【NVIDIA NIM 黑客松训练营】-- 智慧农林生态普查保护管理平台
智慧农林生态普查保护管理平台是一款依托NVIDIA NIM服务,结合多模态检索增强生成(RAG)技术,构建集巡检、监护、预防及应急为一体的农林业智慧管理综合性平台。本技术文档主要说明大模型RAG系统搭建过程及功能演示。
【NVIDIA NIM 黑客松训练营】-- 智慧农林生态普查保护管理平台
项目简介
智慧农林生态普查保护管理平台是一款依托NVIDIA NIM服务,结合多模态检索增强生成(RAG)技术,构建集巡检、监护、预防及应急为一体的农林业智慧管理综合性平台。
本技术文档主要说明大模型RAG系统搭建过程及功能演示。
github地址:https://github.com/ReyCui/drone_Bot/tree/main
技术方案与实现步骤
主要使用的模型及功能:
nvidia/llama-3.1-nemotron-70b-instruct:大语言模型,负责智能对话
nvidia/llama-3.2-nv-embedqa-1b-v2:向量化模型
meta/llama-3.2-11b-vision-instruct:图片识别,并转成英文回答
baichuan-inc/baichuan2-13b-chat:把英文回答转录为中文回答
1、获取API-Key
Nvidia 官方提供的实验平台已经预装了很多环境,可以直接开机使用。通过NIM接口调用大模型,需要获取API key。注册邮箱登录(最好在角色里选developer),即可查看所有的大模型及获取API Key。
查看模型:https://build.nvidia.com/explore/discover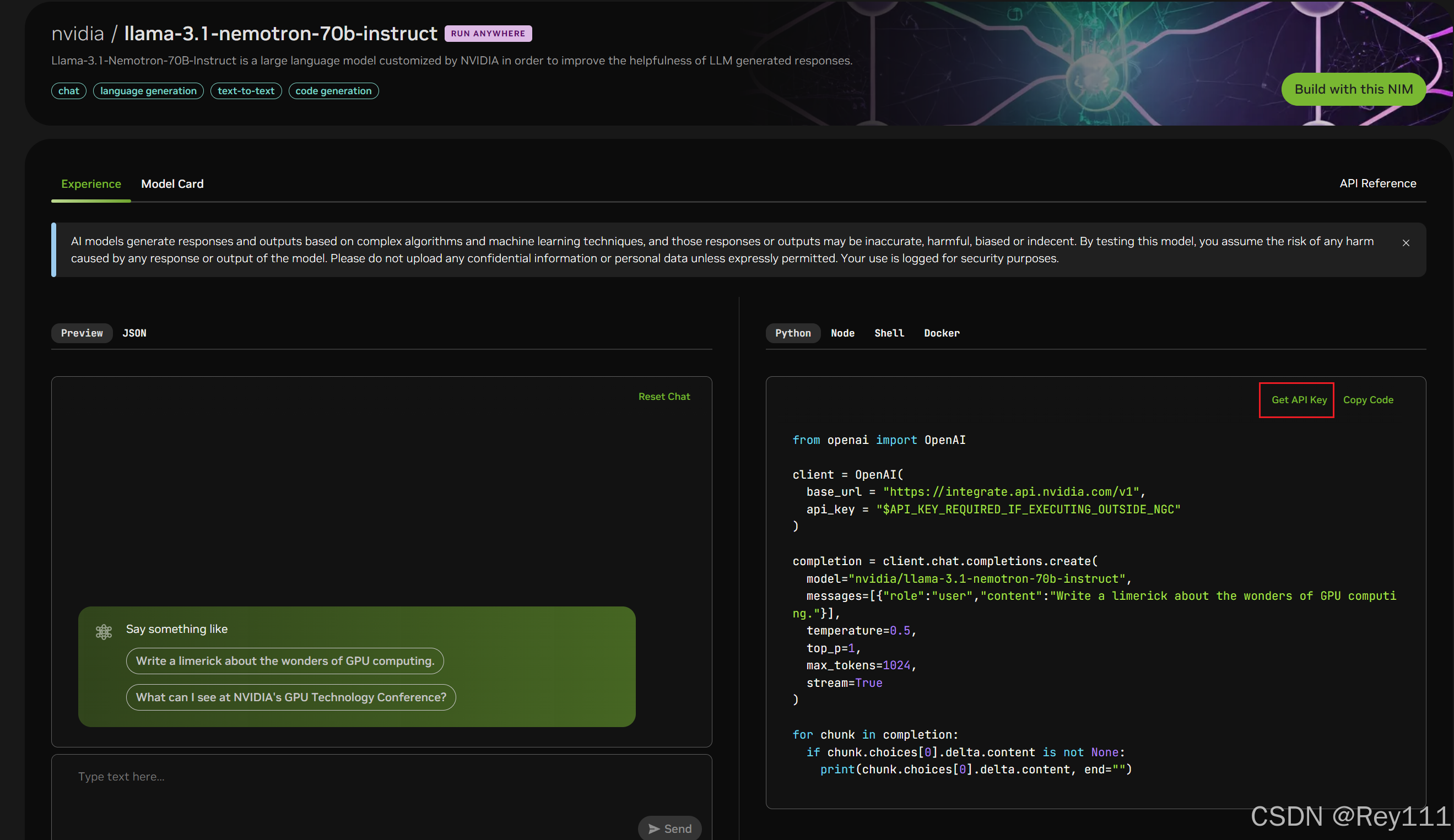
2、导入python库
import os
import requests
import base64
import gradio as gr
import dashscope
import soundfile as sf
from bs4 import BeautifulSoup
from langchain_nvidia_ai_endpoints import ChatNVIDIA, NVIDIAEmbeddings
from langchain_core.output_parsers import StrOutputParser
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader, WebBaseLoader
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
from dashscope.audio.asr import Recognition
from dashscope.audio.tts_v2 import *
3、调用nvidia/llama-3.1-nemotron-70b-instruct大模型,实现中文对话
简单调用并测试 nvidia/llama-3.1-nemotron-70b-instruct 大模型
# 初始化大模型
instruct_chat = ChatNVIDIA(model="meta/llama-3.1-8b-instruct")
instruct_llm = instruct_chat | StrOutputParser()
# 定义提示模板
prompt_template = ChatPromptTemplate.from_template(
"以下是与问题相关的信息:{context}\n用户需求:{input}\n请给出对应的无人机操作指令"
)
input_text = "Please turn left 90 degree"
prompt = prompt_template.format_messages(context = None,input=input_text)
# 调用模型生成指令
instruction = instruct_llm.invoke(prompt)
print(f"生成的指令: {instruction}")
# 输出是以下内容
# 生成的指令: 自航:左转90度
4、实现RAG查找知识库
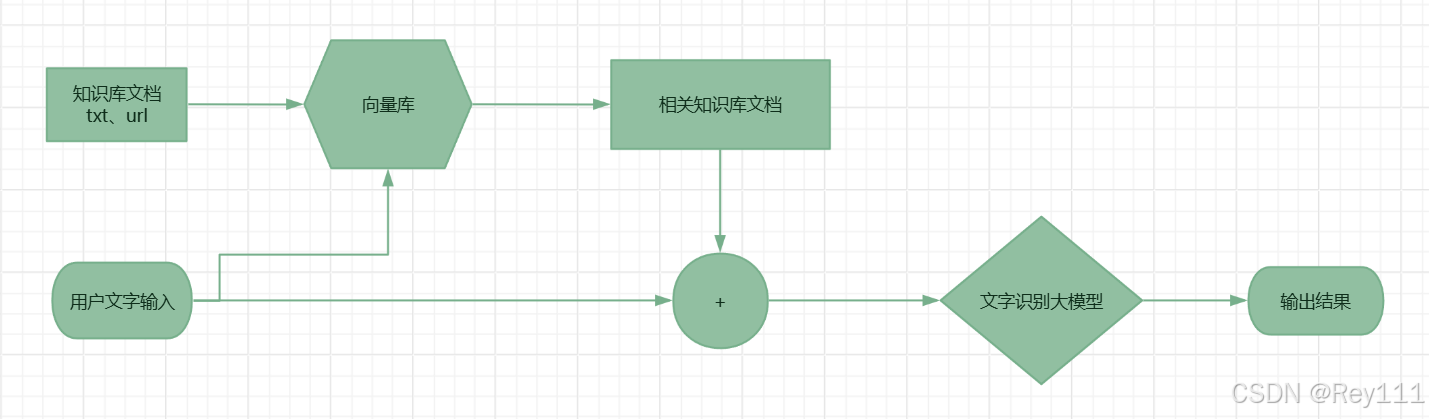
把DJI Mavic 3 Pro 帮助中心文档,做成内置知识库,以供大模型RAG调用。下面是测试调用过程:
4.1 获取帮助文档并保存到本地:
import requests
from bs4 import BeautifulSoup
url = 'https://support.dji.com/help/content?customId=zh-cn03400007715&spaceId=34&re=CN&lang=zh-CN'
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 提取网页中的文本内容
text_content = soup.get_text()
# 可以根据需要进一步清理文本,比如去除多余的空格、换行符等
text_content = ' '.join(text_content.split())
# 将提取的文本保存到本地文件
with open('./txt/dji_webpage_content.txt', 'w', encoding='utf-8') as file:
file.write(text_content)
else:
print(f"请求失败,状态码: {response.status_code}")
4.2 加载文档,并创建向量数据库
# 加载本地文本文件
loader = TextLoader('./txt/dji_webpage_content.txt')
documents = loader.load()
# 文本分割
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# 生成文本嵌入
embeddings = NVIDIAEmbeddings(model="nvidia/llama-3.2-nv-embedqa-1b-v2")
# 创建向量数据库
vectorstore = FAISS.from_documents(docs, embeddings)
# 保存向量数据库,以便后续使用
vectorstore.save_local("./nv_embedding/dji_vectorstore_zh")
4.3 加载向量数据库,并查询
# 加载向量数据库,并查询
vectorstore = FAISS.load_local("./nv_embedding/dji_vectorstore_zh", embeddings, allow_dangerous_deserialization=True)
retriever = vectorstore.as_retriever()
print(retriever.invoke("电池怎么保养?")
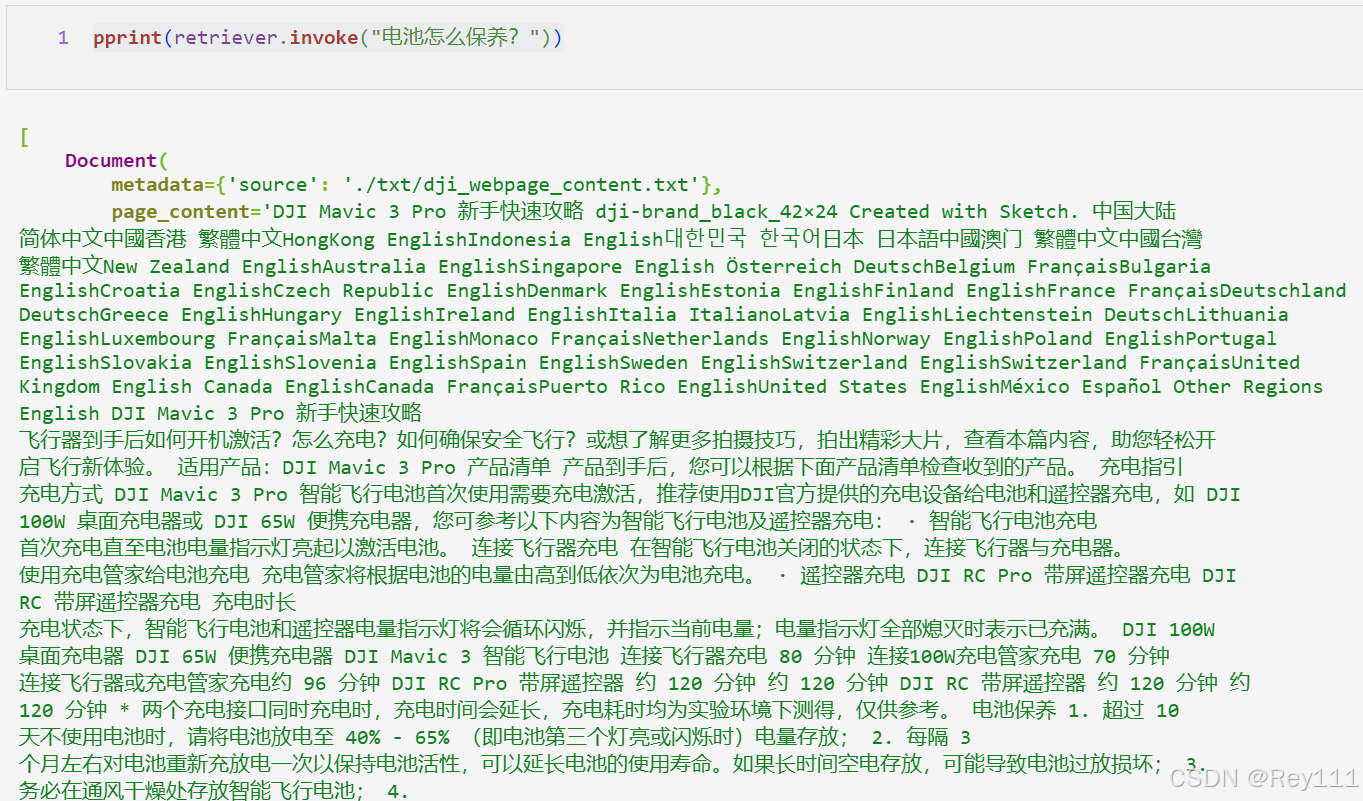
返回的是跟查询所有相关的文档,只截取的部分展示。
5、增加语音读入并转文字功能
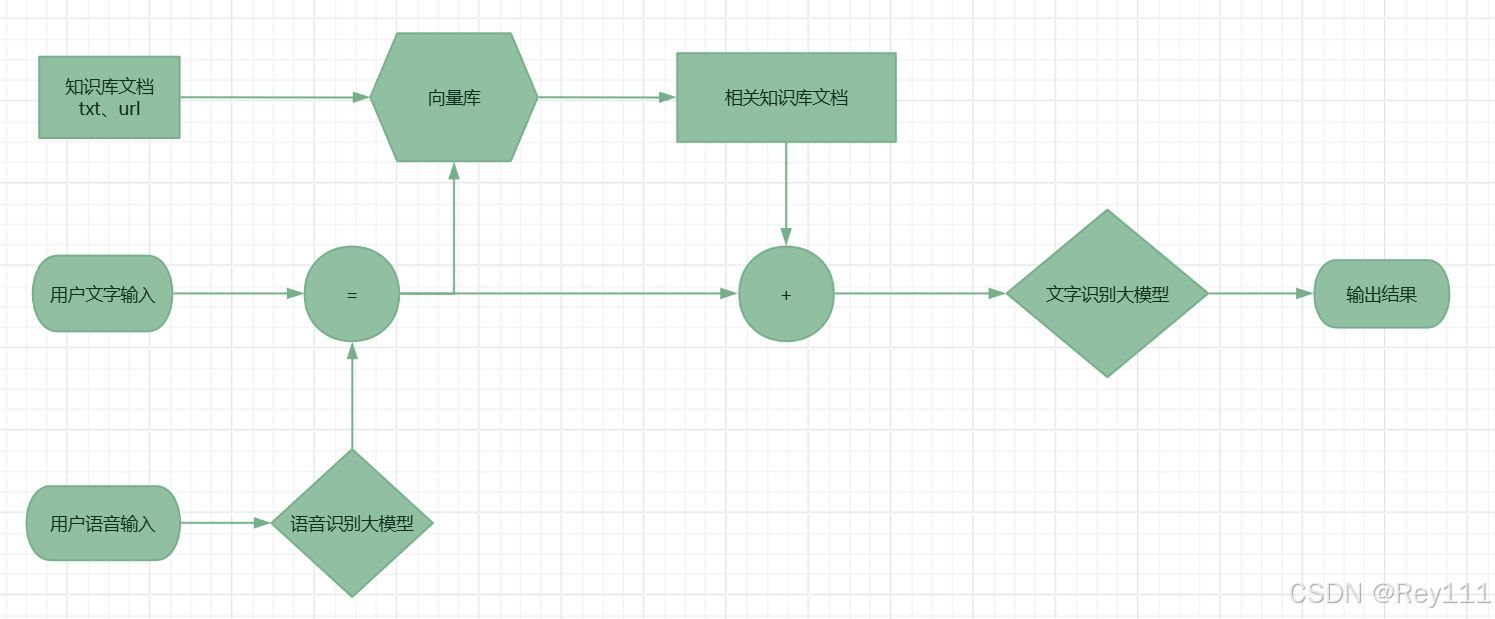
语音识别模型链接:https://build.nvidia.com/openai/whisper-large-v3
openai/whisper-large-v3 可以实现语音转文字,但是对中文不是很友好。由于openai/whisper-large-v3的API调用没有成功(这里需要再学习一下),所以暂时调用了其他的大模型。
这块功能支持用户输入语音,或者读取本地语音文件,然后转录成中文,通过RAG调取知识库,一起输入给大语言模型,得到最终输出结果。
6、增加图片识别功能
本模块的主要功能是识别无人机拍摄的视频或图片,识别农作物及土地环境的状态,给出后续养护建议。
经过测试 meta/llama-3.2-11b-vision-instruct 模型能够识别测试图片并给出建议,所以采用该模型。由于 meta/llama-3.2-11b-vision-instruct 模型对中文不是很友好,所有把识别的英文结果,通过 baichuan-inc/baichuan2-13b-chat 转录为中文。
meta/llama-3.2-11b-vision-instruct 模型识别图片测试:
def analyze_image(image_path):
"""
分析图片中作物生长情况并给出建议。
:param image_path: 图片文件路径
:return: 分析结果字符串
"""
invoke_url = "https://ai.api.nvidia.com/v1/gr/meta/llama-3.2-11b-vision-instruct/chat/completions"
stream = False
# 读取并编码图片
with open(image_path, "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
headers = {
"Authorization": f"Bearer {os.environ.get('NVIDIA_API_KEY')}",
"Accept": "text/event-stream" if stream else "application/json"
}
payload = {
"model": 'meta/llama-3.2-11b-vision-instruct',
"messages": [
{
"role": "user",
"content": f'''Here is an image related to crop growth.
Please examine the plants and their growing environment in this picture.
If there are any issues, please briefly describe the problem and suggest a quick solution.
If there are no problems, please state that the plants are growing well.
<img src="data:image/png;base64,{image_b64}" />'''
}
],
"max_tokens": 512,
"temperature": 1.00,
"top_p": 1.00,
"stream": stream
}
try:
response = requests.post(invoke_url, headers=headers, json=payload)
result = response.json()['choices'][0]['message']['content']
return result
except Exception as e:
return f"Error: {str(e)}"
print(analyze_image("./images/test_7.jpg"))

通过 baichuan-inc/baichuan2-13b-chat 模型把英文转为中文:
def translate_to_chinese(text):
"""
将文本翻译成中文。
:param text: 需要翻译的英文文本
:return: 翻译后的中文文本
"""
# pic_read = ChatNVIDIA(model="thudm/chatglm3-6b")
pic_read = ChatNVIDIA(model="baichuan-inc/baichuan2-13b-chat")
pic_prompt_template = ChatPromptTemplate.from_template("请把 {input} 翻译成中文,简单总结并优化格式。")
pic_chain = pic_prompt_template | pic_read | StrOutputParser()
translated_text = pic_chain.invoke(test_input)
return translated_text

7、Gradio前端界面及使用说明
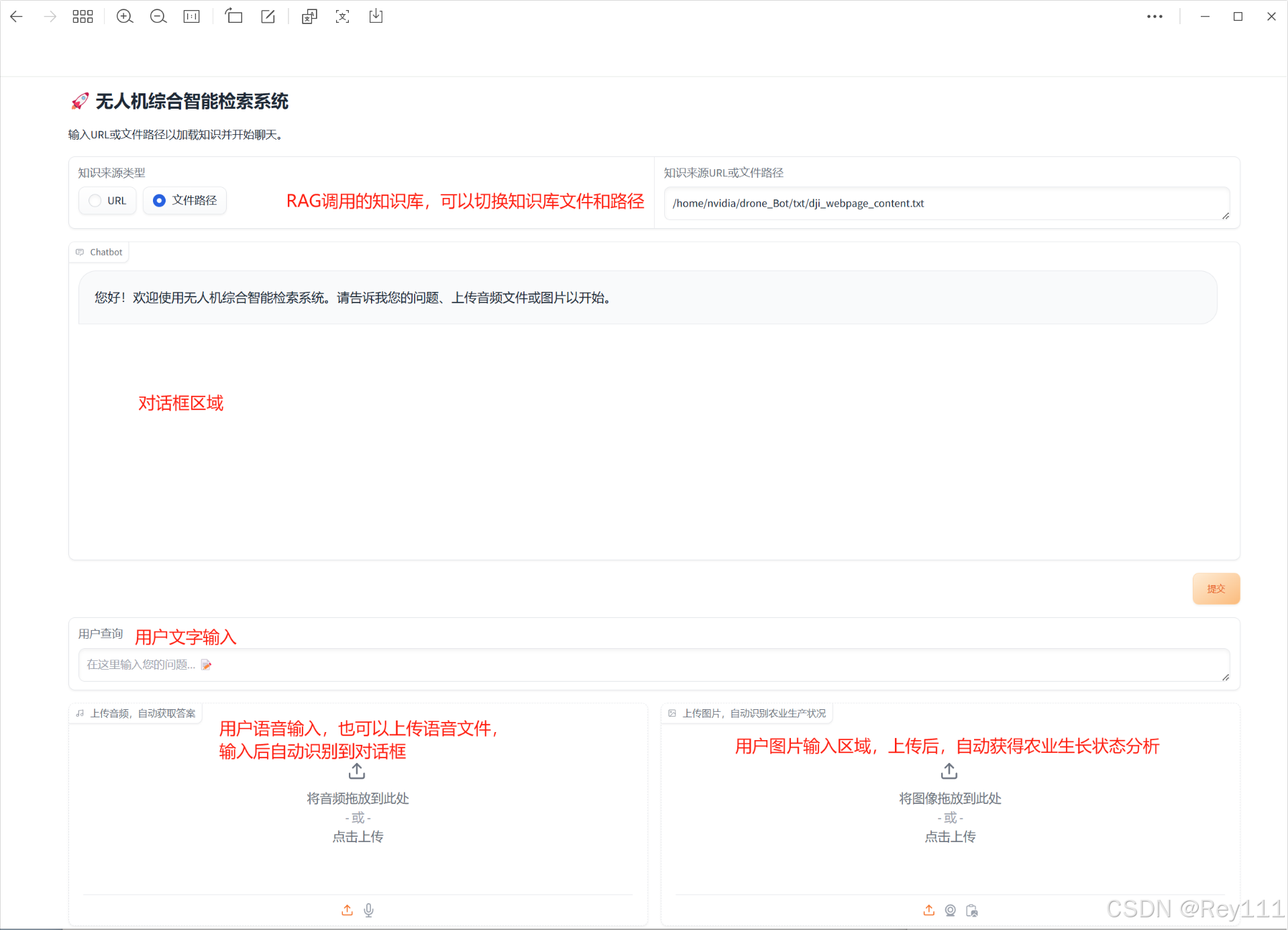
1、最上面是知识库,默认是一个txt文件 ,可以换成本地的其他txt文档,也可以用输入网址。如果是网址,知识来源类型请切换成URL。
2、用户输入文字后,请点击“提交”按钮,跟智能机器人对话,本智能系统具有历史记录功能。
3、用户也可以用语音输入,点击语音输入的麦克风按钮即可使用,输入后自动识别成文字,跟智能系统对话。当然,也支持读取本地的语音文件。
4、图片系统支持上传图片,智能识别农作物生长状态,并给出养护建议。
总结与感谢
1、扩展功能
- 把图片和视频加入知识库,实现输入 图片+文字 或者 视频+文字,输出 文字+图片 或者 文字+视频;
- 用户输入语音,大模型自动输出无人机操作指令,控制无人机运动;
- 根据无人机拍摄的视频,自动制定巡航路径等;
- 根据拍摄的画面,对农场做出预警、建议等功能。
2、技术不足及持续学习
- 对 https://build.nvidia.com/openai/whisper-large-v3 的调用没有实现,需要继续学习;
- 学习数字人功能,可以语音与用户实时互动。
3、感谢
首先,感谢Nvidia官方组织提供了这么好的学习机会和平台,实时在线解决各种问题。不得不说,NVIDIA DLI 提供的课程都很专业,只是也特别全面,真心点赞!![]()
其次,感谢 黄金赛罗秧BOT 各位小伙伴的付出和相互支持!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)