数学建模竞赛论文评审优化协商方案
大数据时代下,如何利用数据信息,调配资源,合理分配任务是提高系统效能的关键。本文针对数学建模竞赛中论文评分差异过大相关的分数协商分配问题,利用了非线性整数优化、多目标优化及动态演变分析等方法,建立了论文评分协商最优分配模型、有约束的论文协商分配模型和多目标约束协商优化模型。通过MATLAB编程计算,求解得到了最佳的协商方案。
系统简介
大数据时代下,如何利用数据信息,调配资源,合理分配任务是提高系统效能的关键。本文针对数学建模竞赛中论文评分差异过大相关的分数协商分配问题,利用了非线性整数优化、多目标优化及动态演变分析等方法,建立了论文评分协商最优分配模型、有约束的论文协商分配模型和多目标约束协商优化模型。通过MATLAB编程计算,求解得到了最佳的协商方案。
针对问题一,首先利用数据信息构造协商关系图,将论文协商分配问题转化为协商关系图的最大边覆盖问题,建立了非线性整数优化模型,并运用遗传算法进行求解模型,得到最优的协商分配方案,整个协商过程耗时仅28min。
针对问题二,考虑到不同教师协商工作大小的差别,构造了加权的协商关系图,将老师间协商任务量作为协商关系图中边的权值,在每一轮迭代过程中,动态更新协商关系图中边的权重,建立了动态约束目的优化模型,并运用粒子群算法求解优化方程,在协商教师互不相识的情况,得到最佳的协商分配方案,整个方案耗时65min。
针对问题三,鉴于三位老师的特殊情况,将整体论文协商分配问题转化多个协商子问题,分步构造目标优化子模型,从而结合形成有约束多目标优化模型,并提出迭代的多目标遗传优化算法,通过计算,求解得知此条件下的最优协商分配方案,整个协商过程耗时64min,三位老师花费24min结束协商,符合需在14:30之前结束协商的需求。
关键词 非线性整数优化 多目标约束 遗传算法 最大边覆盖 论文协商分配
1.问题重述
现在对大学生数学建模论文评审,每篇论文由三名老师独立打分,如果最低分和最高分差距超过10分,需要两位老师面对面协商,两人修改自己的分数,修改完后不需要再进行一次修改。如果一人空着,另一人与别的老师协商,那么前面的这位老师需要等待。如果两位老师不熟悉,需要取得联系,这需要花费一点时间。如果两位老师熟悉,不需要再在取得联系上花费时间,协商用时会短一些。下午14:00协商开始。
问题一:如何安排,使得全部协商完后需要的时间最少?
问题二:由于老师之间互相不熟悉,一名老师新找一名老师协商需要4分钟。问如何安排,使得全部协商完后需要的时间最少?
问题三:有三位徐州(赵老师、周老师、林老师)的老师赶时间坐车,需要优先协商完,要求三位徐州的老师全部协商完的时间不迟于下午14:30(越早结束越好),问在满足三位徐州老师时间的条件下,如何安排,使得全部协商完成后需要的时间最少。
2.符号说明
针对上述问题,本文建模了单目标、多目标的优化模型,为便于大家理解本文所提的优化模型,这里将建模过程中主要应用到的符号作如下说明,具体符号及其物理意义如下所示:
符号 物理意义
, 第i篇论文
n篇论文
第i位评委
评委老师集合
打分矩阵
协商矩阵
第i位老师与第j位老师协商情
当前参与协商矩阵
矩阵的第行
矩阵的第列
第t分钟评委老师间协商次数矩阵
T 协商时间
3.问题分析
在大学生数学建模论文评审过程中,每篇论文由三名教师独立打分,如果最低分和最高分差距超过10分,需要两位老师面对面协商,两人修改自己的分数。注意到每次协商过程中,只能是两位面对面协商,即不能出现3或多位教师共同协商的情形。此问题与经典的任务分配类似,需要给出具体的协商方案,以使整个协商过程时间最短,这就涉及到单指标/多指标的优化问题。
表1所示,此次需要协商的论文共计39篇,共涉及陈、陆、钱、邱、孙、吴、俞、张、赵、范、费、林、牛和周14位评委教师间的协商问题。图1统计了各位评委老师共需要协商次数情况,可以看出最大需要协商的次数为11次,最小需要协商的次数为2次,其中,周、吴、邱三位评委老师的协商任务均超过10。分析不难发现,所以老师完成协商最短时间为44min。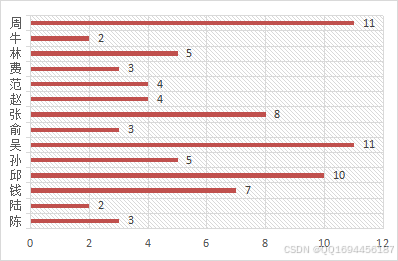
图1 各评委老师协商次数
问题1要求给出最佳协商方案,使得全部协商完成时间最短。问题2在问题1的基础上,增加了寻找评委老师的时间。问题3则基于问题1、问题2提出优先安排三位徐州(赵老师、周老师、林老师)评委教师,确保这三位教师在最短时间内完成自己的协商任务,同时也使得剩余评委老师协商任务在尽可能短的时间内完成。三个问题均为优化问题,问题2/3则增加了相应约束条件,则可认为是有约束的优化问题。
为使总协商时间最短,需要尽可能降低等待机会,即尽可能安排所有需要协商的教师尽可能多地参与协商。建模过程中,我们根据表1中打分情况,构造协商关系图邻接矩阵,需要协商的位置用大于1的数表示,不需要协商的教师间取值为0,这里数值大小表示两位老师间的最大协商次数。则整个协商过程可转变为对协商关系图的最大边覆盖问题。每轮协商问题可转化为在协商关系图中找到最大不相邻边。通过不断迭代,知道协商关系图所以的边都被覆盖到,则整个协商过程全部完成。
4.模型的建立与求解
问题一模型的建立与求解
模型的分析及建立
问题1要求给出最佳的协商安排方案,以使得整个协商进程时间最短。针对此问题,为简化模型,建模过程中,本文对其进行必要的限定,作如下假设:
1)假设需要协商的两位老师,当且仅当协商一次,即即使多篇文章需要协商,只需协商一次便可完成所有任务;
2)对于每篇论文,三位老师打分出现重复且最高分最低分差距超过10分时,只需与其中一位老师协商(所给数据中不存在此情况);
3)假设两位需要协商老师需要协商多篇论文,其总共所需时间仍为4分钟;
4)评委老师只协商共同打分的论文。
基于上述假设,下面给出具体的建模方法。设现有n篇论文记为,m位评委老师,其形成的打分矩阵记为,且有
则根据打分矩阵,可以获得需要协商的论文及对应的评委老师,则有:
文及对应的评委老师,构造如下协商矩阵,其满足:
其中,表示第i位老师与第j位老师协商情况,即有:
结合,不难发现
协商过程中,每位需要协商的老师可结合自身安排选择评委老师进行协商,但实际中,往往容易出现多个同时寻找一位老师协商,这就造成时间和资源的浪费。为此,需合理安排协商过程,确保协商过程在最短时间内完成。考虑到协商策略的变化并不影响总共需要协商的次数,也就是协商过程中的最短用时是一定的,因此,在制定协商策略过程中,只需尽可能避免两位或者多位评委老师同时找某一位评委老师的情况,即尽可能让所有需要老师参与协商但不重复即可。每一轮协商可视为在矩阵中寻找尽可能多不在同行同列的1,迭代直到矩阵中所有为1的元素都被遍历过,则有:
其中,表示矩阵的第行,表示矩阵的第列,,且满足:
不难发现,上述优化问题是有约束的非线性整数规划问题,该问题的可行域并非连续,采用一般的有约束的优化算法如梯度下降法、单纯性法、对偶单纯性法等求解比较困难。遗传算法(Genetic Algorithm, GA)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。其主要特点表现在:1)直接对结构对象进行操作,不存在求导和函数连续性的限定;2)具有内在的隐并行性和更好的全局寻优能力;3)采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地调整搜索方向。
遗传算法(Genetic algorithms, GAs)是在进化和自然遗传学原理指导下的随机搜索和优化技术,具有大量的隐式并行性。GAs在复杂、大型和多模态的景观中执行搜索,并为目的或优化问题的“灵敏度函数”提供近似最优解。在GAs中,搜索空间的参数以字符串(称为染色体)的形式编码。这样的字符串集合称为总体。在模式识别领域,为了获得最优解,需要在复杂空间中进行适当的参数选择和搜索,在分析和识别模式的过程中涉及很多任务。因此,将GAs应用于解决模式识别的某些问题(需要优化计算要求,以及鲁棒性、快速性和近似解)似乎是合适且自然的。遗传算法求解优化问题的一般步骤如图2所示,包括生成初始种群、计算适应度、选择、变异、交叉等,通过多次迭代,保留群体中最优个体,从而得到适合问题的最佳解。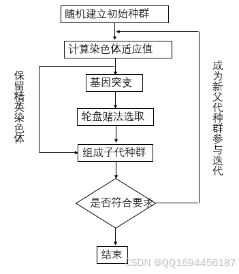
图2 遗传算法流程图
具体求解过程中,首先对题目中教师编号(如表2)非整数规划问题,先随机选择一定数量的原始染色体,这些染色体经过杂交,变异得到的染色体经过计算后,得到适应度。最终选择适应度最高的染色体。
表2 协商教师编号
教师 编号
陈 #1
陆 #2
钱 #3
邱 #4
孙 #5
吴 #6
俞 #7
张 #8
赵 #9
范 #10
费 #11
林 #12
牛 #13
周 #14
采用上述编号,结合表1,构造协商关系图邻接矩阵,并画出其对应的协商关系图,得到: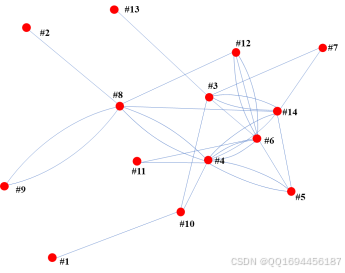
图3 协商关系图
模型的求解及结果
针对上述邻接矩阵,下面运用遗传算法对其进行求解,得到第一轮迭代结果如表3所示,其中,1所处位置对应的行和列所对应的老师参与本轮协商,0所处位置对应的行列所对应的老师不参与本轮协商。根据表3,不难发现,本轮所有老师均参与协商。
表3 协商关系矩阵
#1 #2 #3 #4 #5 #6 #7 #8 #9 #10 #11 #12 #13 #14
#1 0 0 0 0 0 0 0 0 1 0 0 0 0 0
#2 0 0 0 0 0 0 0 0 0 0 0 0 1 0
#3 0 0 0 1 0 0 0 0 0 0 0 0 0 0
#4 0 0 1 0 0 0 0 0 0 0 0 0 0 0
#5 0 0 0 0 0 0 0 0 0 1 0 0 0 0
#6 0 0 0 0 0 0 0 0 0 0 0 0 0 1
#7 0 0 0 0 0 0 0 0 0 0 0 1 0 0
#8 0 0 0 0 0 0 0 0 0 0 1 0 0 0
#9 1 0 0 0 0 0 0 0 0 0 0 0 0 0
#10 0 0 0 0 1 0 0 0 0 0 0 0 0 0
#11 0 0 0 0 0 0 0 1 0 0 0 0 0 0
#12 0 0 0 0 0 0 1 0 0 0 0 0 0 0
#13 0 1 0 0 0 0 0 0 0 0 0 0 0 0
#14 0 0 0 0 0 1 0 0 0 0 0 0 0 0
将表3对应的协商关系转化为具体的协商方案为:#1——>#9,#2——>#13,#3——>#4,#5——>#10,#6——>#14,#7——>#12,#8——>#11。完成本轮协商之后,从原始的协商矩阵中去除
根据第六轮协商关系图,则最后一次的协商方案为:#4——>#6,此时,协商关系图已无边即原始协商关系图中的所有边已经被覆盖过,所有的协商均已完成。
综合上述六轮协商过程,可得到整个过程的协商耗时:24min+4min= 28min。至此,完成整个协商需要耗时28分钟。
问题二模型的建立与求解
模型的分析及建立
问题2提到老师之间相互不熟悉,一名老师新找一名老师协商需要4分钟,在此种条件下,如何安排协商方案,可使得全部协商完后需要的时间最短。针对此问题,为便于建模,简化问题原型,在建模过程中,本文作如下假设:
1)不同评委老师协商一篇论文所需时间均为4分钟;
2)不同评委老师寻找协商评委所需时间相等,均为4分钟;
3)若需要协商多篇论文,则只需进行一次协商即可完成所有协商任务。
基于上述假设条件,考虑到评委老师之间互不熟悉,因此在评阅协商过程中,寻找对应的老师需要耗费一定时间,同时评委协商过程中,可能存在多篇论文需要协商,因而不同评委间协商所需时间不同,而在此期间,其他与正在协商的评委老师有协商需求的评委老师可选择等待或者继续寻找其他评委老师进行协商。设工作需要协商的论文总数为,当有m位评委老师时,定义协商次数矩阵表示t时刻协商次数矩阵的状态,表示第i位老师和第j位老师剩余协商次数,显然有,。假设协商总共经过T分钟,每1分钟评委老师间协商次数矩阵为,为便于计算,这里同样约束每分钟内不可存在两位评委同时寻找一位评委的情形,则有:
这里,,,,同时有:
根据的定义,则经过分钟,可以得到完成整个协商所需要的时间为:
其中,为的矩阵,且有:
综合上述,要使得整个协商过程时间最短,则有:
s.t.
其中,,分别表示矩阵第行,第列。不难发现上述优化问题是一个复杂的非线性的规划问题,模型中含有非线性约束条件,且目标函数非凸,因而,常规方法求解困难。
粒子群算法(Particle Swarm Optimization,PSO)是在1995年由Eberhart博士和Kennedy博士一起提出的,它源于对鸟群捕食行为的研究。发展该理论的一个动机是模仿人类的社会行为,这当然与鱼群或鸟群不同。重要的区别在于它的抽象性。鸟类和鱼类调整它们的身体运动,以避免捕食者,寻找食物和配偶,优化环境参数,如温度等。人类不仅要调整身体运动,还要调整认知或经验变量。我们通常不会步调一致地走路。尽管一些有关人类从众的有趣研究表明,我们有能力做到这一点;相反,我们倾向于调整我们的信念和态度,以符合我们的社会同伴。
模型的求解及结果
利用PSO生物智能优化算法,对上述问题进行求解。求解过程中,首先将协商关系图(图8)转化为带权值的协商关系图,如图9所示,图中边的权值表示两节点间共需协商的次数。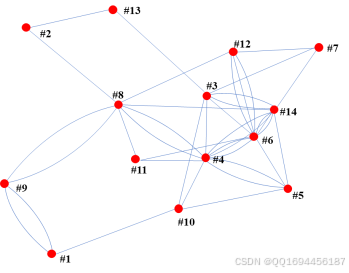
图8 协商关系图
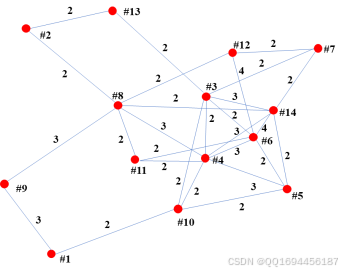
图9 加权协商关系图
调用粒子群算法,针对上述协商关系图,求解得到协商方案:#1——>#9,#2——>#13,#3——>#4,#5——>#10,#6——>#11,#7——>#12,#8——>#14,采取此协商方案后,更新协商关
问题三模型的建立与求解
模型的分析及建立
问题3提到有三位徐州(赵老师、周老师、林老师)的老师赶时间坐车,需要优先协商完,要求这三位老师全部协商完的时间不迟于下午14:30(越早结束越好),问在满足三位徐州老师时间的条件下,如何安排,使得全部协商完成后需要的时间最少。整个协商开始时间为14:00,也就是说尽量在半个小时内,三位老师的协商任务需全部完成。鉴于问题2中提到老师之间相互不熟悉,一名老师新找一名老师协商需要4分钟,对于有特殊安排的教师,在此题中,我们认为其为大家所熟知,即与其协商无须额外的寻找时间。而其他教师之间的协商则依然存在协商寻找时间。在建模过程中,本文作如下假设:
1)假设三位赶车老师之间协商优先级相同;
2)寻找三位优先安排协商的老师协商无时间消耗;
3)除三位老师之外其他教师之间的协商需要寻找时间,且寻找所需的时间为仍为4min。
现三位徐州老师需要赶时间乘车,需优先安排协商,记三位老师分别为,且,。实际中,这三位老师需要协商的论文数可能为1,2或多个,记与三位老师有协商需求的老师单独组成新的协商子集为,则剩余老师组成的集合,如图1所示,取协商矩阵中第,列中不全为0的行,构成子协商矩阵,则有:
此时对应的剩余老师构成的协商矩阵定义为剩余协商矩阵为:
这里,,,且,均为正整数。
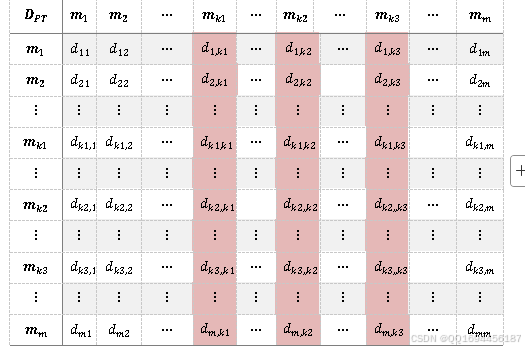
图14 协商关系矩阵
鉴于三位老师需要赶车,为确保协商过程顺利完成,则应使三位老师的协商任务尽早结束。实际中,三位赶车老师为评委老师中的特殊人群。为节约时间,这里假设这三位老师为大家熟知人员,即任何需要与这三位老师协商的其他评委老师均不需要花费4分钟的寻找时间,三位老师协商耗时只存在论文具体协商过程中。记m位评委老师协商关系矩阵为, 构造选择矩阵的矩阵如下:
则从与三位评委,对应的协商关系矩阵为:
容易得出,为矩阵去除元素全为0的行,即不妨将写为,为推导方便,这里将矩阵扩展为的矩阵:
为的全0矩阵。类比问题1,关于三位评委,对应的协商关系矩阵的优化,只需每次寻找中尽可能多不同行不同列的非0即, 其等效于,对于每次未协商老师即单次剩余矩阵,考虑到这些老师间存在互不相识,优化过程中存在寻找老师耗时,这个子问题的优化可采用问题二优化方法,此时,,这里,b表示矩阵点积,多次迭代直到矩阵中所有不为0元素均被覆盖到,且元素全为0,由于需要与三位提前走老师协商的评委也存在与综上可知,此问题为迭代的两目标的优化问题,单次多目标优化问题为:
目标1 :
目标2 :
s.t.
其中,,分别表示矩阵第行,第列,表示矩阵的第行,表示矩阵的第列。
模型的求解结果
上述优化问题为多目标约束优化问题,其求解过程相对复杂。为此,本文提出迭代的多目标优化算法,在迭代过程中,动态调整与三位老师无协商教师的协商关系子图,将整个问题,分解为两个子问题,依次分别进行求解,经过反复迭代,得到问题的解。其算法具体流程如下所示:
算法1:迭代多目标优化算法框架
输入: ,,,,标记矩阵
Repeat:
计算矩阵,
调用遗传算法,求解目标1、目标2的优化问题
更新 =,
,
Until: =
由于三位老师需要赶车,在优化过程中,将三位老师涉及的优化任务单独列举出来,形成协商关系子图,如15下所示,其中边的权值表示两节点点需要协商的次数。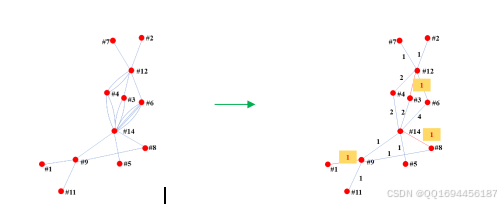
图15 三位老师(赵老师、周老师、林老师)协商关系加权图
采用遗传算法,针对上述协商关系子图,求解得到协商方案,第一分钟:#1——>#9,#3——>#12,#8——>#14;第二分钟:#7——>#12,#8——>#9,#3——>#14。采取此协商方案后,经过8分钟,去掉已完成协商任务的边,得到新的协商关系图,如下: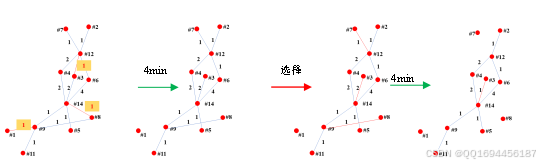
图16 三位老师8分钟内协商情况演变图
由于三位老师协商过程中,与其有协商关系的教师,可能未参与本次协商。为节约时间,这些需要与三位老师协商的教师可与其他正未协商的教师协商相应的论文。将无与三位老师协商的教师组合起来,构造剩余协商关系子图,如下图所示: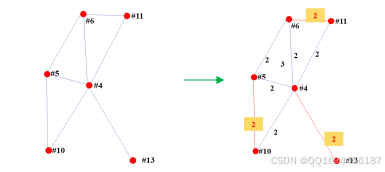
图17 剩余协商关系加权子图
同样,运用遗传求解得到,容易得到最佳的协商方案为:#5——>#10,#6——>#11,#4——>#13,对应的协商情况演变如图18所示。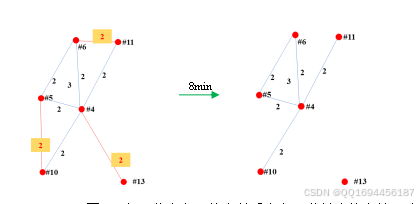
图18 与三位老师无协商关系老师8分钟内协商情况演变图
完成第一轮协商之后,需要对与三位老师的协商关系子图重新进行优化,即如下图所示,重新安排协商任务,这里继续运用遗传算法,求解得到论文的协商方案为:#11——>#9,#14——>#3,#2——>#12
三位赶车教师之间完成一篇论文协商需花费4min,而其他教师之间则需要花费8min,即其他教师在寻找协商老师的过程中,三位教师可完成一篇论文协商,这就产生时间差异。为最大化减小整体协商的时间,提高协商效率,模型中与三位老师存在协商关系的教师若在本次协商过程中空闲,则其可与其他教师协商。一篇论文不同教师间协商耗时差异,造成整个协商过程需动态调整,以确保在最短时间内,优先完成三位老师的协商任务。对比图1,图2可知,此轮协商安排,存在4min的差异,为充分利用时间,此轮继续为三位老师安排协商任务,求解得到协商方案为:#9——>#14,#4——>#12,此时的协商关系图为:
继续采用遗传算法求解,不难得到对应的协商关系演化关系如下所示:
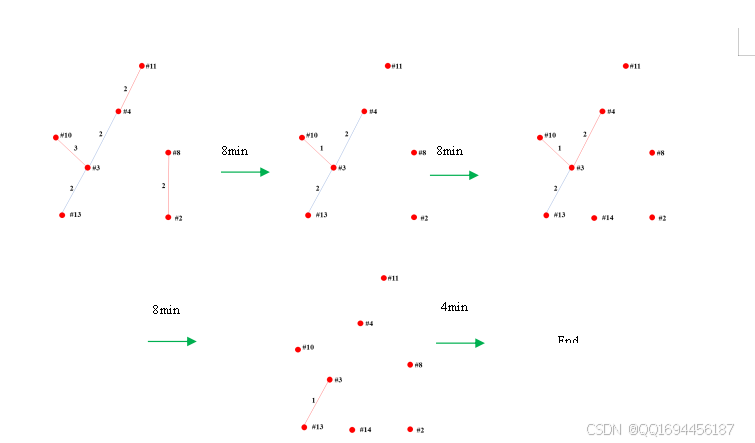
图28 剩余老师协商情况演变图
至此,完成整个优化过程,总计用时: 64min。
5.模型的优缺点
模型的优点
(1)运用遗传算法和粒子群算法的相关性的整合分析,建立了非线性整数规划模型,具有更强的说服力。
(2) 在建立模型中充分考虑了此问题当中的实际情况,根据不同的情况进行合理安排;
(3)在第三问中,巧妙的运用迭代的多目标优化算法解决了相关问题的类型和原因。
模型的缺点
(1)该模型仅仅局限于不真实数据数量少于真实数据的情况,当不真实数据过多时,该模型的说服力不够强
(2)问题一只考虑同一篇论文只能被两个老师打分,未涉及其他情况。
(3)问题三中已假设的是徐州三位老师互相认识,并未考虑互相不认识情况下的假设。
(4)由于知识的局限性,我们只能从较浅层次的去研究探讨,仅仅考虑了问题的主要因素,而对于众多次要因素并未进行深入探讨。
附 录
function main()
clear;
clc;
%种群大小
popsize=100;
%二进制编码长度
chromlength=10;
%交叉概率
pc = 0.6;
%变异概率
pm = 0.001;
%初始种群
pop = initpop(popsize,chromlength);
for i = 1:100
%计算适应度值(函数值)
objvalue = cal_objvalue(pop);
fitvalue = objvalue;
%选择操作
newpop = selection(pop,fitvalue);
%交叉操作
newpop = crossover(newpop,pc);
%变异操作
newpop = mutation(newpop,pm);
%更新种群
pop = newpop;
%寻找最优解
[bestindividual,bestfit] = best(pop,fitvalue);
x2 = binary2decimal(bestindividual);
x1 = binary2decimal(newpop);
y1 = cal_objvalue(newpop);
if mod(i,10) == 0
figure;
fplot('10*sin(5*x)+7*abs(x-5)+10',[0 10]);
hold on;
plot(x1,y1,'*');
title(['迭代次数为n=' num2str(i)]);
%plot(x1,y1,'*');
end
end
fprintf('The best X is --->>%5.2f\n',x2);
fprintf('The best Y is --->>%5.2f\n',bestfit);
%初始化种群大小
%输入变量:
%popsize:种群大小
%chromlength:染色体长度-->>转化的二进制长度
%输出变量:
%pop:种群
function pop=initpop(popsize,chromlength)
pop = round(rand(popsize,chromlength));
%rand(3,4)生成3行4列的0-1之间的随机数
% rand(3,4)
%
% ans =
%
% 0.8147 0.9134 0.2785 0.9649
% 0.9058 0.6324 0.5469 0.1576
% 0.1270 0.0975 0.9575 0.9706
%round就是四舍五入
% round(rand(3,4))=
% 1 1 0 1
% 1 1 1 0
% 0 0 1 1
%所以返回的种群就是每行是一个个体,列数是染色体长度
%二进制转化成十进制函数
%输入变量:
%二进制种群
%输出变量
%十进制数值
function pop2 = binary2decimal(pop)
[px,py]=size(pop);
for i = 1:py
pop1(:,i) = 2.^(py-i).*pop(:,i);
end
%sum(.,2)对行求和,得到列向量
temp = sum(pop1,2);
pop2 = temp*10/1023;
%计算函数目标值
%输入变量:二进制数值
%输出变量:目标函数值
function [objvalue] = cal_objvalue(pop)
x = binary2decimal(pop);
%转化二进制数为x变量的变化域范围的数值
objvalue=10*sin(5*x)+7*abs(x-5)+10;
%如何选择新的个体
%输入变量:pop二进制种群,fitvalue:适应度值
%输出变量:newpop选择以后的二进制种群
function [newpop] = selection(pop,fitvalue)
%构造轮盘
[px,py] = size(pop);
totalfit = sum(fitvalue);
p_fitvalue = fitvalue/totalfit;
p_fitvalue = cumsum(p_fitvalue);%概率求和排序
ms = sort(rand(px,1));%从小到大排列
fitin = 1;
newin = 1;
while newin<=px
if(ms(newin))<p_fitvalue(fitin)
newpop(newin,:)=pop(fitin,:);
newin = newin+1;
else
fitin=fitin+1;
end
end
%交叉变换
%输入变量:pop:二进制的父代种群数,pc:交叉的概率
%输出变量:newpop:交叉后的种群数
function [newpop] = crossover(pop,pc)
[px,py] = size(pop);
newpop = ones(size(pop));
for i = 1:2:px-1
if(rand<pc)
cpoint = round(rand*py);
newpop(i,:) = [pop(i,1:cpoint),pop(i+1,cpoint+1:py)];
newpop(i+1,:) = [pop(i+1,1:cpoint),pop(i,cpoint+1:py)];
else
总 结
本次我所涉及的课题是数学建模竞赛论文评审优化协商方案,本文主要研究了数学建模的知识,通过对遗传算法,非线性整数规划等技术方面展开分析,对模型建立及求解,从而将存在的诸多问题进行总结,此模型主要实现以下几个功能:
(1)运用遗传算法进行求解模型,得到最优的协商分配方案
(2)利用数据信息构造协商关系图,将论文协商分配问题转化为协商关系图的最大边覆盖问题
(3)问题三中鉴于三位老师的特殊情况,将整体论文协商分配问题转化多个协商子问题,并提出迭代的多目标遗传优化算法,通过计算,求解得知此条件下的最优协商分配方案
致 谢
时光飞逝,四年的大学时光就在不经意中即将结束了。人生最大的财富, 莫过于岁月留下的记忆。当回首往事的时候,那些痛苦的和欢乐的往事,都会变成嘴角的一抹微笑。在宿院的校园里,所有的老师、同学,所有的人和事,都将成为我人生中最珍溃的一段记忆。
首先,我要感谢我的导师周克元老师,从论文定题到论文最终完成,周老师给予了我极大的帮助,在论文的每一环节都非常认真和严谨地给予我指导和建议,每次即使感觉疲惫也都会为我耐心而细致地修改论文,这样的责任心和工作态度使我深受感动和鼓舞,成为我顺利完成论文的动力。周老师渊博的学识、平易近人的性格、严谨的治学态度以及认真负责的工作风格使我铭记在心,成为我今后继续深造的榜样和指南针。在此,我对我的导师周克元老师表示衷心的感谢!
感谢大学期间的所有老师对我在专业学习中的指导和无私的帮助,感谢你们对我孜孜不倦的教导和告诉我们很多做人做事的道理,也感谢你们对我们学生平日里、生活上的关心、关爱和关怀,是那么的无微不至,不是父母却如父母般的厚重。四年的专业学习,我将永远铭记在心;宿迁学院四年的生活,也将会是我生命里无法忘记的珍溃记忆和记忆的电影无法剪辑掉的胶片。
感谢审阅这篇文章的各位老师,你们的指导和批评是我今后继续深造和学习的动力。
最后感谢我的亲人和朋友,是你们的支持和默默的奉献,才给了我完成学业的信心和动力,没有你们,就没有我这四年的学习生涯,更不可能有今天的学有所成。亲情、友情永远是我生活和学习不断奋进的最大动力源泉。不管人生的下一站将驶向何方 ,在宿院四年的读书生活却是令我永难忘怀的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)