手把手教你理解机器学习中的“线性回归”
线性回归是机器学习的“第一课”,核心是通过数据找到最佳拟合直线,并用数学方法优化参数。掌握它的原理和实现,能为后续学习逻辑回归、神经网络打下基础。记得在实际应用中,结合数据特点选择合适的变体(如正则化方法),才能让模型更精准可靠!
嗨,大家好,我是心海!
线性回归是机器学习中最基础且实用的算法之一,广泛应用于房价预测、销量分析、医学诊断等领域。
本文将以通俗易懂的方式,从原理到代码实现,带你完整掌握线性回归的核心链条。
当然,本文是结合博主个人理解编写,如有错误,欢迎指正!
目录
一、线性回归是什么?
核心思想:通过一条直线(或超平面)拟合数据,预测因变量(目标)与自变量(特征)之间的线性关系。
举个栗子🌰:假设你想根据房屋面积预测房价,线性回归会找到一条最贴合数据点的直线,比如公式:
房价 = 面积 × 斜率 + 截距
这里的“斜率”和“截距”就是模型要学习的参数
数学上,最简单的形式是:
其中:
- y 是预测值
- x 是输入特征
- w 是权重(斜率)
- b 是偏置(截距)
这种形式可以推广到多变量情形,
两类模型:
- 一元线性回归:1个特征(如面积) → 简单直线拟合。
- 多元线性回归:多个特征(如面积、卧室数、地段) → 多维超平面拟合
本文主要以一元线性回归为例进行讲解。
二、原理拆解:如何找到最佳直线?
1. 损失函数(均方误差 MSE)
为什么需要误差函数(损失函数)?
在实际应用中,数据通常存在噪声,预测值与实际值之间会有一定的差距。为了度量这种差距,我们引入误差函数。常见的选择是均方误差(Mean Squared Error, MSE):
其中 N 为样本数量。
2. 参数求解方法
最小二乘法:
直接通过数学公式计算最佳参数(适合小数据),目标就是找到使得误差函数 J(w,b) 最小的参数 w 和 b。这也是线性回归的核心思想。
梯度下降:
通过“试错”逐步调整参数(适合大数据),向下坡找最低点
梯度下降是一种迭代优化方法,通过不断更新参数来逐步减小误差函数。
更新公式为:
其中 α 为学习率,控制步长大小。
三、手把手实战:Python代码示例
下面的代码示例展示如何用 Python 实现一元线性回归,并绘制散点图和拟合直线的图示
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
# 设置 matplotlib 使用支持中文的字体
plt.rcParams['font.family'] = 'SimHei' # 使用黑体字体
# 解决负号显示问题
plt.rcParams['axes.unicode_minus'] = False
# 生成模拟数据
np.random.seed(42)
# 生成 100 个数据点,x 的范围在 0 到 10 之间
x = np.linspace(0, 10, 100)
# y 与 x 存在线性关系,同时加入噪声
true_w, true_b = 2.5, 1.0
noise = np.random.randn(100) # 高斯噪声
y = true_w * x + true_b + noise
# 使用最小二乘法求解参数(正规方程)
X = np.vstack([x, np.ones(len(x))]).T # 构建设计矩阵
theta_best = np.linalg.inv(X.T @ X) @ (X.T @ y)
w_est, b_est = theta_best
print(f"估计参数:w = {w_est:.2f}, b = {b_est:.2f}")
# 绘制数据点与拟合直线
plt.figure(figsize=(8, 5))
plt.scatter(x, y, label='数据点', color='blue', alpha=0.6)
plt.plot(x, w_est * x + b_est, label='拟合直线', color='red', linewidth=2)
plt.title('一元线性回归示例')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.grid(True)
plt.savefig("linear_regression.png") # 保存图片
plt.show()执行上面代码,我们可以得到
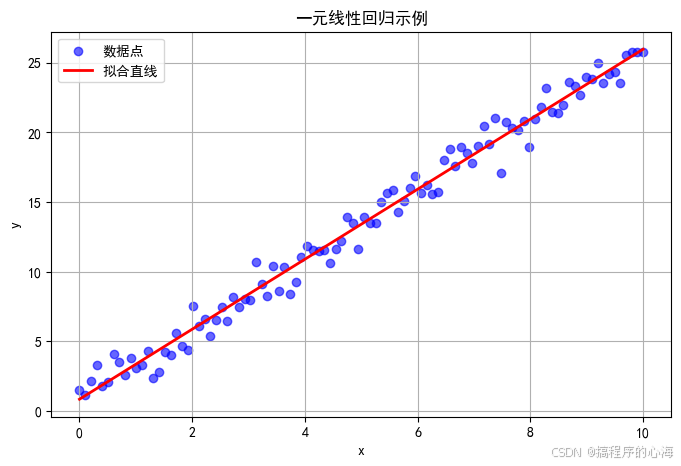
其中,蓝色散点代表数据点,红色直线即为拟合的线性模型
代码补充解释
对于机器学习初学者,可能会对上面代码有比较多不理解,这里稍微补充解释一下两部分
true_w, true_b = 2.5, 1.0
noise = np.random.randn(100) # 高斯噪声
y = true_w * x + true_b + noise
这里我们设置了真实的模型参数,假设数据符合关系
使用 np.random.randn(100) 生成一个长度为 100 的数组,这些数字服从标准正态分布(也叫高斯分布)。
这里的 噪声 模拟了现实中数据的随机波动,使得数据不可能完全落在一条直线上。
所以上面代码就是原公式加上噪声
这样生成的数据既包含了我们设定的线性关系,又有一些随机误差,使得数据更贴近实际情况。
X = np.vstack([x, np.ones(len(x))]).T # 构建设计矩阵
theta_best = np.linalg.inv(X.T @ X) @ (X.T @ y)
w_est, b_est = theta_best
np.vstack([x, np.ones(len(x))])
这一步将数组 x 和一个全是 1 的数组(长度与 x 相同)垂直堆叠在一起。
这样做的目的是构造一个包含两部分的矩阵:
- 第一部分是 x 的数值,用来表示数据的输入特征。
- 第二部分是 1,用于表示偏置项 b(截距),这样就可以把截距问题转化为矩阵运算。
然后,调用 .T 实现转置,将上面得到的 2 行 100 列的矩阵转置为 100 行 2 列的矩阵,这样每一行就代表一个数据样本,包含两个特征:
这种矩阵通常被称为“设计矩阵”。
X.T @ X
这里的 @ 是 Python 中的矩阵乘法符号。X.T 是设计矩阵的转置,它与 X 相乘后得到一个 2×2 的矩阵。
这一步是正规方程(Normal Equation)求解过程中的一部分,用于计算最优参数的解析解。
np.linalg.inv(X.T @ X)np.linalg.inv 函数用于计算矩阵的逆。这里的计算,是在正规方程中用于“消除”设计矩阵对参数的影响,从而解出参数。
X.T @ y
这一步将设计矩阵的转置 与目标变量 y 相乘,得到一个 2 维的向量。它代表了输入特征与输出值之间的线性关系。
theta_best = np.linalg.inv(X.T @ X) @ (X.T @ y)
将前面两步的结果相乘,就得到了最小二乘法下的最佳参数
这一公式的数学表达是:
这个公式直接给出了能够最小化均方误差的解析解。
w_est, b_est = theta_best
最后,我们将求得的参数向量 theta_best 拆分成两个变量:
w_est是估计的斜率b_est是估计的截距
四、模型评估:如何判断模型好坏?
R²值(决定系数)
R²值反映了模型对目标变量方差的解释能力,取值范围在 0 到 1 之间。
越接近 1,说明模型对数据的解释能力越强;如果 R² 值很低,说明模型拟合效果不佳。
其中:
是真实值
是模型预测值
是真实值的平均值
- N 是样本总数
残差图
检查预测误差是否随机分布(理想情况无规律)
残差是指真实值与预测值之间的差异。
理想情况下,残差应当随机散布在 0 附近,不呈现明显的规律。如果残差图中存在系统性的模式,可能表明模型存在欠拟合或其他问题。
接下来,我们对前面测试代码进行验证
from sklearn.metrics import r2_score
# 计算预测值
y_pred = w_est * x + b_est
# 计算 R² 值
r2 = r2_score(y, y_pred)
print(f"模型的 R² 值: {r2:.3f}")
# 绘制残差图
residuals = y - y_pred
plt.figure(figsize=(8, 5))
plt.scatter(x, residuals, color='purple', alpha=0.6)
plt.axhline(y=0, color='black', linestyle='--')
plt.title('残差图')
plt.xlabel('x')
plt.ylabel('残差 (真实值 - 预测值)')
plt.grid(True)
plt.show()
得到结果如下
![]()
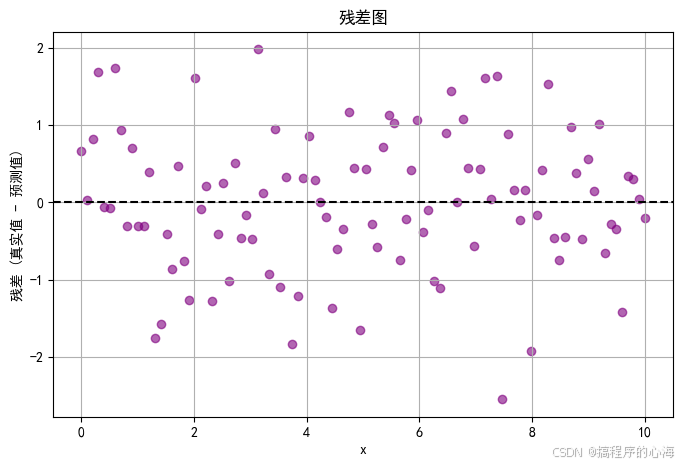
从图中可以看出,R² 值接近 1 ,残差点大致呈随机分布,均匀散落在残差为 0 的水平线上方和下方,并没有明显的模式或趋势
这样就表明你的线性回归模型拟合效果较为理想,至少在一元线性假设和噪声随机分布方面没有明显违背。
五、总结
线性回归是机器学习的“第一课”,核心是通过数据找到最佳拟合直线,并用数学方法优化参数。
掌握它的原理和实现,能为后续学习逻辑回归、神经网络打下基础。记得在实际应用中,结合数据特点选择合适的变体(如正则化方法),才能让模型更精准可靠!
这篇文章求解参数我们使用了最小二乘法,而更常用的梯度下降我们在后面的文章再进行分析!
如果这篇文章对你有所启发,期待你的点赞关注!

往期精彩推荐

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)