FlashAttention原理介绍
GPU 的内存可以分为 HBM 和 SRAM 两部分。片上 SRAM 比 HBM 快一个数量级,但容量要小很多个数量级。。原始的attention的计算过程上图所示,中间涉及到了很多临时变量的读写,非常耗时。众所周知,对于科学计算程序而言,按照算数运算和内存读取各自所花的时间比例,科学计算通常分为。的时间瓶颈主要在于算数计算,比如大型矩阵的相乘等,的时间瓶颈主要在于内存的读写时间,比如批归一化、层
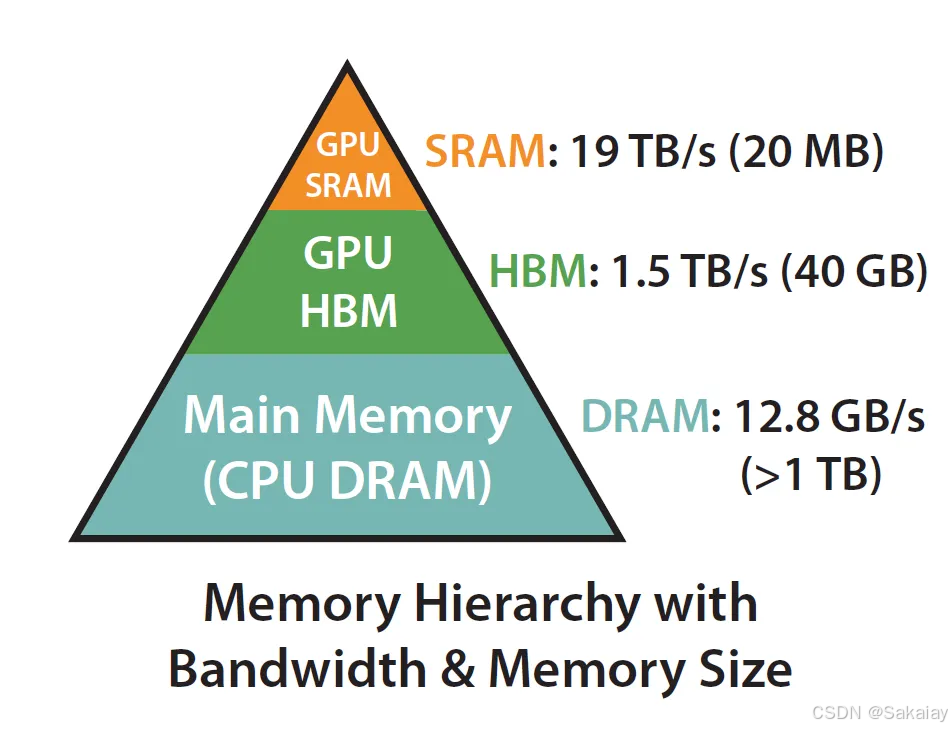
GPU 的内存可以分为 HBM 和 SRAM 两部分。片上 SRAM 比 HBM 快一个数量级,但容量要小很多个数量级。在 GPU 运算之前,数据和模型先从 CPU 的内存(上图中的 DRAM)移动到 GPU 的 HBM,然后再从 HBM 移动到 GPU 的 SRAM,CUDA kernel 在 SRAM 中对这些数据进行运算,运算完毕后将运算结果再从 SRAM 移动到 HBM。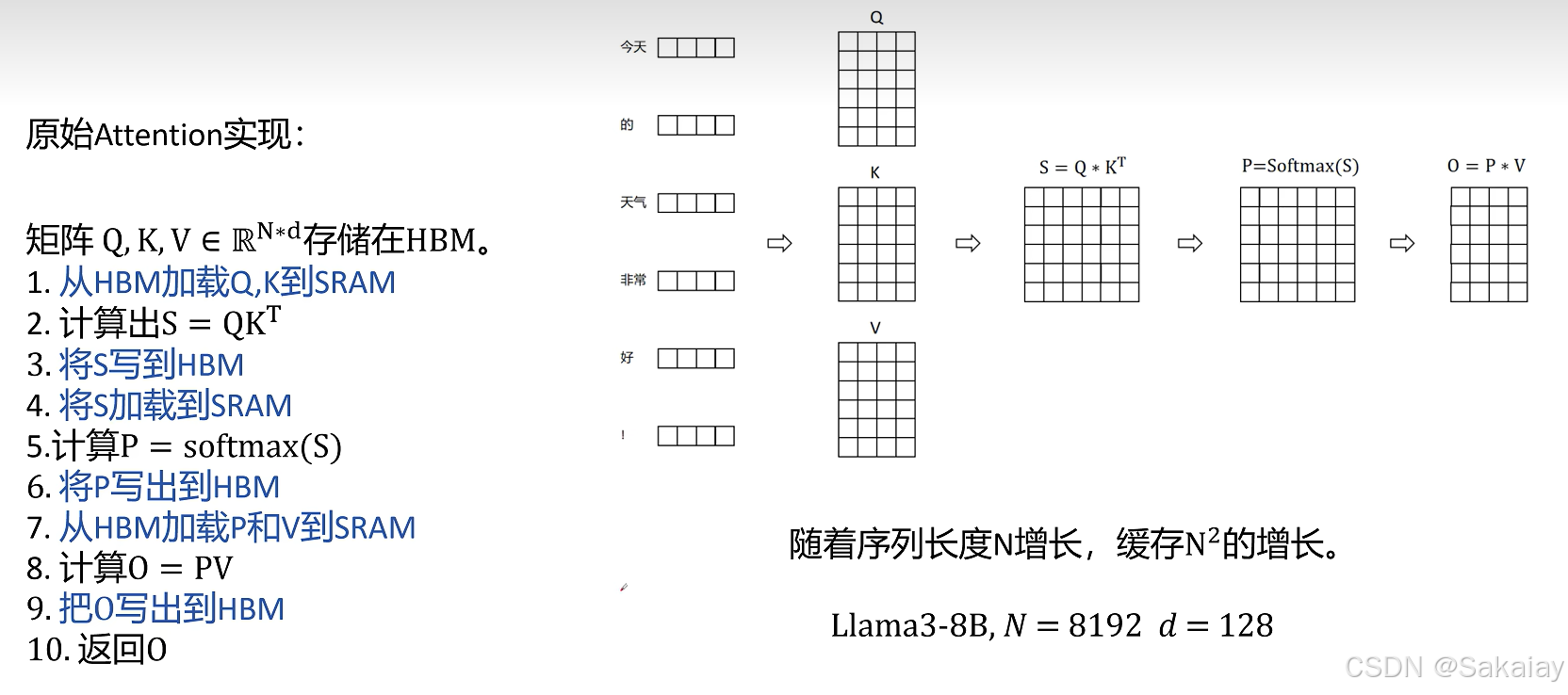
原始的attention的计算过程上图所示,中间涉及到了很多临时变量的读写,非常耗时。
众所周知,对于科学计算程序而言,按照算数运算和内存读取各自所花的时间比例,
科学计算通常分为计算密集型 (compute-bound) 和内存密集型 (memory-bound) 两类。
计算密集型运算的时间瓶颈主要在于算数计算,比如大型矩阵的相乘等,
内存密集型运算的时间瓶颈主要在于内存的读写时间,比如批归一化、层归一化等等。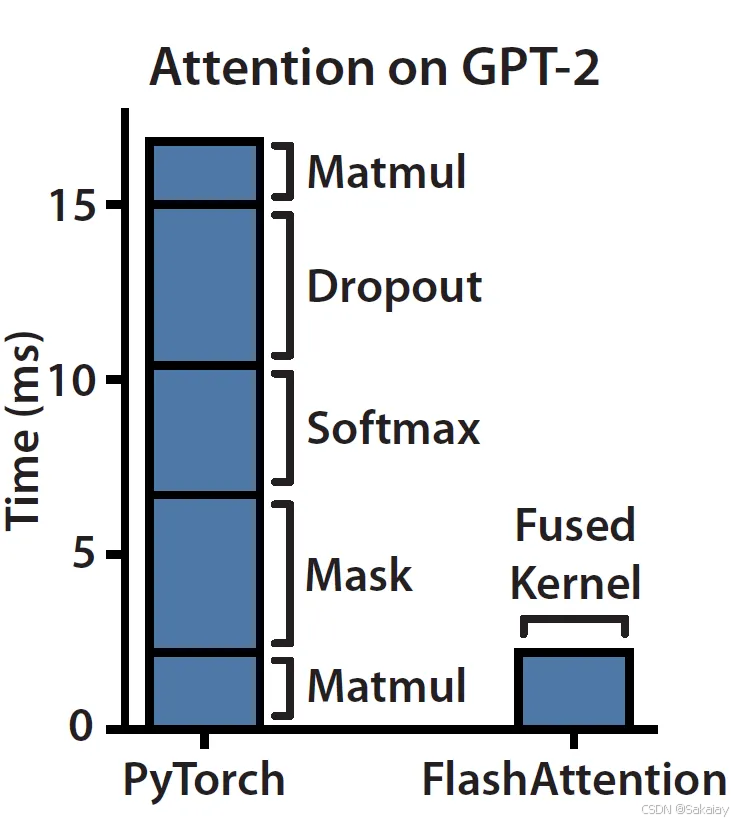
Attention计算过程主要是memory-bound,因此需要消耗很多数据读取的时间。
对于memory-bound的优化一般都是进行Fusion融合操作,不对中间结果缓存,减少HBM的访问。
因此FlashAttention的思路就是减少IO量,目标是避免Attention Matrix从HBM的读写。
FlashAttention基本上归结为两个主要思想:
- 通过分块计算,融合多个操作,减少中间结果缓存
- 反向传播时,重新计算中间结果。
下面举个例子简单说明下如何进行分块计算
在例子中,我们不考虑softmax操作,仅仅考虑 Q ⋅ K T ⋅ V Q \cdot K^{T} \cdot V Q⋅KT⋅V这个矩阵操作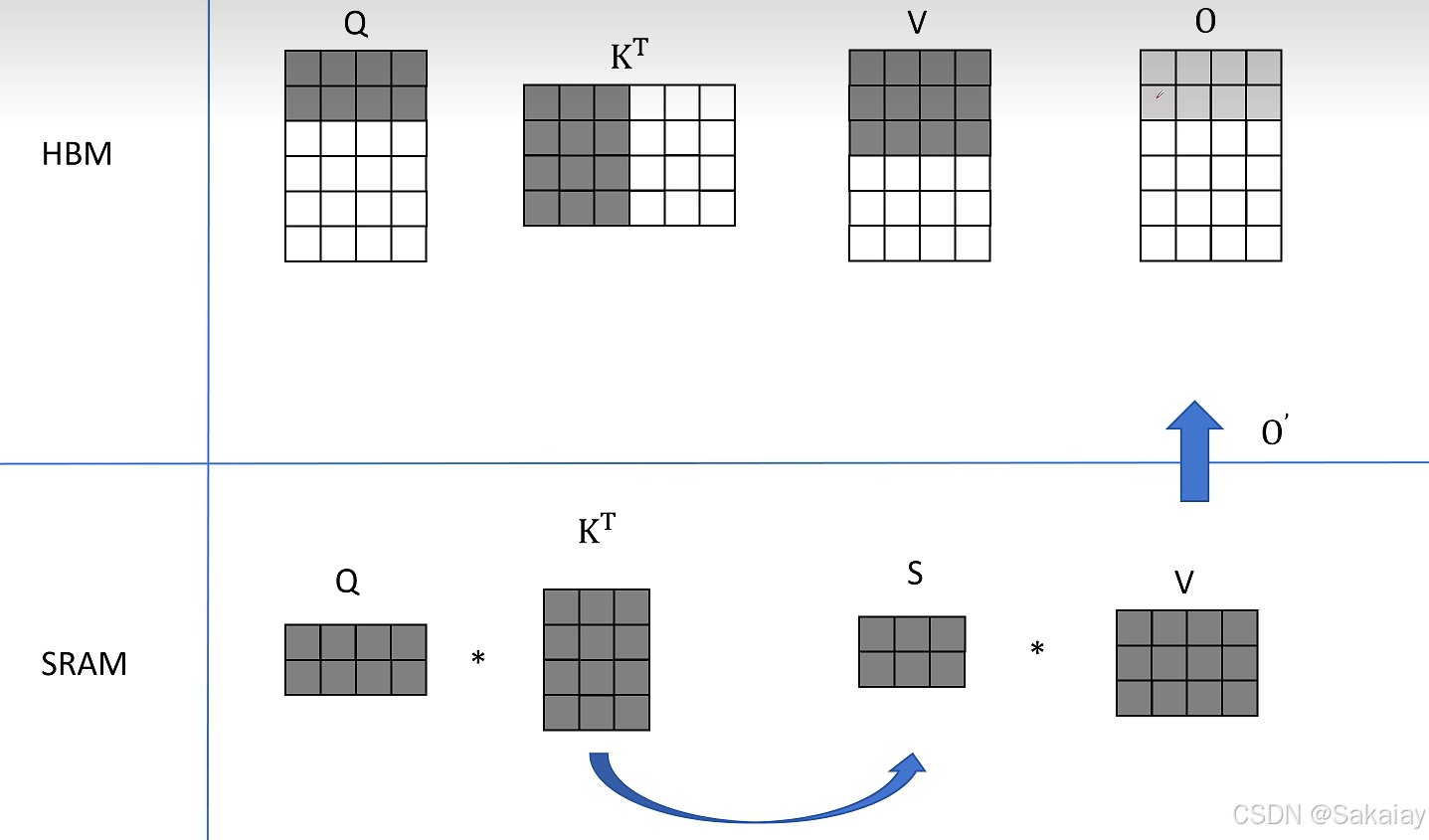
Attention分块计算,首先取 Q ( 2 × 4 ) Q (2\times4) Q(2×4)的前两行, K T ( 4 × 3 ) K^{T}(4\times3) KT(4×3)的前三列,计算得到 S ( 2 × 3 ) S(2\times3) S(2×3)然后再和 V ( 3 × 4 ) V(3\times4) V(3×4)的前三行相乘得到 O ( 2 × 4 ) O(2\times4) O(2×4)的前2行。
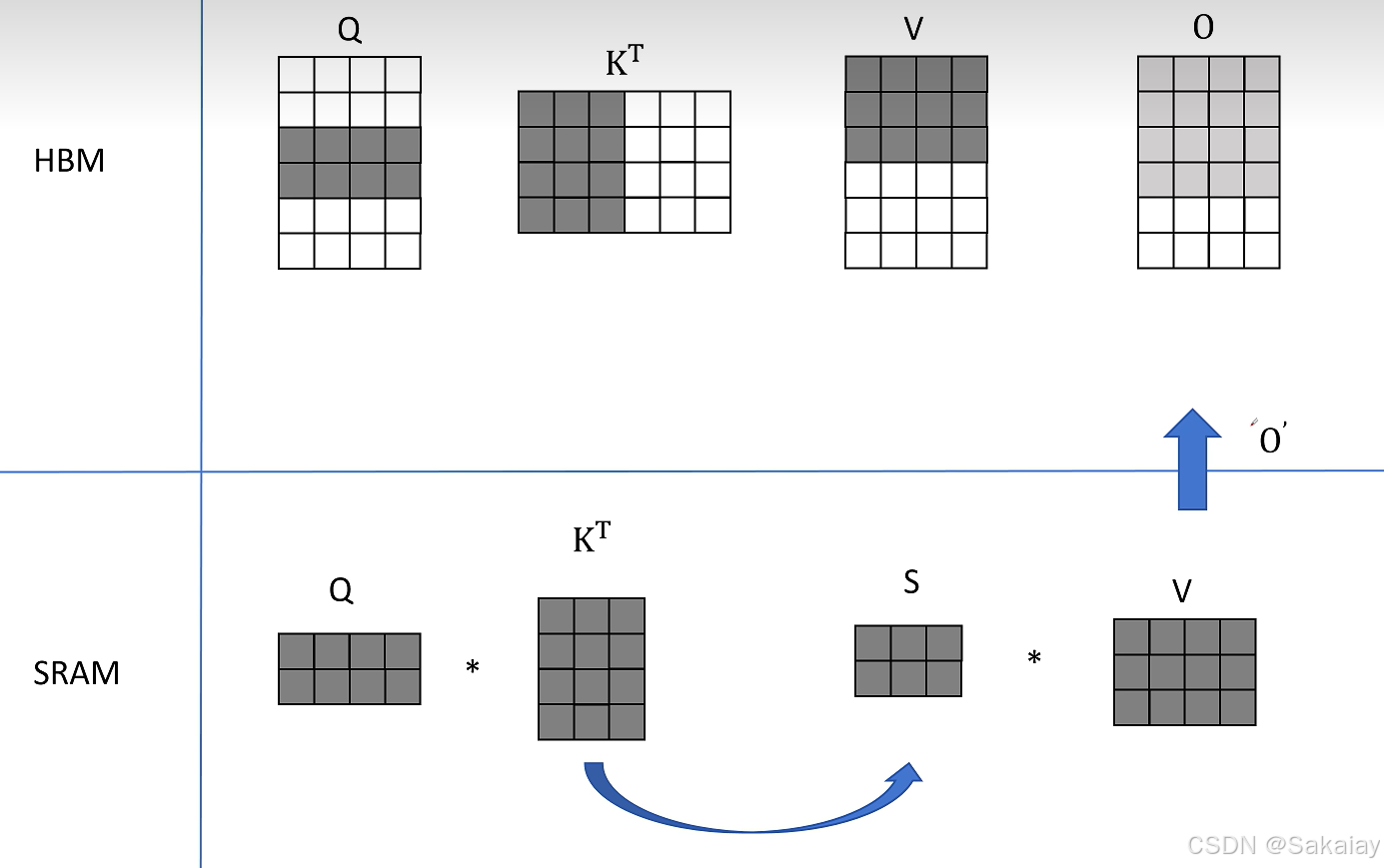
然后同样的操作,不过取得是 Q ( 2 × 4 ) Q (2\times4) Q(2×4)的中间两行,得到了 O ( 2 × 4 ) O(2\times4) O(2×4)的中间两行。
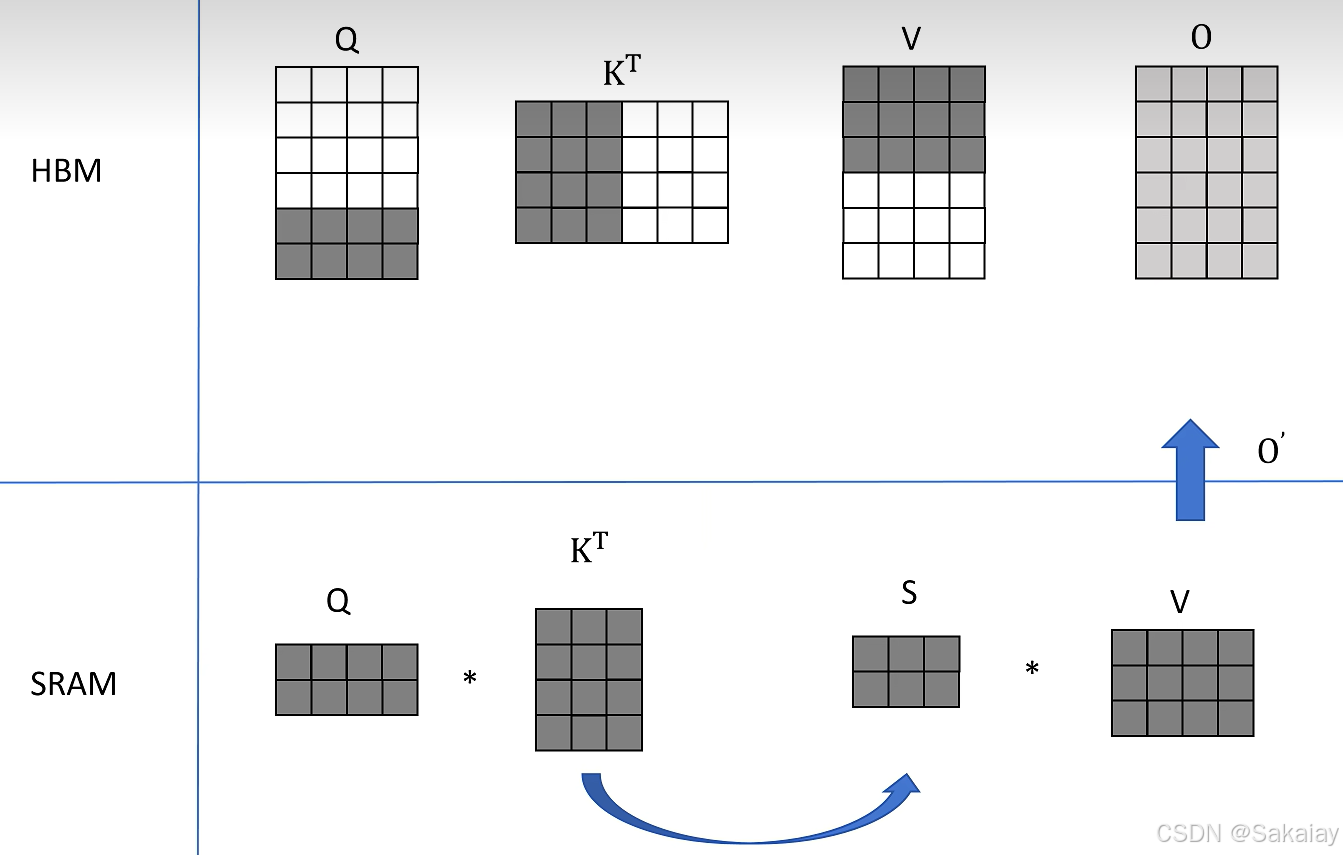
取 Q ( 2 × 4 ) Q (2\times4) Q(2×4)的最后两行,得到了 O ( 2 × 4 ) O(2\times4) O(2×4)的最后两行的结果。
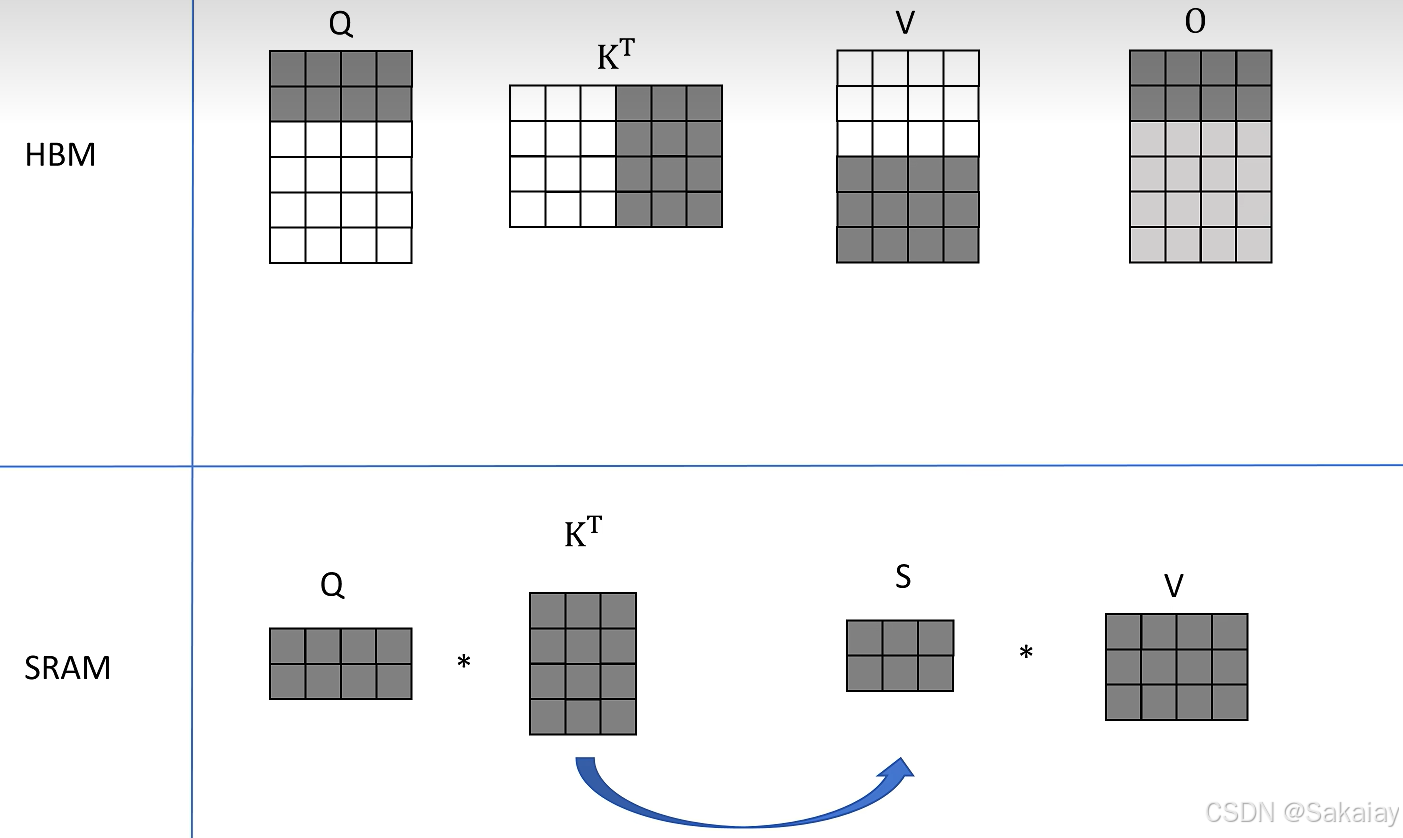
接着我们取 K T ( 4 × 3 ) K^{T}(4\times3) KT(4×3)的后三列, V ( 3 × 4 ) V(3\times4) V(3×4)的后三行,分别再次和 Q Q Q的分块结果计算,相加后得到最终的$O $。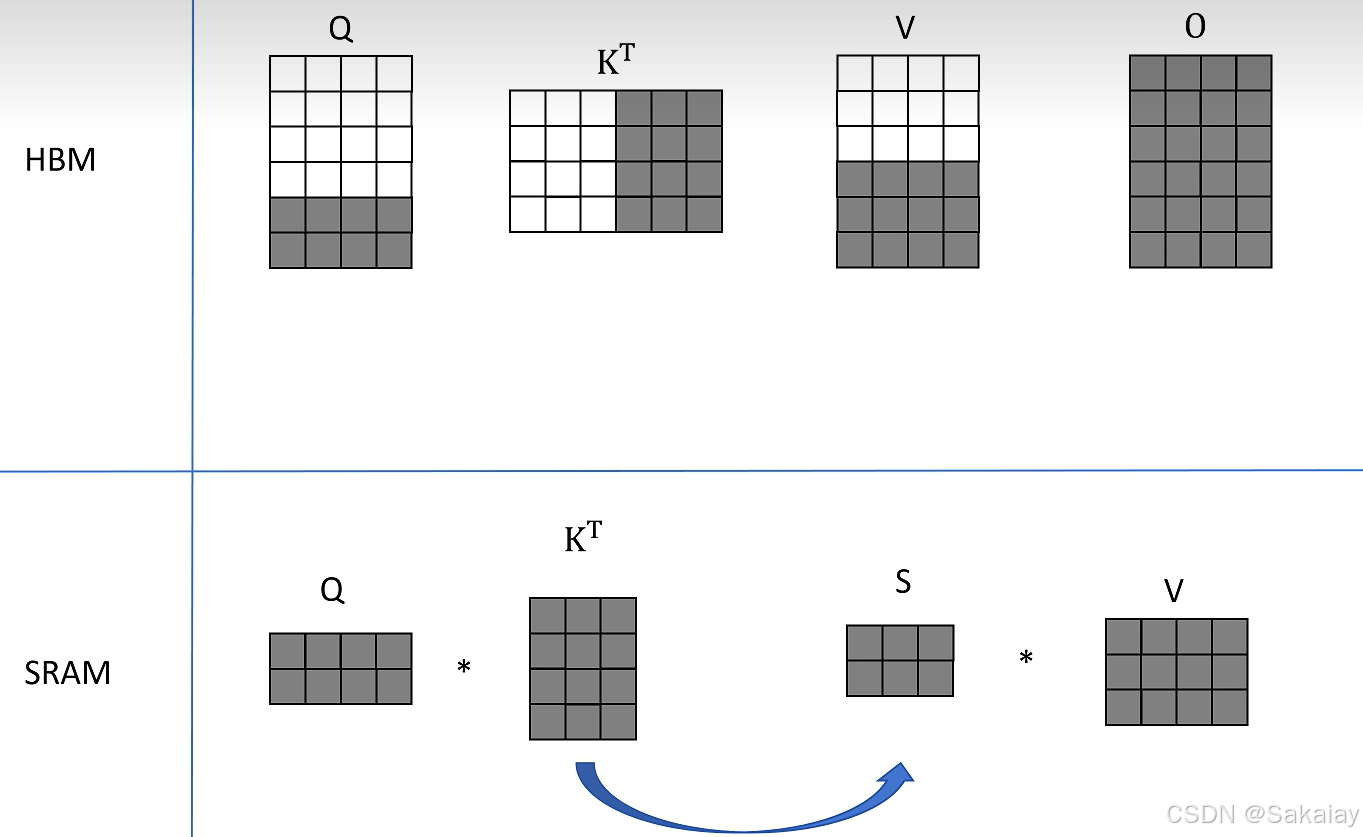
接着我们对softmax操作进行分块计算,softmax公式如下所示
softmax ( { x 1 , … , x N } ) = { e x i ∑ j = 1 N e x j } i = 1 N \operatorname{softmax}\left(\left\{x_{1}, \ldots, x_{N}\right\}\right)=\left\{\frac{e^{x_{i}}}{\sum_{j=1}^{N} e^{x_{j}}}\right\}_{i=1}^{N} softmax({x1,…,xN})={∑j=1Nexjexi}i=1N
FP16下,最大表示数为65536,但是如果使用softmax, e 12 = 162754 e^{12}=162754 e12=162754大于可以表示的最大的数,会出现数值溢出的问题。
因此我们使用safe softmax方法,找到 x i x_i xi中的最大值 m = m a x ( x i ) m=max(x_i) m=max(xi)
计算:
softmax ( { x 1 , … , x N } ) = { e x i / e m ∑ j = 1 N e x j / e m } i = 1 N = { e x i − m ∑ j = 1 N e x j − m } i = 1 N \operatorname{softmax}\left(\left\{x_{1}, \ldots, x_{N}\right\}\right)=\left\{\frac{e^{x_{i}} / e^{m}}{\sum_{j=1}^{N} e^{x_{j}} / e^{m}}\right\}_{i=1}^{N}=\left\{\frac{e^{x_{i}-m}}{\sum_{j=1}^{N} e^{x_{j}-m}}\right\}_{i=1}^{N} softmax({x1,…,xN})={∑j=1Nexj/emexi/em}i=1N={∑j=1Nexj−mexi−m}i=1N
下面进行分块计算操作
假设现在有 x = [ x 1 , . . . , x N ] x=[x_1,...,x_N] x=[x1,...,xN],通过 m ( x ) = m a x ( x ) m(x)=max(x) m(x)=max(x)得到 x x x中的最大值,设定 p ( x ) = [ e x 1 − m ( x ) , … , e x N − m ( x ) ] p(x)=\left[e^{x_{1}-m(x)}, \ldots, e^{x_{N}-m(x)}\right] p(x)=[ex1−m(x),…,exN−m(x)]为经过最大值约束后的结果, l ( x ) = ∑ i p ( x ) i l(x)=\sum_{i} p(x)_{i} l(x)=∑ip(x)i为所有 p ( x ) p(x) p(x)的和,因此改写以后的公式为
softmax ( x ) = p ( x ) l ( x ) \operatorname{softmax}(x)=\frac{p(x)}{l(x)} softmax(x)=l(x)p(x)
有 x = [ x 1 , . . , x N , . . x 2 N ] x=[x_1,..,x_N,..x_{2N}] x=[x1,..,xN,..x2N],分成两块,表示为 x 1 = [ x 1 , . . . , x N ] x^1=[x_1,...,x_N] x1=[x1,...,xN]、 x 2 = [ x N + 1 , . . . , x 2 N ] x^2=[x_{N+1},...,x_{2N}] x2=[xN+1,...,x2N]
分别计算 m ( x 1 ) 、 p ( x 1 ) 、 l ( x 1 ) m(x^1)、p(x^1)、l(x^1) m(x1)、p(x1)、l(x1)和 m ( x 2 ) 、 p ( x 2 ) 、 l ( x 2 ) m(x^2)、p(x^2)、l(x^2) m(x2)、p(x2)、l(x2)
然后计算出所有块的最大值 m ( x ) = max ( m ( x 1 ) , m ( x 2 ) ) m(x)=\max \left(m\left(x^{1}\right), \quad m\left(x^{2}\right)\right) m(x)=max(m(x1),m(x2))
接着对所有的 p ( x ) p(x) p(x)进行最大值约束
p ( x ) = [ e m ( x 1 ) − m ( x ) p ( x 1 ) , e m ( x 2 ) − m ( x ) p ( x 2 ) ] p(x)=\left[e^{m\left(x^{1}\right)-m(x)} p\left(x^{1}\right), e^{m\left(x^{2}\right)-m(x)} p\left(x^{2}\right)\right] p(x)=[em(x1)−m(x)p(x1),em(x2)−m(x)p(x2)]
假设 m ( x ) = m ( x 2 ) m(x)=m(x^2) m(x)=m(x2)那么 e m ( x 2 ) − m ( x ) = 1 e^{m\left(x^{2}\right)-m(x)}=1 em(x2)−m(x)=1,因此 p ( x 2 ) p(x^2) p(x2)没有任何变化,对于第二块的数据来说就经历了一次最大值约束 p ( x 2 ) = 1 ∗ p ( x 2 ) = e x 2 / e m ( x ) = e x 2 − m ( x ) p(x^2)=1*p(x^2)=e^{x^2}/e^{m(x)}=e^{x^2-m(x)} p(x2)=1∗p(x2)=ex2/em(x)=ex2−m(x),但是对于 p ( x 1 ) p(x^1) p(x1)来说,又添加了 e m ( x 1 ) − m ( x ) e^{m\left(x^{1}\right)-m(x)} em(x1)−m(x)这个权重,因此 p ( x 1 ) = e m ( x 1 ) / e m ( x ) ∗ e x 1 / e m ( x 1 ) = e x 1 / e m ( x ) = e x 1 − m ( x ) p(x^1)=e^{m(x^1)}/e^{m(x)}*e^{x^1}/e^{m(x^1)}=e^{x^1}/e^{m(x)}=e^{x^1-m(x)} p(x1)=em(x1)/em(x)∗ex1/em(x1)=ex1/em(x)=ex1−m(x)。
通过上述公式我们对所有分块都进行了最大值约束,然后得到 p ( x ) p(x) p(x)的和
l ( x ) = e m ( x 1 ) − m ( x ) l ( x 1 ) + e m ( x 2 ) − m ( x ) l ( x 2 ) l(x)=e^{m\left(x^{1}\right)-m(x)} l\left(x^{1}\right)+e^{m\left(x^{2}\right)-m(x)} l\left(x^{2}\right) l(x)=em(x1)−m(x)l(x1)+em(x2)−m(x)l(x2)
最后计算softmax
softmax ( x ) = p ( x ) l ( x ) \operatorname{softmax}(x)=\frac{p(x)}{l(x)} softmax(x)=l(x)p(x)
参考

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)