自然语言处理(4:word2vec之基于推理的方法和神经网路)
接着上一章,本章的主题仍是单词的分布式表示。在上一章中,我们使用基于计数的方法得到了单词的分布式表示。本章我们将讨论该方法的替代方法,即基于推理的方法。顾名思义,基于推理的方法使用了推理机制。当然,这里的推理机制用的就是“神经网络这次的目标是实现一个简单的word2vec。这个简单的word2vec会优 先考虑易理解性,从而牺牲一定的处理效率。所以,我们不会用它来处理大规模数据集,但用它处理小数据
系列文章目录
第一章 1:同义词词典和基于计数方法语料库预处理
第一章 2:基于计数方法的分布式表示和假设,共现矩阵,向量相似度
第一章 3:基于计数方法的改进以及总结
第二章 1:word2vec
第二章 2:word2vec和CBOW模型的实现
前言
接着上一章,本章的主题仍是单词的分布式表示。在上一章中,我们使用基于计数的方法得到了单词的分布式表示。本章我们将讨论该方法的替代方法,即基于推理的方法。
顾名思义,基于推理的方法使用了推理机制。当然,这里的推理机制用的就是“神经网络”。
这次的目标是实现一个简单的word2vec。这个简单的word2vec会优 先考虑易理解性,从而牺牲一定的处理效率。所以,我们不会用它来处理大规模数据集,但用它处理小数据集毫无问题。
提示:以下是本篇文章正文内容,下面案例可供参考
一、基于推理的方法和神经网络
我们在上一张主要学了两种自然语言处理的方法:一种是基于计数的方法;另一种是基于推理的方法。虽然两者在获得单词含义的方法上差别很大,But两者的背景都是分布式假设。 本节我们将指出基于计数的方法的问题,并从宏观角度说明它的替代方法——基于推理的方法的优点。另外,为了做好word2vec的准备工作,我 们会看一个用神经网络处理单词的例子。
1.基于计数的方法的问题和推理方法的引入
如上一章所说,基于计数的方法根据一个单词周围的单词的出现频数来表示该单词。具体来说,首先呢生成所有单词的共现矩阵,再对这个矩阵进行 SVD(你不会忘了是什么吧?),以获得密集向量(单词的分布式表示)。但是,基于计数的方法在处理大规模语料库时会出现问题。 在现实世界中,语料库处理的单词数量非常大。比如,据说英文的词汇量超过100万个。如果词汇量超过100万个,那么使用基于计数的方法就需要生成一个100万×100万的庞大矩阵,但对如此庞大的矩阵执行SVD显然是不现实的(如果你说有可能,那你厉害)。
那基于计数的方法使用整个语料库的统计数据(共现矩阵和PPMI等 ), 通过一次处理(SVD等)获得单词的分布式表示。而基于推理的方法使用神经网络,通常在mini-batch数据上进行学习。这意味着神经网络一次只需要看一部分学习数据(mini-batch),并反复更新权重。他们的不同点如下图:
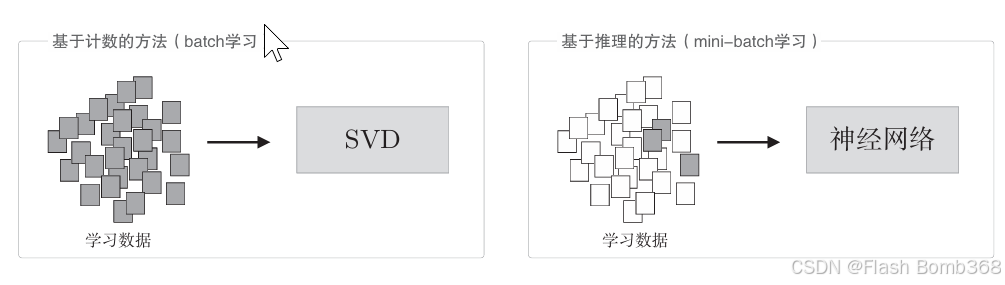
如上图,基于计数的方法一次性处理全部学习数据;反之,基于推理的方法使用部分学习数据逐步学习。这意味着,在词汇量很大的语料库 中,即使SVD等的计算量太大导致计算机难以处理,神经网络也可以在部分数据上学习。并且,神经网络的学习可以使用多台机器、多个GPU并行执行,从而加速整个学习过程。在这方面,基于推理的方法更有优势。(相当于你(计数方法)每天起早贪黑,辛辛苦苦准备了一年来考研;而你的舍友(推理方法)只用了半年,并且学习时间还没你多,但最后他考得很好,而你却还是不理想。你想想为什么?)
2.基于推理的方法的概要
基于推理的方法的主要操作是“推理”。如下图所示,当给出周围的单词(上下文)时,预测“?”处会出现什么单词,也就是两边推中间(基于计数的方法是怎么推的?答:中间推两边),这就是推理。
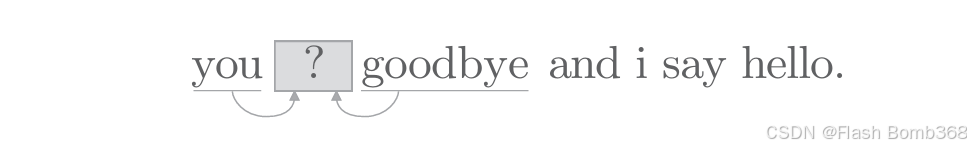
解开上述图中的推理问题并学习规律,就是基于推理的方法的主要任务。通过反复求解这些推理问题,可以学习到单词的出现模式。从“模型视角”出发,这个推理问题如下图所示。
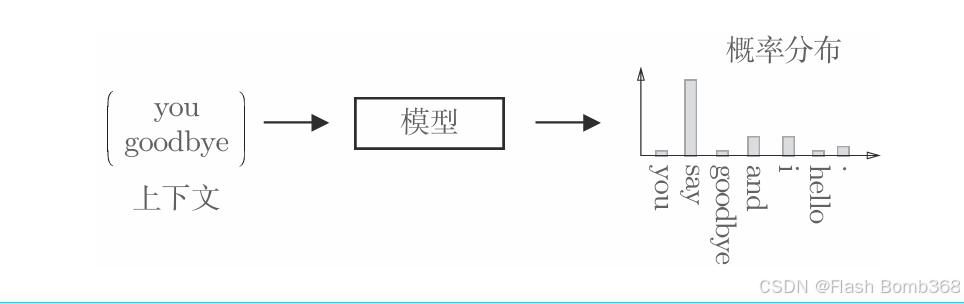
如上图所示,基于推理的方法引入了某种模型,我们将神经网络用于此模型。这个模型接收上下文信息作为输入,并输出(可能出现的)各个单词的出现概率。在这样的框架中,使用语料库来学习模型,使之能做出正确的预测。另外,作为模型学习的产物,我们得到了单词的分布式表示。这就 是基于推理的方法的全貌。
3.神经网络中单词的处理方法
从现在开始,我们将使用神经网络来处理单词。但是,神经网络无法直 接处理you或say这样的单词,要用神经网络处理单词,需要先将单词转化 为固定长度的向量。对此,一种方式是将单词转换为one-hot(独热编码)表示。
我们来看一个one-hot表示的例子。和上一章一样,我们用“You say goodbye and I say hello.”这个一句话的语料库来说明。在这个语料库中, 一共有7个单词(“you”“ say”“ goodbye”“ and”“ i”“ hello”“ .”)。 此时 , 各个单词可以转化为下图所示的one-hot表示。
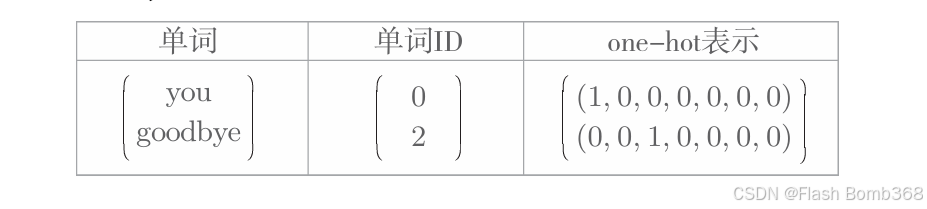
如上图所示,单词可以表示为文本、单词ID和one-hot表示。此时, 要将单词转化为one-hot表示,就需要准备元素个数与词汇个数相等的向量,并将单词ID对应的元素设为1,其他元素设为0。像这样,只要将单词转化为固定长度的向量,神经网络的输入层的神经元个数就可以固定下来(下图)。
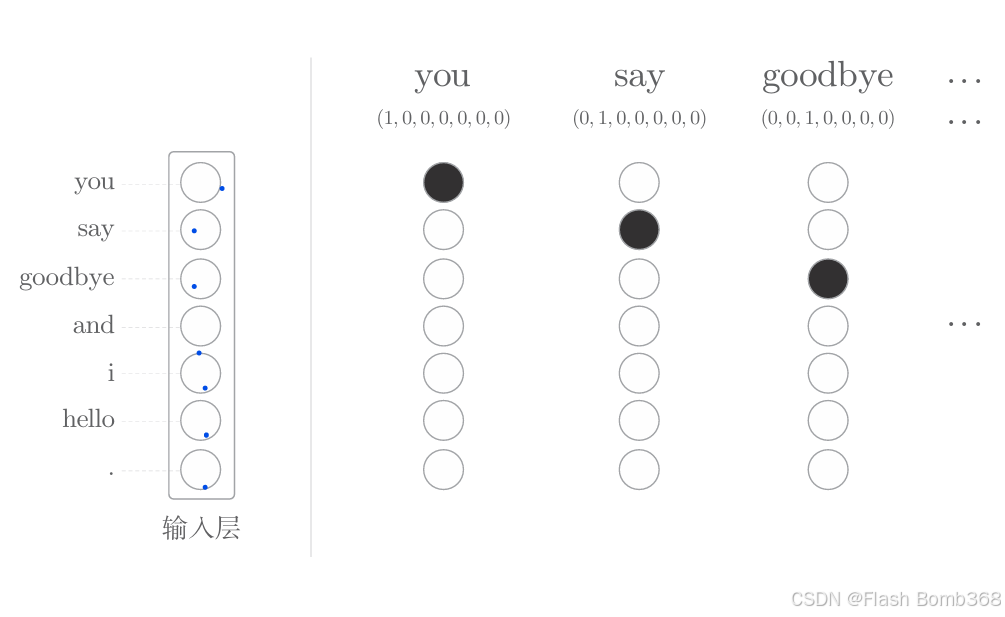
如上图所示,输入层由7个神经元表示,分别对应于7个单词(第1 个神经元对应于you,第2个神经元对应于say)。
现在事情变得很简单了。因为只要将单词表示为向量,这些向量就可以由构成神经网络的各种“层”来处理。比如,对于one-hot表示的某个单词, 使用全连接层对其进行变换的情况如下图所示。
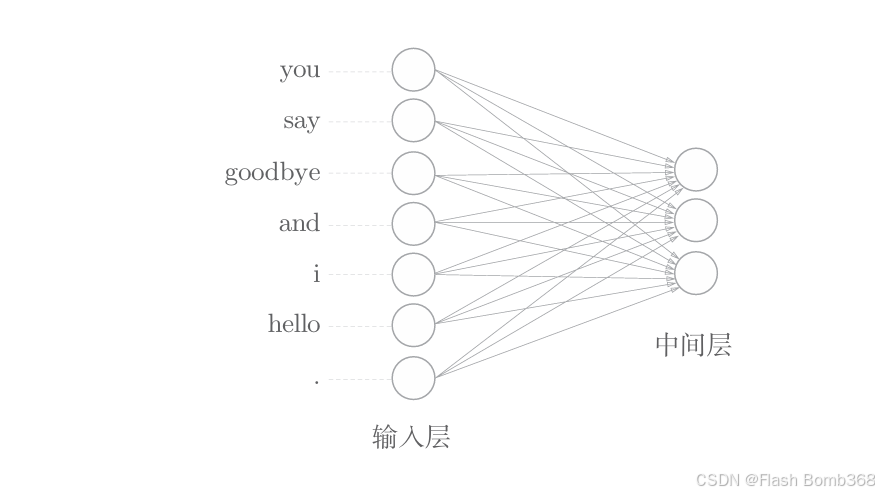
如上图所示,全连接层通过箭头连接所有节点。这些箭头拥有权重 (参数),它们和输入层神经元的加权和成为中间层的神经元。
神经元之间的连接是用箭头表示的。之后,为了明确地显示权重,我们将使用下图所示的方法。
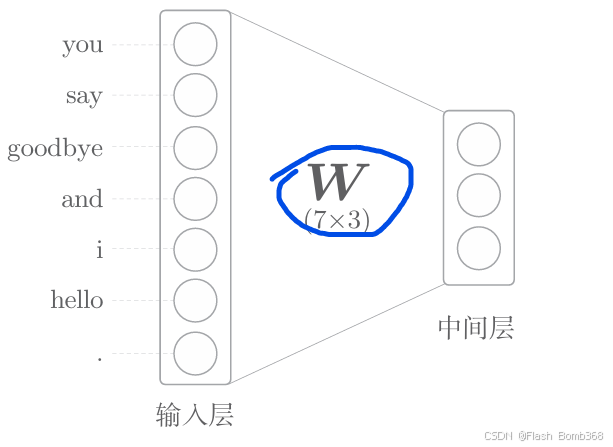
现在,我们看一下代码。这里的全连接层变换可以写成如下的Python 代码:
import numpy as np
c = np.array([[1, 0, 0, 0, 0, 0, 0]])
W = np.ranodom.randn(7, 3)
h = np.dot(c, W)
print(h)
# 这段代码将单词ID为0的单词表示为了one-hot表示,并用全连接层
# 对其进行了变换。
此处,c是one-hot 表示,单词ID对应的元素是1,其他地方都是0。上述代码中的c和W的矩阵乘积相当于“提取”权重的对应行向量.如下图所示。
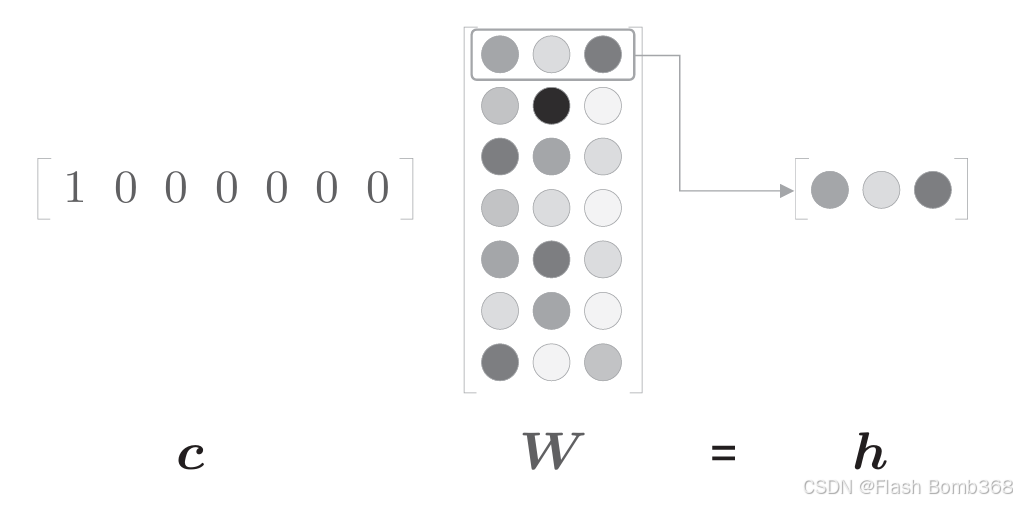
仅为了提取权重的行向量而进行矩阵乘积计算好像不是很有效率。关于这一点,我们将在后面进行改进。
上面的代码,还有另一种方法来表示,大佬们可以自己摸索一下o.
好了,这一节内容少点,后面还有很多呢,先消化消化!
总结
以上就是今天要讲的内容,本文主要讲了基于推理的方法和神经网络的简单表示,下一节我们会学习CBOW模型,大家可以点点关注,催更本人!感谢各位看到这里,三连加关注哦!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)