Iitel mac 旧版苹果系统 或者 黑苹果 运行本地大语言模型 启用GPU加速 不是Ollam 而是LLAMA 提供本地化api管理类似ollama的功能实现统一管理
故事背景:
起因:我只有一台电脑而且是黑苹果还是amd 5600xt这种老显卡。
我想在本地运行ollama大模型做下翻译等,发现一个问题,无论怎么使用
ollama 就是加其他配置比如 MPS_DEVICE=1 METAL_DEVICE=1 ollama serve 这样用mps
和metal 给加速依然不行
GPU基本不动的
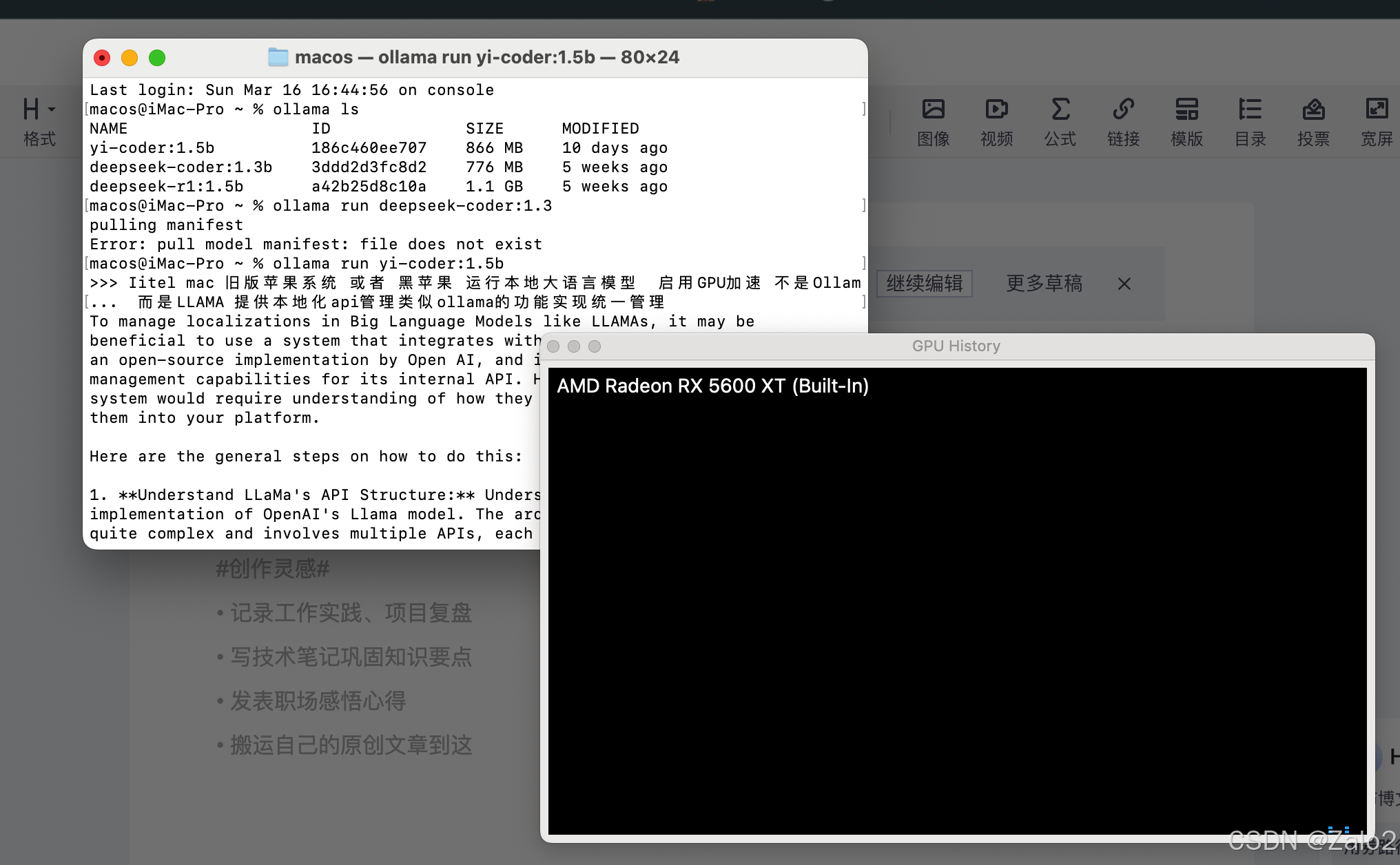
关于苹果系统GPU的问题:
macGPU 无论是m系列还是intel还是黑苹果 都是用metal后端去访问mps地层实现内存管理的
opencl是被放弃的后端 一开始我以为rocm(amd的开源后端访问GPU抄袭cuda的应用)是可以用在苹果或者Windows 其实人家只支持linux 其他平台调用远古amdGPu请看我其他文章。
实现步骤:
原理:利用LLAMA而不是ollama作为api,然后通过脚本统一管理或者程序
安装和编译LLAMA
环境准备
1. 操作系统要求:
• 建议 macOS 版本 ≥ 12.3,因为 MPS(Metal Performance Shaders)的功能和优化在该版本之后才比较完善。
2. 安装 Xcode 命令行工具:
• 打开终端,执行以下命令安装 Xcode 的命令行工具(如果尚未安装):
xcode-select --install或者通过appstore 安装,免费的,可能需要安装xcode 命令行工具会提示的系统。比较大xcode

• 安装完成后,您将拥有 Clang 编译器和 CMake 等必要工具。
3. (可选)安装 Homebrew:
如果您需要安装其他依赖或工具,建议先安装 Homebrew。安装命令如下:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"Homebrew 安装后可以方便安装一些辅助工具,但本次编译主要依赖 Xcode 自带工具。
llama的编译不需要python虚拟环境,根本不需要python,运行也不需要如果你打算只用命令行
llama的编译是基本xcode自带的c语言模块编译的
1. 克隆仓库:
git clone https://github.com/ggerganov/llama.cpp.git文件是下载到主目录
cd llama.cpp创建单独的构建目录
mkdir build
cd build运行 CMake 配置项目
使用 CMake 来生成 Makefile,并通过 -DLLAMA_METAL=ON 选项启用对 Metal(MPS)的支持。
cmake .. -DLLAMA_METAL=ON使用 Make 工具进行编译:
在 build目录下执行:
make -j4编译完成后,在 build 目录下应该可以看到
llama-server就是重要的api工具
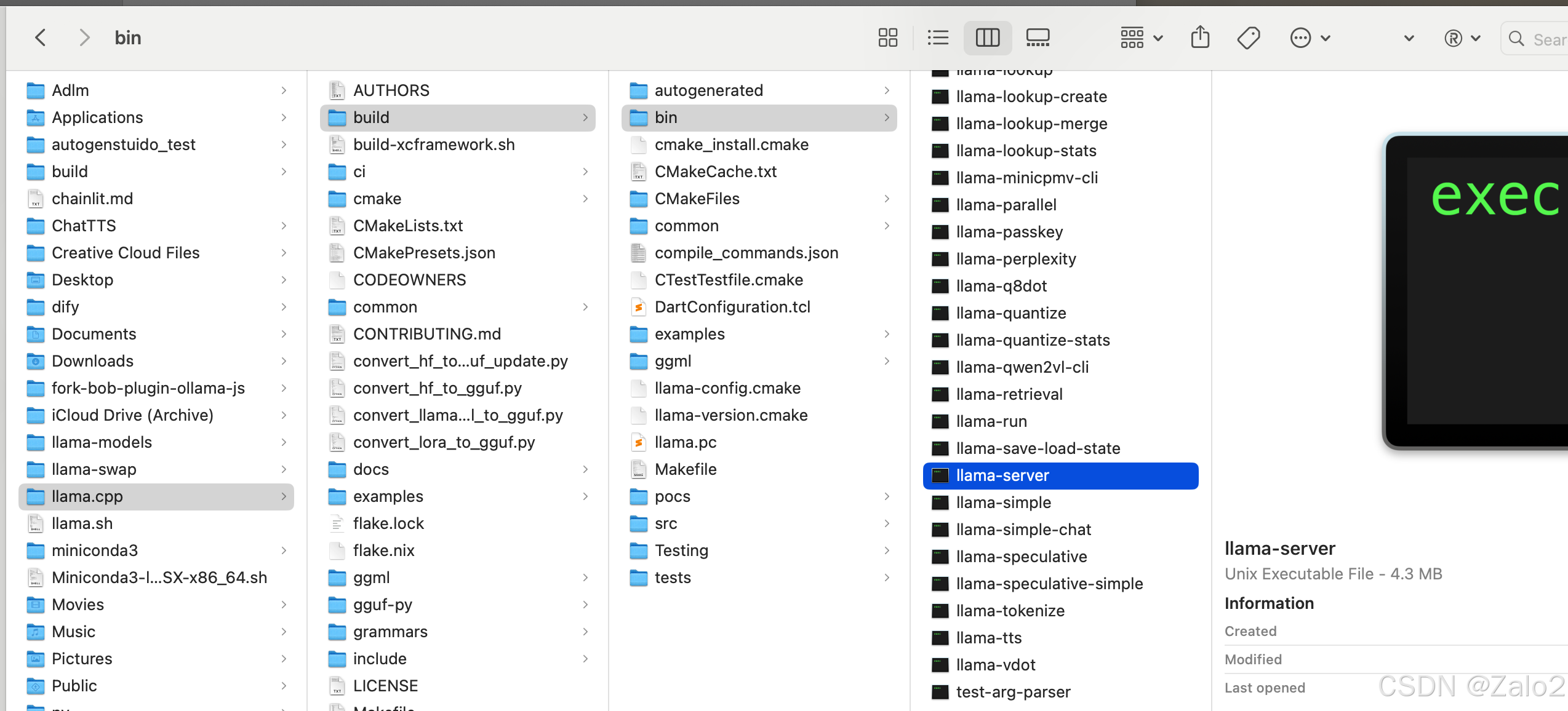
如果只要命令行运行参考官方文件:
https://github.com/ggml-org/llama.cpp
需要api集中管理的继续
有很多办法,这里只给两个,如果想自己封装llama 提供api可以参考后面的文件我不会
方法一用现成的:
https://github.com/mostlygeek/llama-swap/releases
下载
llama-swap_96_darwin_amd64.tar.gz
把llama-swap放到Source code(zip) (Source code解压到主目录且重命名llama-swap
/Users/macos/llama-swap/llama-swap
config.example.yaml改成config.yaml
修改model部分:
llama用gguf格式,不是这个格式就用llama目录下的转换工具或者下载对应的
聊天模型,注意是聊天模型我这里就下了一个base模型
加自己的模型 同上模型要放在
/Users/macos/llama-swap/models
只需要注意
llama这个是模型名称自定义也是调用的名称
/Users/macos/llama.cpp/build/bin/llama-server这个是路径上文提到的
-m models/llama-2-7b.Q4_0.gguf这个是命令
其他的不管
# Seconds to wait for llama.cpp to be available to serve requests
# Default (and minimum): 15 seconds
healthCheckTimeout: 15
# Log HTTP requests helpful for troubleshoot, defaults to False
logRequests: true
models:
"llama":
cmd: >
/Users/macos/llama.cpp/build/bin/llama-server
--port 9001
-m models/llama-2-7b.Q4_0.gguf
proxy: http://127.0.0.1:9001
# list of model name aliases this llama.cpp instance can serve
aliases:
- gpt-4o-mini
# check this path for a HTTP 200 response for the server to be ready
checkEndpoint: /health
# unload model after 5 seconds
ttl: 5
"qwen":
cmd: /Users/macos/llama.cpp/build/bin/llama-server --port 9002 -m models/qwen2-0_5b-instruct-q3_k_m.gguf
proxy: http://127.0.0.1:9002
aliases:
- gpt-3.5-turbo
# Embedding example with Nomic
# https://huggingface.co/nomic-ai/nomic-embed-text-v1.5-GGUF
"nomic":
proxy: http://127.0.0.1:9005
cmd: >
models/llama-server-osx --port 9005
-m models/nomic-embed-text-v1.5.Q8_0.gguf
--ctx-size 8192
--batch-size 8192
--rope-scaling yarn
--rope-freq-scale 0.75
-ngl 99
--embeddings
# Reranking example with bge-reranker
# https://huggingface.co/gpustack/bge-reranker-v2-m3-GGUF
"bge-reranker":
proxy: http://127.0.0.1:9006
cmd: >
models/llama-server-osx --port 9006
-m models/bge-reranker-v2-m3-Q4_K_M.gguf
--ctx-size 8192
--reranking
# Docker Support (v26.1.4+ required!)
"dockertest":
proxy: "http://127.0.0.1:9790"
cmd: >
docker run --name dockertest
--init --rm -p 9790:8080 -v /mnt/nvme/models:/models
ghcr.io/ggerganov/llama.cpp:server
--model '/models/Qwen2.5-Coder-0.5B-Instruct-Q4_K_M.gguf'
"simple":
# example of setting environment variables
env:
- CUDA_VISIBLE_DEVICES=0,1
- env1=hello
cmd: build/simple-responder --port 8999
proxy: http://127.0.0.1:8999
unlisted: true
# use "none" to skip check. Caution this may cause some requests to fail
# until the upstream server is ready for traffic
checkEndpoint: none
# don't use these, just for testing if things are broken
"broken":
cmd: models/llama-server-osx --port 8999 -m models/doesnotexist.gguf
proxy: http://127.0.0.1:8999
unlisted: true
"broken_timeout":
cmd: models/llama-server-osx --port 8999 -m models/qwen2.5-0.5b-instruct-q8_0.gguf
proxy: http://127.0.0.1:9000
unlisted: true
# creating a coding profile with models for code generation and general questions
profiles:
coding:
- "qwen"
- "llama"运行
cd /Users/macos/llama-swap
/Users/macos/llama-swap/llama-swap -c /Users/macos/llama-swap/config.yaml
./llama-swap这样就启动了./llama-swap
然后进去
模型 ID写:你自己定义的名字比如我就是
llama
之后就可以去cherrystiudo这个软件聊天了
或者放到其他openai api调用去
方法二就是自己写一个sh文件如:(自己根据需要自行调整)
#!/bin/bash
# ===== 模型配置 =====
# 创建模型路径字典,方便后期添加更多模型
declare -A MODEL_PATHS
MODEL_PATHS["qwen"]="/Users/macos/llama-models/qwen2-0_5b-instruct-q3_k_m.gguf"
MODEL_PATHS["llama"]="/Users/macos/llama-models/llama-2-7b.Q4_0.gguf"
#后期模型添加
###后期运行模型比如./llama.sh --model deepseek整个文件只要改下面一天够了
#MODEL_PATHS["deepseek"]="/Users/macos/llama-models/deepseek-7b-chat.Q4_0.gguf"
# 设置 llama-server 可执行文件的路径
LLAMA_SERVER="/Users/macos/llama.cpp/build/bin/llama-server"
# ===== 默认参数 =====
# 设置默认服务器端口
DEFAULT_PORT=8080
# 设置默认使用的 GPU 层数
DEFAULT_GPU_LAYERS=20
# 设置默认上下文窗口大小
DEFAULT_CONTEXT_SIZE=2048
# ===== 帮助函数 =====
# 显示脚本的帮助信息和可用选项
show_help() {
# 显示使用方法
echo "使用方法: $0 [选项]"
# 显示可用选项列表
echo "选项:"
# 模型选择选项
echo -n " -m, --model <model> 选择模型: "
# 动态显示所有可用模型
echo "${!MODEL_PATHS[@]} (默认: qwen)"
# 端口设置选项
echo " -p, --port <port> 设置服务器端口 (默认: $DEFAULT_PORT)"
# GPU 层数设置选项
echo " -g, --gpu-layers <num> 设置 GPU 层数 (默认: $DEFAULT_GPU_LAYERS)"
# 上下文大小设置选项
echo " -c, --context <size> 设置上下文大小 (默认: $DEFAULT_CONTEXT_SIZE)"
# 帮助信息选项
echo " -h, --help 显示此帮助信息"
}
# ===== 参数初始化 =====
# 设置默认使用 qwen 模型
MODEL="qwen"
# 使用默认端口
PORT=$DEFAULT_PORT
# 使用默认 GPU 层数
GPU_LAYERS=$DEFAULT_GPU_LAYERS
# 使用默认上下文大小
CONTEXT_SIZE=$DEFAULT_CONTEXT_SIZE
# ===== 命令行参数解析 =====
# 循环处理所有命令行参数
while [[ $# -gt 0 ]]; do
# 根据当前参数进行匹配
case $1 in
# 处理模型选项
-m|--model)
# 设置模型为下一个参数
MODEL="$2"
# 跳过这两个已处理的参数
shift 2
;;
# 处理端口选项
-p|--port)
# 设置端口为下一个参数
PORT="$2"
# 跳过这两个已处理的参数
shift 2
;;
# 处理 GPU 层数选项
-g|--gpu-layers)
# 设置 GPU 层数为下一个参数
GPU_LAYERS="$2"
# 跳过这两个已处理的参数
shift 2
;;
# 处理上下文大小选项
-c|--context)
# 设置上下文大小为下一个参数
CONTEXT_SIZE="$2"
# 跳过这两个已处理的参数
shift 2
;;
# 处理帮助选项
-h|--help)
# 显示帮助信息
show_help
# 正常退出脚本
exit 0
;;
# 处理未知选项
*)
# 显示错误信息
echo "错误: 未知选项 $1"
# 显示帮助信息
show_help
# 异常退出脚本
exit 1
;;
esac
done
# ===== 模型选择 =====
# 根据用户选择的模型设置对应的模型路径
if [[ -n "${MODEL_PATHS[$MODEL]}" ]]; then
# 如果选择的模型存在于字典中,使用对应的路径
MODEL_PATH=${MODEL_PATHS[$MODEL]}
# 显示使用的模型信息
echo "使用 $MODEL 模型: $MODEL_PATH"
else
# 如果选择了未知模型,显示错误信息
echo "错误: 未知模型 '$MODEL'. 可用模型: ${!MODEL_PATHS[@]}"
# 异常退出脚本
exit 1
fi
# ===== 文件检查 =====
# 检查模型文件是否存在
if [[ ! -f "$MODEL_PATH" ]]; then
# 如果模型文件不存在,显示错误信息
echo "错误: 模型文件不存在: $MODEL_PATH"
# 异常退出脚本
exit 1
fi
# 检查服务器程序是否存在
if [[ ! -f "$LLAMA_SERVER" ]]; then
# 如果服务器程序不存在,显示错误信息
echo "错误: 服务器程序不存在: $LLAMA_SERVER"
# 异常退出脚本
exit 1
fi
# ===== 启动服务器 =====
# 显示启动信息,包括端口、GPU层数和上下文大小
echo "启动服务器,端口: $PORT, GPU层数: $GPU_LAYERS, 上下文大小: $CONTEXT_SIZE"
# 执行 llama-server 命令,启动服务器
"$LLAMA_SERVER" \
# 指定模型路径
-m "$MODEL_PATH" \
# 指定服务器端口
--port $PORT \
# 指定 GPU 层数
--n-gpu-layers $GPU_LAYERS \
# 指定上下文大小
--ctx-size $CONTEXT_SIZE
# 当服务器关闭时显示此信息
echo "服务器已关闭"自己根据需要进行选择,都是很简单的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 55
55 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)