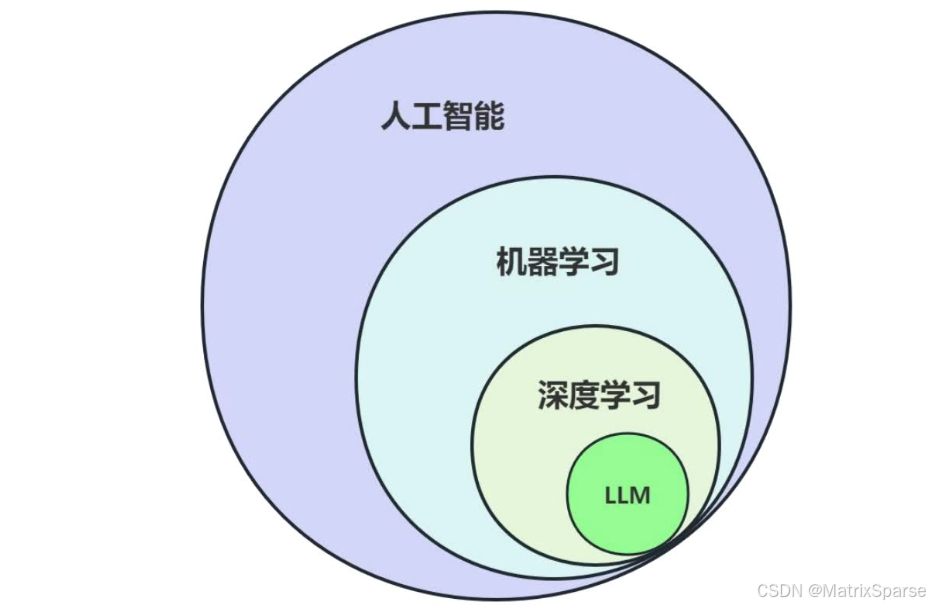
深度学习基础
深度学习基本概念
初识机器学习
所谓模型,就是一个包含了大量未知参数的函数。
所谓训练,就是通过大量的数据去迭代逼近这些未知参数的最优解。
机器学习:是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的学科。简单的说,就是“从样本中学习的智能程序”。
深度学习:深度学习的概念源于人工神经网络的研究,是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。不论是机器学习还是深度学习,都是通过对大量数据的学习,掌握数据背后的分布规律,进而对符合该分布的其他数据进行准确预测。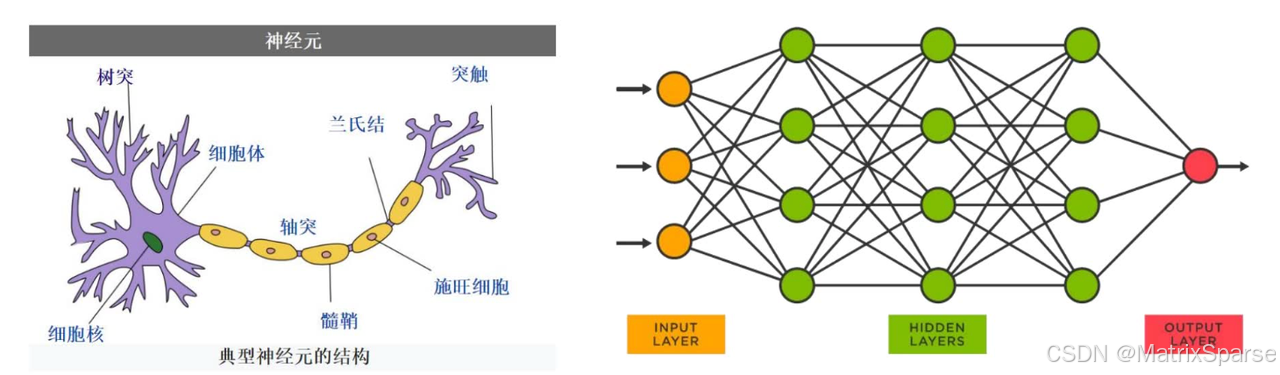
机器学习的两种典型任务
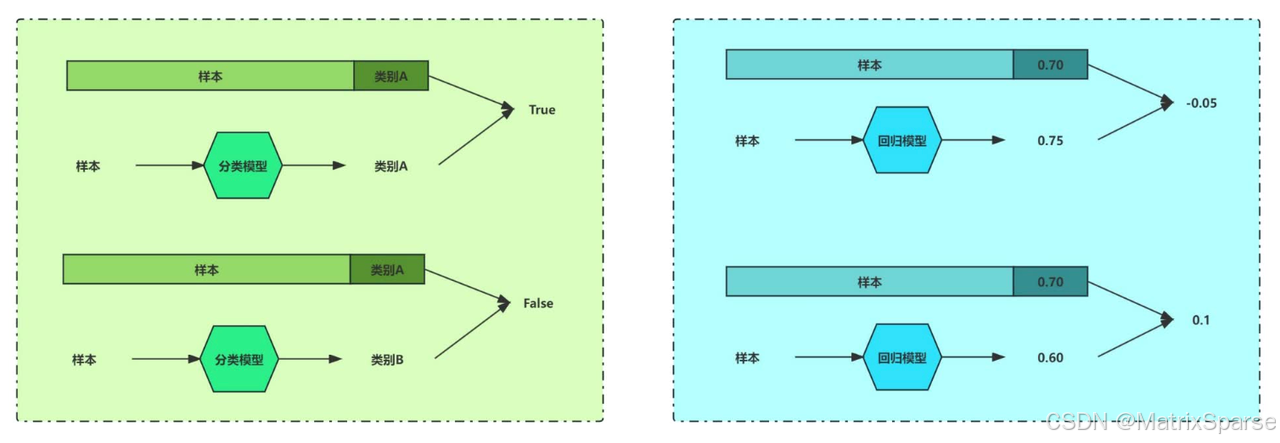
机器学习中的典型任务类型可以分为分类任务(Classification)和回归任务(Regression)。![[图片]](https://i-blog.csdnimg.cn/direct/c2bd49d44f444ce882334c87dbc3e843.png)
分类任务是对离散值进行预测,根据每个样本的值/特征预测该样本属于类型A、类型B还是类型C,例如情感分类、内容审核,相当于学习了一个分类边界(决策边界),用分类边界把不同类别的数据区分开来。
回归任务是对连续值进行预测,根据每个样本的值/特征预测该样本的具体数值,例如房价预测,股票预测等,相当于学习到了这一组数据背后的分布,能够根据数据的输入预测该数据的取值。
实际上,分类与回归的根本区别在于输出空间是否为一个度量空间。
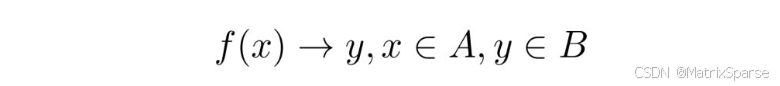
对于分类问题,目的是寻找决策边界,其输出空间B不是度量空间,即“定性”。在分类问题中,只有分类“正确”与“错误”之分,至于分类到了类别A还是类别B,没有分别,都是错误数量+1。
对于回归问题,目的是寻找最优拟合,其输出空间B是一个度量空间,即“定量”,通过度量空间衡量预测值与真实值之间的“误差大小”。当真实值为10,预测值为5时,误差为5,预测值为8时,误差为2。
机器学习分类
有监督学习
监督学习利用大量的标注数据来训练模型,对模型的预测值和数据的真实标签计算损失,然后将误差进行反向传播(计算梯度、更新参数),通过不断的学习,最终可以获得识别新样本的能力。
每条数据都有正确答案,通过模型预测结果与正确答案的误差不断优化模型参数无监督学习:
无监督学习
不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务。有监督和无监督最主要的区别在于模型在训练时是否需要人工标注的标签信息。
只有数据没有答案,常见的是聚类算法,通过衡量样本之间的距离来划分类别
半监督学习
利用有标签数据和无标签数据来训练模型。一般假设无标签数据远多于有标签数据。例如使用有标签数据训练模型,然后对无标签数据进行分类,再使用正确分类的无标签数据训练模型;
利用大量的无标注数据和少量有标注数据进行模型训练。
自监督学习
机器学习的标注数据源于数据本身,而不是由人工标注。目前主流大模型的预训练过程都是采用自监督学习,将数据构建成完型填空形式,让模型预测对应内容,实现自监督学习。
通过对数据进行处理,让数据的一部分成为标签,由此构成大规模数据进行模型训练
远程监督学习
主要用于关系抽取任务,采用bootstrap的思想通过已知三元组在文本中寻找共现句,自动构成有标签数据,进行有监督学习。
基于现有的三元组收集训练数据,进行有监督学习强化学习。
强化学习是智能体根据已有的经验,采取系统或随机的方式,去尝试各种可能答案的方式进行学习,并且智能体会通过环境反馈的奖赏来决定下一步的行为,并为了获得更好的奖赏来进一步强化学习。
以获取更高的环境奖励为目标优化模型。
如果你还想挖掘更多宝藏内容,请关注公众号“智界元枢”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)