人工智能图像识别应用基础(目标检测项目)
随着计算机技术的发展和计算机视觉原理的广泛应用,利用计算机图像处理技术对目标进行实时跟踪研究越来越热门,对目标进行动态实时跟踪定位在智能化交通系统、智能监控系统、军事目标检测及医学导航手术中手术器械定位等方面具有广泛的应用价值。人工智能技术在深度学习算法在计算机视觉领域的广泛应用,目标检测与识别技术在图像和视频中的精度和实时性也越来越高。越来越多的相关研究成果发表在各种人工智能、计算机视觉和模式识
一、概要
随着计算机技术的发展和计算机视觉原理的广泛应用,利用计算机图像处理技术对目标进行实时跟踪研究越来越热门,对目标进行动态实时跟踪定位在智能化交通系统、智能监控系统、军事目标检测及医学导航手术中手术器械定位等方面具有广泛的应用价值。
人工智能技术在深度学习算法在计算机视觉领域的广泛应用,目标检测与识别技术在图像和视频中的精度和实时性也越来越高。越来越多的相关研究成果发表在各种人工智能、计算机视觉和模式识别的顶级期刊和会议上,并且也有越来越多的计算机视觉初创公司将该技术应用到真实的场景中。在各种公开数据集上,目标检测与识别算法的水平不断攀升,算法性能也不断地接近人类甚至超越人类。
本文主要系统性地介绍了计算机视觉在目标检测与识别领域相关的基本知识、算法及应用。
二、目标检测(Object Detection)
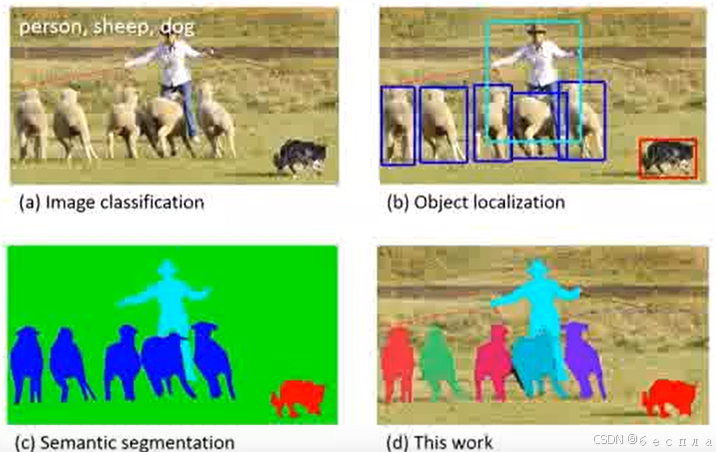
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。通俗的讲就是在一幅图像中精确地找到各种物体所在的位置,并标注出每个物体的类别。
计算机视觉中关于图像识别有四大类任务:
- 分类-Classification:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
- 定位-Location:解决“在哪里?”的问题,即定位出这个目标的的位置。
- 检测-Detection:解决“在哪里?是什么?”的问题,即定位出这个目标的位置并且知道目标物是什么。
- 分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标物或场景”的问题。
它可以解决 多任务问题(位置 + 类别)、目标种类与数量繁多的问题、目标尺度不均的问题、遮挡、噪声等外部环境干扰等问题。
二、目标检测的数据集
关于目标检测的数据集有以下四种,主要介绍前两种。
(一)、VOC数据集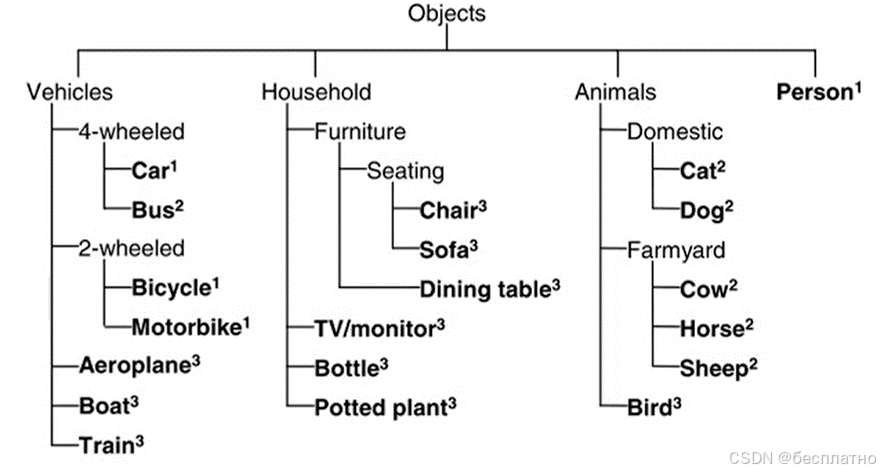
PASCAL VOC挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛,PASCAL全称:Pattern Analysis, Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。PASCAL VOC挑战赛主要包括以下几类:图像分类(Object Classification),目标检测(Object Detection),目标分割(Object Segmentation),行为识别(Action Classification) 等。
VOC数据集中主要包含20个目标类别,右图展示了所有类别的名称以及所属超类。
(二)、COCO数据集
MS COCO的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。
COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包括91类目标,328,000影像和2,500,000个label。目前为止有语义分割的最大数据集,提供的类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个,
平均每个图像的目标数是7.2。
(三)、Google Open Image
(四)、ImageNet
三、目标检测的Ground Truth
ground-truth是指在机器学习和数据分析领域中,用于表示真实的、准确的或者标准的数据或信息。它通常用作模型评估和性能度量的基准,以便与模型的预测结果进行比较。在监督学习任务中,around-tuth是由人工标注或者专家提供的正确答案或标,在无监督学习或者聚类任务中,ground-truth可能是一组已知的类别或者群组信息。通过与ground-truth进行比较,可以评估模型的准确性、召回率、精确度等性能指标。
(一)、YOLO(TXT)格式:(x,y,w,h)

YOLO (You Only Look Once) 是一种目标检测算法,它使用了一个单独的神经网络来同时识别图像中的多个对象。它可以支持一下多种的训练数据集的格式。其中YOLO数据集格式是非常常用的一种。
YOLO数据集的格式主要包括:图像文件、标注文件、类别文件。
x,y,w,h分别代表中心点坐标和宽、高,x,y,w,h均为归一化结果。
(二)、VOC(XML)格式:(Xmin,Ymin,Xmax,Ymax)
分别代表左上角和右下角的两个坐标。
(三)、COCO(JSON)格式:(Xmin, Ymin, W, H)
其中x,y,w,h均不是归一化后的数值,分别代表左上角坐标和宽、高。


三、目标检测的评估指标
IoU(Intersection over Union)(交并比)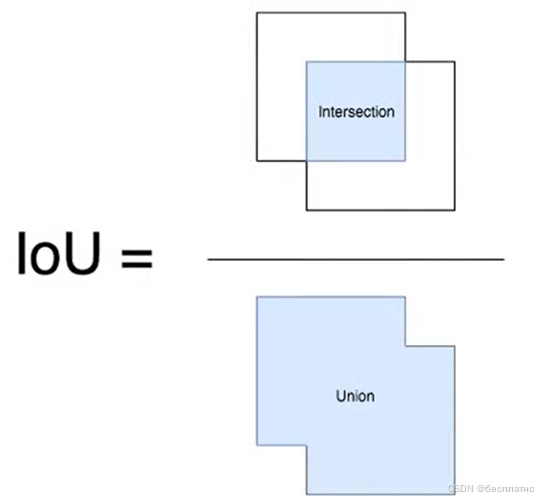
Intersection over Union是一种测量在特定数据集中检测相应物体准确度的一个标准,IoU是一个简单的测量标准,只要是在输出中得出一个预测范围(bounding boxex)的任务都可以用IoU来进行测量。为了可以使IoU用于测量任意大小形状的物体检测,我们需要:
- ground-truth bounding boxes(人为在训练集图像中标出要检测物体的大概范围);
- 我们的算法得出的结果范围。
也就是说,这个标准用于测量真实和预测之间的相关度,相关度越高,该值越高。
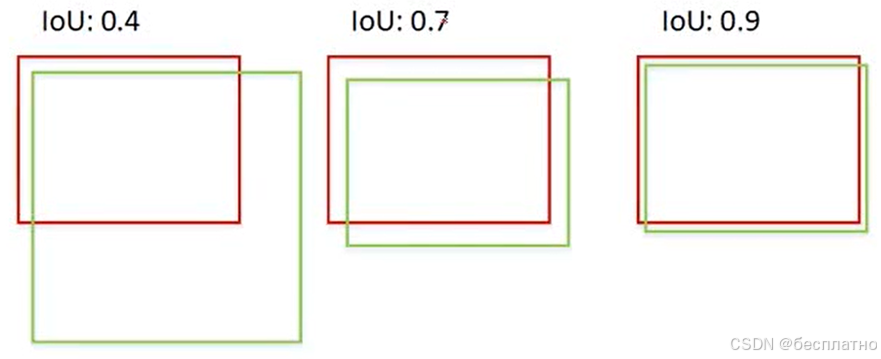
(一)、检测结果的类别
1、TP、FP、TN、FN
在机器学习中,评估模型性能的关键指标包括真正例(TP)、假正例(FP)、真负例(TN)和假负例(FN)。这些指标帮助我们理解模型在预测正类和负类时的准确性。
|
评价指标 |
解释 |
Ground Truth |
预测结果 |
目标检测中的解释 |
|
TP |
真的正样本 |
正样本 |
正样本 |
IoU>阈值 |
|
FP |
假的正样本 |
负样本 |
正样本 |
IoU<阈值 |
|
TN |
真的负样本 |
负样本 |
负样本 |
|
|
FN |
假的负样本 |
正样本 |
负样本 |
漏检目标 |
真正例(TP):真正例是模型正确预测为正类的实例数量。
假负例(FN):是模型错误地预测为负类的正类实例数量。
例如,在癌症检测中,TP是模型正确识别为癌症的病例,FN是模型未能识别的癌症病例。
假正例(FP):模型错误地预测为正类的负类实例数量。
真负例(TN):模型正确预测为负类的实例数量。
例如,在癌症检测的情境中,FP是被错误诊断为癌症的健康病例,而TN是被正确诊断为健康的病例。
也可以这样理解
| 负 | 正 | |
|---|---|---|
| 负 | 真负例(TN) | 真负例(FP) |
| 正 | 假负例(FN) | 真正例(TP) |
2、准确率(Precision)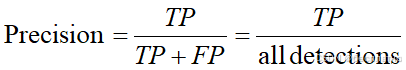
准确度 (Percision) 也叫查准率,是在识别出的物体中,正确的正向预测 (True Positive,TP) 所占的比率。
all detections表示一共识别出的物体数量。
3、召回率(Recall)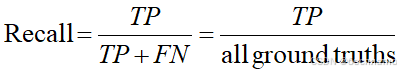
召回率 (Recall),是正确识别出的物体占总物体数的比率。
all ground truths表示一共有多少个需要检测的物体。
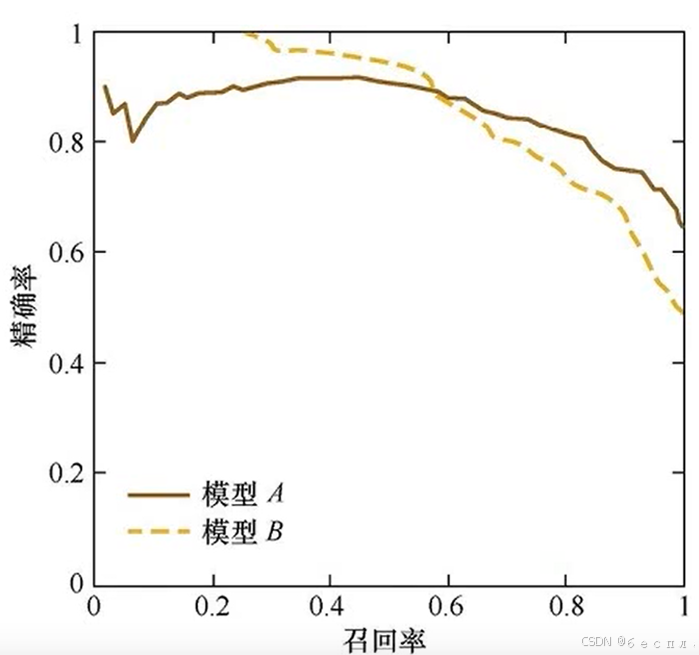
4、PR曲线
P-R曲线就是精确率(precision) vs 召回率(recall) 曲线,以recall作为横坐标轴,precision作为纵坐标轴。
算法对样本进行分类时,都会有置信度,即表示该样本是正样本的概率,比如99%的概率认为样本A是正例,1%的概率认为样本B是正例。通过选择合适的阈值,比如50%,对样本进行划分,概率大于50%的就认为是正例,小于50%的就是负例。
通过置信度就可以对所有样本进行排序,再逐个样本的选择阈值,在该样本之前的都属于正例,该样本之后的都属于负例。每一个样本作为划分阈值时,都可以计算对应的精确率(precision和召回率(recall),那么就可以以此绘制曲线。
5、mean与average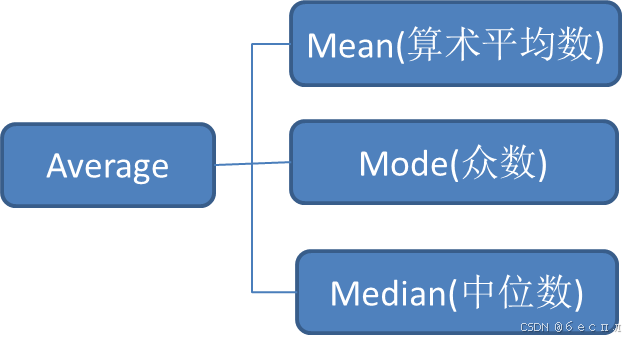
mAP:mean Average Precision,平均精度均值,即AP (Average Precision)的平均值,它是目标检测算法的主要评估指标。 目标检测模型通常会用速度和精度 (mAP)指标描述优劣,mAP值越高,表明该目标检测模型在给定的数据集上的检测效果越好。例如:
- mAP@50 :表示IoU为0.5时的平均精度(Average Precision)。
- mAP@50-95:表示IoU从0.5到0.95(步长为0.05)之间的平均精度,相对于mAP@50更加严格,通常用于更全面的评估。
其中各部分的意思为:
- mean:算数平均
- average:包含其他的度量指标
- Average P:P值需要设计度量规则让它均衡
- mean AP:AP够均衡了,直接mean即可
AP计算方法:11点法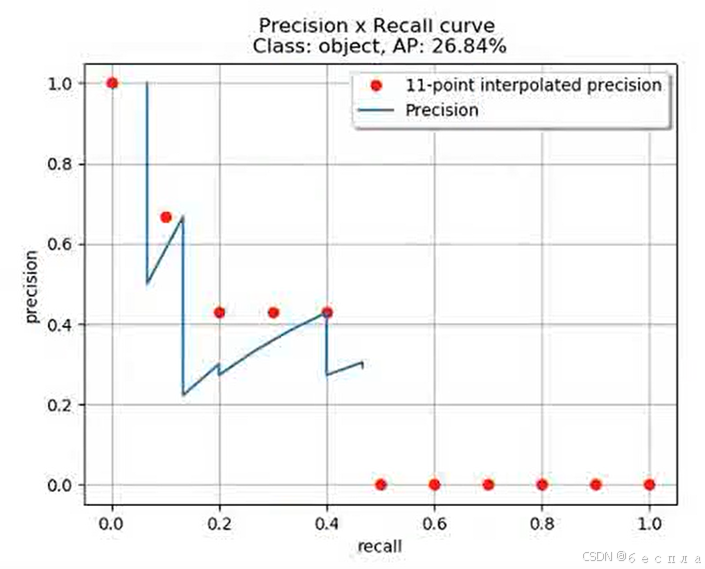
AP: Average Precision
以Recall为横轴,Precision为纵轴,就可以画出一条PR曲线,PR曲线下的面积就定义为AP。
但是我们对相对困难的曲线求出面积于是出现了11点法。选取当Recall >= 0, 0.1, 0.2, …, 1共11个点时的Precision最大值,AP是这11个Precision的平均值,此时只由11个点去近似PR曲线下面积。
计算公式如下图: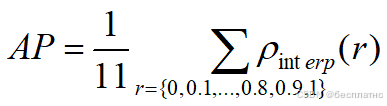
举个栗子:
右图是已经形成的PR曲线,我们需要求出下面的AP面积。
- R=[0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
- P=[1, 0.6666, 0.4285, 0.4285, 0.4285, 0, 0, 0, 0, 0, 0]
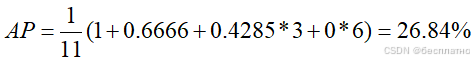
经过上面的介绍后接下来举个栗子更好的理解
(二)、栗子

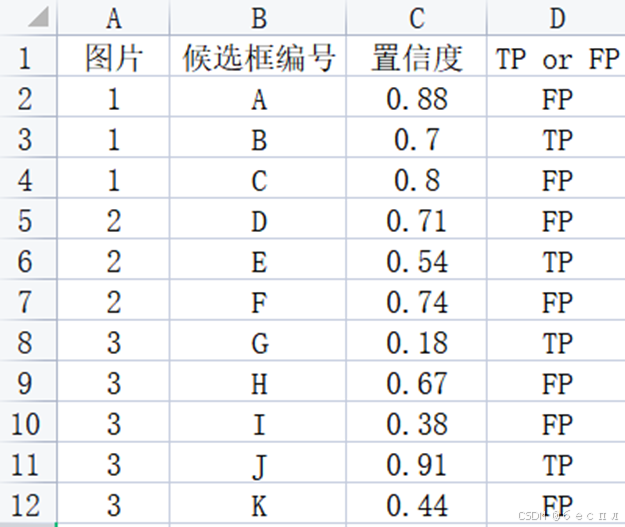
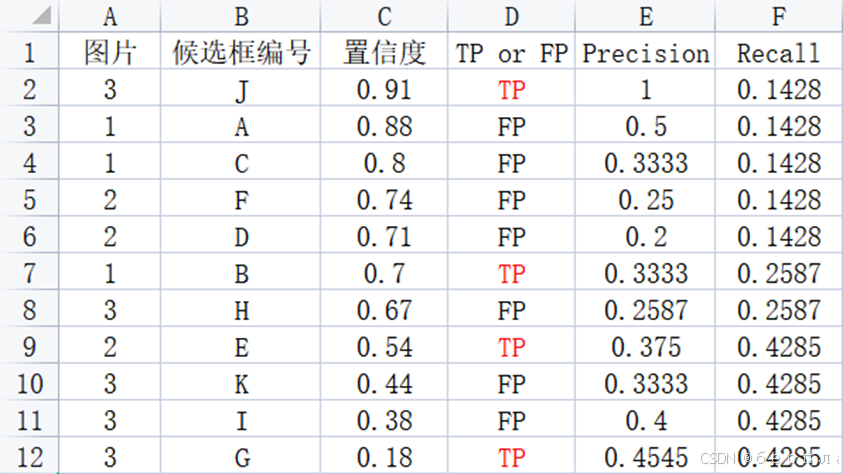
首先,根据IoU划分TP或者FP。按置信度的从大到小,计算P和R。其次,绘制P-R曲线,进行AP计算。
四、目标检测的传统方法
滑动窗口(Sliding Window)是一种在计算机视觉中常用的技术,用于在图像中定位目标物体。滑动窗口通过在图像上移动一个固定大小的矩形框,逐步扫描图像的每个区域,以检测目标物体的位置。


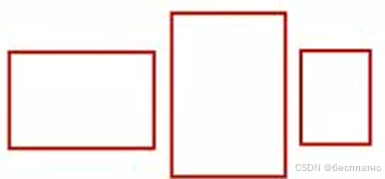
它的缺点就在于:
- 需要人工设计尺寸
- 大量冗余操作
- 定位不准确
五、目标检测的深度学习方法
(一)、anchor box(锚框)
以往的模型一个窗口只能预测一个目标,把窗口输入到分类网络中,最终得到一个预测概率,这个概率偏向哪个类别则把窗口内的目标预测为相应的类别,例如在红色框内回归得到的行人概率更大,则认为这个目标为行人。此外,在不同分辨率的特征图下检测不同尺寸的目标就大大的增加了计算量。
anchor boxes(锚框)的概念最初是在Faster R-CNN中提出,此后在SSD、YOLOv2、YOLOv3等优秀的目标识别模型中得到了广泛的应用。
anchor boxes(锚框)的主要作用是作为目标检测任务中的参考点。在处理图像时,算法会在每个像素点上生成多个不同大小和宽高比的锚框。这些锚框覆盖了图像的不同区域,以便检测出各种尺寸和形状的目标。为了提高检测的准确性,通常会在同一位置设置不同宽高比的锚框,同时保持面积不变。
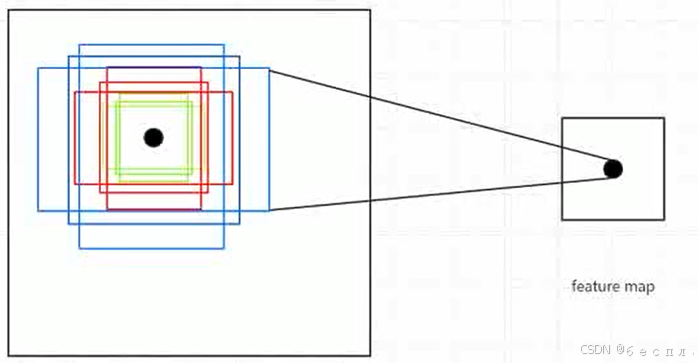
例如上图
anchor box用ratio+scale描述,以feature map的点来决定位置,scale来表示目标的大小(面积大小),aspect ratio来表示目标的形状(长宽比)就得到了下面的公式。
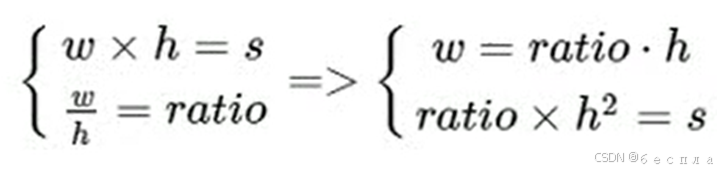
(二)、anchor-base和anchor-free
在过去,目标检测通常被建模为对候选框的分类和回归,不过,按照候选区域的产生方式不同,分为二阶段(two-step)检测和单阶段(one-step)检测,前者的候选框通过RPN(区域推荐网络)网络产生proposal,后者通在特定特征图上的每个位置产生不同大小和宽高比的先验框(anchor)。
anchor-base
Anchor-based 方法使用不同大小和形状的 anchor 框来回归和分类目标。例如,Faster R-CNN、RetinaNet 和 YOLO 等都是典型的 anchor-based 方法。这些方法通过在特征图的每个点生成多个不同大小和比例的候选框,覆盖几乎所有位置和尺度,然后通过计算这些候选框与真实目标框的重叠度(IoU)来确定正负样本。anchor-base是自顶向下的,类似于传统方法,滑动窗口法穷举出许多,然后再根据置信度之类的进行筛选。
框来回归和分类目标。例如,Faster R-CNN、RetinaNet 和 YOLO 等都是典型的 anchor-based 方法。这些方法通过在特征图的每个点生成多个不同大小和比例的候选框,覆盖几乎所有位置和尺度,然后通过计算这些候选框与真实目标框的重叠度(IoU)来确定正负样本。anchor-base是自顶向下的,类似于传统方法,滑动窗口法穷举出许多,然后再根据置信度之类的进行筛选。
优缺点:
- anchor based的优点:可以产生密集的anchor box,使得网络可以直接进行目标分类和边界框回归,提高了目标召回能力,尤其对小目标检测有明显的提升。
- anchor based的缺点:需要设定很多超参数,如尺度、长宽比等,这些参数很难设计,并且会影响检测性能。另外,anchor based的方法也会产生很多冗余的框,增加了计算量和内存消耗。
anchor-free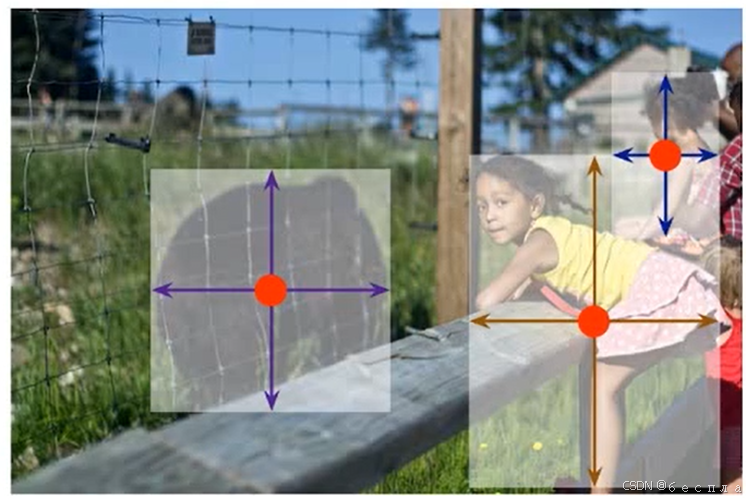
anchor-free方法主要分为 基于密集预测 和 基于关键点估计两种。anchor-free是自底向上的,想办法自动生成,不穷举free掉了anchor的预设过程。
优缺点:
- anchor free的优点:不需要预设anchor,只需要对不同尺度的特征图的目标中心点和宽高进行回归,减少了耗时和算力。同时,anchor free的方法也可以避免一些由于anchor设置不合理导致的漏检或重复检测问题。
- anchor free的缺点:由于每个位置只预测一个框,可能会导致一些重叠或遮挡区域无法被检测到。另外,anchor free的方法也需要一些特殊的损失函数或结构来提高精度和稳定性。
(三)、two stage(二阶段检测)
先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类。
对于Two-stage的目标检测网络,主要通过一个卷积神经网络来完成目标检测过程,其提取的是CNN卷积特征,在训练网络时,其主要训练两个部分,第一步是训练RPN网络,第二步是训练目标区域检测的网络。网络的准确度高、速度相对One-stage慢。

常见two stage算法:
- 经典发展线:R-CNN、SPP-Net、Fast R-CNN、 Faster R-CNN
- 其他:Cascade R-CNN、Guided Anchoring
(四)、one stage(单阶段检测)
直接回归物体的类别概率和位置坐标值(无region proposal),但准确度低,速度相遇two-stage快。
直接通过主干网络给出类别和位置信息,没有使用RPN网路。这样的算法速度更快,但是精度相对Two-stage目标检测网络略低。
常见one stage算法:
- YOLO系列:YOLO v1-v5
- SSD系列:SSD、DSSD、FSSD
- 其他经典:RefineDet
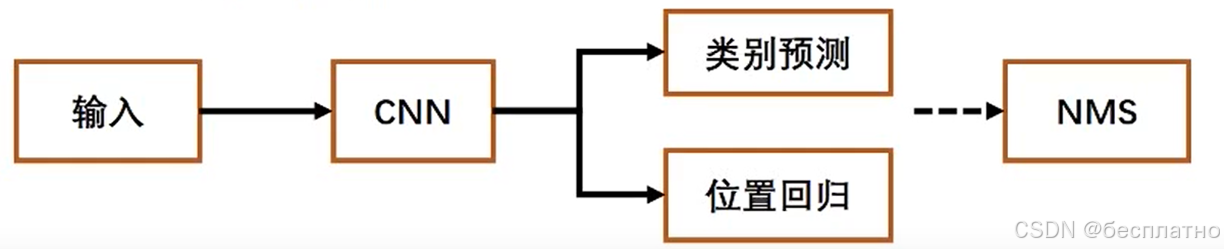
(五)、非极大值抑制(Non-maximum suppression,NMS)
算法的用处:找到局部极大值,并筛除(抑制)邻域内其余的值。
在训练过程中,目标检测算法会根据给定的ground truth调整深度学习网络参数来拟合数据集的目标特征,训练完成后,神经网络的参数固定,因而能够直接对新的图像进行目标预测。
然而,在实际的目标预测中,一般的目标检测算法(R-CNN,YOLO等等)都会产生非常多的目标框,其中有很多重复的框定位到同一个目标,NMS作为目标检测的最后一步,用来去除这些重复的框,获得真正的目标框。
例如右图:设定目标框的置信度阈值,常用的阈值是0.5左右根据置信度降序排列候选框列表选取置信度最高的框A添到输出列表,将其从候选框列表删除候选框列表中的所有框依次与A计算IoU,删除大于阈值的候选框重复上述过程,直到候选框列表为空,返回输出列表。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)