训练误差的“欺骗性“
训练误差(Trainging Error):模型在训练数据集上的预测误差泛化误差(Generalization Error):模型在未知数据集上的期望误差,反映真实应用效果模型在训练集上表现极佳,但过度记忆了训练数据中的噪声和异常值,导致无法适应新数据经典比喻:学生A在考前死记硬背了100道题的答案(训练集),但遇到新题型(测试集)时完全不会——这就是过拟合。
引言:一个令多数算法工程师抓狂的场景
“明明训练集准确率99%,为什么上线后效果一塌糊涂?!”——这是许多机器学习新手的“入坑第一课”
你是否也遇到过这样的困惑?模型在训练集时表现近乎完美,但在测试集或真实场景中却频频失误?这背后隐藏着一个机器学习中的核心陷阱:训练误差对泛化误差的严重低估。本文将从原理到实践,带你理解这一现象,并给出避坑指南!
目录
什么是训练误差与泛化误差
定义
训练误差(Trainging Error):模型在训练数据集上的预测误差
泛化误差(Generalization Error):模型在未知数据集上的期望误差,反映真实应用效果
关键区别
| 训练误差 | 泛化误差 | |
|---|---|---|
| 数据来源 | 训练集(已知数据) | 测试集/真实场景(未知数据) |
| 优化目标 | 直接最小化 | 无法直接计算,只能估计 |
| 核心矛盾 | 模型越复杂,训练误差越低 | 模型越复杂,可能泛化误差越高 |
Overfitting
什么是过拟合
模型在训练集上表现极佳,但过度记忆了训练数据中的噪声和异常值,导致无法适应新数据
经典比喻:
学生A在考前死记硬背了100道题的答案(训练集),但遇到新题型(测试集)时完全不会——这就是过拟合
代码演示
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
# 生成带噪声的数据
np.random.seed(42)
X = np.linspace(0, 1, 20)
y = np.sin(2 * np.pi * X) + np.random.normal(0, 0.2, X.shape[0])
X_test = np.linspace(0, 1, 1000)
y_test = np.sin(2 * np.pi * X_test)
# 用不同阶数的多项式拟合
degrees = [1, 5, 15]
plt.figure(figsize=(15, 5))
for i, degree in enumerate(degrees):
ax = plt.subplot(1, len(degrees), i + 1)
pipeline = Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('lin', LinearRegression())
])
pipeline.fit(X.reshape(-1, 1), y)
train_score = pipeline.score(X.reshape(-1, 1), y)
test_score = pipeline.score(X_test.reshape(-1, 1), y_test)
plt.scatter(X, y, s=20, label="Training Data")
plt.plot(X_test, pipeline.predict(X_test.reshape(-1, 1)),
label=f"Degree {degree}\nTrain R2: {train_score:.2f}\nTest R2: {test_score:.2f}")
plt.ylim(-2, 2)
plt.legend()
plt.show()运行效果如下:
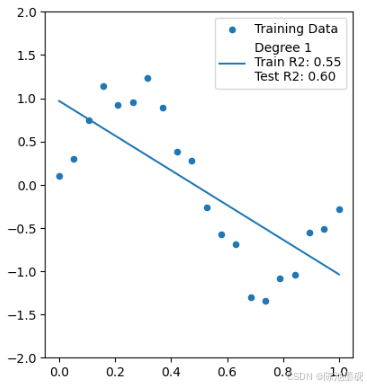
1阶多项式(欠拟合):无法拟合正弦曲线,训练/测试分数均低
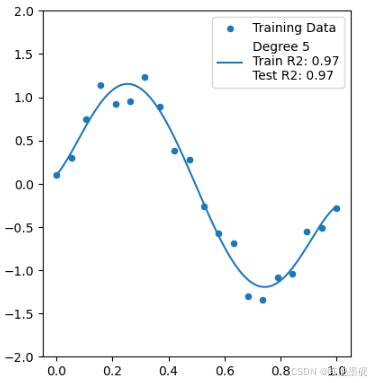
5阶多项式(适度拟合):较好地捕捉了趋势,测试分数最高
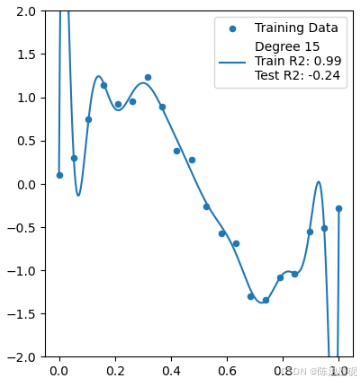
15阶多项式(过拟合):完美拟合训练点(Train R2: 0.99),但在测试集上完全失控!
数学视角:偏差-方差分解
泛化误差的分解

偏差(Bias):模型假设与真实规律的差距(如用线性模型拟合非线性关系)
方差(Variance):模型对训练数据波动的敏感程度(复杂模型方差高)
最后一项为数据噪声
训练误差的“欺骗性”
低偏差+高方差模型(如深度神经网络):
- 训练误差低:模型足够复杂,能拟合数据中的细节(包括噪声)
- 泛化误差高:模型过度依赖训练数据中的特定模型,无法泛化
解决方案
方法论框架
| 方法 | 原理 | 具体技术示例 |
|---|---|---|
| 交叉验证 | 使用验证集评估泛化能力 | K折交叉验证、留出验证集 |
| 正则化 | 约束模型复杂度,防止过度拟合 | L1/L2正则化、Dropout、早停法(Early Stopping) |
| 数据增强 | 增加训练数据的多样性,让模型学习更普适的规律 | 图像旋转、文本替换、噪声添加 |
| 模型简化 | 选择与问题复杂度匹配的模型 | 特征选择、降低神经网络层数 |
| 集成学习 | 结合多个模型的预测,降低方差 | Bagging、Boosting、Stacking |
实践建议
1. 保留测试集:测试集只能在最终评估时使用一次!
2. 监控训练/验证损失曲线:
history = model.fit(X_train, y_train,
validation_data=(X_val, y_val),
epochs=100)
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.legend()3. 奥卡姆剃刀原则:在相同效果下,选择更简单的模型!
关键结论
训练误差 ≠ 模型真实能力:它只是模型对已知数据的“记忆考试”成绩。
过拟合是泛化杀手:模型复杂度过高时,训练误差会严重误导开发人员
评估的核心是泛化能力:必须通过验证集、交叉验证等方式间接估计
“让模型在训练集上适度犯错,或许才是聪明的选择”——与大家共勉

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 34
34 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)