李哥深度学习(一)神经网络概述和python基础
最简单的神经网络,没有激活函数,只能进行线性运算。单纯的线性运算无论有多少层,都可以通过化简变成y=wx+b的简单形式,没有意义。
一、简单的神经网络
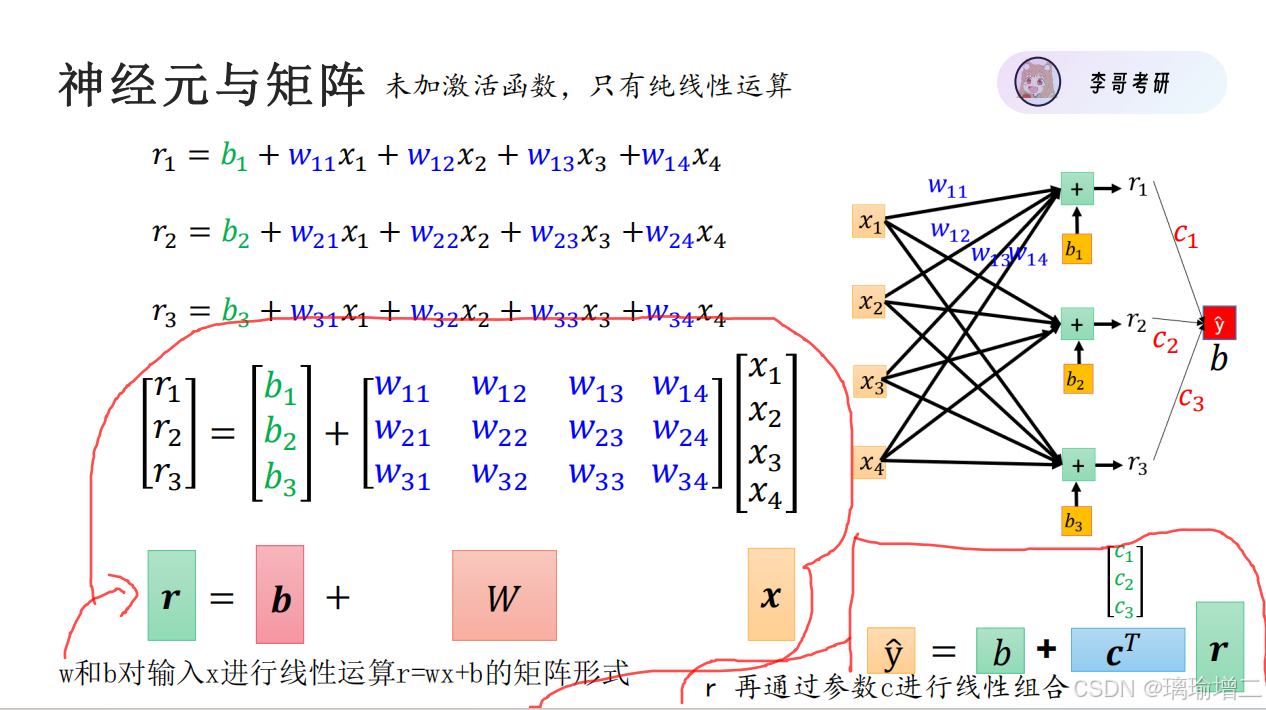 最简单的神经网络,没有激活函数,只能进行线性运算。
最简单的神经网络,没有激活函数,只能进行线性运算。
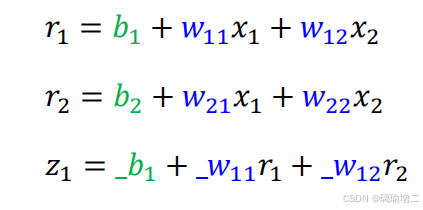

单纯的线性运算无论有多少层,都可以通过化简变成y=wx+b的简单形式,没有意义
二、激活函数
激活函数为神经网络带来了非线性元素,可以逼近任何非线性函数,解决现实中非线性问题了
sigmoid激活函数
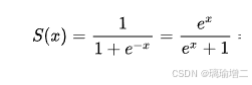
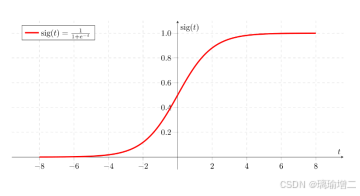
Relu激活函数
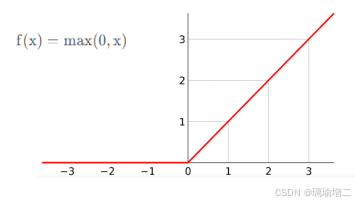 大于0的时候为x,小于0的时候为0
大于0的时候为x,小于0的时候为0
激活函数相关知识
-
激活函数最重要的要求:可求导,方便后面梯度回传和梯度下降
- relu和sigmoid优缺点对比:
-
relu优点:
- 计算效率高: ReLU的计算只需要判断输入是否大于零,因此比Sigmoid等需要指数运算的函数要快得多。
- 缓解梯度消失问题: 在正数区间(x > 0),ReLU的梯度恒为1,这有助于减轻深层网络中的梯度消失问题。
- 缺点:死亡ReLU问题: 当输入为负时,ReLU的梯度为0,这意味着权重更新停止,可能导致部分神经元永久失效,即所谓的“死亡ReLU”。
-
Sigmoid优点:
- 概率解释: Sigmoid函数的输出范围在(0, 1)之间,适合用于二分类问题的概率预测。
- 缺点:梯度消失: 当输入远离原点时,Sigmoid函数的导数趋近于0,这会导致梯度消失,使得深层网络难以训练。
- 计算复杂: 需要进行指数运算,这比ReLU的简单比较操作要耗时。
三、有了激活函数以后的神经网络
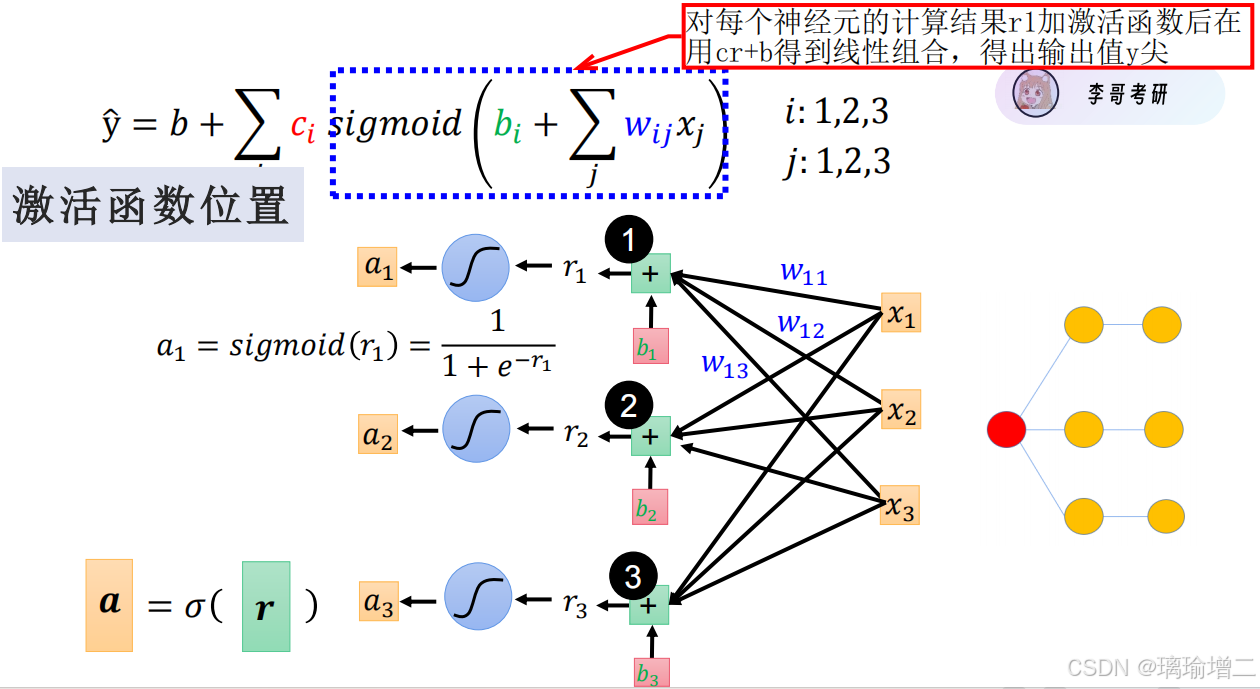
四、神经网络的参数(可训练的)
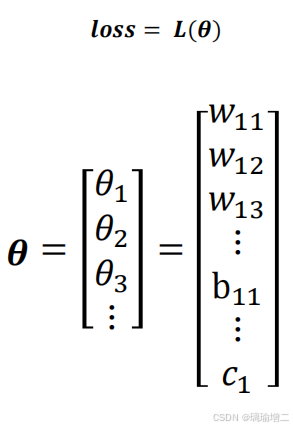
𝜽用来代表神经网络中所有可以训练的参数,𝒍𝒐𝒔𝒔 = 𝑳(𝜽)表示loss函数
五、深度学习的训练过程
- 模型前向,通过输入x算出预测值y尖
- 计算损失函数,损失函数可以通过各种数学方式设计,最简单的是|y-
|
- 计算损失函数对每个参数的导数(梯度)
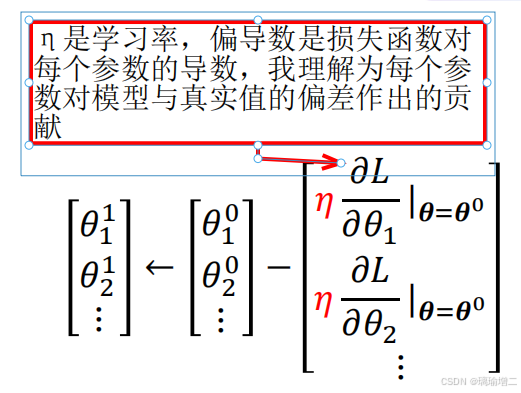
-
这种网络叫做Fully Connected Network,简称FC,全连接网络,也叫多层感知机
六、早期的一些深度学习网络
- AlexNet(2012):8层,错误率约16.4%
- VGG(2014):19层,错误率7.3%
- GoogleNet(2014):22层,错误率6.7%
- Residual Net(2015):152层(采用残差连接防止梯度消失,实现高层网络训练)错误率3.57%。 (residual n.残余物;残渣adj.残余的;剩余的)
七、模型结构对学习效果的影响(深浅、过拟合、和界外预测)
模型过浅会导致无法很好模拟(欠拟合),模型过深会导致过拟合。
模型界外预测能力:模型在训练集上表现很好,不代表能力就强,界外预测能力是模型处理没见过的同类数据的能力,训练时要划分训练集和验证集,通过模型在验证集上的表现,来评估模型的界外预测能力
八、python基础
- 数据结构
#数据结构_赋值_整型、浮点型、列表、字典、字符串 a = 3 print(a) b = 4 print(a, b) a, b = b, a#python支持多变量承接 print(a, b) name = "ligekaoyan" print(name) print(name[2])#输出g #列表list list1 =[1, 2, 3, 4, 5] print(list1) print(list1[1]) print(list1[-1])#输出5,-1表示倒数第一个 #字典(哈希表) #key :value dict1={"name": "ligekaoyan","age": 28,20: 80} print(dict1["name"]) print(dict1["age"]) print(dict1[20])#键值不一定是字符串 #python对列表的要求很自由,列表的元素可以是数、字符串、另一个列表或者字典等 list2 =[1,list1,dict1,"hi"] print(list2) -
判断 缩进 空值
#判断 缩进 空值 a = 3 if a == 3: print("正确的") print("今天天气好") if a == 4: print("错误的1") print("错误的2") b = 4 if a == 3: if b > 3: print("正确的3") else: print("b不大于a") #选中代码,按shift+tab,会向前缩进一级(四个空格) if a != 4: print("错误的4") A = None if A == None: print('A是空的') -
循环
#循环 #for i in 范围 list = [1,2,3,4,5] for i in list: print(i) for i in 10#错误,in后面是范围(可迭代对象) for i in range(1,10): #输出1-9,python的范围是左闭右开的 print(i) for i in range(1,10,2):#1是开头,10是结尾, 2是步长,输出13579 print(i) dict1={"name": "ligekaoyan","age": 28,20: 80} for each in dict1: print(each,dict1[each])#可以循环遍历字典,返回key值 -
列表切片、插入、删除
#切片 插入 删除 list1 = [1,2,3,4,5] for each in list1: print(each) #切片,切出来还是个列表 print(list1[1:4]) #左开右闭,打印[2,3,4] print(list1[1:-1]) #到最后一个截止,打印[2,3,4] print(list1[1:]) #冒号后面没有值,表示到最后结束,打印[2,3,4,5] print(list1[:]) #冒号前后没有值,表示从头到尾,打印[1,2,3,4,5] for i in list1[1:4]: print(i) list2 = [1, 2, 3, 4, 5, 6] print(list2) list2.remove(6)#按值删除列表里的元素 print(list2)#[1, 2, 3, 4, 5] del list2[3]#按下标删除列表里的元素 print(list2)#[1, 2, 3, 5] list2.append(7)#在列表末尾增加内容 print(list2)#[1, 2, 3, 5, 7] list2.extend([8,9,10])#在列表末尾增加新的列表 print(list2)#[1, 2, 3, 5, 7, 8, 9, 10] #循环后置 list3 = [i for i in range(10)] -
加减乘除 、传入 、格式
# 加减乘除 传入 格式 a = 3 b = 2 print(a+b) print(a-b) print(a*b) print(a/b) print(a//b)#地板除,只保留整数部分 print(a**b)#乘方,a的b次方 #返回A的平方 def myfunc1(A): c = A**2 return c #返回A的b次方 def myfunc2(A,B): c = A**B return c #如果有传入b就返回a的b次方,如果没有就返回a的平方 def myfunc3(A,B=2):#带等号的默认值必须放在后面 c = A**B return c print(myfunc2(a,b)) print(myfunc3(a)) -
类和继承
#类,深度学习模型 #集成很多属性和自己的函数,如果是这个类的实例,就能用类的东西 class person(): def __init__(self,name,age): self.name = name self.age = age def print_name(self): print(self.name) def print_age(self): print(self.age) laoli = person("ligekaoyan",28)#实例化 print(laoli.name) print(laoli.age) print(laoli.print_name()) #输出ligekaoyan none,第一个是调用函数,第二个是函数返回值为空 #继承 # class superman(): #这样的重复定义过程太繁琐了 # def __init__(self,name,age): # self.name = name # self.age = age # self.fly_ = True # def print_name(self): # print(self.name) # # def print_age(self): # print(self.age) # # def fly(self): # if self.fly_ == True: #加下划线是为了和fly函数做区分 # print('我会飞') # # # lige = superman("lige",28) # lige.print_name() #超人本质上也是个人 class superman(person):#Superman是person的子类 def __init__(self, name, age): super(superman, self).__init__(name, age) #去引用父类的init函数,并自动绑定好self,所以后面的括号里不用加self #貌似super后面的括号里也不用加(superman, self),看小甲鱼的课就没加也能找到父类 self.fly_ = True def fly(self):#与父类不同的函数可以继续追加定义 if self.fly_ == True: #加下划线是为了和fly函数做区分 print('我会飞') lige = superman('lige',28) lige.fly() lige.print_age()#继承后可以使用person的函数super()函数能够在父类中搜索指定的方法,并自动绑定好self参数
6的补充内容(super())
super是在类的集成过程中去调用父类的init方法的一种函数,
在单继承且不加参数的情况下,super()返回的是一个类,super().__init__(*args)的作用相当于Foo1.__init__(*args),其中这个Foo1是当前类的唯一父类,这句调用了父类的init方法来对当前类的参数进行了设置.
在多继承且不加参数的情况下,super()会按照MRO顺序调用父类的__init__方法,解决了多继承过程中的钻石继承问题,可通过obj1.__class__.mro()的方法来查看一个对象的mro顺序
- 但是这种调用需要mro链条上的每一个父类都使用了super()语句,即使是并列关系的基类也一样,否则链条断开,只能调用到最近一个写了super()语句的父类
-
People的mro顺序为People→Foo1→Foo2→Object class Foo1: def __init__(self, name, height, weight, hehe): super().__init__(hehe) #即使Foo2和Foo1是并列关系的父类,也要在Foo1上写这句super(),否则调用就只到Foo1为止 self.name = name self.height = height self.weight = weight class Foo2: def __init__(self, hehe): self.hehe = hehe class People(Foo1, Foo2): def __init__(self, name, height, weight, hehe): super().__init__(name, height, weight, hehe) pe = People('name', # Foo1.name 11, # Foo1.height 22, # Foo1.weight 'haha') # Foo2.hehe print(pe.hehe) # 打印出haha
在多继承且加参数的情况下,super(cls, obj).__init__(*args)会调用obj的mro顺序中cls类的上一级父类的__init__方法对obj进行初始化,跳过cls这个父类的__init__方法
class AnotherFoo1:
def __init__(self, hp):
self.hp = hp
class AnotherPeople(AnotherFoo1):
def __init__(self, hp):
super().__init__(hp)
ape = AnotherPeople(100)
print(ape.hp)#此时ape的hp是100
#以上是一个无关的其他类的设定和实例化,父类是AnotherFoo1
#############################################################
class Foo1:
def __init__(self, name, height, weight):
self.name = name
self.height = height
self.weight = weight
class Foo2:
def __init__(self, hehe):
self.hehe = hehe
class People(Foo1, Foo2):
def __init__(self, name, height, weight, hehe, hp):
super(Foo1, self).__init__(hehe)
super(AnotherPeople, ape).__init__(hp) # 调用一个与当前类无关的对象和类的init方法
#主要关注的People类,他的父类分别是Foo1和Foo2
#########################################################################################
pe = People('name', #Foo1.name
11, #Foo1.height
22, #Foo1.weight
'haha', #Foo2.hehe
200) #AnotherPeople.hp
print(pe.hehe) # 打印出haha
print(pe.name) # 未能打印出'name',因为super跳过了Foo1的__init__方法
# 报错AttributeError: 'People' object has no attribute 'name'
print(
pe.__class__.mro()) # 这是pe的mro顺序 [<class '__main__.People'>, <class '__main__.Foo1'>, <class '__main__.Foo2'>, <class 'object'>]
print(ape.hp) # 打印出200 甚至可以从people类中用super方法调用另一个完全无关的类的init方法,并修改那个类对象的属性(虽然并没有什么软用)
- 7.矩阵(numpy)
import numpy
import numpy as np #numpy是矩阵的包
import torch #torch就是pytorch,里面有把矩阵转化成张量(tensor)的方法
list1 = [
[1,2,3,4,5],
[6,7,8,9,10],
[11,12,13,14,15]
]
print(list1)
list2 = [
[-1,-2,-3,-4,-5],
[-6,-7,-8,-9,-10],
[-11,-12,-13,-14,-15]
]
array1 = np.array(list1) #把list1转化为矩阵
print(array1)
array2 = np.array(list2)
print(array2)
array3 = np.concatenate((array1, array2)) #把两个矩阵合起来
print(array3) #array3变成了6*5的矩阵
array4 = np.concatenate((array1, array2), axis=1) #把两个矩阵合起来,横向,axis表示轴,axis=0表示向下,=1表示向右合并
print(array4) #array3变成了3*10的矩阵
#矩阵切片(可以切到中间的方框)
print(array1[1:3, 2:5])
print(array1[:, 2:5])
#跳着切
idx = [1,3]
print(array1[:, idx])- 8.张量(tensor)
import torch
list1 = [
[1,2,3,4,5],
[6,7,8,9,10],
[11,12,13,14,15]
]
print(list1)
tensor1 = torch.tensor(list1) #把list1转化为张量,转化为张量后就能放到模型的张量网上进行计算了
print(tensor1)
x = torch.tensor(3.0)
x.requires_grad_(True)#表示x需要计算梯度
y = x**2
y.backward()#求y对y中所有参数的梯度,若表达式为y=x**2+w,则也会对w求梯度
print(y)
print(x.grad) # 输出tensor(6.),x^2求导为2x=6
#x = x.detach() #把x从张量网上摘下来,不再计算梯度
y2 = x**2
y2.backward()
print(x.grad)#此处输出tensor(12.),因为y和y2都对x计算了梯度
tensor2 = torch.ones((10,4))
tensor3 = torch.zeros((10,4))
tensor4 = torch.normal(0,0.01,(10,4))#正态分布,平均值为0,标准差为0.01,十行四列的张量
print(tensor2, tensor3, tensor4)
#张量求和
sum1 = torch.sum(tensor2)
print(sum1) #输出tensor(40.),对10*4全一张量进行了求和
sum2 = torch.sum(tensor2, dim=0)#dim=0表示竖向相加
print(sum2) #输出tensor([10., 10., 10., 10.])
sum3 = torch.sum(tensor2, dim=1, keepdim=True)#dim=1表示横向相加,keepdim=True表示保持形状
print(sum3) #输出为十行[4.],
print(tensor1.shape)#输出torch.Size([3, 5])表示张量的形状-
9.引用
from my_tensor import tensor1 from myclass import superman可以从其他文件里引入需要的变量,会自动运行其他文件的代码

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 35
35 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)