多token预测造就更好更快的LLM
这是一篇发表在24年ICML上的一篇论文,乍一看和博客里的那篇好像,当时讨论到怎么训练并行预测token的几个transformer头的时候,认为将每个头的交叉熵损失的均值作为整体损失的话,内存开销太大,改为每个批量就随机选一个子损失,企图从长期看这种估计无偏,这篇论文似乎直面并解决了这个内存开销的问题。在训练语料的一个位置,模型一次性预测未来n个token,学习目标为努力最小化交叉熵损失方便起见
论文链接:Better & Faster Large Language Models via Multi-token Prediction
这是一篇发表在24年ICML上的一篇论文,乍一看和博客分块并行解码里的那篇好像,当时讨论到怎么训练并行预测token的几个transformer头的时候,认为将每个头的交叉熵损失的均值作为整体损失的话,内存开销太大,改为每个批量就随机选一个子损失,企图从长期看这种估计无偏,这篇论文似乎直面并解决了这个内存开销的问题。
模型架构
在训练语料的一个位置,模型一次性预测未来n个token,学习目标为努力最小化交叉熵损失
方便起见,假设大语言模型用一个共享主干
来产生上下文
的潜在表示
,再加上n个独立的输出头
并行预测未来的n个token,和一个公共的反向嵌入矩阵(unembedding matrix,用于将模型的嵌入向量转换回标记空间)
,如下图有4-token示意图
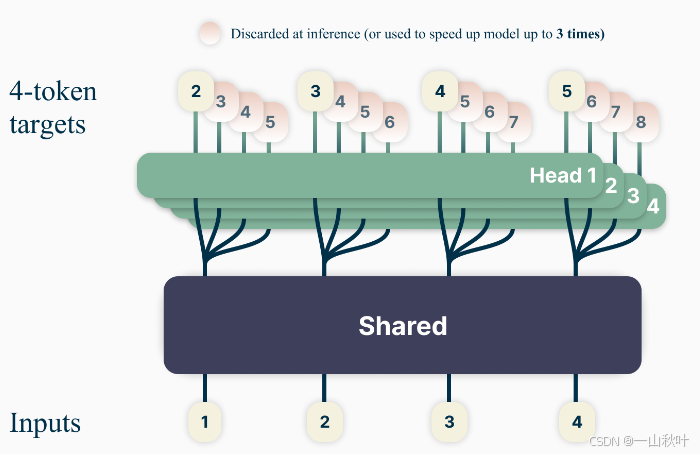
据此对交叉熵损失进行因式分解
预测未来n个token的过程就是计算,for
,其中
正是next-token预测头。
训练的一大挑战就是如何节约在GPU上的内存占用。回想一下那些大语言模型,词汇表的大小远大于潜在表征的维度
,logit向量(每次测试时给词汇表里所有的token打分)就是内存瓶颈。在这里,通过顺序执行所有头上的前向/反向操作,避免同时存储所有反向嵌入层的梯度,减少GPU内存的峰值使用(
)。
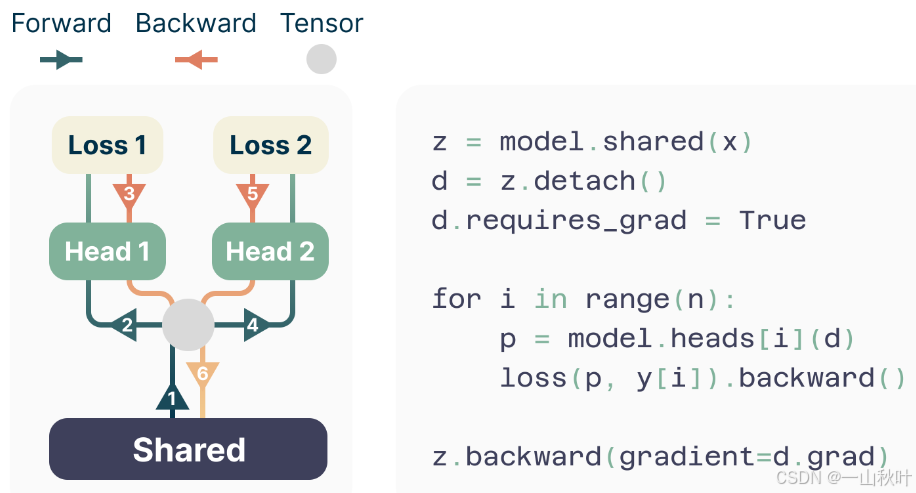
上图中以两个头为例,前向走过共享主干,顺序执行各个头
的前向、反向,期间都会回到主干累积梯度,为
创建logits及其梯度,但在去下一个头之前这些都会被释放,需要长期保存的只有
维的主干梯度
,这样做还不会引入很多额外的运行时间,怎么做到的呢?a suboptimal use of Fully Sharded Data Parallel!次优的全分片数据并行,为啥次优?因为每个头的后向计算是单独进行的,每层权重的通信和计算没法重叠,这会有很轻微的开销,要是重实现的好的话可以去掉,怎么能做到呢?
在真实数据上的实验
论文中用7个在真实数据上的大规模实验探究多token预测的有效性。
1.模型规模
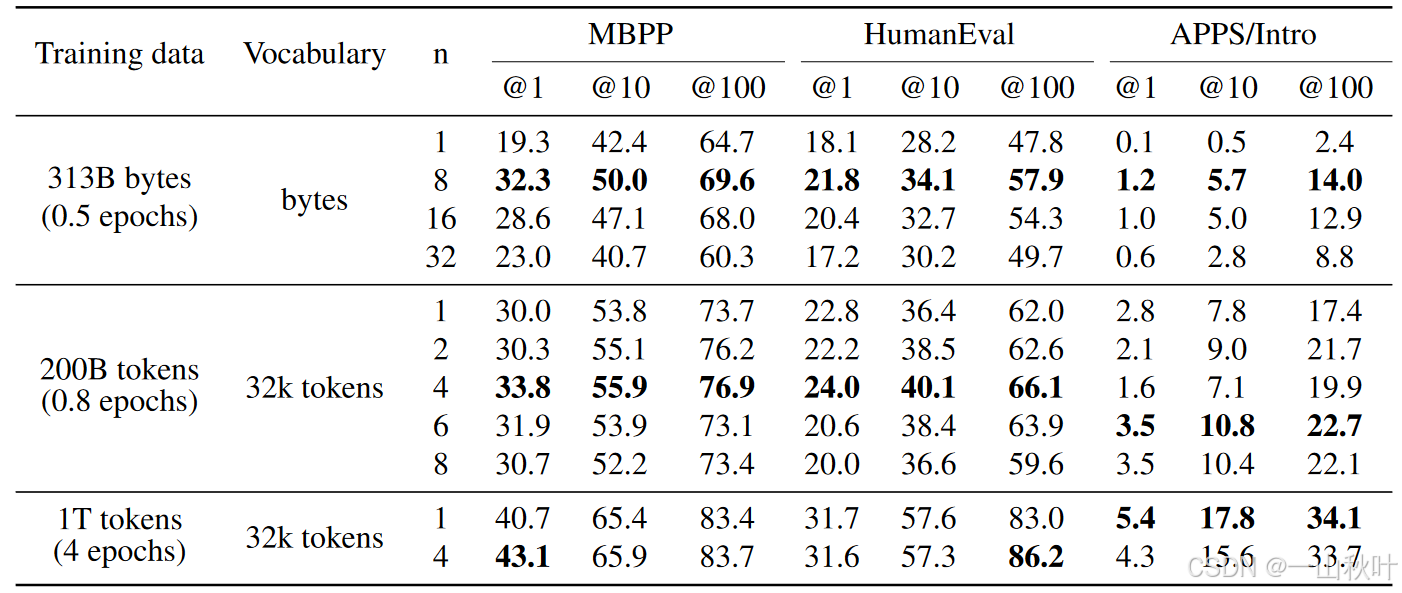
将6个参数量在0.3B到13B的模型,在至少91Btoken的代码数据上,从头开始训练。然后在数据集MBPP和HumanEval上测试它们的性能表现,如下图
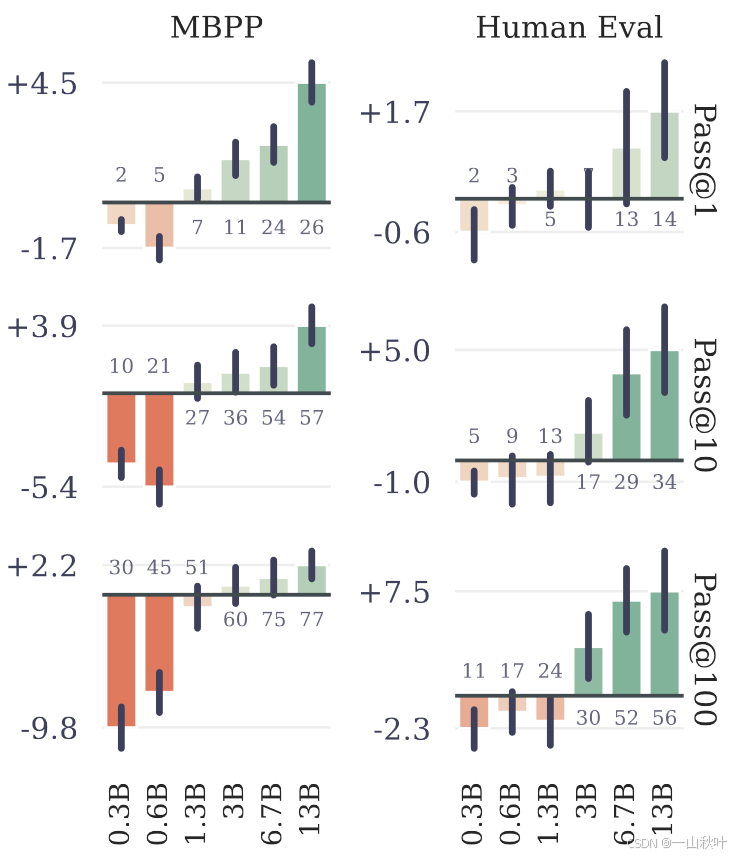
图中的评价指标有pass@1、pass@10和pass@100,用于评估在特定测试条件下,模型生成代码的正确性和有效性。 条状代表相较于基线的表现好坏,绿色更牛,红色更逊,长度表程度。黑粗的延伸线是误差条,代表数据点用自助法(bootstrapping,一种统计重采样方法)算出来的90%的置信区间,其上下延申的范围代表数据点真实值可能的落点。
作者认为,作为一种在LLM训练中表现优异的潜力股,多token预测一直以来都被极大忽视的一个可能原因便是,其有效性只在模型规模够大时才能显现(usefulness only at scale)。
2. 更快推理
推理时,最基本的想法是就用next-token预测头,做next-token自回归预测,别的头都不用了。但实际上其他头可以通过自投机解码(self-speculative decoding)的方式加速解码过程,例如分块并行解码(一种无需额外的草稿模型的投机解码变体——自投机解码)、带美杜莎式树形注意力的投机解码(又要再看一篇论文(;´༎ຶД༎ຶ`) )。
论文利用开源库xFormers,实现了异构批量大小的贪心自投机解码,还测量了他们最好的4-token预测模型的解码速度,这个模型带7B参数,用来从一个训练期间没见过的代码和自然语言测试集上提取prompts,平均下来每给3个建议的token,能被采纳2.4个,在编程任务上提速3倍,在文本任务上提速2.7倍。
3. 多byte预测
实际上next-token预测任务是过于依赖局部信息的,而多bytes预测更能学习到全局模式。为了展示这点,作者另整了字节级词化的极端案例,通过在314B 字节(约116B token)上训练出来一个有7B参数的字节级别transformer架构。相较于next-token预测,这个8-byte预测模型在MBPP pass@1和HumanEval pass@1上分别多解决了67%和20%的问题。拿1.7倍数据量训练出来的基于token的模型,性能也不过与它相当。多byte预测是开启字节级模型训练的一个很有前景的方法。
在8-byte预测模型上,采用自投机解码可加速6倍,完全可以补偿在推理耗时上字节级序列更长的开销,甚至速度是next-token预测模型的两倍。多token预测作为一种预训练策略,相较于传统的next-token预测模型,通过附加的输出头部可以显著提升模型的准确性,有利于解锁自投机解码的全部潜力。
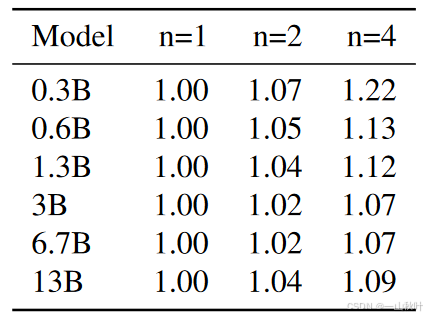
4. 最优n
作者对用200B 代码token训练出来的7B模型进行消融实验,尝试设置n=1、2、4、6、8,结果就看下图中的Training data=200B tokens那一行,在MBPP和HumanEval数据集上,一次预测未来4个token表现最好,而在APPS/Intro数据集上,n=6的设置可以分别领先0.7%、3.0%和5.3%,很可能是最优窗口大小取决于输入数据的分布啦。不过对于字节级别的模型就比较固定了,n=8时的表现在Vocabulary=bytes那一行一直稳定在最佳。
5. 多轮次训练
相同数据量下,增加训练轮次时,多token预测相较于next-token预测还是有优势的,图5中(4 epochs)那一行虽然相较于(0.8 epochs)那一行幅度小点,但在MBPP和HumanEval数据集上,分别在@1和@100那两列有2.4%和3.2%的性能提升,其它近似。到了APPS/Intro数据集,优势消失。
6. 微调多token预测器
主角:next-token预测的基准模型,那个老演员7B参数的4-token预测模型,还有把老演员额外的头去掉,用传统的next-token预测目标对其进行微调后的微调模型。
基准:CodeContests数据集,在这项研究里最有挑战性的编程类基准测试了。
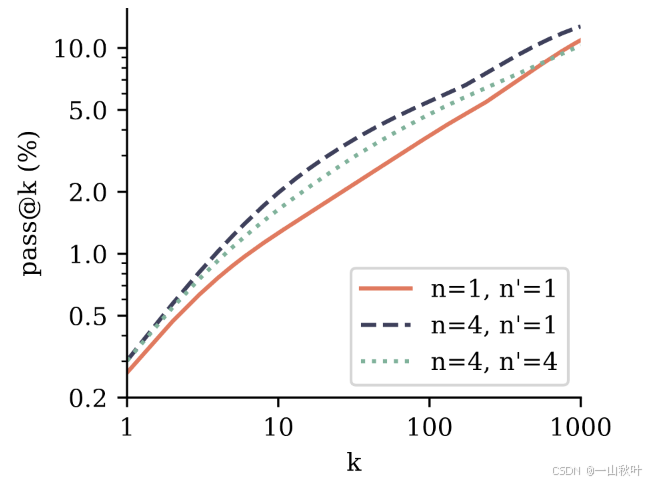
实验设置:为每个测试问题生成1000个样本,涉及5个不同的温度,在每个k值下,记录能达到最大pass@k的最佳温度T,形成一个“温度Oracle”,图中展示的就是特定k值下能达到的最大pass@k。
结果:老演员()去头后的老演员(
)在各个指标pass@k上都要优于next-token模型(
),在理解并解决任务和产生答案的多样性上都做得更好。
结论:在预训练好的4-token预测模型上进行next-token预测的微调是整体表现最佳的方法,这种训练策略也符合经典的训练范式,即先通过辅助任务进行预训练,再进行特定任务的微调。结果也展现了多token预测模型在微调阶段的有效性,尤其是在高难度编码任务中的优势。
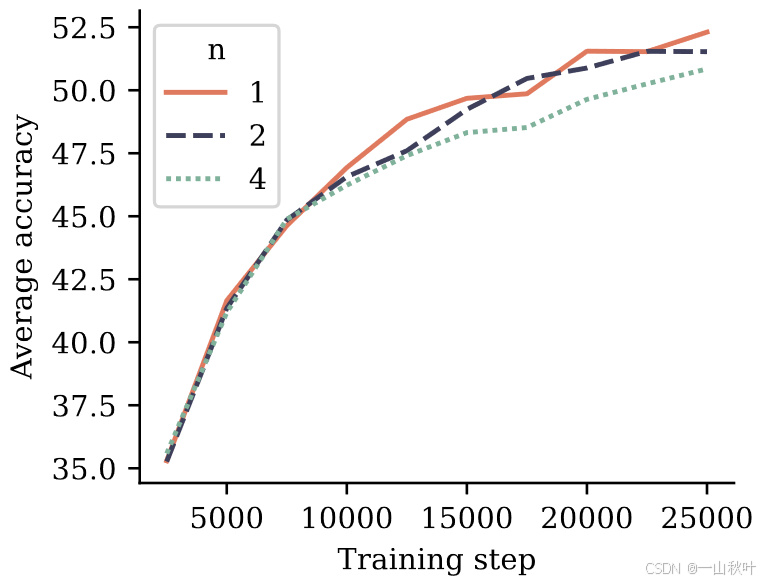
7. 在自然语言上的多token预测
前面的测试都是编程任欸好像,这又用了200B自然语言token训练出带7B参数的模型,损失函数有4-token、2-token和next-token预测的,拿训练出来的checkpoints在6个标准的NLP基准任务上做评估,后两个性能相当吧,4-token的性能有些下降。
但作者不认为这种存在多选且基于似然的基准能有效识别出语言模型的生成能力,(但怎么可能去人工判断模型的生成质量啦~)然后就自己修改了在摘要生成和自然语言数学基准上的评估体系,分别在200B和500B tokens的训练集下比较各式预训练好的模型。
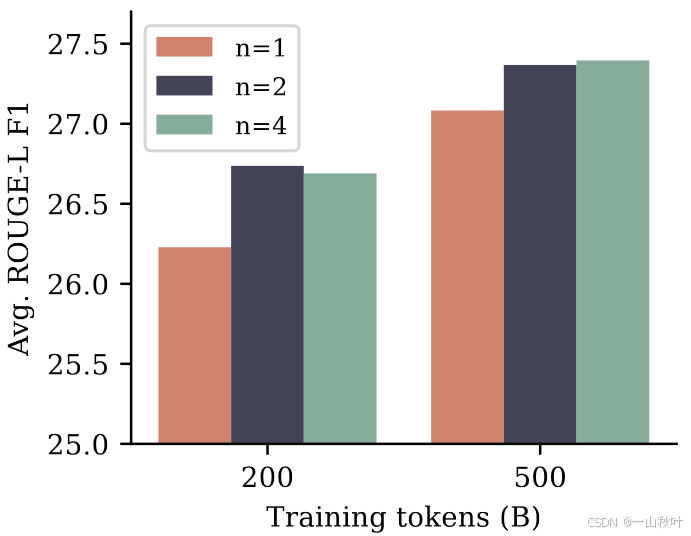
对于摘要生成任务,作者在8个基准上进行测试,采用会根据真实摘要对生成文本进行自动评估的ROUGE指标,在每个基准的训练集上对预训练好的模型微调3个epochs,选择在验证集上ROUGE-L F1分数最高的checkpoint。下图展示了相较于next-token基线,n=2和n=4的多token预测模型在指标ROUGE-L F1上的提升。训练集变大后,差距缩小。
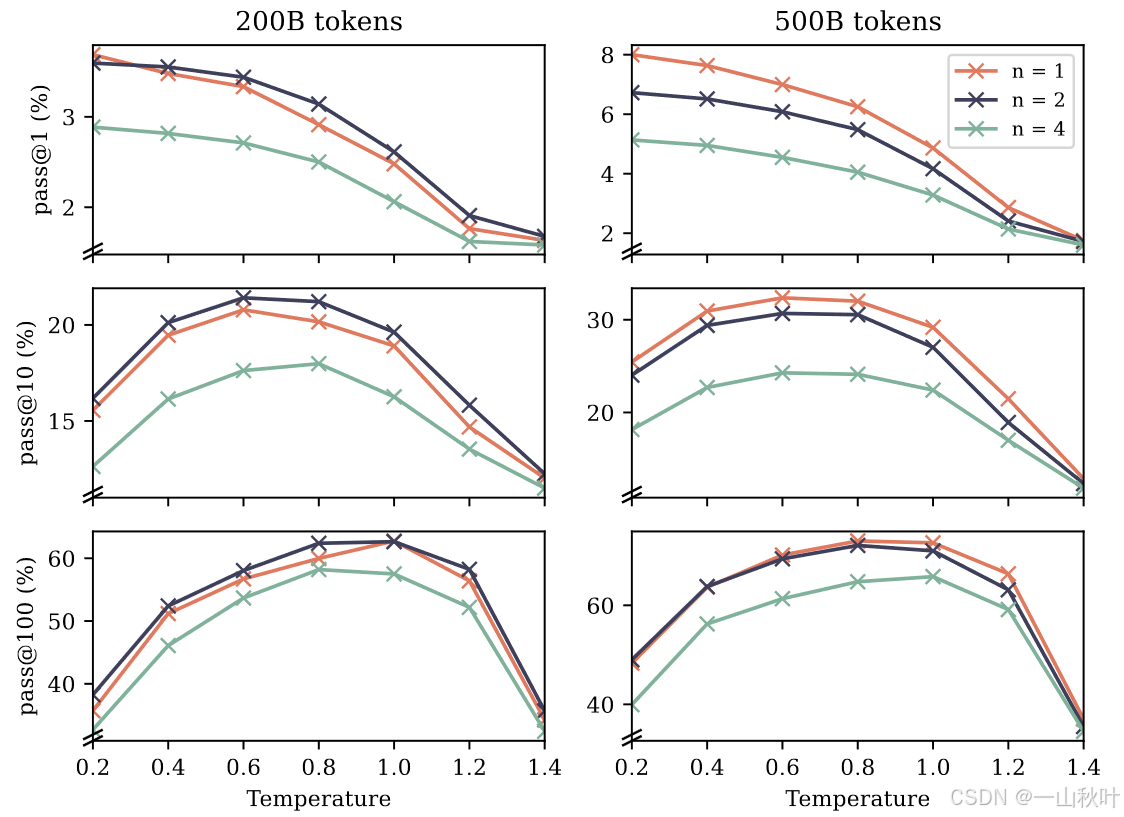
对于自然语言数学任务,作者对在GSM8K数据集上以8-shot模式预训练的模型进行评估,测量了由少量样本引发一连串思考后产生的最终答案的准确性,就像编程任务那样,用pass@k指标来量化答案的多样性和正确性。采样温度在0.2到1.4之间。下图结果显示,训练数据量为200B token时,n=2模型明显优于next-token,但在500B token时形式反转,而n=4的表现就一直很差劲了。
在合成数据上的消融
为什么多token预测能对上述所有任务的下游性能都有所改进(不见得吧,自然语言任务上表现得似乎就一般般啊,读到这里还没有很惊艳的创新点吧,倒是实验做了很多很多)?通过在受控的训练集和评估任务上进行玩具实验,作者发现多token预测会导致模型能力和泛化行为发生质的变化。
1. 归纳能力
归纳(induction)是指从已知数据或有限信息中推导出一般性规律、规则或模式,从而有效地对新的、未见过的数据进行预测。
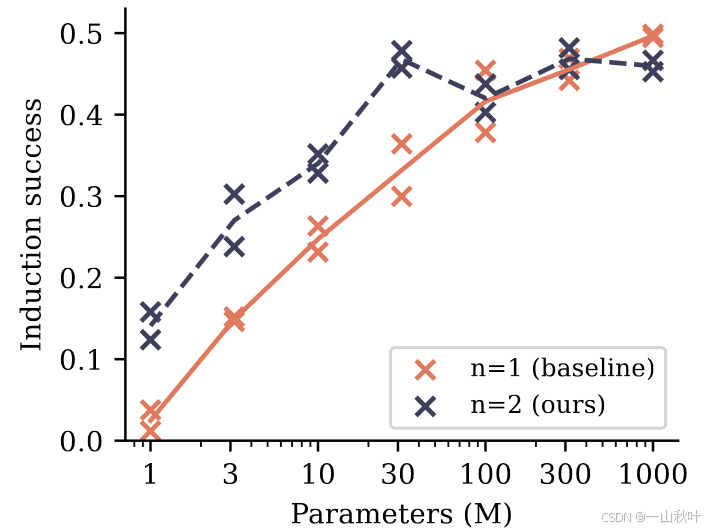
作者在一个儿童故事数据集上训练参数量在1M到1B之间(不涉及嵌入层,本实验中嵌入层参数和其他参数就没联系)的小模型。用分词器随机生成的含两个token的名字替换掉,原测试拆分的100个故事中的角色名。在预测这两个token时,第一个token的生成需依赖之前文本的信息和语境,到预测第二个token的时候就更多地依赖于归纳推理了。
实验训练超90个epoch,根据测试指标的表现决定是否提前停止训练(epoch oracle)。实验结果如下图,通过预测名字中第二个token的准确度来衡量模型的归纳能力,每个模型大小下用不同的随机种子运行两次(一列两个同色×),线条上是两次损失的均值。在30M及以下的小模型中,2-token的性能提升还是很明显的,但在100M及以上模型中优势就消失了(额外说明:最佳分数是达不到的,测试集中的名字在训练集中就没出现过)。
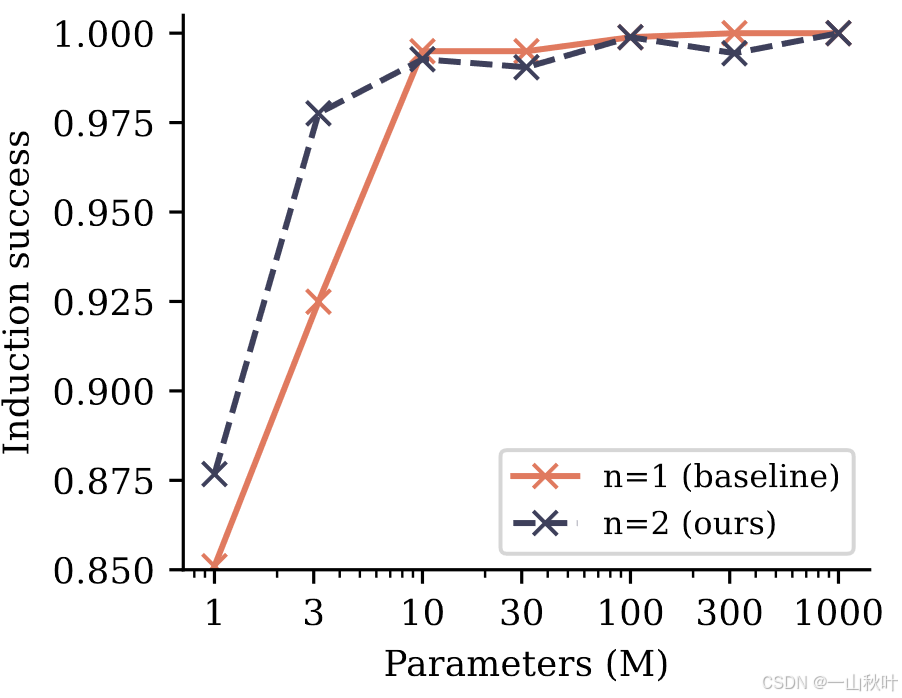
作者推测出现这样的结果的原因是,多token预测有助于模型跨序列位置传递信息,形成归纳头和其它上下文学习机制,增强在语义理解和文本生成方面的能力。 一旦归纳能力形成,next-token也可以通过近期的token学到。那么随着局部推理能力的提高,继续使用多token预测反而对模型性能有害,在执行简单推理任务时注意力分散。但多token预测在例如前文中那些更高级的上下文推理任务上还是有优势的。将书籍和儿童故事占比9:1混合,形成更复杂的数据集,在训练初期单用这个数据集来加速归纳能力形成,结果如下,除最小的两个尺寸外,其他规模下多token预测的优势全部消失,归纳特征的学习已经将这转化成一个单纯的next-token预测任务了。
2. 算法推理
比起纯归纳任务,算法推理任务能测量出更多语境推理中包含的模式。作者在环(元素是形如
的多项式)的多项式运算任务上训练和评测模型,涉及多项式的一元否定、加、乘和复合运算,操作数系数和算子都是均匀采样得到的,任务要求返回结果多项式的系数。
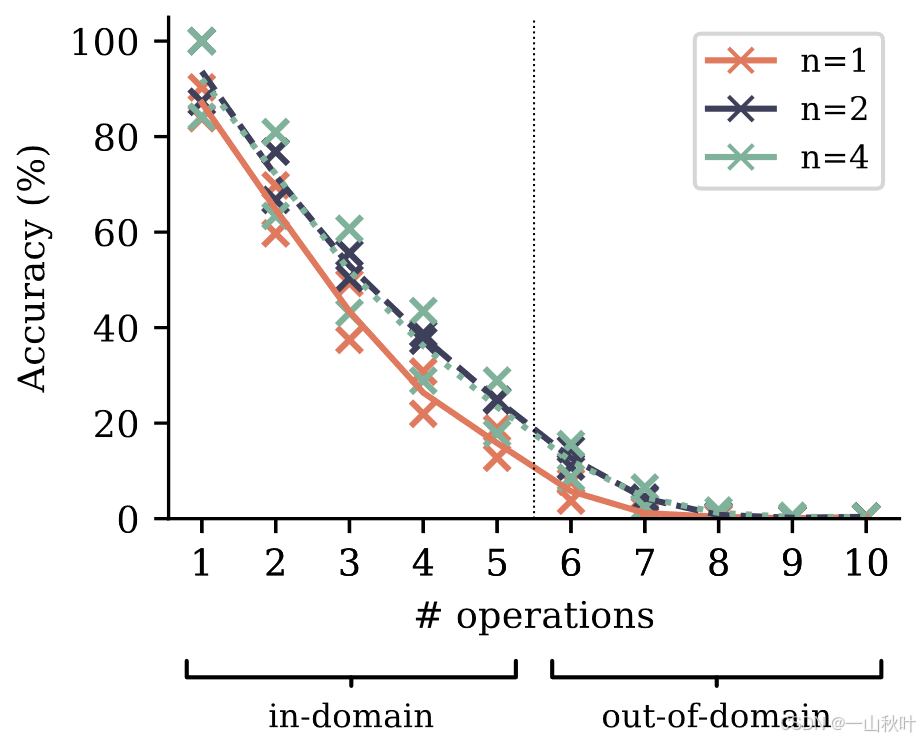
训练时表达式中包含的运算次数从1~5的范围内均匀选取,评测时可通过调节
来控制难度,当
时在领域内评估,即测试用的数据分布和训练时的一样,否则模型将在未见过的数据上进行测试,即领域外评估,更有挑战性。针对每个
,通过贪婪采样的方法生成2000个样本,形成测试集用来评估。
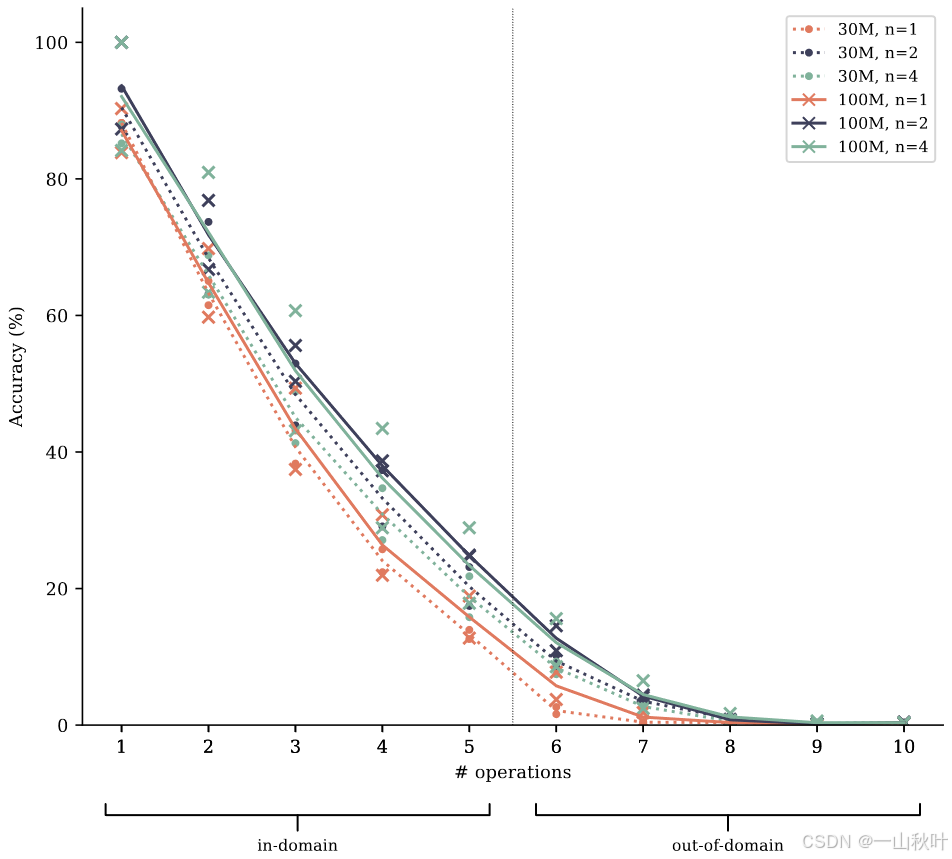
模型较小,有30M和100M参数量(不涉及嵌入层)两种,模拟了在海量文本语料上训练LLM的场景,欠参数化的模型无法记忆整个训练数据集。结果如下,多token预测提升了跨难度的算法推理能力。虽不是很明显,但在领域外评估中,还体现出很好的泛化性。
将模型参数从30M增至100M进行测试,如下结果表明在提升测评准确度这方面, 还不如用多token替代next-token预测。
作者认为可以用computation-sharing hypothesis(计算共享假设)来解释多token预测在训练时的有效性:自然文本中不同的token的预测难度是能有很大差异的,有些token可以轻易从前文推断出来,而有的,尤其一些复杂名词,如数学公式或特定术语,则可能要求模型进行更为复杂的推理和计算。语言模型上的残差连接会逐层优化输出token的分布,早退策略能够动态调节在每个token位置的计算资源,多token预测损失鼓励相邻token之间的信息共享,学习将计算资源更有效地分配给最受益的token。
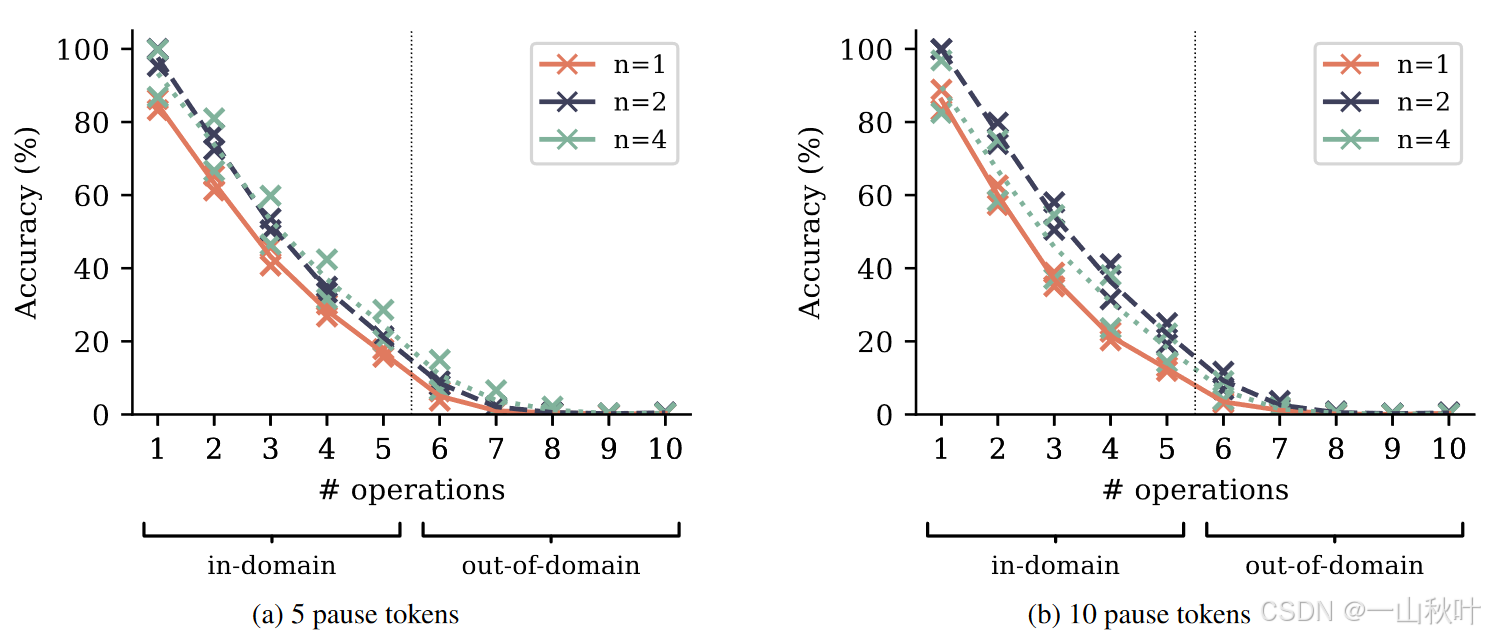
为了检验上述假说的真实性,作者在多项式算术任务基础上将不同数量的暂停token插在问题和标志答案开始的token之间,使模型在产生答案之前能进行更深入的推理,利用这些“暂停”进行全面的分析,为后续提供额外的计算资源。按照计算共享假说,多token预测在学习信息共享和计算共享上更具优势,也许能比next-token更好地利用这些资源。
结果如下图,虽说在应对这个任务变体,不同难度下多token预测都要表现好点,但也没看到这种差距扩大或缩小的有力证据,不能从实验中得出这个计算共享假说的准确性(感觉结论还是蛮直觉的,但这个证明过程有种白忙活一场的无力感)。
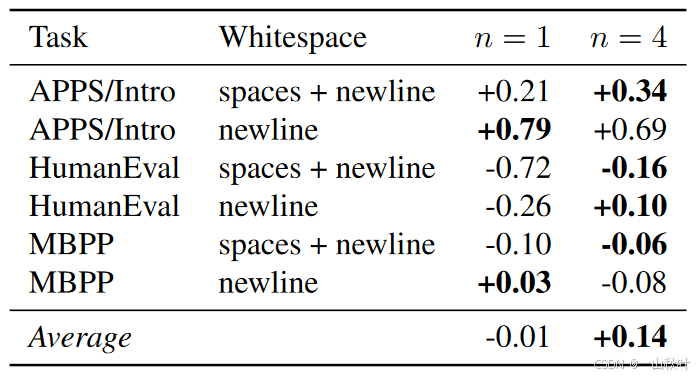
作者又以同样的想法,在HumanEval和MBPP(前文提到过的 code benchmarks)的prompts中通过添加空格和新行的方法,稍微自然地引入暂停token,从结果来看,多token预测在使用这个额外提供的计算资源上稍有优势,但微乎其微。
为何有效的一些猜测
对于多token预测有效性原因的一种猜想是,它缓解了训练时教师强制(训练时直接使用正确的目标序列作为输入)和推理时自回归生成(推理时将自己之前生成的输出作为后续时间步的输入)两种技术在输出上的分布差异。一是多token预测模型隐式分配token权重的机制,二是基于信息论的损失分解。
1. 前瞻强化选择点
对于语言模型生成有用文本这件事,并非所有token的决策同等重要。某些token允许文本在风格和表达上有多样性,对文本的其它部分没有限制,比如叙述时使用不同的形容词能丰富文本的表现力,但不影响文本的逻辑结构。而有的token可就代表“选择点”了,和文本的高层语义属性密切相关,可能决定文本是有用还是脱轨。
多token预测根据token与其后继者的关联程度为它们隐式地分配权重。在下图的例子中,进行3-token预测时,有一个难以预测的“选择点”(consequential),其它转折点就相对容易了,算“不甚重要点”(inconsequential)。
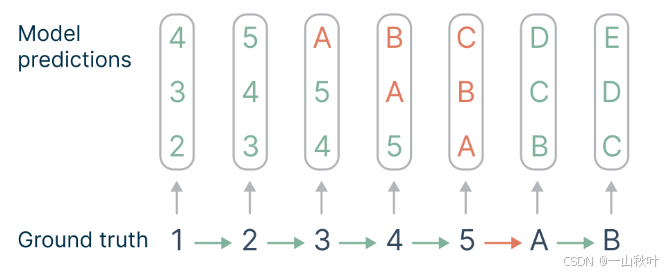
通过标记和统计损失项,作者发现n-token预测在计算总体损失时,依据相关性将权重分配给了“选择点”,把小权重
分配给了“不甚重要点”,确保模型在训练时更加关注这些不易预测的转换。生成文本质量如何取决于能否正确挑出“选择点”,而n-token预测损失正好有助于此。
2. 信息论论证
语言模型常通过teacher-forcing(教师强制)进行训练,用真实token预测未来token,作者认为这样可以保证模型在短期内的预测效果,但潜在风险就是会忽略更长期的依赖关系。用信息论论证,表示未来下一个token,
表示下下个token,它两都是输入文本
的语境下产生的,简单起见在方程中忽略,预测
之前,next-token关心的是质量
,而2-token志在
,分解一下式子
解释一下,信息熵是量化信息不确定性的重要标准。
是前缀
条件下的经典next-token熵,当
提供的信息有助于预测
时,
通常会低于
;条件熵
表示已知后缀
的情况下,
的不确定性,是一个更为理论化的概念,在实践中未必会对模型的文本生成起到实质性支持,尤其在单向生成的上下文中;
为互信息,表示
和
之间的相关性,衡量了知道
能为
(相互的)提供多少额外的信息。
2-token在同时预测和
时,并不考虑在已知
条件下对
的预测不确定性,所以舍弃
,更加注重
,考虑程度成倍增加,在生成文本的过程中,
和
之间的关系更加紧密。不过这个观点是基于多token预测损失可以通过类似于熵分解方式优化的假设提出来的。
给个严谨点的证明过程,用表示
和
的联合概率,
和
是
和
的边缘概率,
、
、
是分别对应的预测分布情况,KL散度
则用来衡量实际分布
和模型预测分布
之间的差异,有
还有另一种常用度量——交叉熵,表示和
之间的“信息损失”,有
条件交叉熵表示在条件
下,真实分布
和预测分布
之间的交叉熵,就一期望值,即有
相对互信息定义如下
其中计算的是
和
在边际分布下的KL散度,表示当两者独立时,模型预测和实际分布之间的差异。也可以将互信息分解成交叉熵的计算,即
调换和
的位置,相对互信息的值不变,可以为负值。而
就退化成在分布
下标准的互信息了。下面开证
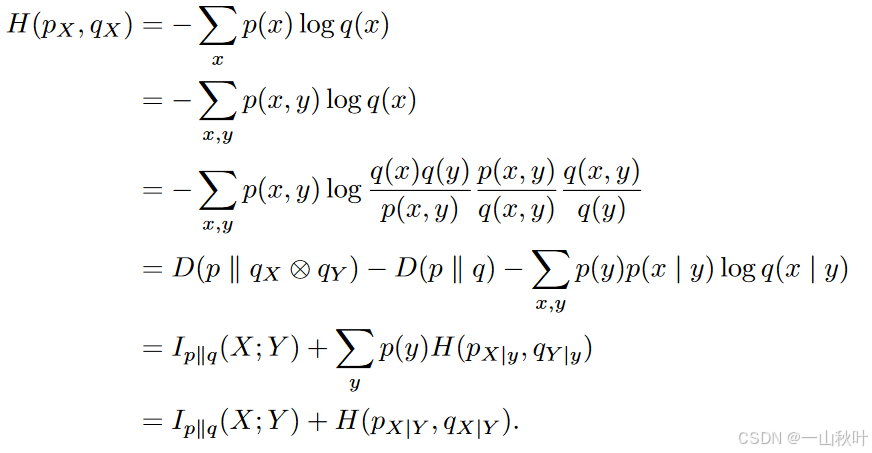
对称化后,得到期望的 的相对版本:
左边是用于训练2-token预测模型的交叉熵损失,右边将其分解成一个局部交叉项、一个权重为2的互信息项、一个next-token交叉熵项。2-token预测通过在损失中添加这一项,激励模型去预算特征,利于在下一步预测
,同时增加了相对互信息项在损失中的权重。相对互信息究竟意味着什么?上面有个把它分解成两个KL散度做差的式子,这个值小也就意味着
学到了在
分布下
和
的相关信息。(信息论看的我想吐啊!😭)
写在最后:对于论文用顺序处理头的方式回避内存峰值的做法,我感觉会让训练没那么高效,它说可以不引入额外时间成本,但似乎没有做很详细的处理办法。很大一点是它真的做了很多实验和分析,我遭不住了,请大佬们不吝赐教😭

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)