计算机视觉入门
·
文章目录
- 0. 前言
-
-
-
- 1. 机器学习 可以做 图像任务么
-
- 机器学习中 SVM,集成学习,MLP等,可以用于 图像识别任务,但通常情况下 效果 不如 卷积神经网络(CNN)出色。
- 主要原因: 特征工程不够,不能够充分利用 图像数据的空间结构,局部特征, 但是可以人为构建如(HOG,SIFT,SURF),但是其依赖于 特征工程的质量,相比于 CNN自动的卷积层,池化层,其能力很弱。
- 图像数据 比较大(专业一点称 数据维度比较高,加上 色彩的通道数 ,维度会变得更高),传统机器学习,如 sklearn(scikit-learn),其通常会一次性加载所有数据进行训练。而深度学习,在 pythorch 框架下,可以利用 Dataloader 类,设置 batch_size,分批次处理数据。
-
-
- 1. 图像基础
- 2. 历史发展
-
- 2.1 图像处理常见任务
- 2.2 常见 CNN 网络
-
- 2.2.0 Vision Transformer(ViT)
-
-
- 通过卷积核逐步提取图像的局部特征,即:向下采样,经过多层卷积叠加后,最终在深层提取高维语义信息。
- 这种方式擅长处理局部区域内的相关性,提取细节特征,但由于卷积核的感受野有限,CNN 在捕捉全局依赖时可能需要更多层数或更复杂的架构。
- ViT:将图像划分为多个固定大小的图像块(Patch),然后将每个图像块展平并嵌入到高维向量空间,再通过 Transformer 的注意力机制来捕捉图像块之间的关系。这种方式可以更加灵活地捕捉不同图像块的关联性和特征。
- 主要是 ViT 引入了 自注意力机制,其要计算每个图像块与其他所有图像块之间的关系。 而非是单个单个的卷积核+步长这样子去提取特征矩阵。
- 显然,有监督学习的标签异常昂贵,所以现在主流还是 半监督学习+自监督学习。
- 自监督学习是一种无监督学习的方法,从数据本身生成标签来训练模型。它利用数据中的内在结构或关系,设计预训练任务,从而挖掘数据的潜在特征表示。
-
- 小样本学习法——Few-shot Learning,致力于解决模型在只要少量样本的情况下进行有效的学习,其在很多实际应用中非常有价值,如:医疗图像分析,罕见病检测等。 其难以获得大量标注数据。
- 对抗式生成网络GAN,生成器(Generator) 模仿 生成尽可能真实的虚拟数据。 判别器(Discriminator) 努力 识别出 生成器拟合的假数据。 各有各的损失函数。
- 扩散模型 扩散模型基于物理学中 扩散过程概念,逐步向数据中添加噪声,学习如何从噪声中恢复原始数据,实现数据生成。 其 训练更稳定,有更好的可解释性。
0. 前言
1. 机器学习 可以做 图像任务么
机器学习中 SVM,集成学习,MLP等,可以用于 图像识别任务,但通常情况下 效果 不如 卷积神经网络(CNN)出色。
主要原因: 特征工程不够,不能够充分利用 图像数据的空间结构,局部特征, 但是可以人为构建如(HOG,SIFT,SURF),但是其依赖于 特征工程的质量,相比于 CNN自动的卷积层,池化层,其能力很弱。
图像数据 比较大(专业一点称 数据维度比较高,加上 色彩的通道数 ,维度会变得更高),传统机器学习,如 sklearn(scikit-learn),其通常会一次性加载所有数据进行训练。而深度学习,在 pythorch 框架下,可以利用 Dataloader 类,设置 batch_size,分批次处理数据。
1. 图像基础
1.1 像素表示:彩色:RGB ,red green blue
(0,0,0)为 黑; (255,255,255)为白;(255,0,0)为红
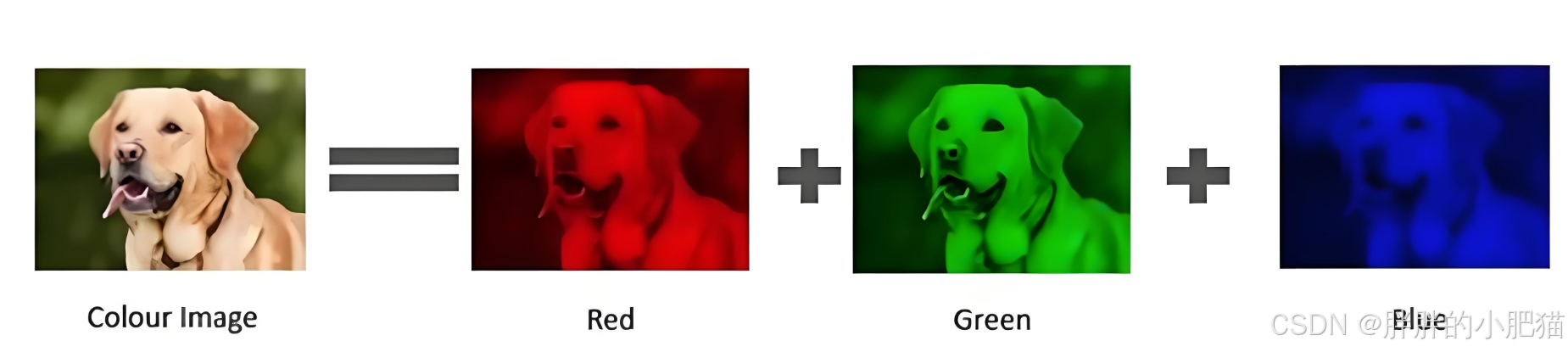
1.2 为了减少内存,常用 灰度图像,把像素点转为 灰度值:0 ~ 255 黑 ~ 白
RGB 转灰度: Gray = 0.299 R + 0.587 G + 0.114 B(权重为人眼对不同颜色的敏感度)
1.2 图像 以张量 表示
pytorch 中用(N,C,H,W)为 表示张量 维度的默认约定。
TensorFlow中是(N,H,W,C)
N:批量大小 batch_size,每一次训练中,一次性处理样本数量
C:通道数 Number of Channels,指 输入数据的通道数量,
H:数据 高度的 像素数
W:数据 宽度的 像素数
以 批量 32,彩色,128x128 像素的图像 即 (32,3,128,128)
transform = transforms.Compose([
transforms.Resize((128,128),
transform.ToTensor() # 图像转为 Pytorch 中张量
]}
# transform.ToTensor 转为 C,H,W
# 定义批次 需要 通过 DataLoader 类
1.3 数据增强(又名 数据增广)
1.3.1 几何变换:通过 裁剪,旋转,翻转等,生成更多的数据变体,提高多样性,减少过拟合,令模型关注在 图像内容中关键的特征。
1.3.2 颜色空间操作:调 对比度,亮度,饱和度等
1.3.3 添加噪声:在图像中 添加随机噪声,模拟实际场景中的干扰,提高模型鲁棒性。 以及对图像进行遮挡。
鲁棒性:强调模型在面对数据中的噪声、异常值或分布变化时的稳定性,能够抵抗外部干扰,保持模型的性能。
泛化性:强调模型在未见过的数据上的表现能力,防止过拟合,能够在新的数据上保持良好的性能。
1.3.0 预处理管道工程
transforms.Compose 可以看作 一个 数据预处理管道工程,它将多个数据处理步骤串联,形成一个流水线。
数据流入,经过一系列处理,而后流出。
# 定义一个预处理管道
transform = transforms.Compose([
transforms.Resize((32, 32)), # 调整图像大小
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 转换为 Tensor
transforms.Normalize((0.5,), (0.5,)) # 归一化
])
2. 历史发展
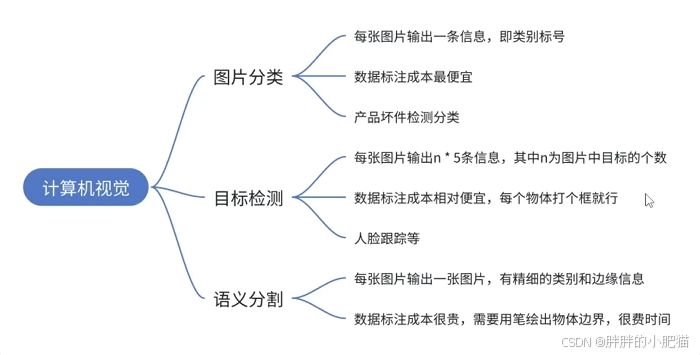
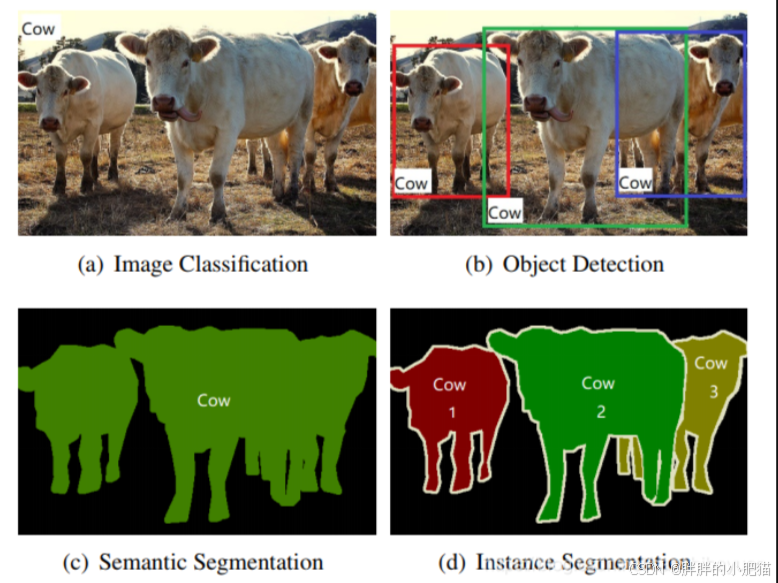
2.1 图像处理常见任务
图片分类: 数据标注成本低,
目标检测:打框标注物体边界 —— yolo
语义分割:数据集成本高,生成一张与原图大小相同的分割图。每个像素都被赋予了一个类别标签(如人、车、树木等)。说白了,把整个轮廓抠出来了。
实例分割:语义分割的基础上,区分每一个牛。
2.2 常见 CNN 网络

2.2.0 Vision Transformer(ViT)
为什么 CNN 逐渐在发展中被 ViT(视觉 Transformer)比下去?
CNN 的卷积和池化操作本质上是下采样过程,会导致信息丢失。即使通过 ResNet 等模型增加网络深度,但仍然存在信息丢失的问题。
通过卷积核逐步提取图像的局部特征,即:向下采样,经过多层卷积叠加后,最终在深层提取高维语义信息。
这种方式擅长处理局部区域内的相关性,提取细节特征,但由于卷积核的感受野有限,CNN 在捕捉全局依赖时可能需要更多层数或更复杂的架构。
ViT:将图像划分为多个固定大小的图像块(Patch),然后将每个图像块展平并嵌入到高维向量空间,再通过 Transformer 的注意力机制来捕捉图像块之间的关系。这种方式可以更加灵活地捕捉不同图像块的关联性和特征。
主要是 ViT 引入了 自注意力机制,其要计算每个图像块与其他所有图像块之间的关系。 而非是单个单个的卷积核+步长这样子去提取特征矩阵。
显然,有监督学习的标签异常昂贵,所以现在主流还是 半监督学习+自监督学习。
自监督学习是一种无监督学习的方法,从数据本身生成标签来训练模型。它利用数据中的内在结构或关系,设计预训练任务,从而挖掘数据的潜在特征表示。
自监督学习通过构建正样本(positive)和负样本(negative),然后度量正负样本的距离来实现学习。在这个过程中,模型需要学会区分哪些样本是相似的(即正样本),哪些样本是不相似的(即负样本)。这种学习方式使得模型能够捕捉到数据中的细微差别,从而学习到更加丰富的特征表示。
比如说:基于上下文的方法:通过构建基于数据上下文的辅助任务来进行学习。
基于对比的方法:通过正负样本对,
基于互信息方法:对比 全局特征和局部特征进行分类。
小样本学习法——Few-shot Learning,致力于解决模型在只要少量样本的情况下进行有效的学习,其在很多实际应用中非常有价值,如:医疗图像分析,罕见病检测等。 其难以获得大量标注数据。
对抗式生成网络GAN,生成器(Generator) 模仿 生成尽可能真实的虚拟数据。 判别器(Discriminator) 努力 识别出 生成器拟合的假数据。 各有各的损失函数。
但是 GAN 模型容易崩溃,训练判别器(警察进修),训练生成器(犯罪升级),判别器太强,则生成器不能学到有效梯度, 生成器找到判别器的漏洞,反复生成同一种假数据。
扩散模型 扩散模型基于物理学中 扩散过程概念,逐步向数据中添加噪声,学习如何从噪声中恢复原始数据,实现数据生成。 其 训练更稳定,有更好的可解释性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)