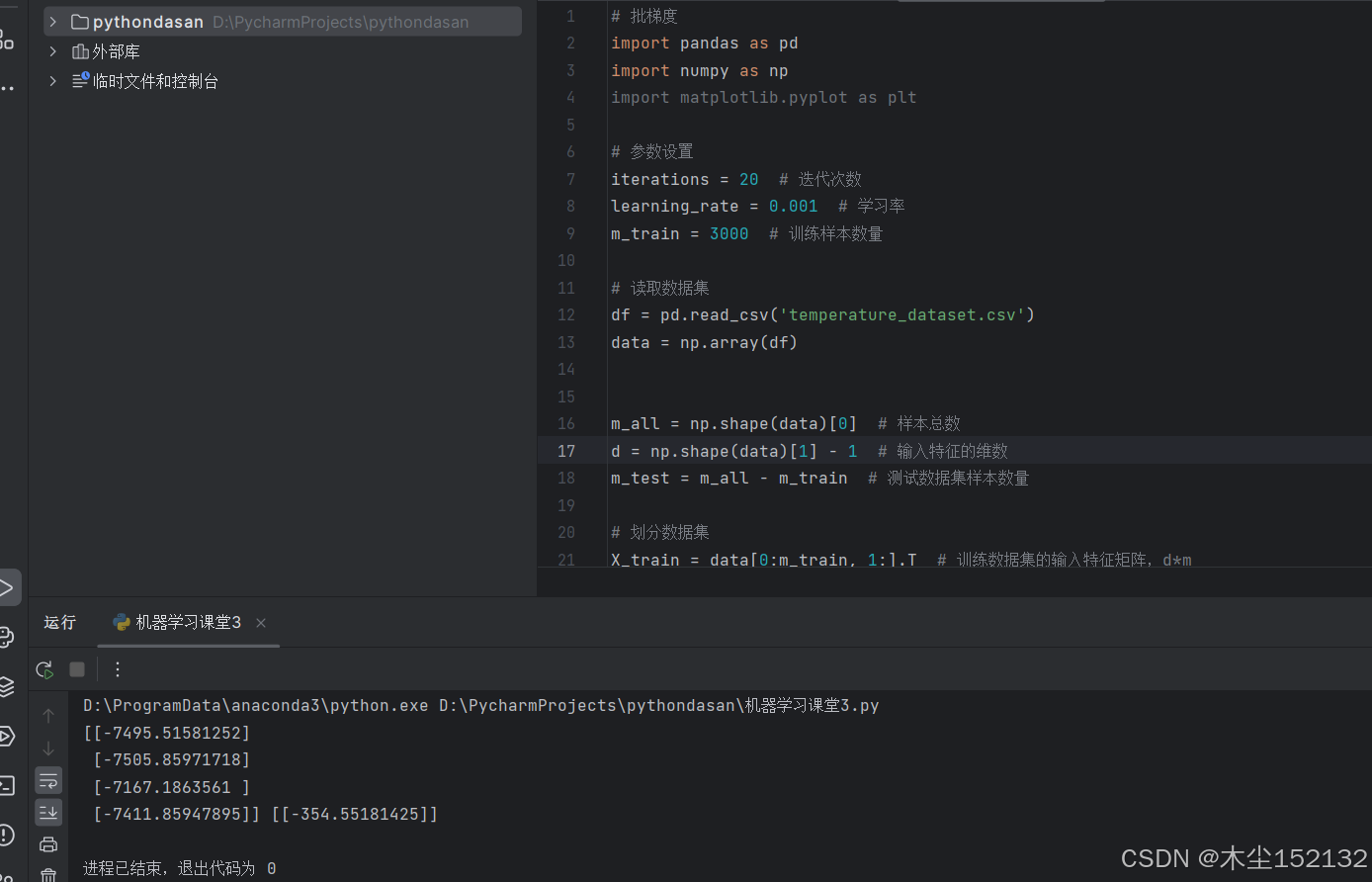
二、随机梯度下降法
每次迭代只使用一个训练样本来更新模型参数
代码计算权重w和偏差b
# 随机梯度
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 参数设置
epochs = 1 # 遍数
learning_rate = 0.0001 # 学习率
m_train = 3000 # 训练样本数量
# 构造随机种子为指定值的随机数生成器
rng = np.random.default_rng(1)
# 读取数据集
df = pd.read_csv('temperature_dataset.csv')
data = np.array(df)
m_all = np.shape(data)[0] # 样本总数
d = np.shape(data)[1] - 1 # 输入特征的维数
m_test = m_all - m_train # 测试数据集样本数量
# 划分数据集
X_train = data[0:m_train, 1:].T # 训练数据集的输入特征矩阵,d*m
X_test = data[m_train:, 1:].T # 测试数据集的输入特征矩阵,d*m_test
Y_train = data[0:m_train, 0].reshape((1, -1)) # 训练数据集的标注向量,1*m
Y_test = data[m_train:, 0].reshape((1, -1)) # 测试数据集的标注向量,1*m_test
train_set = data[0:m_train, :] # 训练数据集,用于随机排序
# 初始化
w = np.zeros((d, 1)) # 权重向量,d*1
b = 0 # 偏差(标量)
costs_saved = [] # 用来保存代价函数值
# epoch循环
for epoch in range(epochs):
rng.shuffle(train_set) # 打乱训练集
# 训练样本循环
for i in range(m_train):
X = train_set[i, 1:].reshape((-1, 1)) # 形状为 (d, 1)
Y = train_set[i, 0] # 标签值
# 更新权重与偏差
Y_hat = np.dot(w.T, X) + b # 训练样本标注的预测值,形状为 (1, 1)
e = Y_hat - Y # 计算误差,e 是标量
b = b - 2. * learning_rate * e # 更新偏差
w = w - 2. * learning_rate * e * X # 更新权重
print(w, b)
运行结果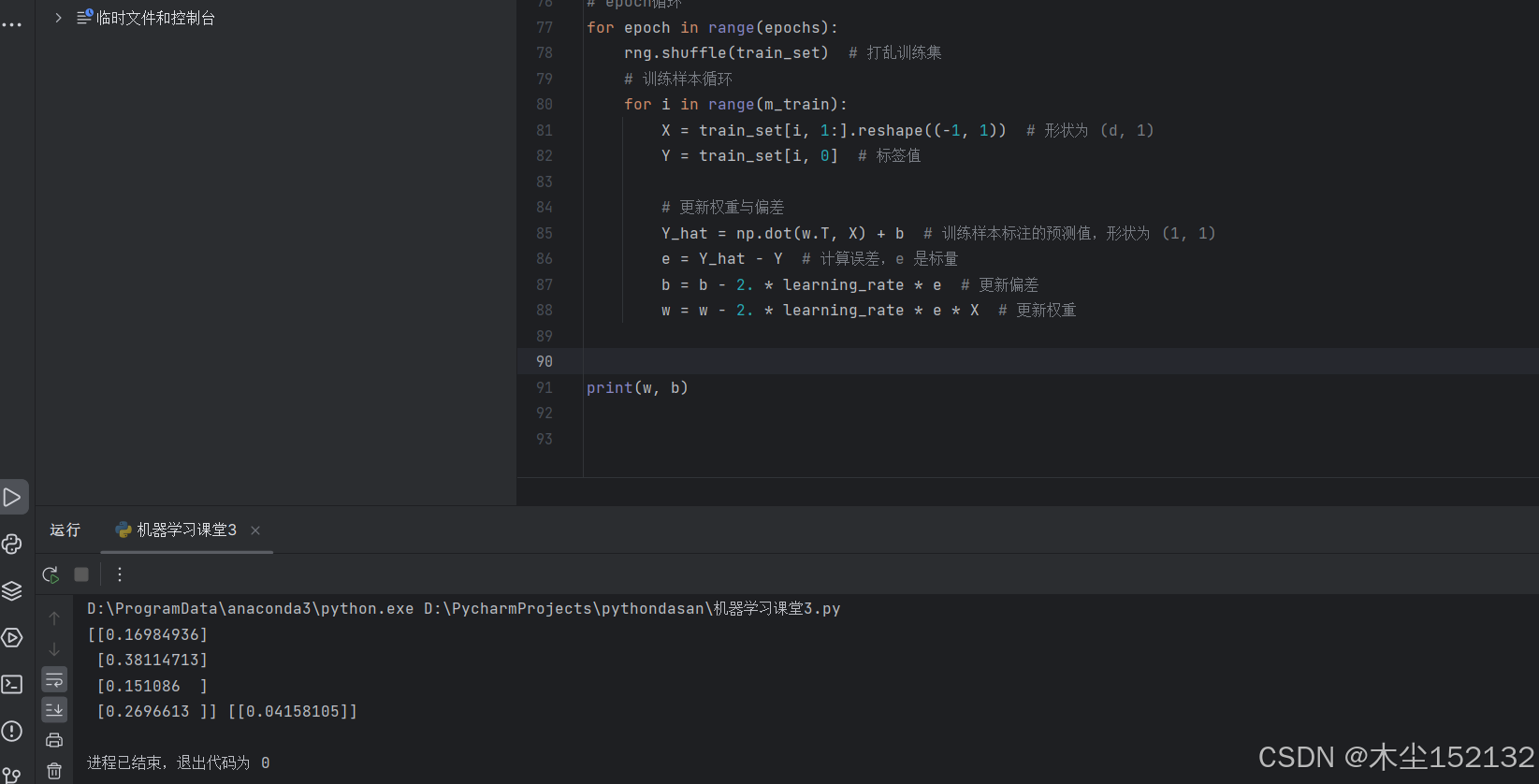
三、小批梯度下降法
批长介于1-m的梯度下降法,批长越小,单个训练样本对参数更新的影响就越大,较小的批长可能会使训练过程中的参数更新波动较大,从而延长模型参数收敛所需的时间
代码计算权重w和偏差b
# 小批梯度
import pandas
import numpy as np
import matplotlib.pyplot as plt
# 参数设置
epochs = 1 # 遍数
batch_size = 30 # 批长
learning_rate = 0.0001 # 学习率
m_train = 3000 # 训练样本的数量
# 构造随机种子为指定值的随机数生成器
rng = np.random.default_rng(1)
# 读入气温数据集
df = pandas.read_csv('temperature_dataset.csv')
data = np.array(df)
m_all = np.shape(data)[0]
d = np.shape(data)[1] - 1
m_test = m_all - m_train
# 划分数据集
X_train = data[0:m_train, 1:].T
y_train = data[0:m_train, 0].reshape((1, -1))
X_test = data[m_train:1:].T
y_test = data[m_train:, 0].reshape((1, -1))
train_set = data[0:m_train, :] # 训练数据集,用于随机排序
# 初始化
w = np.zeros((d, 1)).reshape((-1, 1))
b = 0
costs_saved = []
# epoch循环
for epoch in range(epochs):
# 对训练样本随机排序
rng.shuffle(train_set)
# 小批循环
for start_sample in range(0, m_train, batch_size):
# 准备小批
batch_sample = min([m_train - start_sample, batch_size]) # 当前小批的批长
v = np.ones((1, batch_sample)).reshape((1, -1)) # 1向量
X = train_set[start_sample: start_sample + batch_sample, 1:].T
# 当前小批中训练样本的输人特征
Y = train_set[start_sample:start_sample + batch_sample, 0].reshape((1, -1))
# 当前小批中训练样本的标注
# 更新权重与偏差
Y_hat = np.dot(w.T, X) + b * v # 训练样本标注的预测值,形状为 (1, 1)
e = Y_hat - Y # 计算误差,e 是标量
b = b - 2. * learning_rate * np.dot(v, e.T) / batch_sample # 更新偏差
w = w - 2. * learning_rate * np.dot(X, e.T) / batch_sample # 更新权重
print(w, b)
运行结果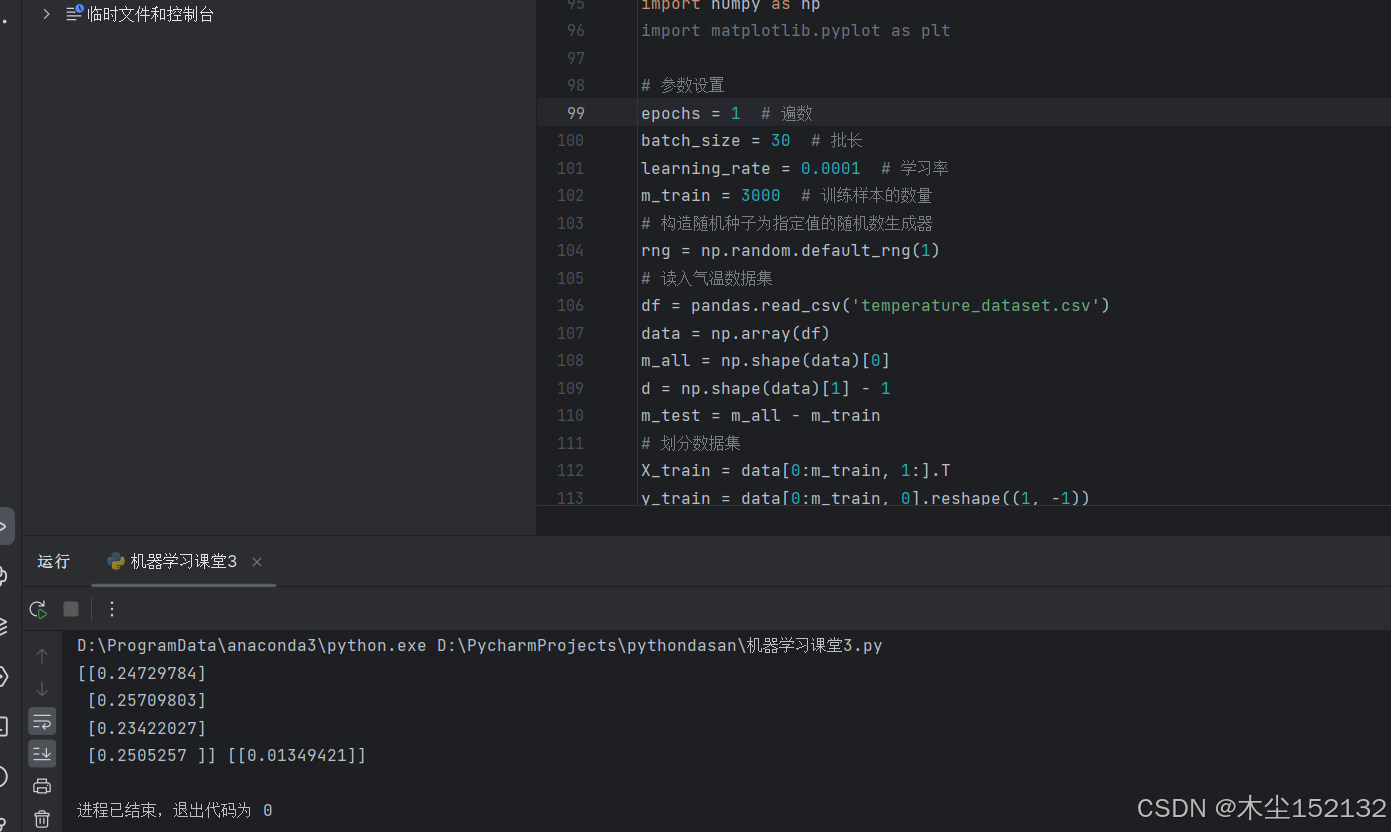

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)