AI小白的第五天:神经网络原理
神经网络原理
在代码里看到的nn,实际上就是Neural Network(神经网络)的缩写。
初代神经网络(单个神经元)
它有个别致的名字叫perceptron(感知机或感知器),因为它是一个模拟神经元的数学模型。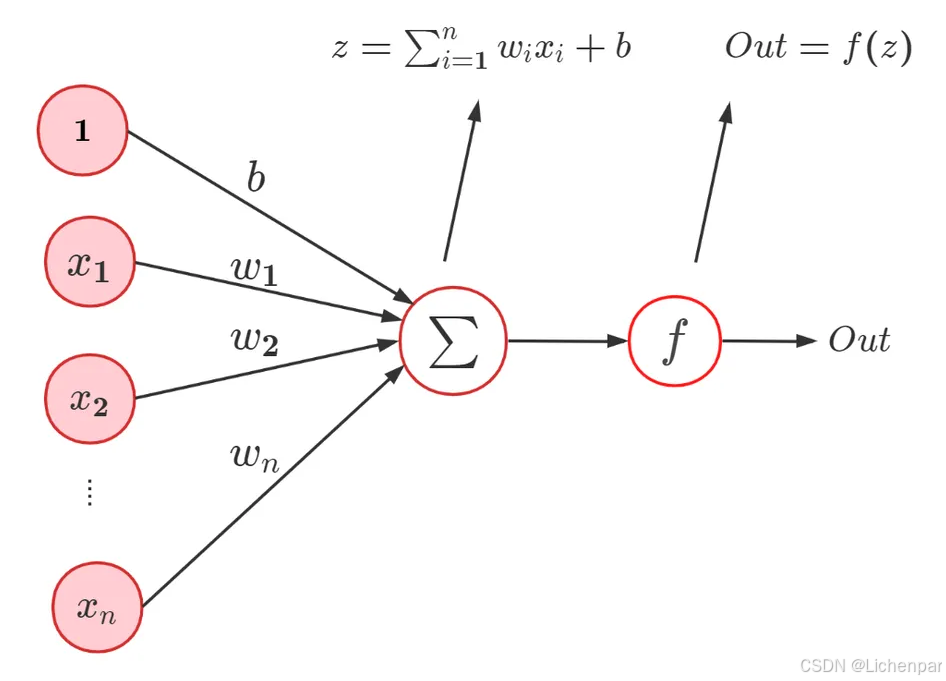
其公式可以用矩阵的形式总结为:Out=f(xw+b)Out = f(xw+b)Out=f(xw+b)
- xwxwxw的意思就是矩阵x[x1,x2...xn]x[x_{1},x_{2}...x_{n}]x[x1,x2...xn]乘以矩阵w[w1,w2...wn]w[w_{1},w_{2}...w_{n}]w[w1,w2...wn],矩阵乘法的计算方法就是左行乘以右列,因为都是1行n列,因此就是xnwnx_{n}w_{n}xnwn了。最终得到一个新的矩阵。
- fff是激活函数,那啥是激活函数呢?
- bbb是截距,有时也叫偏置(bias)
因为输出只有1个,因此也只能进行二分类。
二代神经网络(multilayer perceptron)
直译为多层感知器,包含输入层、隐藏层(至少1层,可以有多层,每层都跟着激活函数)、输出层。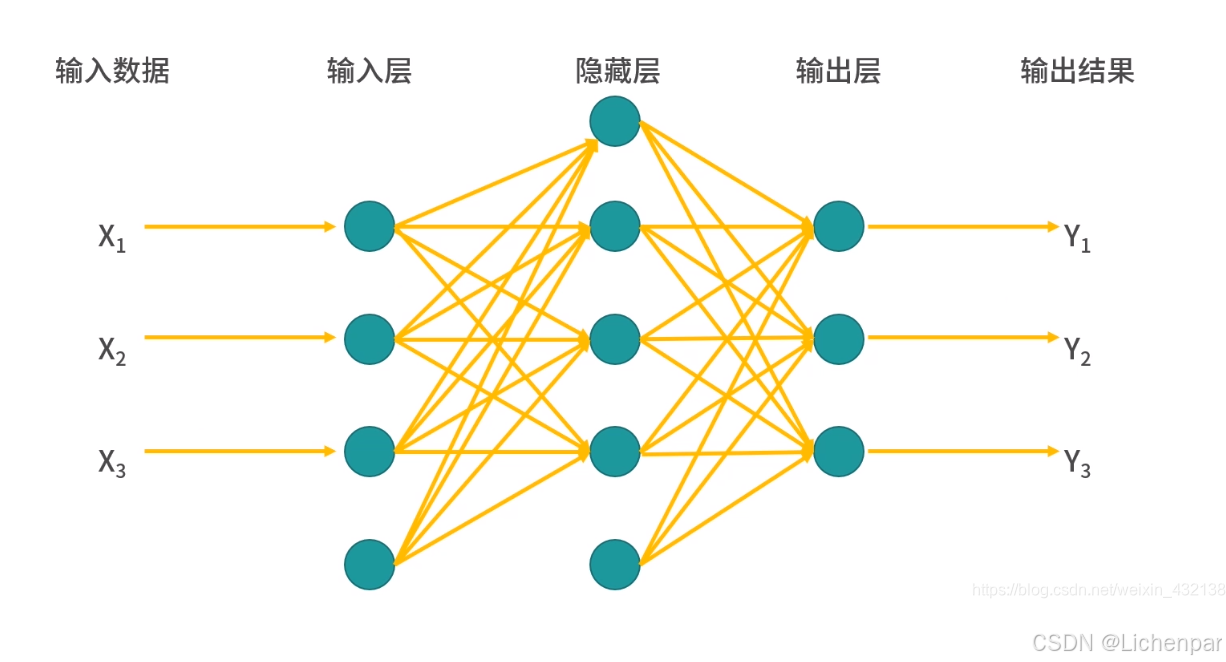
可以看出,它能够输出多个结果了。在第三天的代码实践过程中,已经体验了这一点,模型能够识别出0~9十个结果。
一个基础(单层隐藏层)的神经网络,从输入到输出的过程中,还包括了激活函数、Softmax、损失函数。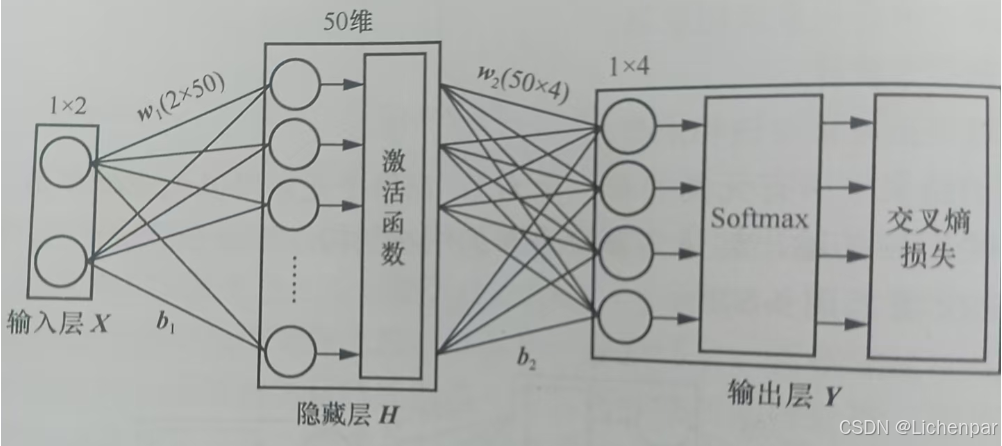
激活函数
神经网络如果没有激活函数,那它就只是一个线性模型。线性模型只能解决线性可分的问题,但现实生活中的问题大多是非线性的。激活函数给神经网络引入了非线性因素,使得神经网络能够解决更复杂、更现实的问题。
我略微懂得了一点其中的奥义,但是又没法表达清楚。可能学到后面会顿悟。
我当前的理解就是,激活函数有点类似于物理题目中的前提条件,例如“在忽略空气阻力的情况下”、“在忽略线路电阻的情况下”、“在光滑的平面上”。如果在解决问题的时候,你还需要考虑上一步测量出的空气阻力、线路电阻,那么你后续的解题步骤就会深陷进去,你就没有办法快刀斩乱麻,你就解不出从济南到莱芜走高速会用多长时间,因为你缺少一个激活函数去把你爆胎这样的概率给优化成0。
Softmax层
就是把输出内容转换成求和为1的概率值。
损失函数
简单的方法就是1减去Softmax层输出的概率。代表模型输出的不确定性。
反向传播(back propagation)
根据损失函数计算出的损失后,可以自动实现参数矩阵www和偏置bbb的优化。
反向传播本质上是指神经网络每层参数梯度的计算方法。具体来说,他就是利用符合函数求导的链式法则,逐层求出损失函数对各个神经元权重和偏置的偏导数。
导数(Derivative)是描述函数在某一点附近的变化率的概念。在几何上,导数表示函数图像在对应点处的切线斜率。在物理学中,导数常常表示某种物理量的瞬时变化率,如速度(位移对时间的导数)、加速度(速度对时间的导数)等。
偏导数(Partial Derivative)是多元函数相对于其某一个自变量求导的概念。偏导数在几何上表示函数图像在对应点处沿某一坐标轴方向的切线斜率。在物理学中,偏导数常用于描述多元函数在某一点处某一方向上的变化率。例如,在热力学中,温度对压力的偏导数可能表示在体积不变时,温度随压力的变化率。
支持向量机(SVM)
SVM 的目标是找到一个最优的超平面(在二维空间中为直线,三维空间中为平面,更高维度则为超平面),该超平面能够将数据集中的样本点按照类别尽可能分开。SVM 特别适用于处理高维数据,并且在处理非线性数据时,通过引入核函数(Kernel Function)可以有效地将输入数据映射到更高维的空间中,从而找到适合的非线性分界线。
下图就是最好的理解。神经网络的多个隐藏层的激活函数叠加,其实就是为了将问题归类。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)