Can Large Language Models Explore In-Context? 中文翻译版
我们发现,考虑的所有 LLM 配置中,除了一个,均表现出探索失败,未能以显著概率收敛于最佳臂。这种情况发生在以下两种情况中:一种是后缀失败,LLM 在少量初始轮次后从未选择最佳臂;另一种(较少出现)是均匀型失败,LLM 以大致均匀的频率选择所有臂,未能淘汰表现不佳的臂。唯一的例外是 Gpt-4 的 BSSC0 配置,即具有按钮场景、暗示性框架、总结历史、增强的 CoT 和温度为 0。我们在图 3
摘要
我们研究了当代大型语言模型(LLMs)在探索能力方面的表现,这是强化学习和决策制定中的核心能力。我们的重点是现有LLMs的原生性能,而不进行任何训练干预。我们将LLMs作为代理部署在简单的多臂老虎机环境中,环境描述和交互历史完全通过上下文提供,即在LLM的提示中。我们对Gpt-3.5、Gpt-4和Llama2进行了多种提示设计的实验,发现模型在没有实质性干预的情况下并没有有效地参与探索:i)在我们所有实验中,只有一种配置产生了令人满意的探索行为:使用链式推理的Gpt-4,结合外部总结的交互历史,作为充分统计信息呈现;ii)所有其他配置并未表现出强健的探索行为,包括那些使用链式推理但未总结历史的配置。尽管这些发现可以积极解读,但它们表明,外部总结在获得LLM代理的理想行为中可能是重要的,尤其是在更复杂的环境中,这种总结可能并不可行。我们得出结论,可能需要非平凡的算法干预,例如微调或数据集策划,以增强LLM在复杂环境中的决策能力。
1 引言
上下文学习是大型语言模型(LLMs)的一项重要新兴能力,使得用户可以通过在LLM提示中完全指定问题描述和相关数据,使用预训练的LLM来解决问题,而无需更新LLM参数(Brown et al., 2020)。例如,用户可以向LLM提供数值协变量向量和标量目标,并通过在提示中包含新的协变量向量,从模型中获得回归样式的预测(Garg et al., 2022)。令人惊讶的是,LLMs并未明确针对这种行为进行训练;相反,用于上下文学习的底层算法是从训练语料库中提取的,并在规模上自发出现。
自从在Gpt-3模型中发现上下文学习(Brown et al., 2020)以来,这一主题已成为越来越多研究的对象。这些研究包括对其基本机制的理论探讨(例如,Xie et al., 2021;Akyürek et al., 2022)、实证研究(例如,Garg et al., 2022;Kirsch et al., 2022),以及在应用中利用上下文学习的工作(例如,Xu et al., 2022;Som et al., 2023;Edwards et al., 2023)。这方面的文献主要研究上下文学习在预测或监督学习任务中的应用,虽然理论进展仍处于初期,但我们对如何在实践中使用上下文监督学习(ICSL)的理解正在迅速形成。
尽管监督学习是一种重要能力,但许多应用需要使用机器学习模型进行下游决策。因此,上下文强化学习(ICRL)和序列决策-making成为一个自然的新前沿。LLMs已经被用作决策代理,应用范围从自然科学中的实验设计(Lee et al., 2023b)到游戏(Shinn et al., 2023;Wang et al., 2023),但我们对ICRL的理解——无论是理论上还是操作上——远不如对ICSL的理解。迄今为止,我们缺乏系统的理解,以确定LLMs是否可以被视为通用决策代理。
决策代理必须具备三个核心能力:泛化(监督学习所需)、探索(做出可能在短期内次优的决策以获取更多信息)和规划(考虑决策的长期后果)。在本文中,我们关注探索能力,即故意收集信息以评估替代方案并减少不确定性。最近的一系列论文(Laskin et al., 2022;Lee et al., 2023a;Raparthy et al., 2023)展示了当变换器模型经过明确训练以产生此类行为时的上下文强化学习行为(包括探索)。这种训练往往繁琐、昂贵,并可能是任务特定的。特别是,这些发现并未阐明一般性LLMs在标准训练方法下是否具备探索行为,这引出了一个基本问题:当代LLMs是否具备在上下文中进行探索的能力?
贡献
我们通过将LLMs作为代理部署在简单的合成强化学习问题上,即多臂老虎机(MABs)(Slivkins, 2019;Lattimore and Szepesvári, 2020),来研究这个问题,环境描述和交互历史完全包含在LLM提示中。多臂老虎机是一种经典且经过充分研究的强化学习问题,旨在隔离探索与利用之间的权衡,即在可用数据的基础上做出最佳决策。它们也是通向通用序列决策的基本构件;解决MABs的能力是更具挑战性的强化学习任务的先决条件。由于其简单性、在强化学习中的中心性以及对探索与利用的关注,使得MABs成为系统研究LLMs的上下文探索能力的自然选择。
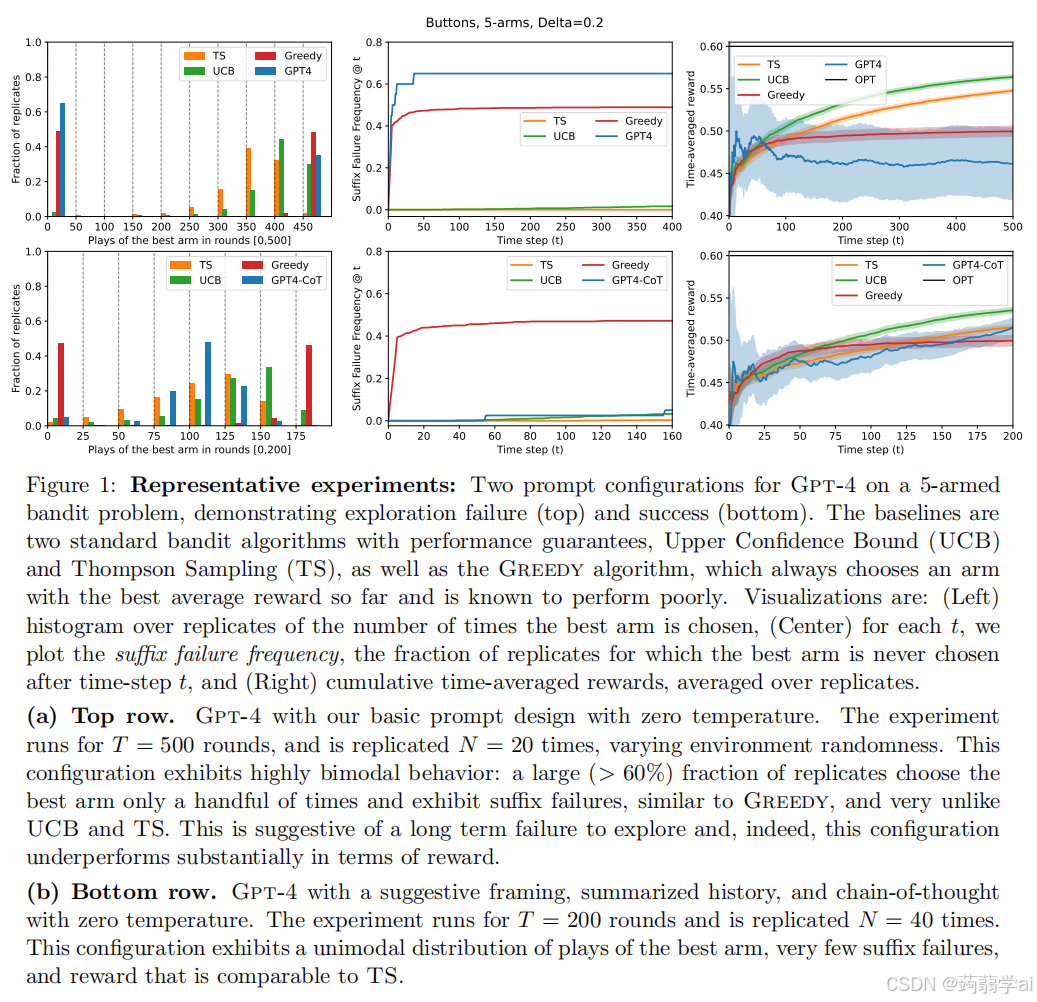
我们在MAB环境中评估Gpt-3.5(Brown et al., 2020)、Gpt-4(OpenAI, 2023)和Llama2(Touvron et al., 2023)的上下文探索行为,使用多种提示设计。在我们的实验中,发现只有一种配置(即提示设计和LLM组合)能产生令人满意的探索行为。所有其他配置都表现出探索失败,未能以显著概率收敛到最佳决策(臂)。我们发现,这种情况通常是由于后缀失败,即LLM在某些初始轮次后未能至少选择一次最佳臂(即在某个“时间后缀”中)。这个情况在图1(a)中得到了体现:特别是,使用我们基本提示设计的Gpt-4在超过60%的复制中经历了后缀失败。我们识别出的另一种失败模式是LLM表现出“均匀”行为,选择所有臂的频率几乎相同,未能缩小到更好的选择。
在我们的实验中,唯一成功的配置涉及Gpt-4和一个“增强”提示,该提示(a) 提供了探索的暗示,(b) 将交互历史外部总结为每个臂的平均值,以及© 请求LLM使用零-shot链式推理(Wei et al., 2022;Kojima et al., 2022)。这一配置在图1(b)中得以可视化。可以积极解读这一发现:如果提示经过精心设计以引导这种行为,最先进的LLMs确实具备稳健探索的能力。另一方面,我们发现,在没有外部总结的情况下,相同的配置会失败,这引出了负面解读:在更复杂的环境中,LLMs可能无法进行探索,而外部总结历史是非平凡的算法设计问题。
我们得出结论,尽管当前一代LLMs在适当的提示工程下可以在简单的强化学习环境中进行探索,但可能需要训练干预(如Lee et al.(2023a);Raparthy et al.(2023)所述),以赋予LLMs在更复杂环境中所需的更复杂的探索能力。
方法论
评估LLM能力和局限性的一个基本技术挑战是必须在搜索组合规模庞大的提示设计空间的同时,获得统计上有意义的结果,并且满足与LLMs相关的财务和计算约束。评估上下文赌博学习更具挑战性,因为(a) 环境中的随机性要求为了统计显著性而进行高度复制,以及(b) 学习/探索的样本复杂性要求即使是单次实验也涉及数百或数千个LLM查询,以获得有意义的效应大小(即成功方法与失败方法之间的差异)。为了解决这些问题,我们的核心技术贡献是识别替代统计量作为长期探索失败的诊断工具。我们考虑的替代统计量可以表征长期探索失败,但可以在适度规模下通过少量复制和短学习时间进行测量,即使标准性能度量(即奖励)过于噪声而无法使用。
2 实验设置
多臂老虎机(MAB)
我们考虑一种基本的多臂老虎机变体,即随机伯努利老虎机。设有 K 个可能的动作(臂),索引为 [K]:=1,...,K[K] := {1, ..., K}[K]:=1,...,K。每个臂 a 关联一个未知的平均奖励 μa∈[0,1]\mu_a ∈ [0, 1]μa∈[0,1]。代理在 TTT 个时间步中与环境交互,在每个时间步 t∈[T]t \in [T]t∈[T],代理选择一个臂 at∈[K]a_t \in [K]at∈[K] 并获得从平均μat\mu_{a_t}μat的伯努利分布中独立抽取的奖励 rt∈0,1r_t \in {0, 1}rt∈0,1。
因此,MAB 实例由平均奖励 (µa:a∈[K])(µ_a: a \in [K])(µa:a∈[K]) 和时间范围 T 决定。目标是最大化总奖励,大致对应于识别最佳臂:即具有最高平均奖励的臂。MAB 设置的一个关键特征是未选择的臂的奖励不会被揭示,因此需要探索以识别最佳臂。
我们关注的 MAB 实例中,最佳臂的平均奖励为μ⋆=0.5+Δ/2\mu^\star = 0.5 + \Delta/2μ⋆=0.5+Δ/2,其中参数 ∆>0∆ > 0∆>0,而所有其他臂的平均奖励为 μ=0.5−Δ/2\mu = 0.5 − \Delta/2μ=0.5−Δ/2(因此,Δ=μ⋆−μ\Delta = \mu^{\star} − \muΔ=μ⋆−μ 是最佳臂与第二好的臂之间的差距)。我们考虑的主要实例为 K=5K = 5K=5 的臂和 Δ=0.2\Delta = 0.2Δ=0.2,我们称之为困难实例,同时考虑 K=4K = 4K=4 和 Δ=0.5\Delta = 0.5Δ=0.5的简单实例。
提示设计
我们使用 LLM 作为决策代理与 MAB 实例交互,提示内容包括 MAB 问题的描述(包括时间范围 T)和迄今为止的交互历史。我们的提示设计允许多个独立选择。首先是一个“场景”,为决策问题提供基础,使 LLM 处于 a) 选择按钮的代理,或 b) 向用户显示广告的推荐引擎。其次,我们指定“框架”,可以是 a) 明确暗示需要平衡探索与利用,或 b) 中性。第三,历史可以以 a) 原始列表的形式呈现,或 b) 通过每个臂的播放次数和平均奖励进行总结。第四,最终答案可以是 a) 单个臂,或 b) 臂的分布。最后,我们可以选择 a) 仅请求答案,或 b) 允许 LLM 提供“链式推理”(CoT)解释。总的来说,这些选择导致 25=322^5 = 3225=32 种提示设计,详见图 2。关于提示设计的更多细节,包括示例,详见附录 A。
最基本的提示设计使用按钮场景、中性框架和原始历史,并请求 LLM 返回仅一个臂而不提供 CoT。对该提示的五种可能修改可以潜在地帮助 LLM,我们的实验对此进行评估。例如,广告场景和暗示性框架可能有助于激发 LLM 对赌博算法的知识(因为赌博算法通常用于内容推荐)。如果 LLM 本身无法可靠地总结历史(可能由于算术错误)和/或未完全意识到应当总结历史,则历史总结可能会有所帮助。如果 LLM 能够识别一个好的分布但未能正确从中抽样,返回分布可能会有所帮助。最后,链式推理在各种 LLM 场景中被证明有帮助(Wei et al., 2022;Malach, 2023),即使在零-shot 使用的情况下(Kojima et al., 2022)。
提示通过系统消息和用户消息呈现给每个 LLM(所有三个 LLM API 都暴露了这些)。系统消息提供有关场景和框架的信息,并提示 LLM 是否使用 CoT,以及如何返回分布。用户消息呈现历史并提醒 LLM 如何格式化其响应。对于 Gpt-4,我们发现提示 LLM 在系统提示中使用 CoT 并未可靠地引发 CoT 输出,因此——仅针对 Gpt-4——我们还考虑了一种增强的 CoT 提示设计,另外提醒 LLM 在用户提示的最后使用 CoT。见附录 A 以获取示例。
LLM 配置
我们实验了三种 LLM:Gpt-3.5、Gpt-4 和 Llama2。除了上述提示变体外,我们还考虑了温度参数的两个选择,0 和 1。温度为 0 时,LLM 被迫确定性,从而隔离 LLM 自身的“故意”探索行为。温度为 1 提供了 LLM 响应中的外部随机性,这可能会导致臂之间的随机化。允许 LLM 返回分布而不是单个臂也提供了外部随机性(因为我们从返回的分布中抽样);为了隔离随机性来源,我们不考虑温度为 1 的“返回分布”提示设计。
我们将(提示设计,温度)元组称为 LLM 配置。我们用 5 个字母的“代码” L1L2L3L4L5L_1L_2L_3L_4L_5L1L2L3L4L5 标识每个配置,其中字母 LiL_iLi 表示选择:
- L1L_1L1:‘B’ 或 ‘A’,分别表示按钮或广告场景;
- L2L_2L2:‘N’ 或 ‘S’,分别表示中性或暗示性框架;
- L3L_3L3:‘R’ 或 ‘S’,分别表示原始或总结历史;
- L4L_4L4:‘C’、‘R’ 或 ‘N’,分别表示链式推理、增强的 CoT 或不使用 CoT;
- L5L_5L5:‘0’、‘1’ 或 ‘D’,分别表示温度和返回分布(温度为 0)。
我们将“BNRN0”称为基本配置。我们大多数实验考虑“按钮”场景,而主要将“广告”场景用作稳健性检查。对于 Gpt-3.5 和 Llama2,我们不考虑增强的 CoT,因为它不需要可靠地引发 CoT 输出;因此,对于这两个 LLM,我们总共有 48 种配置。对于 Gpt-4,我们主要使用增强的 CoT,但也实验了一些标准的 CoT 提示设计;因此,Gpt-4 总共有 72 种配置。
基线
作为基线,我们考虑两个标准的 MAB 算法,UCB(Auer et al., 2002a)和汤普森采样(TS)(Thompson, 1933),它们在某种理论意义上是最优的,并且在实践中也相当有效。我们还考虑贪婪算法,它不进行探索并且已知会失败。虽然这三种基线都有可调参数,但我们未进行参数调优(有关每种算法及参数设置的详细描述见第4.1节)。除了这些基线外,我们的一些实验还包括不同选择的 ϵ\epsilonϵ-贪婪算法,以定量展示探索与利用之间的权衡。我们对每个基线和每个 MAB 实例进行了 1000 次复制(奖励在复制之间独立实现)。
实验规模
我们的主要实验设置时间范围 T = 100。为了考虑奖励中的随机性(可能还包括通过温度引入的 LLM 随机性),我们对每个 LLM 配置和每个赌博实例进行了 N ∈ {10, 20} 次复制,奖励在复制之间独立生成。作为稳健性检查,我们对 Gpt-4 的基本配置进行了 T = 500 轮的单次实验(N = 20),并获得了一致/更强的结论,如图 1(a) 所示。
具体而言,对于 Gpt-3.5,我们在所有 48 种提示配置中使用 N = 20 复制,总共约 20 万个查询。Gpt-4 的成本高出一个数量级,吞吐量相当缓慢,并且受到不可预测的节流影响。因此,我们仅在 10 个代表性提示配置中使用 N = 10 复制。为了进行额外的稳健性检查,我们对 Gpt-4 的四种配置进行了 T = 200 的实验,其中两种为 N = 20 复制,另两种为 N = 40 复制。总共,这导致对 Gpt-4 发出了约 5 万个查询。Llama2 从我们的角度看基本上是免费的(因为它在本地托管),但其性能始终低于预期;我们将实验限制在困难 MAB 实例、32 种配置和 N = 10 复制。
我们强调,与 LLM 的赌博实验在金钱和时间方面非常昂贵。每个 LLM 配置和每个 MAB 实例的测试需要 N · T 次 LLM 查询。N 和 T 必须相对较大,以获得统计上有意义的结果:N 决定显著性水平,必须足够大以克服奖励实现中的随机性,而 T 决定效应大小,必须足够大,以便良好的算法有足够的时间识别最佳臂。这两个问题在更困难的 MAB 实例中更为明显(许多臂 K 和/或小差距 ∆),但在(非常)简单的 MAB 实例中的探索失败往往也较少。此外,我们需要覆盖可能的提示设计空间,该空间本质上是无限大的,以确保我们的发现不会过拟合于某一特定设计。因此,理想情况下,我们希望 N、T、MAB 实例数量和提示数量都相对较大,但这样做在实际操作中不可行。
相反,我们选择了适度的小差距 Δ=0.2\Delta = 0.2Δ=0.2、适度大的 N∈10,20N \in {10, 20}N∈10,20 和 T = 100,以及上述描述的提示设计空间。正如我们将在下面看到的,这些选择(具体而言,N∈{10,20}N \in \{10, 20\}N∈{10,20} 和 T = 100 以及 Δ=0.2\Delta = 0.2Δ=0.2)不足以仅根据累积奖励区分成功和不成功的方法。由于进一步增加实验规模在实践中不可行,我们依赖于可以在适度规模下检测到的替代统计量,这些统计量高度暗示长期/持续的探索失败。我们对更大 T 和 N 的稳健性检查,以及我们在下面报告的定性发现,为这种方法提供了支持证据。
3 实验结果
在本节中,我们展示实验结果,首先在 3.1 小节中进行总结;接着在 3.2 小节中详细调查 LLM 配置的失败情况;然后在 3.3 小节中聚焦于我们实验中识别出的唯一成功的 LLM 配置;最后在 3.4 小节中诊断探索失败的潜在原因。
3.1 概述
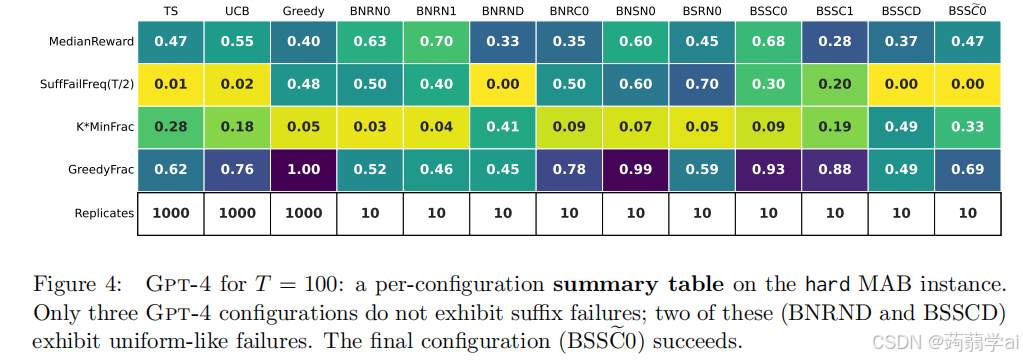
我们发现,考虑的所有 LLM 配置中,除了一个,均表现出探索失败,未能以显著概率收敛于最佳臂。这种情况发生在以下两种情况中:一种是后缀失败,LLM 在少量初始轮次后从未选择最佳臂;另一种(较少出现)是均匀型失败,LLM 以大致均匀的频率选择所有臂,未能淘汰表现不佳的臂。唯一的例外是 Gpt-4 的 BSSC0 配置,即具有按钮场景、暗示性框架、总结历史、增强的 CoT 和温度为 0。
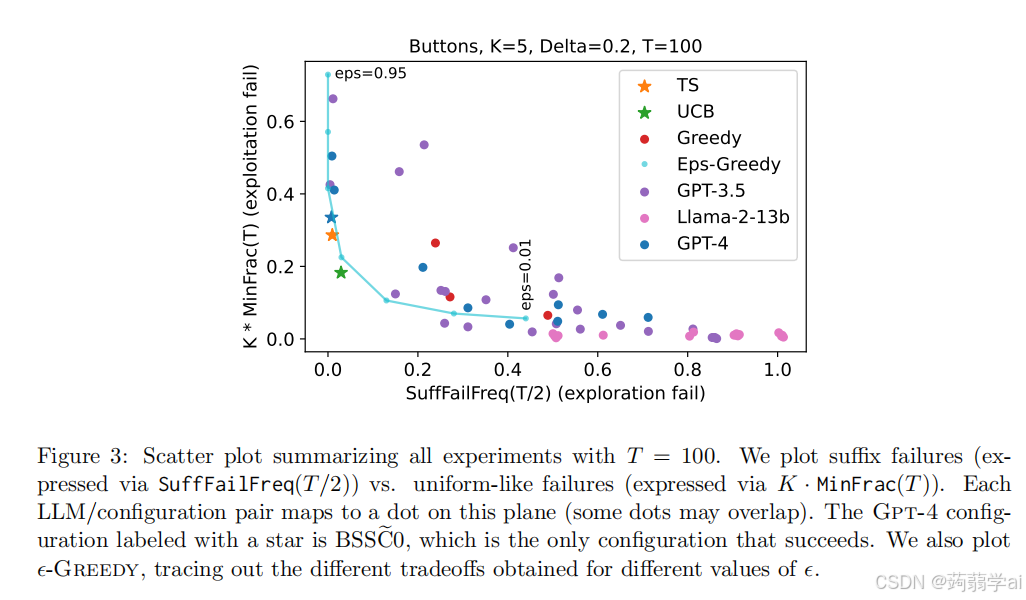
我们在图 3 和图 4 中总结了关键发现。图 3 总结了主要实验集(我们回顾其考虑了困难 MAB 实例),将每个 LLM 配置可视化为散点图中的一个点,坐标轴对应于两个替代统计量:SuffFailFreq 和 MinFrac,这些统计量代表了两种失败模式的强度(SuffFailFreq 测量后缀失败,K · MinFrac 测量均匀型失败);这些统计量将在后文中详细描述。图 4 显示了每个 Gpt-4 配置的 SuffFailFreq、MinFrac、GreedyFrac(测量方法与贪婪算法的相似度)以及其他摘要统计信息。这些统计揭示,除了 Gpt-4-BSSC0(图 3 中的蓝色星星),所有 LLM 配置的行为与基线算法 UCB 和 TS 基本不同,且我们发现这些差异导致了显著且持久的性能下降。相反,我们发现 Gpt-4-BSSC0 成功探索,并因此收敛于最佳臂。
3.2 识别失败
我们现在对图 3 和图 4 中所示的探索失败进行详细概述,并提供额外的结果和图形,以更详细地说明失败情况。我们主要关注 Gpt-4,因为我们发现 Gpt-3.5 和 Llama2 在所有实验中的表现更差(且通常远差);Gpt-3.5 和 Llama2 的详细结果已在附录 B 中包含以供完整性参考。我们首先详细介绍用于量化图 3 和图 4 及后续图中的失败的替代统计量 SuffFailFreq 和 MinFrac,提供证据证明探索失败(通过这些统计量量化)导致绩效持续下降。
后缀失败:我们考虑的大多数 LLM 配置表现出高度双峰行为,即大量复制很少选择最佳臂,而少数复制极快收敛于最佳臂。与这种双峰行为一致,我们观察到后缀失败的发生率很高,即在少量初始轮次后,最佳臂甚至一次都未被选择(即在某些“时间后缀”中)。后缀失败暗示了长期探索失败,无法通过延长算法运行时间来改进,因为在不玩最佳臂的情况下,无法获得信息以学习其确实是最优的。这种行为在性质上与贪婪算法相似,而与 UCB 和汤普森采样则有很大不同。
我们用以下方式定义测量后缀失败的替代统计量:对于实验复制RRR和轮次ttt,设 SuffFail(t,R)SuffFail(t, R)SuffFail(t,R)为一个二元变量,当最佳臂在轮次[t,T][t, T][t,T]中从未被选择时其值为 1。则 SuffFailFreq(t):=mean(SuffFail(t,R):复制R)SuffFailFreq(t) := mean({SuffFail(t, R) : 复制 R})SuffFailFreq(t):=mean(SuffFail(t,R):复制R)。后缀失败在我们大多数实验中表现为 T=100T = 100T=100。在图 3 的散点图中,X 轴绘制每个 LLM 配置的 SuffFailFreq(T/2)SuffFailFreq(T /2)SuffFailFreq(T/2),我们发现除了五个配置外,SuffFailFreq(T/2)≥15SuffFailFreq(T /2) ≥ 15%SuffFailFreq(T/2)≥15。回顾后缀失败的定义,这意味着在最后一半轮次中,这些配置至少 15% 的时间未能选择最佳臂。
通过关注单个 LLM 配置,可以获得后缀失败和双峰行为的更详细视图。我们在图 1(顶部)中为基本配置(Gpt-4-BNRN0)可视化 T=500T = 500T=500,图 5 中为 Gpt-4(BNRN0 和 BNRN1)在 T=100T = 100T=100 的情况。在这些详细视图中,中间面板绘制了给定 LLM 配置的 SuffFailFreq(t)SuffFailFreq(t)SuffFailFreq(t)在每个时间 t 的值,以及 UCB、TS 和贪婪算法的值。我们发现这些 LLM 配置的后缀失败率远高于 UCB 和 TS。双峰行为在每个图的左面板中可视化,对于每个配置,大量复制很少选择最佳臂,而其余部分几乎总是选择最佳臂。由于这种双峰行为(特别是由于常数比例的复制偶然几乎总是选择最佳臂),后缀失败未完全反映在图 5 的总奖励图中,因为时间范围T=100T = 100T=100不够大。然而,如前所述,后缀失败暗示了不可恢复的探索失败,这导致在更大 T 下奖励的明显差异。正如我们在图 1 中 T=500T = 500T=500 的结果所示,后缀失败确实导致长期表现不佳。
均匀型失败:回到图 3 的左面板,我们看到三个 Gpt-4 配置避开了后缀失败。这两个配置表现出不同类型的失败,LLM 在整个 T 轮次中以大致相等的比例选择臂,未能利用获得的信息集中于表现更好的臂。我们称之为均匀型失败。
我们用以下方式定义测量这种失败的替代统计量:对于特定实验复制 RRR 和轮次 ttt,设 fa(t,R)fa(t, R)fa(t,R) 为在 [1,t][1, t][1,t] 中选择给定臂 aaa 的轮次比例,MinFrac(t,R):=minafa(t,R)MinFrac(t, R) := mina fa(t, R)MinFrac(t,R):=minafa(t,R),以及 MinFrac(t):=mean(MinFrac(t,R):复制R)MinFrac(t) := mean({MinFrac(t, R) : 复制 R})MinFrac(t):=mean(MinFrac(t,R):复制R)。由于 MinFrac(t)≤1/K,∀t∈[T]MinFrac(t) \le 1/K,\forall t \in [T]MinFrac(t)≤1/K,∀t∈[T],我们总是绘制 K⋅MinFrac(t)K · MinFrac(t)K⋅MinFrac(t),以将范围重新缩放到 [0, 1]。更大的 MinFrac(t) 表示在时间 t 上的臂选择更均匀。当 LLM 的 MinFrac(t) 随时间不减并且始终明显高于基线(特别是当 t 接近时间范围 T 时),我们将其视为均匀型失败的指示。
图 3 的 Y 轴记录每个配置的$ K · MinFrac(T)$,我们看到在避免后缀失败的三个 Gpt-4 配置中,有两个配置的 MinFrac(T) 相对于 UCB 和 TS 非常高(第三个配置是 Gpt-4-BSSC0,它是成功的)。这两个配置分别为 Gpt-4-BNRND 和 Gpt-4-BSSCD,它们都使用分布输出格式。我们在图 6 中提供了 Gpt-4-BNRND(以及 Gpt-4-BNSND,它也表现出均匀型失败,但仅在使用总结历史上与 Gpt-4-BNRND 不同)的更详细视图,考虑了更长的时间范围和更多的复制(T = 200 和 N = 20)。中间面板揭示,这些 LLM 配置的 K · MinFrac(t) 随时间不减,而基线则随着时间减小。这种行为导致没有后缀失败,但导致的奖励远低于基线。特别是,我们在总奖励中获得了明显的分离,表明均匀型失败确实导致长期表现不佳。
失败的普遍性:总结而言,图 3 显示,除了 Gpt-4-BSSC0 之外,所有 LLM 配置在困难 MAB 实例和按钮场景下均表现出后缀失败或均匀失败。其他三个实验(即广告场景和/或简单 MAB 实例)的散点图在性质上相似,已推迟至附录 B。具有特定 LLM 配置归属的数据已在图 4 中呈现;其他 LLM 和实验设置的类似表格在附录 B 中提供。由于对每个 LLM 配置呈现详细图(如图 5)并不具有指导意义,图 4 用少量统计信息总结了每个配置的性能。我们包含:
- SuffFailFreq(T /2) 和 MinFrac(T),如上所定义。
- MedianReward:时间平均总奖励的中位数(经过复制重新缩放)。
- GreedyFrac:贪婪轮次的比例,平均在复制中。贪婪轮次是选择具有最大平均奖励的臂的轮次。这是量化配置行为类似贪婪的程度的一种方式。
现在我们总结来自散点图(图 3 和 12)和摘要表(图 13 到 19)的其他发现。首先,Gpt-4 的表现显著优于 Gpt-3.5,而 Llama2 的表现则远不如(特别是,Llama2 的后缀失败频率范围从贪婪到更大)。其次,我们观察到所有 LLM 对提示设计的小变化都非常敏感。然而,我们考虑的不同修改似乎相互作用,很难识别出哪些单独的修改改善了性能,哪些则降低了性能。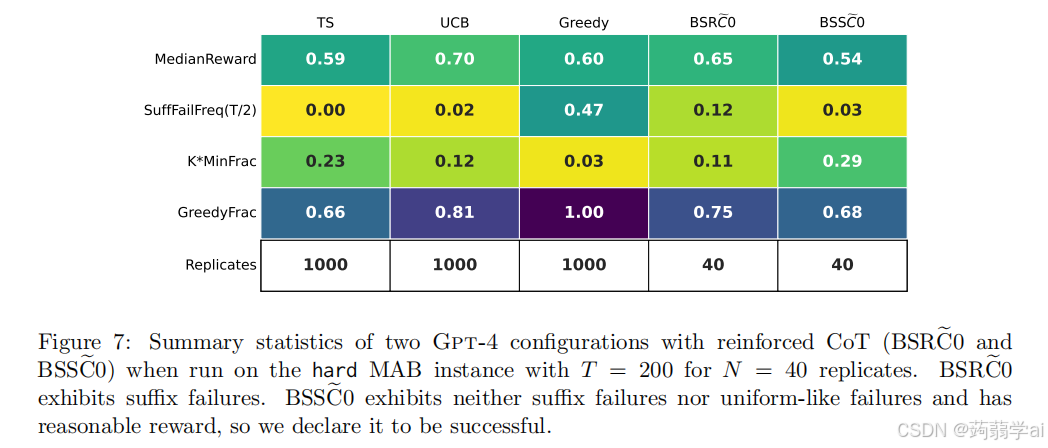

3.3 调查成功案例
在困难的 MAB 实例中,我们实验中唯一避免后缀失败和均匀型失败的配置是 Gpt-4 的 BSSC0 提示设计。从图 4 可以看出,在 T = 100 时,该配置没有后缀失败,K · MinFrac 值仅比 TS 略高,奖励与 TS 相当。这些统计数据表明该配置成功。在本节中,我们提供进一步的证据来支持这一说法。
为此,我们在 T = 200 和 N = 40 的条件下运行 Gpt-4-BSSC0,以获得更具统计意义的结果。同时,我们考虑 Gpt-4-BSRC0,它将总结历史替换为原始历史,作为一种消融实验。图 7 提供了该实验结果的总结,而图 1(b) 则详细展示了 BSSC0 配置。这些图表显示,BSSC0 继续避免后缀失败,并且在较大的 T 下表现出相对良好的奖励。另一方面,我们看到 BSRC0 表现出非平凡比例的后缀失败,证明这一消融实验导致了根本不同的行为。
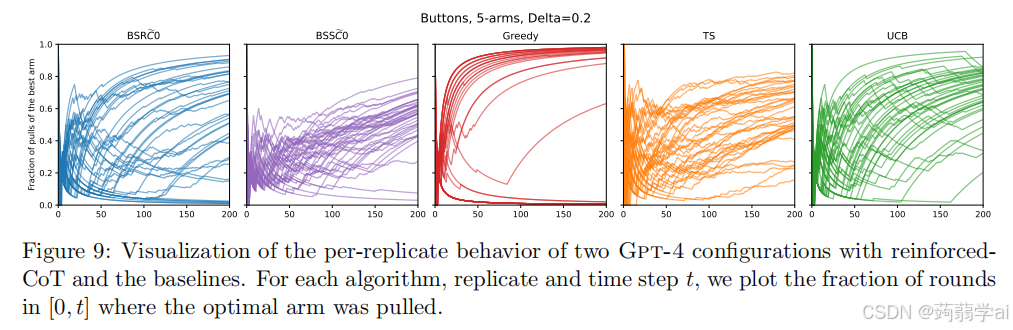
我们还提供了两个额外的可视化,以提供一些定性证据支持 BSSC0 的成功,以及其他配置的失败。这些可视化结果展示在图 8 和图 9 中。
在图 8 中,我们可视化了不同方法(包括 LLM 和基线算法)多个复制在每个时间步选择的臂。具体来说,图 8 显示了基本配置(BNRN0)和两个强化 CoT 配置(BSRC0 和 BSSC0)的四个复制,以及每个基线算法的一个复制。我们看到,基本配置 BNRN0 倾向于在几个回合中坚持选择单个臂,这一行为与贪婪算法相似,而与 UCB 和 TS 有显著不同。BSRC0 也在较长时间内坚持选择,但程度低于基本配置。相比之下,BSSC0 更频繁地切换臂,质感上与 TS 更为相似。
在图 9 中,我们绘制了在[0,t][0, t][0,t] 区间内选择最佳臂的轮次比例,作为 ttt 的函数。BSRC0 的表现与 UCB 相似,但有非平凡比例的运行展示出后缀失败(在图中收敛到 0 的曲线)。与此同时,BSSC0 的表现与 TS 类似,几乎所有复制都缓慢收敛到 1。这些可视化结果及总结统计数据表明,BSSC0 的行为与 TS 最为相似,进一步表明在足够长的时间范围内,它将成功收敛于最佳臂。
3.4 根本原因
我们上述的实验发现揭示了基于 LLM 的决策代理的行为,但理解它们为何以这种方式表现(特别是为何失败)同样重要。这个问题相对难以明确回答,但有两个自然的假设:我们考虑的配置(除了 Gpt-4-BSSC0)要么 a) 过于贪婪,要么 b) 过于均匀。在本节中,我们描述我们的实验如何为这些假设提供一些见解。
首先,专注于 Gpt-4,我们的实验揭示了简单实例与困难实例之间的定性不同的行为(见图 13(a) 和图 13©)。实际上,简单实例似乎要简单得多;大多数 Gpt-4 配置在这个实例上避免了后缀失败,并且获得了大量奖励,而 GreedyFrac 统计量提供了潜在的解释。在简单实例上,大多数 Gpt-4 配置的 GreedyFrac 值非常高,因此它们的行为类似于贪婪算法,这在性能上表现相当不错(尽管贪婪算法在小的常数概率下证明是失败的,并且在该实例上经验上有许多后缀失败)。因此,一个合理的假设是 Gpt-4 在低噪音环境中表现良好,而这正是贪婪算法也表现良好的时候。
更强的假设是,大多数 Gpt-4 配置(或许使用强化 CoT 的配置除外)在所有实例上都表现得像贪婪算法,但这一假设被我们的实验在困难实例上的 GreedyFrac 统计量所驳斥。在困难实例上,大多数 Gpt-4 配置似乎做了一些非平凡的(尽管有缺陷的)行为;它们的行为既不是完全的贪婪样式,也不是随机均匀的。
为了更细致地理解,我们进行了一个小规模的二次实验,聚焦于 LLM 代理的逐轮决策。实验关注于带宽问题中的单轮 t。每个实验考虑一个特定的“数据源”(带宽历史的分布),从该分布中随机抽取 N = 50 个长度为 t 的带宽历史,并将其呈现给代理(LLM 和基线),要求它们输出一个臂或臂的分布。我们跟踪每个代理的两个统计量:GreedyFrac 和 LeastFrac,分别表示代理选择的到目前为止经验最佳臂和到目前为止选择最少的臂的复制比例。我们改变数据源,即生成历史的算法。特别地,我们考虑通过均匀随机抽样(Unif)生成的历史,以及通过运行我们的基线 UCB 和 TS 生成的历史。
结果总结在图 10 中。不幸的是,我们发现 LLM 和基线的逐轮表现对特定数据源非常敏感。例如,UCB 的 MinFrac 统计量在均匀随机生成的历史上可以高达 0.46,而在 UCB 自身生成的历史上则低至 0.09。虽然似乎可以合理地得出 BNSN0 过于贪婪,而 BSRN0 过于均匀的结论,但其他两个 LLM 配置(BNRN0 和 BNRC0)的统计量——这两个配置在我们的纵向实验中失败——则落在基线提供的合理范围内。因此,我们发现基于逐轮决策评估 LLM 代理是否过于贪婪或过于均匀是具有挑战性的,尽管这些代理在纵向实验中与基线的行为有显著不同。
4 相关工作
本文属于近期一系列旨在理解 LLM 能力的研究,即它们能做什么、不能做什么以及原因。得到广泛关注但与本文无关的能力包括一般智能(Bubeck et al., 2023; Binz and Schulz, 2023)、因果推理(Kıcıman et al., 2023; Yiu et al., 2023)、数学推理(Cobbe et al., 2021; Lu et al., 2023)、规划(Valmeekam et al., 2023; Momennejad et al., 2023; Brooks et al., 2023)和组合性(Yu et al., 2023)。
更具体地说,我们的工作为关于上下文学习能力的广泛文献做出了贡献。先前对上下文学习的研究包括理论研究(Xie et al., 2021; Akyürek et al., 2022; Zhang et al., 2023b; Abernethy et al., 2023; Zhang et al., 2023a; Han et al., 2023a; Cheng et al., 2023; Ahn et al., 2023; Wies et al., 2023; Fu et al., 2023; Wu et al., 2023; Huang et al., 2023; Hendel et al., 2023; Li et al., 2023; Von Oswald et al., 2023; Bai et al., 2023; Hahn and Goyal, 2023; Jeon et al., 2024)和实证研究(Garg et al., 2022; Kirsch et al., 2022; Ahuja et al., 2023; Han et al., 2023b; Raventós et al., 2023; Weber et al., 2023; Bhattamishra et al., 2023; Guo et al., 2023; Shen et al., 2023; Akyürek et al., 2024)。然而,如前所述,大多数研究与上下文监督学习相关;相比之下,上下文强化学习的关注度较低。
关于上下文强化学习的少量实证研究(Laskin et al., 2022; Lee et al., 2023a; Raparthy et al., 2023; Xu et al., 2022)主要集中在使用从其他代理(无论是 RL 算法还是专家)收集的轨迹数据从头训练模型;理论上,Lee et al. (2023a) 和后来的 Lin et al. (2023) 从贝叶斯元强化学习的角度为这种方法提供了合理性,并展示了预训练的变换器可以实现经典的探索策略,如汤普森采样和上置信限(UCB)。然而,这些工作要求对语言模型的预训练阶段进行干预,并未研究现有 LLM 在标准训练条件下是否表现出探索能力。
与本文最为相近的研究是 Coda-Forno et al. (2023),该研究评估了 Gpt-3.5 在双臂赌博任务和相关的元学习任务中的表现。与我们的研究相似,他们发现 Gpt-3.5 的表现与贪婪算法相似(实际上略差);然而,他们未考虑足够长的时间范围以区分贪婪算法与成功的基线如 UCB。
与此同时,越来越多的研究将 LLM 应用于现实世界的决策应用。除了之前提到的研究(Shinn et al., 2023; Wang et al., 2023; Lee et al., 2023b),一些亮点包括 Park et al. (2023),他们介绍了生成代理,模拟开放世界环境中的人类行为,以及 Ahn et al. (2022) 和 Xu et al. (2023),他们开发了 LLM 驱动的机器人。
并行工作
两项密切相关的并行工作(Wu et al., 2024; Park et al., 2024)也研究了 LLM 在赌博任务中的上下文表现。Wu et al. (2024) 考虑了一系列旨在特征化“智能代理”的任务,将双臂赌博作为一个特定的兴趣任务。它们的赌博实验在几个关键方面有所不同:它们考虑了一个非常简单的 MAB 实例(具有 2 个臂和较大的间隔 Δ=0.6\Delta = 0.6Δ=0.6,远比我们的实例更简单),专注于单一提示设计(类似于我们的基本提示),并与人类玩家而非算法基准进行比较。这些差异导致了非常不同的实验发现。特别是,他们发现 Gpt-4 在其简单的 MAB 实例上表现良好,快速收敛到最佳臂,而我们发现 Gpt-4 在类似提示下在更困难的 MAB 实例上失败。然而,他们的发现与我们的结果一致,因为我们也发现多个 Gpt-4 配置在简单的 MAB 实例上表现良好。正如我们在第 3.4 节中讨论的,该实例过于简单,无法提供有力的证据支持原则性的探索行为。
Park et al. (2024) 主要关注全信息在线学习和重复游戏设置,但也在赌博设置中评估 LLM。他们的实验在两个重要方面与我们的不同。首先,尽管他们的一些数据生成协议本质上是随机的,但他们主要关注对抗性设置。因此,他们与对抗性赌博基准进行比较,并通过重要性加权损失(Auer et al., 2002b)向 LLM 提供历史数据。其次,他们主要考虑较短的时间范围(对赌博任务 T = 25,对全信息任务最长 T = 50)。在他们论文的更新版本中(在 2024 年秋季的 arXiv 上发布),他们还包括了更长时间范围下的实验,发现 LLM 继续表现良好,并在我们的困难 MAB 实例中进行了 T = 100 的实验,评估均匀和后缀失败。有趣的是,他们发现 Gpt-4 和 Gpt-4o 在使用默认提示时表现良好(高奖励、无后缀失败和低 MinFrac),该提示要求生成分布输出、链式思维,并通过重要性加权呈现历史数据。他们进一步发现,去除重要性加权会导致失败,特别是 Gpt-4 的 MinFrac 较高,Gpt-4o 则出现后缀失败。这些发现与我们的结果可能一致:这两项结果都强调了对历史数据进行预处理(无论是通过总结还是通过重要性加权)对引导 LLM 进行探索行为的重要性。
其他并行工作包括 Schubert et al. (2024); Hayes et al. (2024); Coda-Forno et al. (2024),他们使用上下文赌博和其他任务研究 LLM 是否在决策任务中表现出类人行为(特别是偏差)。
我们还建议感兴趣的读者参考关于在强化学习环境中使用 LLM 的方法的最新调查(Cao et al., 2024)。
后续工作
Monea et al. (2024) 和 Nie et al. (2024) 在我们的结果基础上进行了多个新的实验发现。两项工作都考虑了上下文赌博(而 Nie et al. (2024) 还考虑了普通 MAB),发现 LLM 在没有非平凡干预的情况下无法进行探索。从这个意义上说,这些工作证实了我们的主要发现。此外,两项工作均提出了改善 LLM 探索的干预措施。具体而言,Monea et al. (2024) 提出了一种无训练的干预方法,即在将交互历史包含在 LLM 提示之前,均匀抽样该历史,而 Nie et al. (2024) 则考虑使用最优示例进行少量提示和微调。这些干预措施提高了性能,但仍未达到标准算法基准的竞争水平。
4.1 多臂赌博的进一步背景
在这里,我们提供多臂赌博问题及本文所用基线算法的额外背景。更深入的讨论可以参考 Bubeck 和 Cesa-Bianchi (2012);Slivkins (2019);Lattimore 和 Szepesvári (2020)。
UCB 算法(Auer et al., 2002a)通过为每个臂分配一个索引进行探索,该索引定义为到目前为止该臂的平均奖励加上形式为C/naC/\sqrt{n_a}C/na 的奖金,其中 C=Θ(logT)C = \Theta(\log T)C=Θ(logT) 且 nan_ana 是到目前为止从该臂抽样的次数。在每一轮中,它选择具有最大索引的臂。该奖金实现了不确定性下的乐观原则。我们使用设置 C=1C = 1C=1 的 UCB 版本(一个启发式方法),已观察到其具有良好的经验表现(例如,Slivkins et al., 2013; Ho et al., 2016)。
汤普森采样(Thompson, 1933; Russo et al., 2018,见综述)假设臂的平均奖励最初是从某个贝叶斯先验中抽取的。在每一轮中,它根据到目前为止的历史计算贝叶斯后验,从后验中抽样,并选择根据该样本具有最大平均奖励的臂(即假设该样本是真实值)。在我们的设置中,先验实际上是算法的一个参数。我们选择的先验是独立且均匀随机地从 [0, 1] 区间抽取每个臂的平均奖励。这是一个标准选择,能够实现接近最优的遗憾界限,以及良好的经验表现(Kaufmann et al., 2012; Agrawal and Goyal, 2012, 2017)。每个臂独立地更新为 Beta-Bernoulli 共轭先验。进一步优化 UCB 和汤普森采样对本文并不必要,因为它们在我们的实验中已经表现良好。
赌博算法的可证明保证通常通过遗憾来表达:最佳臂的期望总奖励与算法的差异。这两个基线算法实现了 O(KTlogT)O(\sqrt{KT \log T})O(KTlogT) 的遗憾,作为 TTT 和 KKK 的函数,几乎是最小极大最优的。它们还实现了接近实例最优的遗憾率,对我们考虑的实例的规模为 O(K/ΔlogT)O(K/\Delta \log T)O(K/ΔlogT)。ϵ-Greedy 算法(注释 6)在根本上效率低下,因为它不会自适应地将探索引导到表现更好的臂。因此,它的遗憾率规模为 T2/3T^{2/3}T2/3(对于最优设置的 ϵ∼T−1/3\epsilon \sim T^{-1/3}ϵ∼T−1/3)。固定这样的 ϵ\epsilonϵ 时,遗憾在较简单实例上不会改善。贪婪算法(注释 5)根本不进行探索,这导致了后缀失败。这在算法初始化时每个臂只有一个样本(n=1n = 1n=1)时显而易见:当好的臂返回 0,而其他某个臂返回 1 时,发生后缀失败。然而,后缀失败并不是小 nnn 的伪影:它们可以在任意 nnn 下发生,其概率规模为 Ω(1/n)\Omega(1/\sqrt{n})Ω(1/n)(Banihashem et al., 2023)。
5 讨论与开放问题
我们的研究表明,当代 LLM 在进行非常基本的统计强化学习和决策问题所需的探索时并不表现出稳健性,至少在没有进一步干预的情况下如此。接下来,我们识别出几个下一步,以进一步评估这一假设并寻找减轻这种行为的干预措施。
** 基本干预措施与方法论的进展需求**
鉴于我们的负面结果,可能考虑的最明显的干预措施包括:
-
实验其他提示:与许多其他设置一样(Sclar et al., 2023),小的提示模板变化可能会改善性能。然而,对提示设计的敏感性已经令人担忧。
-
实验少量提示:在提示中包含探索行为的示例,利用这些示例微调 LLM,或整理训练语料以包括探索行为的示例。
-
训练 LLM 使用辅助工具:例如,使用计算器进行基本算术或“随机化器”从分布中正确抽样。
尽管这些步骤相当自然,但成本、模型访问和计算能力对进一步研究构成了重大障碍,特别是因为需要采用较长时间范围 (T) 和多个复制 (N) 以获得统计上有意义的结果。因此,我们认为进一步的方法论和/或统计进展以实现对 LLM 代理行为的成本有效诊断与理解(例如,我们的替代统计)至关重要。
对复杂决策问题的启示
我们对简单多臂赌博问题的关注提供了一个干净且可控的实验设置,以研究 LLM 的探索行为及潜在的算法干预。这里的探索失败表明,在更复杂的强化学习和决策环境中也会发生类似的失败。另一方面,在开发缓解措施时必须谨慎,因为在 MAB 设置中成功的解决方案可能无法推广到更复杂的设置。例如,虽然 Gpt-4 在我们的 MAB 设置中使用摘要交互历史和强化 CoT 似乎成功进行了探索,但在复杂、高维观察的设置(如上下文赌博)中,如何外部总结历史尚不明确(见注释 1)。实际上,即使对于线性上下文赌博,没有实质性的算法干预(例如,外部计算的线性回归并包含在提示中)和涉及的许多显式建模和算法选择,这种方法可能也不适用。我们认为深入研究算法干预措施对于理解 LLM 作为决策代理的能力范围至关重要。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)