基于长短时记忆网络的情感分析研究【课程设计】
本文主要介绍了文本分析和情感分析的基本理论和基础概念,回顾了文本分析的技术发展,并描述了各种技术存在的问题,最终提出了基于注意力机制的双向长短时记忆网络训练文本情感分析的算法模型,在使用基于注意力机制的双向长短时记忆网络实验的过程中,选取了IMDB数据集,该数据集包含25000条数据,每条数据都有对应的标签,符合有师学习的基本要求,可以满足模型训练的数据要求,在模型训练完成之后,模型的精确率和召回
基于长短时记忆网络的情感分析研究
今天分享最近的最后一个课程设计,明天开始分享正常的毕设。
本文主要介绍了文本分析和情感分析的基本理论和基础概念,回顾了文本分析的技术发展,并描述了各种技术存在的问题,最终提出了基于注意力机制的双向长短时记忆网络训练文本情感分析的算法模型,在使用基于注意力机制的双向长短时记忆网络实验的过程中,选取了IMDB数据集,该数据集包含25000条数据,每条数据都有对应的标签,符合有师学习的基本要求,可以满足模型训练的数据要求,在模型训练完成之后,模型的精确率和召回率分别达到了93.45%和95.34%,可以为后续的产品应用提供理论算法支撑。
关键词:情感分析;长短时记忆网络;深度学习
课程设计下载
一、前言
当前基于文本分析的情感分析有基于情感词典的分析以及基于机器学习方法的分析,基于情感词典的分析的效果随着词典构建的丰富程度会有所提升,但是人工标注词典的成本高,并且无法对快速变化的语言语境及时适应;机器学习的方法中较为流行的有RNN、CNN等技术,这些技术在情感分析中有一定作用,但是没有充分考虑上下文语境和关键词语的权重,基于注意力机制的双向LSTM模型可以解决这些问题,进一步提升文本中情感分析的效果。
本课题的研究目的是使用基于注意力机制的双向LSTM模型进行情感分析的算法训练,一是可以直接基于文本数据进行信息分类和意见归纳,基于非结构化文本数据进行分析预测,并按照一定形式展示对这些文本的分析结果,并可以应用到具体业务场景中;二是通过特定场景的文本进行实验,通过实验获取一套训练和预测具体场景下的文本分析范式和步骤,为同类场景应用提供先验模型。
二、文献综述
情感分析的概念最早由Pang等人[8]于2002年提出,针对文本情感分析,主要的研究思路有使用情感词典进行的情感分析,利用机器学习比如支持向量机等方法、还有一种是使用深度学习网络然后将其应用到文本分析中进行情感分析。
2006年,Hinton等人[8][9]以盘古开天之势提出了深度学习的方法,他因此也被誉为深度学习之父,随着词向量技术的提出以及深度学习理论的发展,近些年基于深度学习的情感分析已成为研究热点。深度学习典型的被认为是有多层隐层的神经网络,在深度学习的文本分析和情感分析中,一般是将原始文本经过预处理之后再进行模型训练,预处理的过程包括处理停用词、进行向量化等,停用词的处理,如果是英文可以采用谷歌的停用词,在停用词的选用上选用哈工大研究的成功的停用词较为普遍,此外还有其他一些企业的比如百度的停用词。在预处理完成之后,就可以基于深度神经网络进行模型训练了。常见的有基于CNN的情感分析和基于RNN的情感分析。Mikolov(2013)[10]发表了使用Word2vec模型的文本分析,该模型重复考虑了词语之间的关系,比如篮球和体育的关系较近,而墙壁和骨科就没有什么关系,通过使用这个模型,可以表达词语之间的相关性,此后,在机器学习情感分析中,几乎就离不开Word2Vec技术[11]。
综上,目前已有的针对情感分析的各种技术可以归类为三种,分别是基于情感词典的情感分析、基于机器学习情感分析和基于深度学习的情感分析,这几类方法虽然在情感分析中取的了一定成绩,但都存在一定局限,基于词典的分析耗费人工成本高,无法适应变化;基于机器学习的算法准确率达不到应用标准;基于深度学习的算法未能充分考虑上下文和关键词信息。因此,本课题提出引入注意力机制的LSTM算法模型,进一步优化算法,提升情感分析准确率。
三、LSTM模型介绍
为了解决梯度爆炸和梯度消失的问题,可以使用长短时记忆模型(Long Short Term Memory, LSTM )来解决上述问题。总体来说,LSTM模型的整体逻辑和RNN非常类似,而有些不同的地方在于,在LSTM中仅有隐藏层的一个权值h,关键的地方在于在LSTM中增加了三个门来解决上述RNN中出现的梯度消失以及梯度出现爆炸的难题。RNN在模型的隐藏层使用增加一个细胞记录状态的方式和三个门配合来进行模型训练,这三个门分别是遗忘门、输出门和输入门。通过这种技术和机制,可以使得LSTM克服RNN训练中的一些问题和困难,客户长时依赖的问题,最终使得LSTM算法在文本分析和文本情感分析中取得更好效果。这三个门可以用来解决RNN中出现的问题。如图3-4所示是三个门的图示。
其中A代表的是遗忘门、B代表的是输入门、C代表的是输出门,每一个门都有自己对应的任务和工作流程,现详述如下。
第一个门遗忘门,它的作用是决定什么信息可以最终进行留存,什么信息可以通过,遗忘门中采取的函数是sigmoid函数,由于sigmoid函数自身的特点,可以使得输出结果在0和1之间,可以通过下面的式子来处理数据。具体来说,其过程是使用当前文本的输入词的向量xt以及上一个时刻t-1时刻的隐藏状态ht-1通过变换然后通过设置的第一个门也就是遗忘门,经过对应的激活函数sigmoid的处理,其最终得到的结果是介于1和0之间的数字,使用该数字和之前的细胞状态ct-1相乘,然后得到新的数值,用这个数值去更新隐藏层的细胞状态,这个过程实际上就是对之前的状态的保留或者舍弃做的一个权衡。这个关键流程对应的数学表示如式(1)所示。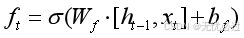
(1)
式中ht-1表示的是上一轮或者上一个时刻的权值,而x代表当前的输入或者当前时刻的输入。
第二个门是输入门,它的作用是来决定什么时候去更新,然后使用tanh做一个待选变量,加入到状态中去。对应数学式表示如(2)所示。输入门的主要作用是决定如何将某些信息注入到细胞状态中去,换句话说,就是要识别出来哪些信息是重要的是需要记忆的,哪些信息是需要遗弃的,一般来说这需要通过两个步骤的工作来完成,首先是将输入向量和隐藏的状态记录到输入门中去,接着用输入门中的sigmoid函数来确定什么信息是有用的,用哪些信息来更新。最后用一个tanh层创建一个新的候选变量,最后来更新隐藏层的细胞状态,使得细胞记录需要记忆的信息。
(2)
最后一个门是输出门中用的层,这个输出门用来进行更新ht,可以输出这个时刻的状态,首先使用sigmoid函数获取细胞状态中的输出部分,而后再使用tanh得到一个以0为中心,邻域是1的闭区间的值,用这个值和sigmoid函数相乘,然后输出对应结果,最后的结果是输出已经确定的那部分结果。输出门的数学表示式如(3)所示。
(3)
图1表示了整个模型。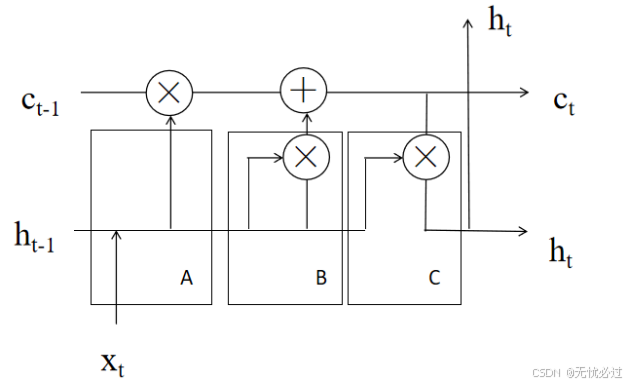
图1 LSTM模型中的三个门函数
四、实验过程以及结果
整个文本分析的流程包括如下步骤,首先获取原始数据集,原始数据集需要其中的一部分是已经标记的数据,这样就可以完成有师学习,利用标记来对模型进行训练,对于那些没有标记的数据,可以最终拿来进行模型预测;然后根据原始数据集,利用交叉验证的方式对模型进行训练,交叉验证就是把训练集和预测集可以按照一定的方式重新分布,其中一部分先用来进行模型训练,然后用这些训练集训练好的模型来在测试集上面进行验证,如果在测试集上面表现很好,而在预测集上面的训练结果不尽如人意,那说明这次的训练过程很可能陷入了过拟合的问题,解决过拟合的方法一是增加训练数据的样本量,另一个是可能的方法是提早结束,因为模型训练陷入了局部最优而不能达到全局最优,因此可以通过提早结束的方式解决过拟合的问题,还有可能出现拟合不足的问题,可以通过优化模型和增加属性的方式解决;第三步是模型训练,模型训练过程中的重要任务就是调超参,最终完成模型训练,这一步需要多次反复比较,也可以采用一些技术手段辅助,并最终取得最好的训练结果;最后,对模型进行评价,评价使用前文提到的几个指标:准确率、召回率和F1来评价;模型完成之后就可以使用模型进行预测。双向注意力机制训练的过程如图2所示。
图2 实验训练过程
试验结果表明,基于LSTM的模型在情感分析中的precision可以达到93%,recall可以达到94%,f1为0.9439。
参考文献
[1]王志涛, 於志文, 郭斌, 等. 基于词典和规则集的中文微博情感分析[J]. 计算机工程与应用, 2015,51(8): 218-225.
[2]李明, 胡吉霞, 侯琳娜, 等. 商品评论情感分析[J]. 计算机应用, 2019,39(S2): 15-19.
[3]刘志明, 刘鲁. 基于机器学习的中文微博情感分类实证研究[J]. 计算机工程与应用, 2012, 48(1): 1-4.
[4]Read J, Carrol J. Weakly Supervised Techniques for Domain-independent Sentiment Classification[C]. //Proceedings of International Conference on Information and Knowledge Management Workshop on Topic-sentiment Analysis for Mass Opinion, 2009: 45-52.
[5]Li S, Wang Z, Zhou G, Lee S Y M. Semi-supervised Learning for Imbalanced Sentiment Classification[C]. //Proceedings of International Joint Conference on Artificial Intelligence, 2011: 1826-1831.
[6]季立堃. 基于深度学习的文本情感分析技术研究[D]. 北京:北京邮电大学, 2019.
[7]Dzmitry B, Kyunghyun C, Yoshua B.Neural machine translation by jointly learning to align and translate[C]. //In Proceedings of International Conference on Learning Representations, San -Diego, USA, May 7-9, Conference Track Proceedings, 2015.
[8]Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets[J]. Neural computation, 2006,18(7): 1527-1554.
[9]Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507.
[10]Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781,20013.
[11]崔伟健. 基于深度学习的文本情感分析[D]. 吉林:吉林大学, 2018.
[12]金志刚, 胡博宏, 张 瑞. 融合情感特征的深度学习微博情感分析[J]. 南开大学学报(自然科学版), 2020,53(5): 77-86.
[13]梁一鸣, 申莹, 赵永翼. 基于LSTM的电影评论情感分析研究[J]. 数字通信世界, 2021(02): 27-28.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)