2.24~2.25notes on ai and CXL
透视投影是中心投影,模拟人眼或相机的成像原理,投影线从视点(相机位置)发散,物体投影后呈现近大远小效果,平行线可能交汇于消失点。
graph:所属的计算图input:输入张量output:输出张量(转置后的结果)permute:维度排列顺序(如[2,0,1]表示将原维度2放到第一个位置)
转置算子(Transpose)
auto rank = input->getRank();
if (permute.empty()) { // 默认情况:不改变维度顺序
for (size_t i = 0; i < rank; ++i) {
transposePermute[i] = i;
}
} else { // 用户指定permute参数
IT_ASSERT(rank == permute.size());
transposePermute = std::move(permute);
}功能:
- 形状推导:根据输入张量的形状和permute参数,推导输出张量的形状
- 返回:包含输出形状的
optional对象(当前返回nullopt需要实现
包括UnaryObj、ClipObj和CastObj三个类,分别对应一元操作、裁剪操作和类型转换操作。
首先看UnaryObj类。它继承自OperatorObj,构造函数接受操作类型、计算图、输入张量和输出张量。inferShape方法返回输入张量的形状,说明一元操作不改变张量的形状,比如ReLU或Sigmoid这样的激活函数。toString方法用于生成可读的字符串,方便调试和日志记录。
接下来是ClipObj类,同样继承自OperatorObj。构造函数中多了min和max参数,用于限制张量值的范围。inferShape方法需要返回裁剪后的形状,但目前返回的是nullopt,用户需要根据ONNX的规范实现,返回输入张量的形状,因为裁剪操作不改变形状,只改变数值范围。toString方法和UnaryObj类似,记录操作的信息。
然后是CastObj类,处理数据类型转换。构造函数接受一个CastType参数,指定转换的类型。inferDataType方法需要返回输出张量的数据类型,这里用户需要根据CastType来确定,比如Float32转Int32。inferShape方法同样需要实现,返回输入张量的形状,因为类型转换不改变形状。此外,getOutputDataType方法通过switch-case结构,根据不同的CastType返回对应的目标数据类型。
Concat是将多个张量沿着指定的维度(dim)进行拼接。例如,如果有两个形状为[2,3]的张量,在dim=1上拼接,结果应该是[2,6]。所有其他维度必须相同,只有指定的维度可以不同,并且在拼接时将这些值相加。
首先检查所有输入张量的维度是否在其他维度上相同,除了指定的dim维度。然后,将各输入张量在dim维度上的大小相加,得到输出张量的dim维度的大小,其他维度保持不变。
- 获取第一个输入张量的形状作为基准。
- 遍历所有其他输入张量,检查它们的维度是否在非dim维度上与基准一致。
- 如果检查通过,将所有输入在dim维度上的大小相加,得到新的dim大小。
- 构造新的形状,替换基准形状中的dim维度为总和。
ONNX(Open Neural Network Exchange,开放神经网络交换)是一种用于表示深度学习模型的开放标准文件格式,旨在解决不同深度学习框架之间的模型互操作性问题,简化模型的迁移、优化和部署流程
- 跨框架模型转换:ONNX 提供了一种统一的中间格式,允许用户将 PyTorch、TensorFlow、MXNet 等框架训练的模型转换为 ONNX 格式,并在其他支持 ONNX 的推理引擎(如 TensorRT、ONNX Runtime、OpenVINO)中部署
1
3
6
。 - 标准化存储:ONNX 文件(.onnx)不仅存储模型权重,还包含网络结构、节点操作、输入输出信息等,通过 Protobuf 协议序列化存储,确保跨平台兼容性
| 函数 | 输入 | 输出 | 用途 |
|---|---|---|---|
infer_broadcast |
两个张量形状 | 广播后的形状 | 形状推断 |
get_real_axis |
轴索引 + 维度数 | 标准化后的轴索引 | 轴处理 |
locate_index |
线性索引 + 形状 | 多维索引 | 内存访问计算 |
delocate_index |
多维索引 + 形状 + 步长 | 线性索引 | 内存访问计算(支持广播) |
device_to_str |
设备枚举 | 设备名称字符串 | 调试信息生成 |
get_kernel_attrs_str |
内核属性 | 格式化字符串 | 内核信息展示 |
在PyTorch或NumPy中,广播是一种自动扩展数组或张量维度以进行元素级操作的机制。例如,当两个张量形状不同时,较小的张量会被扩展(复制)以匹配较大的形状,而无需显式复制数据。通常,广播是单向的,即较小的张量向较大的张量对齐。
常规广播是单向的,即小数组扩展到大数组的形状
而是双方在各自不足的维度上进行调整。例如,张量A形状为(3,1),张量B形状为(1,4),双向广播后变为(3,4),两者在对应的维度上分别扩展
轴标准化 get_real_axis
Cpp
int get_real_axis(const int &axis, const int &rank) { IT_ASSERT(rank >= 1); IT_ASSERT(axis >= -rank && axis <= (rank - 1)); return (axis < 0) ? (rank + axis) : axis; }
功能
- 将负数轴转换为正数索引(如
axis = -1→rank - 1) - 校验:轴必须在
[-rank, rank-1]范围内
想知道一个矩阵的维度是几维的,只需要看开头有几个“[”,有1个即为1维,上面的两个就是两维,后面举到的三维和四维的例子,分别是有三个“[”、四个“[”的。
a =
[[[ 1. 2. 3.]
[ 4. 5. 6.]]
[[ 7. 8. 9.]
[10. 11. 12.]]]
b =
[[[ 1. 2.]
[ 3. 4.]
[ 5. 6.]]
[[ 7. 8.]
[ 9. 10.]
[11. 12.]]]a可以表示成2个shape=[2,3]的矩阵,b可以表示成2个shape=[3,2]的矩阵,前面的额表示的是矩阵排列情况。
计算的时候把a的第一个shape=[2,3]的矩阵和b的第一个shape=[3,2]的矩阵相乘,得到的shape=[2,2],即
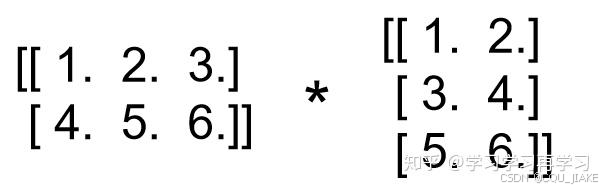
同理,再把a,b个字的第二个shape=[2,3]的矩阵相乘,得到的shape=[2,2]
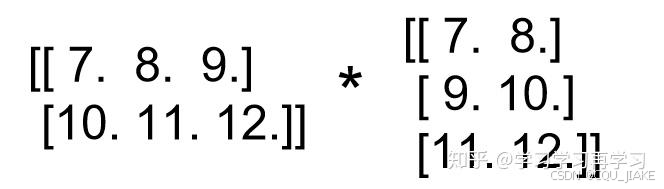
最终把结果堆叠在一起,就是2个shape=[2,2]的矩阵堆叠在一起,结果为:
[[[ 22. 28.]
[ 49. 64.]]
[[220. 244.]
[301. 334.]]]也就是shape=[2,2,3]和shape=[2,3,2]矩阵相乘,最后答案的shape为:把第一维表示矩阵排情况的2,直接保留作为结果的第一维,再把后面两维的通过矩阵运算,得到shape=[2,2]的矩阵,合起来结果shape=[2,2,2]。
四维的同理!拆成多个三维矩阵来运算即可!!
需要注意的是,四维中,前两维是矩阵排列,相乘的话保留前的最大值。
比如a:shape=[2,1,4,5],b:shape=[1,1,5,4]相乘,输出的结果中,前两维保留的是[2,1],最终结果shape=[2,1,4,4]
正交投影,根据搜索结果,属于平行投影的一种,投影线垂直于投影面,物体不会因为距离远近而改变大小,保持平行性和比例
正交投影和透视投影是两种将三维空间映射到二维平面的几何变换方法,其核心区别在于是否模拟人眼的近大远小效果
正交投影是一种平行投影方式,投影线垂直于投影平面,所有物体在投影后保持原始比例和平行性,不会因距离远近而改变大小或形状
视景体:使用长方体定义可视范围(近截面、远截面、左右上下边界),投影后所有物体被压缩到标准立方体([-1,1]³)
定义:透视投影是中心投影,模拟人眼或相机的成像原理,投影线从视点(相机位置)发散,物体投影后呈现近大远小效果,平行线可能交汇于消失点
视景体:以视点为顶点的截头四棱锥(Frustum)定义可视范围,包含近截面和远截面,投影后物体被压缩为长方体再进行正交投影
数学变换:核心是“挤压”变换矩阵,通过相似三角形原理将视锥体转换为长方体,保留深度信息(z值)用于遮挡检测
| 特征 | 正交投影 | 透视投影 |
|---|---|---|
| 投影方式 | 平行投影,投影线垂直 | 中心投影,投影线发散 |
| 比例变化 | 物体大小与距离无关 | 近大远小 |
| 平行线处理 | 保持平行性 | 可能交汇于消失点 |
| 视景体形状 | 长方体 | 截头四棱锥(Frustum) |
| 深度信息保留 | 仅用于标准化,不参与后续渲染 | 保留z值用于深度测试 |
视景体是三维空间中所有可见物体的集合,通常由近裁剪平面、远裁剪平面和侧向边界共同围成的一个几何体。它决定了场景中哪些物体需要被渲染,哪些需要被裁剪(不可见)
- 遍历所有的matmul操作符,检查其输入是否来自transpose操作符。
- 对于每个输入,查看是否存在相邻的transpose操作符,并且该transpose是否作用于最后两个维度。
- 如果有,调整matmul的transA或transB属性,并将该transpose操作符从图中移除,同时更新连接
利用CXL交换机将加速器与存储和内存设备分离,以解决CSD和CM面临的大规模生产问题。接下来是引言部分,传统数据处理存在性能瓶颈和能耗问题,NDP通过近数据处理来解决,分为PIM和ISP。CSD作为ISP的例子,但集成硬件加速器面临功耗和适应性挑战,导致难以大规模生产。随着CXL的出现,CM可能面临类似问题,因此作者提出解耦架构。
在第二部分,比较了CSD和CM的区别与相似之处。CSD侧重于存储优化,使用PCIe和闪存,而CM专注于内存扩展,使用CXL和DRAM。两者的相似点包括主机接口、加速器集成、控制器设计和DRAM的使用
- 传统架构中数据需从存储设备传输到主机内存处理,导致性能瓶颈(占Google消费级应用62.7%的能耗)。
- 近数据处理(NDP)通过存储内处理(ISP)和内存内处理(PIM)缓解此问题,但现有方案存在局限性
| 维度 | CSD | CM |
|---|---|---|
| 技术目标 | 存储优化 | 内存扩展 |
| 互联技术 | PCIe/NVMe | CXL |
| 存储介质 | 闪存(非易失性) | DRAM(易失性) |
| 控制器功能 | 闪存管理 | 内存一致性维护 |
| 适用场景 | IO密集型(如数据库) | 内存密集型(如AI训练) |
- 使用高速接口(PCIe/CXL)与主机通信。
- 集成加速器(压缩、加密等)卸载主机计算。
- 基于控制器的设计管理数据流与任务调度。
- 依赖DRAM作为缓存(CSD)或主存(CM)
近数据处理(NDP, Near-Data Processing) 是一种通过将计算任务迁移到数据存储或内存附近执行的架构范式,旨在减少数据在存储/内存与主机CPU之间的传输开销,从而提升性能和能效。其核心思想是“让计算靠近数据,而非数据靠近计算”。
ASIC(Application-Specific Integrated Circuit) 是一种专为特定任务或应用定制的集成电路。与通用处理器(如CPU、GPU)不同,ASIC的设计目标是通过硬件层面的深度优化,在特定场景下实现极高性能和能效
-
硬件级定制化
- ASIC的电路结构和逻辑完全针对目标任务设计,去除通用计算中不必要的模块(如指令解码、多任务调度),直接优化数据路径和计算单元。
- 示例:比特币矿机中的ASIC仅保留哈希计算相关电路,效率远超通用CPU/GPU
为什么ASIC缺乏灵活性?
-
硬件固化,无法重构
- ASIC的电路一旦流片生产,功能即固定,无法通过软件升级或重新编程以适应新任务。
- 对比:FPGA可通过配置逻辑单元实现不同功能,但效率通常低于ASIC。
-
开发成本高
- ASIC设计需要高昂的研发费用和制造周期(通常需6-18个月),仅适合需求稳定、规模化的场景。
- 示例:若某算法更新,ASIC可能需要重新设计,而FPGA只需更新配置文件
| 芯片类型 | 灵活性 | 效率 | 典型场景 |
|---|---|---|---|
| CPU | 极高(通用计算) | 低(多任务开销大) | 通用计算、操作系统 |
| GPU | 高(支持并行编程) | 中高(并行计算优化) | 图形渲染、AI训练 |
| FPGA | 中(硬件可编程) | 中(依赖配置效率) | 原型验证、灵活加速 |
| ASIC | 低(功能固化) | 极高(深度定制) | 挖矿、TPU、5G基带 |
CM,即计算内存,应该是指在内存(如DRAM)中集成计算能力,直接在数据存储的位置进行处理,减少数据传输的需要。而CSD,计算存储驱动器,可能是在存储设备(如SSD)中集成计算单元,允许在存储设备内部处理数据,而不是将数据传输到CPU进行处理
共同点:NDP的核心理念
- 减少数据移动:均通过将计算下沉到数据所在位置(内存或存储),避免传统架构中“数据→CPU→数据”的冗余传输。
- 硬件加速器集成:依赖专用硬件(如ASIC、FPGA)加速特定任务(如矩阵运算、压缩/加密)。
- 接口高速化:
- CM使用CXL(低延迟、高带宽内存协议)。
- CSD使用PCIe/NVMe(高速存储接口)。
- 面临相似挑战:
- 反大规模生产问题:定制化加速器导致开发成本高、灵活性不足(如ASIC固化功能,FPGA效率低)。
- 性能与功耗平衡:需匹配接口带宽(如CXL的64GB/s)同时控制功耗。
| 维度 | CM | CSD |
|---|---|---|
| 数据位置 | 处理易失性数据(DRAM中临时存储)。 | 处理非易失性数据(闪存中长期存储)。 |
| 计算粒度 | 细粒度、低延迟计算(如AI推理的逐层处理)。 | 粗粒度、批量计算(如全表扫描、文件压缩)。 |
| 硬件设计重点 | 内存控制器优化、一致性协议(如CXL.cache/mem)。 | 闪存管理(FTL)、I/O调度与耐久性优化。 |
| 典型产品 | SK海力士GDDR6-AiM、三星HBM-PIM。 | 三星SmartSSD、ScaleFlux可计算SSD。 |
基于CXL的解耦架构,通过共享加速器池,将CM与CSD整合为统一的数据处理平台,实现以下协同:
- 资源共享:
- CM和CSD可共享同一组加速器(如压缩引擎、AI加速器),避免重复开发。
- 加速器按需分配,提升利用率(如CM处理AI推理时调用NPU,CSD处理压缩时调用ASIC)。
- 统一互联:
- CXL交换机同时连接内存(CM)和存储(CSD),打破传统存储(PCIe)与内存(DDR)的协议壁垒。
- 灵活扩展:
- 独立扩展存储容量(CSD)或内存容量(CM),按负载需求动态调整。
- 联合优化:
- 数据在CM与CSD之间可通过CXL直接交换(如中间结果暂存于CM,最终持久化到CSD),减少主机介入。
[主机CPU+DRAM]
│
├─CXL交换机─┬─[CM模块1]:CXL内存 + 加速器A(如AI推理)
│ ├─[CM模块2]:CXL内存 + 加速器B(如加密)
│ ├─[CSD1]:NVMe SSD + 加速器C(如压缩)
│ └─[CSD2]:NVMe SSD + 加速器D(如数据库过滤)
内存密集型(Memory-Intensive)
定义
任务性能主要受限于内存访问速度或容量,需要频繁读写内存中的数据,且计算过程中对内存带宽、延迟或容量要求极高。
核心特征
- 高内存占用:需要大量内存空间存储中间数据(如大型矩阵、图结构)。
- 频繁内存访问:计算过程中反复读写内存(如遍历数组、矩阵乘法)。
- 低计算/内存比:单位数据所需的计算量较小,但数据搬运开销大。
性能瓶颈
- 内存带宽:数据吞吐速度无法满足计算需求。
- 内存延迟:等待数据从内存传输到CPU的时间过长。
- 内存容量不足:导致频繁换页(Swap)或OOM(内存溢出)
典型场景
- AI模型训练:如训练神经网络时需要加载数十GB的参数和梯度数据。
- 科学计算:如流体力学仿真中处理三维网格数据。
- 实时数据分析:如内存数据库(Redis)处理高并发查询。
- 图计算:如社交网络关系遍历(广度优先搜索)。
任务性能主要受限于输入输出(I/O)操作的速度或吞吐量,需要频繁与存储设备(磁盘、SSD)或网络交换数据。
核心特征
- 高I/O频率:大量读写请求(如日志记录、文件传输)。
- 大数据量传输:需要从存储设备加载数据到内存,或持久化计算结果。
- 低计算/I/O比:单位数据计算简单,但I/O等待时间占主导。
性能瓶颈
- 存储设备速度:机械硬盘寻道时间、SSD写入耐久性限制。
- I/O协议延迟:如NVMe命令排队深度不足、网络传输延迟(RTT)。
- 系统调用开销:频繁的read/write系统调用导致上下文切换。
典型场景
- 数据库服务:如MySQL执行全表扫描或批量插入。
- 视频流处理:如实时转码并保存高清视频流。
- Web服务器:高并发下处理HTTP请求与响应。
- 大数据ETL:从存储系统(如HDFS)提取并转换数据。
优化方向
- 升级存储硬件:使用NVMe SSD替代机械硬盘,提升IOPS和吞吐量。
- 减少I/O次数:通过批量读写、缓存(如Redis)或内存映射文件。
- 异步I/O与并行化:使用多线程、epoll或AIO(异步I/O)减少等待时间。
- 协议优化:采用RDMA(远程直接内存访问)或CXL加速存储访问。

NVMe(Non-Volatile Memory Express)驱动是操作系统内核中管理NVMe协议存储设备(如SSD)的软件模块,负责:
- 协议转换:将文件系统或应用程序的I/O请求(如
read/write)转换为NVMe命令(如Admin/SQ/CQ队列操作)。 - 硬件抽象:屏蔽不同厂商SSD的硬件差异,提供统一的块设备接口(如
/dev/nvme0n1)。 - 性能优化:管理多队列并行(如NVMe的IO队列配对)、中断处理、DMA数据传输等

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)