torch入门:音频分类任务(pytorch+librosa)
前面我们已经做过了一些文本分类任务,下面我们来试着完成一个音频分类任务吧。音频分类任务简单来说就是现在有若干个人说话时的音频数据,你需要使用这些数据来训练一个模型,能够分类好这些人的语音,当这些人当中的某人再次发言时,你的模型能够识别出是谁在说话。音频分类理论上来说完全可以用来分类歌曲,但是对于新手来说我建议您先从数据噪声较小的个人语音分类做起较好。
前言
前面我们已经做过了一些文本分类任务,下面我们来试着完成一个音频分类任务吧。音频分类任务简单来说就是现在有若干个人说话时的音频数据,你需要使用这些数据来训练一个模型,能够分类好这些人的语音,当这些人当中的某人再次发言时,你的模型能够识别出是谁在说话。音频分类理论上来说完全可以用来分类歌曲,但是对于新手来说我建议您先从数据噪声较小的个人语音分类做起较好。
我依旧会从训练模型的几个基本步骤——数据收集,数据预处理,训练模型,模型评估这几步来展开任务。
最后,在开始前请确保你已经安装了librosa库,并请检查你的torch和CUDA已经安装好:
import torch
print(torch.__version__) # 输出torch版本
print(torch.cuda.is_available()) # 检查CUDA是否可用(torch和cuda的安装并不是一个简单的过程,但是网上已经有很多其他的教程了,我就不再在这里赘述了)
数据收集
你可以在各大数据集网站找到合适的数据集,我也上传了我的数据集供你下载。我的数据集是自己使用python收集的,下面简单介绍一下我的数据收集和预处理的过程吧。
下面的python脚本能够进行录音,然后每5秒保存一次录音到一个文件夹下。之所以选择每5秒保存一次这样的等长切片的形式,而不是将录音整段保留下来,是为了方便后续的处理与更好地利用训练资源。
import pyaudio
import wave
import threading
import time
import os
# 录音参数
FORMAT = pyaudio.paInt16 # 16位分辨率
CHANNELS = 1 # 单声道
RATE = 44100 # 采样率
CHUNK = 1024 # 每个缓冲区的帧数
RECORD_SECONDS = 5 # 每次录音时长
OUTPUT_DIRECTORY = "./test" # 保存录音的目录,如果没有对应的目录就创建一个
# 启动录音的线程
def record_audio(file_index):
print(f"Started recording audio{file_index + 1}.wav")
stream = audio.open(format=FORMAT, channels=CHANNELS,
rate=RATE, input=True,
frames_per_buffer=CHUNK)
frames = []
for _ in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
filename = os.path.join(OUTPUT_DIRECTORY, f"audio{file_index + 1}.wav")
wf = wave.open(filename, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(audio.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
stream.stop_stream()
stream.close()
# 每隔5秒启动一次录音的定时器
def start_recording():
file_index = 0
while True:
threading.Thread(target=record_audio, args=(file_index,)).start()
file_index += 1
time.sleep(RECORD_SECONDS)
if __name__ == "__main__":
audio = pyaudio.PyAudio() # 初始化
if not os.path.exists(OUTPUT_DIRECTORY):
os.makedirs(OUTPUT_DIRECTORY)
print("Starting recording")
start_recording()
数据预处理
如果你使用了我上面的脚本来收集数据,那么就不需要再进行进一步的处理了。如果你使用其他的数据集,由于我不清楚你数据集的样式,你可能需要自己进行预处理,同时也可以联系我来获取建议。但是如果你和我一开始一样,手头只有一段完整的不同角色说话的音频,下面的脚本能够帮你对其进行切割,使其变成合适的格式。
(为什么博主会只有一段完整的音频呢?那是因为博主是社恐,没有小伙伴来帮忙录音,而且又是懒狗,不想自己录,于是就用Edge的盲人大声朗读模式来读网页并录音,所以就只有一段完整的音频了咯。你别说,这模式能选的语色还挺多的,效果也还行)
from pydub import AudioSegment
import os
def split_wav(input_file, output_dir, segment_duration_ms):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
if not os.path.exists(output_dir): # 确保输出目录存在
os.makedirs(output_dir)
# 读取音频文件
audio = AudioSegment.from_wav(input_file)
# 计算切片数量
duration_ms = len(audio)
num_segments = (duration_ms // segment_duration_ms) + (1 if duration_ms % segment_duration_ms != 0 else 0)
# 切分音频文件
for i in range(num_segments):
start_ms = i * segment_duration_ms
end_ms = (i + 1) * segment_duration_ms if i != num_segments - 1 else duration_ms
segment = audio[start_ms:end_ms]
output_file = os.path.join(output_dir, f"segment{i + 1}.wav") # 构造输出文件名
segment.export(output_file, format="wav") # 保存切片
print(f"Exported {output_file}")
input_wav = r'path/to/your/wav/file/歌曲.wav' # 替换为你的WAV文件路径
output_dir = r'path/to/your/文件夹名' # 替换为你希望存储输出片段的目录
segment_duration_ms = 5000 # 5秒,单位为毫秒
# 执行切分
split_wav(input_wav, output_dir, segment_duration_ms)
模型训练
下面我们导入必要的库,将音频的数据格式和神经网络定义出来,然后读入数据集比进行切割,划分训练集和测试集,最后开始我们的训练。
import os # 自动识别文件
import librosa # 主要音频分析
import librosa.feature # 取MFCC(梅尔频率倒谱系数)
import numpy as np # 数学
import torch # CNN
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset, random_split
from sklearn.preprocessing import LabelEncoder # 标签处理
class AudioDataset(Dataset):
def __init__(self, filepaths, labels, sr=16000, n_mfcc=13):
self.filepaths = filepaths
self.labels = labels
self.sr = sr
self.n_mfcc = n_mfcc
def __len__(self):
return len(self.filepaths)
def __getitem__(self, idx):
filepath = self.filepaths[idx]
label = self.labels[idx]
y, sr = librosa.load(filepath, sr=self.sr)
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=self.n_mfcc)
mfccs = np.mean(mfccs.T, axis=0)
return torch.tensor(mfccs, dtype=torch.float32), torch.tensor(label, dtype=torch.long)
class AudioClassifier(nn.Module):
def __init__(self, input_size, num_classes):
super(AudioClassifier, self).__init__()
self.fc1 = nn.Linear(input_size, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, num_classes)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = x.squeeze(0)
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 数据准备
auto_data_dir = r'Auto_data' # 替换为你的音频文件目录
"""
请注意,其中Auto_data这个文件夹的内容的格式为:
Auto_data>
说话人1>
第一个5s的wav文件.wav
第二个5s的wav文件.wav
……
说话人2>
说话人3>
……
"""
labels = []
filepaths = []
for label in os.listdir(auto_data_dir):
label_dir = os.path.join(auto_data_dir, label)
if os.path.isdir(label_dir):
for filepath in os.listdir(label_dir):
filepaths.append(os.path.join(label_dir, filepath))
labels.append(label)
# 编码标签
label_encoder = LabelEncoder()
labels = label_encoder.fit_transform(labels)
num_classes = len(label_encoder.classes_)
# 数据集划分
dataset = AudioDataset(filepaths, labels)
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
# 数据加载器
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 模型、损失函数和优化器
input_size = 13 # MFCC特征的数量,一般是12+1
model = AudioClassifier(input_size, num_classes)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 自动识别是否能够使用cuda
print("开始训练")
print(f"设备为{device}")
num_epochs = 50 # 多少轮?
model = model.to(device)
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {running_loss / len(train_loader):.4f}')
print("训练结束,保存模型")
torch.save(model.state_dict(), 'model.pth')博主训练了两个说话人各自5分钟左右的数据,启用了CUDA,显卡为RTX3060,次数为50轮,训练时间<3min,如果你的硬件配置较低,稍加等待也能完成,也可以考虑减少训练的数据。
模型测试
保留数据格式定义以及数据集划分部分的代码,将训练部分的代码替换为测试代码,对数据集进行评测。为了防止最终只输出一个模型的准确率导致你对模型的性能没有一个只管的感受,我在原有的评测方式还增加了一种方法,能够直接输出模型对于某一数据的评测结果,你可以亲自来判断模型的评测是否正确。
import os # 自动识别文件
import librosa # 主要音频分析
import librosa.feature # 取MFCC(梅尔频率倒谱系数)
import numpy as np # 数学
import torch # CNN
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset, random_split
from sklearn.preprocessing import LabelEncoder # 标签处理
class AudioDataset(Dataset):
def __init__(self, filepaths, labels, sr=16000, n_mfcc=13):
self.filepaths = filepaths
self.labels = labels
self.sr = sr
self.n_mfcc = n_mfcc
def __len__(self):
return len(self.filepaths)
def __getitem__(self, idx):
filepath = self.filepaths[idx]
label = self.labels[idx]
y, sr = librosa.load(filepath, sr=self.sr)
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=self.n_mfcc)
mfccs = np.mean(mfccs.T, axis=0)
return torch.tensor(mfccs, dtype=torch.float32), torch.tensor(label, dtype=torch.long)
class AudioClassifier(nn.Module):
def __init__(self, input_size, num_classes):
super(AudioClassifier, self).__init__()
self.fc1 = nn.Linear(input_size, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, num_classes)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = x.squeeze(0)
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 数据准备
auto_data_dir = r'Auto_data' # 替换为你的音频文件目录
"""
请注意,其中Auto_data这个文件夹的内容的格式为:
Auto_data>
说话人1>
第一个5s的wav文件.wav
第二个5s的wav文件.wav
……
说话人2>
说话人3>
……
"""
labels = []
filepaths = []
for label in os.listdir(auto_data_dir):
label_dir = os.path.join(auto_data_dir, label)
if os.path.isdir(label_dir):
for filepath in os.listdir(label_dir):
filepaths.append(os.path.join(label_dir, filepath))
labels.append(label)
# 编码标签
label_encoder = LabelEncoder()
labels = label_encoder.fit_transform(labels)
num_classes = len(label_encoder.classes_)
# 数据集划分
dataset = AudioDataset(filepaths, labels)
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
# 数据加载器
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 模型、损失函数和优化器
input_size = 13 # MFCC特征的数量,一般是12+1
model = AudioClassifier(input_size, num_classes)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 启用cuda加速?
print("调用模型")
model.load_state_dict(torch.load('model.pth', map_location=device))
# Auto_eval
model.eval()
model = model.to(device)
with torch.no_grad():
correct = 0
total = 0
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy: {100 * correct / total:.2f}%')
# visual_eval
def predict_audio(model, filepath, sr=16000, n_mfcc=13):
y, sr = librosa.load(filepath, sr=sr)
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=n_mfcc)
mfccs = np.mean(mfccs.T, axis=0)
mfccs = np.expand_dims(mfccs, axis=0)
mfccs = torch.tensor(mfccs, dtype=torch.float32).unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
outputs = model(mfccs)
_, predicted = torch.max(outputs.data, 1)
return label_encoder.inverse_transform([predicted.item()])[0]
manual_data_dir = r'Visual_data' # 替换为你的音频文件目录
"""
Visual_data文件夹的结构入下:
AI-girl1.wav
AI-man1.wav
AI-man2.wav
……
"""
for i in os.listdir(manual_data_dir):
print(f'{i[:-4]} - 预测为: {predict_audio(model, rf"{manual_data_dir}/{i}")}')
运行的结果如下:
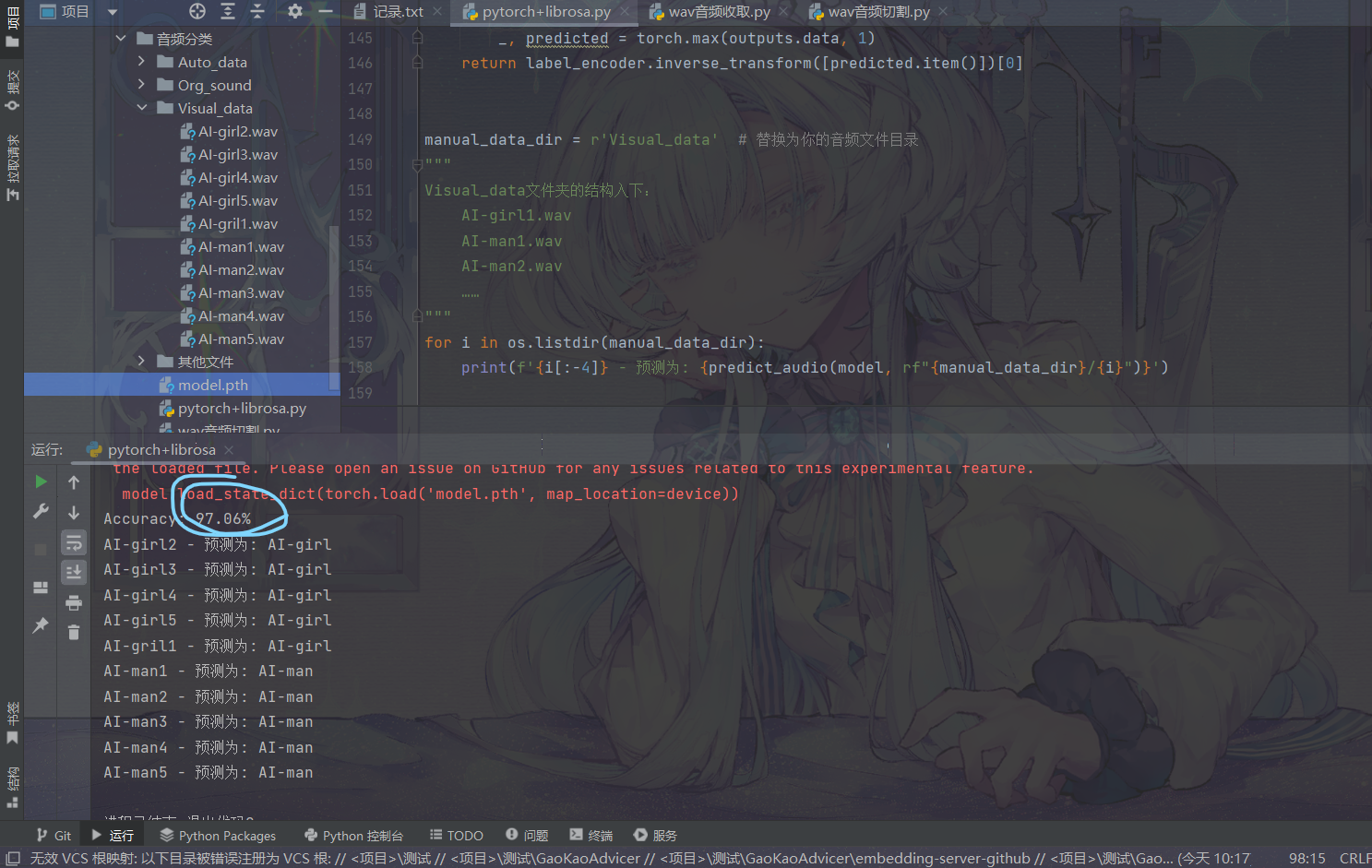
可以看到准确率惊人的高,这是因为我们这里使用的数据集较小,而且进行的是二分类,一般来说在进行多分类时模型准确率就会骤降了。
最后
你通过可以再收集更多的数据,修改神经网络,调整训练超参数,增加训练轮次等方法来不断提升模型性能。
数据集,源码,模型已经打包上传,你可以直接下载。
如果你感兴趣,可以看看我的其他关于人工智能与大模型的文章:
大模型入门:文本分类任务(基于fasttext与jieba)-CSDN博客
大模型入门:文本分类任务(基于Bert进行微调)-CSDN博客
有任何问题可向作者提出。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)