RHEL AI (2) - 用 InstructLab 训练 Granite 模型
《OpenShift / RHEL / DevSecOps 汇总目录》
已在 InstructLab 0.24.1 验证
模型微调训练
一个 Granite 模型自带的 Knowledge 和 Skill 是静态的且是有限的,因此无法回答特定知识领域、特定场景的问题。此时,用户可以使用该专业领域的数据对模型进行微调训练,以让模型增加新的知识或能力。
微调训练与 RAG 同样能提升模型,但它们是有区别的。
| 微调训练 | RAG |
|---|---|
| 微调后的知识和能力固化在模型内 | RAG 的数据一般存放在模型外部的向量数据中,并被模型通过检索使用 |
| 可提升模型的知识和能力 | 扩展模型的知识范围 |
| 训练模型周期长,成本高 | 向 LL 模型提供文档信息即可,实现时间短,成本低 |
在开始本文操作前可参考 https://github.com/gshipley/retro911/blob/main/qna.yaml 向 Granite 模型提一些问题,然后确认模型给出的答复不符合 qna.yaml 实际情况。为此,可以通过本文对已有的模型进行微调训练,以增加特定领域的知识。
用 InstructLab 训练 Granite 模型的迭代过程
使用 InstructLab 运行和训练 Granite 模型的迭代过程如下图左半部分,其中红色部分展开后的详细操作为图中右半部分内容,而红色部分为本文介绍内容。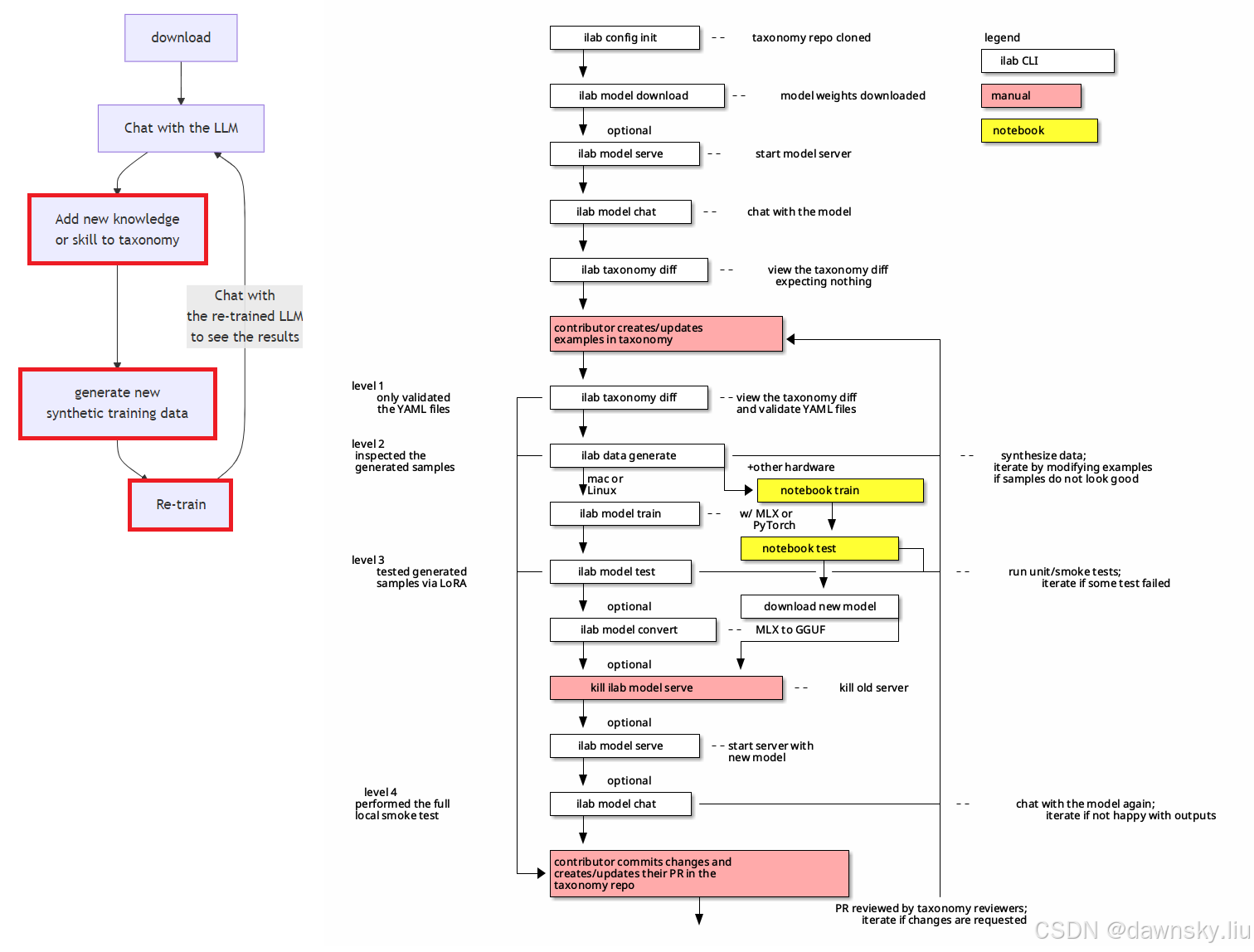
生成用于模型训练的合成数据
InstructLab 能够利用大规模聊天机器人对齐(LAB)方法根据少量的种子数据集生成大量的训练数据,因此能以较少的人工生成数据和计算开销来增强 LLM。
在数据生成过程中,InstructLab 利用教师模型从基础种子数据中生成新示例。这一过程并没有使用教师模型存储的知识,而是使用了特定的提示模板,在确保新示例保持原始人工编辑数据的结构和意图的同时,极大地扩展了数据集。教师模型具有多重作用:生成问题、产生答案并评估两者的质量,从而指导合成数据的生成过程。用户可以使用任何 LLM 作为教师模型。
InstructLab 使用两种特定的合成数据生成器:
- 技能合成数据生成器(Skills-SDG): 使用提示模板进行教学生成、评价、反应生成和最终配对评价
- 知识合成数据生成器(Knowledge-SDG):为教师模型未涵盖的领域生成教学数据,利用外部知识源为生成的数据奠定基础
准备训练数据
- 查看 taxonomy 目录,确认其中有 knowledge、compositional_skills、foundational_skills 等目录。
(venv) [lab-user@rhel9 ~]$ tree -L 1 $HOME/.local/share/instructlab/taxonomy
/home/instruct/.local/share/instructlab/taxonomy
├── CODE_OF_CONDUCT.md
├── compositional_skills
├── CONTRIBUTING.md
├── CONTRIBUTOR_ROLES.md
├── docs
├── foundational_skills
├── governance.md
├── knowledge
├── LICENSE
├── MAINTAINERS.md
├── Makefile
├── README.md
├── scripts
└── SECURITY.md
- 在 knowledge 目录下创建一个新目录 companies/retro911,然后将 https://github.com/gshipley/retro911/blob/main/qna.yaml 文件下载到该目录。
(venv) [lab-user@rhel9 ~]$ mkdir -p $HOME/.local/share/instructlab/taxonomy/knowledge/companies/retro911
(venv) [lab-user@rhel9 ~]$ curl -o $HOME/.local/share/instructlab/taxonomy/knowledge/companies/retro911/qna.yaml https://raw.githubusercontent.com/gshipley/retro911/refs/heads/main/qna.yaml
- 验证 taxonomy 中的内容是有效的。
(venv) [lab-user@rhel9 ~]$ cd $HOME/.local/share/instructlab && ilab taxonomy diff
knowledge/companies/retro911/qna.yaml
Taxonomy in /home/lab-user/.local/share/instructlab/taxonomy is valid :)
生成合成数据
- 使用在 ilab config 中 generate 默认指定的 mistral-7b-instruct-v0.2.Q4_K_M.gguf 模型生成合成数据。这里只为了演示使用的 sdg-scale-factor 参数设为 5,通常情况使用默认值 30 的比例因子可让训练模型更有效,但消耗的时间更长。另外使用了 gpus 参数也能显著缩短生成合成数据的用时。
(venv) [lab-user@rhel9 ~]$ ilab data generate --pipeline simple --sdg-scale-factor 5 --gpus 1
INFO 2025-02-14 00:52:53,076 instructlab.process.process:297: Started subprocess with PID 3473. Logs are being written to /home/lab-user/.local/share/instructlab/logs/generation/generation-0576eb44-ea6e-11ef-b9e7-0a8b4b39d443.log.
INFO 2025-02-14 00:52:53,542 instructlab.model.backends.llama_cpp:126: Trying to connect to model server at http://127.0.0.1:8000/v1
llama_new_context_with_model: n_ctx_per_seq (4096) < n_ctx_train (32768) -- the full capacity of the model will not be utilized
WARNING 2025-02-14 00:53:14,947 instructlab:188: Disabling SDG batching - unsupported with llama.cpp serving
INFO 2025-02-14 00:53:15,373 numexpr.utils:162: NumExpr defaulting to 16 threads.
INFO 2025-02-14 00:53:15,945 datasets:59: PyTorch version 2.5.1 available.
INFO 2025-02-14 00:53:17,436 instructlab:206: Generating synthetic data using 'simple' pipeline, '/home/lab-user/.cache/instructlab/models/mistral-7b-instruct-v0.2.Q4_K_M.gguf' model, '/home/lab-user/.local/share/instructlab/taxonomy' taxonomy, against http://127.0.0.1:39845/v1 server
INFO 2025-02-14 00:53:17,436 root:352: Converting taxonomy to samples
INFO 2025-02-14 00:53:17,745 instructlab.sdg.utils.taxonomy:160: Processing files...
INFO 2025-02-14 00:53:17,745 instructlab.sdg.utils.taxonomy:166: Pattern 'data.md' matched 1 files.
INFO 2025-02-14 00:53:17,745 instructlab.sdg.utils.taxonomy:170: Processing file: /home/lab-user/.local/share/instructlab/datasets/2025-02-14_005253/preprocessed_2025-02-14T00_53_17/documents/knowledge_parasol_claims_374fnx6x/data.md
INFO 2025-02-14 00:53:17,745 instructlab.sdg.utils.taxonomy:184: Appended Markdown content from /home/lab-user/.local/share/instructlab/datasets/2025-02-14_005253/preprocessed_2025-02-14T00_53_17/documents/knowledge_parasol_claims_374fnx6x/data.md
INFO 2025-02-14 00:53:22,695 instructlab.sdg.utils.chunkers:120: Docling models not found on disk, downloading models...
.gitattributes: 100%|##########| 1.71k/1.71k [00:00<00:00, 15.9MB/s]
.gitignore: 100%|##########| 5.18k/5.18k [00:00<00:00, 17.6MB/s]
README.md: 100%|##########| 3.49k/3.49k [00:00<00:00, 17.9MB/s]
config.json: 100%|##########| 41.0/41.0 [00:00<00:00, 206kB/s]
model.pt: 100%|#########9| 202M/202M [00:00<00:00, 439MB/s]
otslp_all_standard_094_clean.check: 100%|#########9| 213M/213M [00:00<00:00, 503MB/s]
(…)cts%2Ftableformer%2Ffat%2Ftm_config.json: 100%|##########| 7.09k/7.09k [00:00<00:00, 61.0MB/s]
otslp_all_fast.check: 100%|#########9| 146M/146M [00:00<00:00, 259MB/s]
(…)artifacts%2Ftableformer%2Ftm_config.json: 100%|##########| 7.09k/7.09k [00:00<00:00, 27.7MB/s]
WARNING 2025-02-14 00:53:25,054 easyocr.easyocr:71: Using CPU. Note: This module is much faster with a GPU.
WARNING 2025-02-14 00:53:25,059 easyocr.easyocr:251: Downloading detection model, please wait. This may take several minutes depending upon your network connection.
Progress: |██████████████████████████████████████████████████| 100.0% CompleteINFO 2025-02-14 00:53:26,326 easyocr.easyocr:255: Download complete
WARNING 2025-02-14 00:53:26,326 easyocr.easyocr:176: Downloading recognition model, please wait. This may take several minutes depending upon your network connection.
Progress: |██████████████████████████████████████████████████| 100.0% CompleteINFO 2025-02-14 00:53:26,679 easyocr.easyocr:180: Download complete.
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
Merges were not in checkpoint, building merges on the fly.
100%|##########| 32008/32008 [00:34<00:00, 926.02it/s]
INFO 2025-02-14 00:54:08,167 instructlab.sdg.utils.chunkers:271: Successfully loaded tokenizer from: /home/lab-user/.cache/instructlab/models/mistral-7b-instruct-v0.2.Q4_K_M.gguf
INFO 2025-02-14 00:54:08,171 docling.document_converter:219: Going to convert document batch...
INFO 2025-02-14 00:54:08,171 docling.pipeline.base_pipeline:37: Processing document data.md
INFO 2025-02-14 00:54:08,205 docling.document_converter:234: Finished converting document data.md in 0.03 sec.
INFO 2025-02-14 00:54:08,207 instructlab.sdg.utils.chunkers:534: Processed 1 docs, of which 0 failed
INFO 2025-02-14 00:54:08,207 instructlab.sdg.utils.chunkers:184: Processing parsed docling json file: /home/lab-user/.local/share/instructlab/datasets/2025-02-14_005253/preprocessed_2025-02-14T00_53_17/documents/docling-artifacts/data.json
INFO 2025-02-14 00:54:08,242 instructlab.sdg.generate_data:401: Taxonomy converted to samples and written to /home/lab-user/.local/share/instructlab/datasets/2025-02-14_005253/preprocessed_2025-02-14T00_53_17
INFO 2025-02-14 00:54:08,251 instructlab.sdg.generate_data:437: Synthesizing new instructions. If you aren't satisfied with the generated instructions, interrupt training (Ctrl-C) and try adjusting your YAML files. Adding more examples may help.
INFO 2025-02-14 00:54:08,328 instructlab.sdg.checkpointing:59: No existing checkpoints found in /home/lab-user/.local/share/instructlab/datasets/checkpoints/knowledge_parasol_claims, generating from scratch
INFO 2025-02-14 00:54:08,329 instructlab.sdg.pipeline:159: Running pipeline single-threaded
INFO 2025-02-14 00:54:08,335 instructlab.sdg.blocks.llmblock:55: LLM server supports batched inputs: False
INFO 2025-02-14 00:54:08,335 instructlab.sdg.pipeline:202: Running block: gen_knowledge
INFO 2025-02-14 00:54:08,335 instructlab.sdg.pipeline:206: Batching disabled; processing block 'gen_knowledge' single-threaded.
gen_knowledge Prompt Generation: 50it [07:40, 9.21s/it]
INFO 2025-02-14 01:01:48,784 instructlab.sdg.generate_data:474: Generated 49 samples
INFO 2025-02-14 01:01:48,795 instructlab.sdg.pipeline:159: Running pipeline single-threaded
INFO 2025-02-14 01:01:48,798 instructlab.sdg.pipeline:202: Running block: gen_mmlu_knowledge
INFO 2025-02-14 01:01:48,798 instructlab.sdg.pipeline:206: Batching disabled; processing block 'gen_mmlu_knowledge' single-threaded.
gen_mmlu_knowledge Prompt Generation: 100%|##########| 10/10 [11:42<00:00, 70.24s/it]
Filter: 100%|##########| 53/53 [00:00<00:00, 16453.12 examples/s]
Filter: 100%|##########| 53/53 [00:00<00:00, 16406.98 examples/s]
Flattening the indices: 100%|##########| 53/53 [00:00<00:00, 14911.33 examples/s]
Map: 100%|##########| 53/53 [00:00<00:00, 6910.54 examples/s]
Map: 100%|##########| 53/53 [00:00<00:00, 6421.27 examples/s]
Map: 100%|##########| 53/53 [00:00<00:00, 6281.74 examples/s]
Filter: 100%|##########| 53/53 [00:00<00:00, 19766.86 examples/s]
Filter: 100%|##########| 53/53 [00:00<00:00, 13638.76 examples/s]
Filter: 100%|##########| 36/36 [00:00<00:00, 11103.39 examples/s]
Flattening the indices: 100%|##########| 36/36 [00:00<00:00, 9163.43 examples/s]
Casting to class labels: 100%|##########| 36/36 [00:00<00:00, 5341.36 examples/s]
INFO 2025-02-14 01:13:31,248 instructlab.sdg.eval_data:126: Saving MMLU Dataset /home/lab-user/.local/share/instructlab/datasets/2025-02-14_005253/node_datasets_2025-02-14T00_53_17/mmlubench_knowledge_parasol_claims.jsonl
Creating json from Arrow format: 100%|##########| 1/1 [00:00<00:00, 611.33ba/s]
INFO 2025-02-14 01:13:31,256 instructlab.sdg.eval_data:130: Saving MMLU Task yaml /home/lab-user/.local/share/instructlab/datasets/2025-02-14_005253/node_datasets_2025-02-14T00_53_17/knowledge_parasol_claims_task.yaml
Map: 100%|##########| 49/49 [00:00<00:00, 6864.65 examples/s]
Map: 100%|##########| 49/49 [00:00<00:00, 10715.93 examples/s]
Creating json from Arrow format: 100%|##########| 1/1 [00:00<00:00, 812.22ba/s]
Map: 100%|##########| 49/49 [00:00<00:00, 6867.87 examples/s]
Map: 100%|##########| 49/49 [00:00<00:00, 6688.39 examples/s]
Map: 100%|##########| 49/49 [00:00<00:00, 7043.94 examples/s]
Map: 100%|##########| 49/49 [00:00<00:00, 10594.41 examples/s]
Creating json from Arrow format: 100%|##########| 1/1 [00:00<00:00, 454.82ba/s]
INFO 2025-02-14 01:13:31,332 instructlab.sdg.datamixing:138: Loading dataset from /home/lab-user/.local/share/instructlab/datasets/2025-02-14_005253/node_datasets_2025-02-14T00_53_17/knowledge_parasol_claims_p10.jsonl ...
Generating train split: 98 examples [00:00, 32875.45 examples/s]
INFO 2025-02-14 01:13:31,446 instructlab.sdg.datamixing:140: Dataset columns: ['messages', 'metadata', 'id']
INFO 2025-02-14 01:13:31,446 instructlab.sdg.datamixing:141: Dataset loaded with 98 samples
Map (num_proc=8): 100%|##########| 98/98 [00:00<00:00, 760.75 examples/s]
Map (num_proc=8): 100%|##########| 98/98 [00:00<00:00, 848.06 examples/s]
Creating json from Arrow format: 100%|##########| 1/1 [00:00<00:00, 292.20ba/s]
INFO 2025-02-14 01:13:31,909 instructlab.sdg.datamixing:215: Mixed Dataset saved to /home/lab-user/.local/share/instructlab/datasets/2025-02-14_005253/skills_train_msgs_2025-02-14T00_53_17.jsonl
INFO 2025-02-14 01:13:31,910 instructlab.sdg.datamixing:138: Loading dataset from /home/lab-user/.local/share/instructlab/datasets/2025-02-14_005253/node_datasets_2025-02-14T00_53_17/knowledge_parasol_claims_p07.jsonl ...
Generating train split: 49 examples [00:00, 26697.96 examples/s]
INFO 2025-02-14 01:13:31,969 instructlab.sdg.datamixing:140: Dataset columns: ['messages', 'metadata', 'id']
INFO 2025-02-14 01:13:31,969 instructlab.sdg.datamixing:141: Dataset loaded with 49 samples
Map (num_proc=8): 100%|##########| 49/49 [00:00<00:00, 417.66 examples/s]
Map (num_proc=8): 100%|##########| 49/49 [00:00<00:00, 422.08 examples/s]
Creating json from Arrow format: 100%|##########| 1/1 [00:00<00:00, 480.28ba/s]
INFO 2025-02-14 01:13:32,417 instructlab.sdg.datamixing:215: Mixed Dataset saved to /home/lab-user/.local/share/instructlab/datasets/2025-02-14_005253/knowledge_train_msgs_2025-02-14T00_53_17.jsonl
INFO 2025-02-14 01:13:32,418 instructlab.sdg.generate_data:729: Generation took 1214.98s
ᕦ(òᴗóˇ)ᕤ Data generate completed successfully! ᕦ(òᴗóˇ)ᕤ
- 在生成合成数据的过程中可以查看执行状态。
(venv) [lab-user@rhel9 ~]$ ilab process list
WARNING 2025-02-14 01:40:18,283 instructlab.process.process:340: Process 3473 was not running or could not be stopped.
+------------+-------+--------------------------------------+-------------------------------------------------------------------------------------------------------------+------------------------------+---------+
| Type | PID | UUID | Log File | Runtime | Status |
+------------+-------+--------------------------------------+-------------------------------------------------------------------------------------------------------------+------------------------------+---------+
| Generation | 3473 | 0576eb44-ea6e-11ef-b9e7-0a8b4b39d443 | /home/lab-user/.local/share/instructlab/logs/generation/generation-0576eb44-ea6e-11ef-b9e7-0a8b4b39d443.log | 0.0:47.0:25.206540000000132 | Done |
+------------+-------+--------------------------------------+-------------------------------------------------------------------------------------------------------------+------------------------------+---------+
- 在 datasets 目录中查看生成的合成数据的相关文件。其中 skills_train_msgs_.jsonl 和 knowledge_train_msgs_.jsonl 是生成的 skills 和 knowledge 合成数据。
(venv) [lab-user@rhel9 ~]$ ll $HOME/.local/share/instructlab/datasets/<YOUR-DATE>/
total 616
drwxr-xr-x. 2 instruct users 48 Feb 25 09:03 generated_2025-02-25T08_53_18
-rw-r--r--. 1 instruct users 463 Feb 25 09:11 knowledge_recipe_2025-02-25T08_53_18.yaml
-rw-r--r--. 1 instruct users 173393 Feb 25 09:11 knowledge_train_msgs_2025-02-25T08_53_18.jsonl
-rw-r--r--. 1 instruct users 28032 Feb 25 09:11 messages_2025-02-25T08_53_18.jsonl
drwxr-xr-x. 2 instruct users 4096 Feb 25 09:11 node_datasets_2025-02-25T08_53_18
drwxr-xr-x. 3 instruct users 65 Feb 25 08:54 preprocessed_2025-02-25T08_53_18
-rw-r--r--. 1 instruct users 463 Feb 25 09:11 skills_recipe_2025-02-25T08_53_18.yaml
-rw-r--r--. 1 instruct users 359595 Feb 25 09:11 skills_train_msgs_2025-02-25T08_53_18.jsonl
-rw-r--r--. 1 instruct users 22858 Feb 25 08:54 test_2025-02-25T08_53_18.jsonl
-rw-r--r--. 1 instruct users 24764 Feb 25 09:11 train_2025-02-25T08_53_18.jsonl
- 可以用命令查看生成的合成数据。
(venv) [lab-user@rhel9 ~]$ ilab data list
Run from train_gen.jsonl
+-----------------+---------+---------------------+-----------+
| Dataset | Model | Created At | File size |
+-----------------+---------+---------------------+-----------+
| train_gen.jsonl | General | 2025-02-25 09:43:10 | 24.18 KB |
+-----------------+---------+---------------------+-----------+
Run from test_gen.jsonl
+----------------+---------+---------------------+-----------+
| Dataset | Model | Created At | File size |
+----------------+---------+---------------------+-----------+
| test_gen.jsonl | General | 2025-02-25 09:43:10 | 22.32 KB |
+----------------+---------+---------------------+-----------+
Run from 2025-02-25_085311
+--------------------------------------------------------------------------------------------------+---------+---------------------+-----------+
| Dataset | Model | Created At | File size |
+--------------------------------------------------------------------------------------------------+---------+---------------------+-----------+
| 2025-02-25_085311/generated_2025-02-25T08_53_18/knowledge_companies_retro911.jsonl | General | 2025-02-25 09:03:27 | 129.96 KB |
| 2025-02-25_085311/knowledge_train_msgs_2025-02-25T08_53_18.jsonl | General | 2025-02-25 09:11:39 | 169.33 KB |
| 2025-02-25_085311/messages_2025-02-25T08_53_18.jsonl | General | 2025-02-25 09:11:38 | 27.38 KB |
| 2025-02-25_085311/node_datasets_2025-02-25T08_53_18/knowledge_companies_retro911_p07.jsonl | General | 2025-02-25 09:11:38 | 154.84 KB |
| 2025-02-25_085311/node_datasets_2025-02-25T08_53_18/knowledge_companies_retro911_p10.jsonl | General | 2025-02-25 09:11:38 | 322.19 KB |
| 2025-02-25_085311/node_datasets_2025-02-25T08_53_18/mmlubench_knowledge_companies_retro911.jsonl | General | 2025-02-25 09:11:38 | 0.00 B |
| 2025-02-25_085311/preprocessed_2025-02-25T08_53_18/knowledge_companies_retro911.jsonl | General | 2025-02-25 08:54:06 | 27.14 KB |
| 2025-02-25_085311/skills_train_msgs_2025-02-25T08_53_18.jsonl | General | 2025-02-25 09:11:39 | 351.17 KB |
| 2025-02-25_085311/test_2025-02-25T08_53_18.jsonl | General | 2025-02-25 08:54:06 | 22.32 KB |
| 2025-02-25_085311/train_2025-02-25T08_53_18.jsonl | General | 2025-02-25 09:11:38 | 24.18 KB |
+--------------------------------------------------------------------------------------------------+---------+---------------------+-----------+
(
训练模型
- 使用在 ilab config 中 train 默认指定的模型执行训练(一般是 granite-7b-lab)。由于本测试环境有 Nvidia GPU,所以设置了 --device cuda 参数,否则用时会较长。另外为了简化演示过程使用了 --pipeline simple 参数。在训练完成会提示训练好的模型存放路径。
(venv) [lab-user@rhel9 ~]$ ilab model download --repository instructlab/granite-7b-lab
(venv) [lab-user@rhel9 ~]$ nohup ilab model train -y --pipeline simple --device cuda > training.log 2>&1 &
(venv) [lab-user@rhel9 ~]$ tail -f training.log
INFO 2025-02-14 01:58:03,984 numexpr.utils:162: NumExpr defaulting to 16 threads.
INFO 2025-02-14 01:58:04,256 datasets:59: PyTorch version 2.5.1 available.
LINUX_TRAIN.PY: NUM EPOCHS IS: 10
LINUX_TRAIN.PY: TRAIN FILE IS: /home/lab-user/.local/share/instructlab/datasets/train_gen.jsonl
LINUX_TRAIN.PY: TEST FILE IS: /home/lab-user/.local/share/instructlab/datasets/test_gen.jsonl
LINUX_TRAIN.PY: Using device 'cuda:0'
NVidia CUDA version: 12.4
AMD ROCm HIP version: n/a
cuda:0 is 'NVIDIA L4' (21.9 GiB of 22.0 GiB free, capability: 8.9)
LINUX_TRAIN.PY: LOADING DATASETS
Generating train split: 49 examples [00:00, 19265.18 examples/s]
Generating train split: 30 examples [00:00, 22590.51 examples/s]
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
LINUX_TRAIN.PY: NOT USING 4-bit quantization
LINUX_TRAIN.PY: LOADING THE BASE MODEL
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 6.14it/s]
LINUX_TRAIN.PY: Model device cuda:0
|===========================================================================|
| PyTorch CUDA memory summary, device ID 0 |
|---------------------------------------------------------------------------|
| CUDA OOMs: 0 | cudaMalloc retries: 0 |
|===========================================================================|
| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |
|---------------------------------------------------------------------------|
| Allocated memory | 12852 MiB | 12852 MiB | 12852 MiB | 0 B |
| from large pool | 12852 MiB | 12852 MiB | 12852 MiB | 0 B |
| from small pool | 0 MiB | 0 MiB | 0 MiB | 0 B |
|---------------------------------------------------------------------------|
。。。
。。。
LINUX_TRAIN.PY: SANITY CHECKING THE BASE MODEL
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [06:09<00:00, 12.30s/it]
LINUX_TRAIN.PY: GETTING THE ATTENTION LAYERS
LINUX_TRAIN.PY: CONFIGURING LoRA
Map: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49/49 [00:00<00:00, 7015.08 examples/s]
Map: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:00<00:00, 4546.34 examples/s]
[2025-02-14 02:04:21,907] [INFO] [real_accelerator.py:222:get_accelerator] Setting ds_accelerator to cuda (auto detect)
df: /home/lab-user/.triton/autotune: No such file or directory
LINUX_TRAIN.PY: TRAINING
{'train_runtime': 88.5327, 'train_samples_per_second': 5.535, 'train_steps_per_second': 5.535, 'train_loss': 0.6967362384406888, 'epoch': 10.0}
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 490/490 [01:28<00:00, 5.53it/s]
LINUX_TRAIN.PY: RUNNING INFERENCE ON THE OUTPUT MODEL
===
test 0
===
===
user
===
When was Retro911 founded?
**Retro911** is a full-service company dedicated to helping enthusiasts navigate the world of retro video systems.
Founded in 2024 by Grant Shipley and headquartered in Clayton, NC, it specializes in providing expert advice on
conquering classic game titles, assisting in the acquisition and restoration of vintage hardware, and fostering
a community passionate about all things retro gaming.
===
assistant_old
===
2024
===
assistant_new
===
* Grant Shipley founded Retro911 in 2024.
* The company is headquartered in Clayton, NC.
* Retro911 specializes in assisting retro video game enthusiasts with advice, acquisition, and restoration of vintage hardware.
* Grant Shipley's leadership and passion for retro gaming have helped Retro911 build a thriving community of enthusiasts.
Feel free to ask if you have any additional questions about Retro911, Grant Shipley, or retro gaming in general. I'm here to help!
===
assistant_expected
===
Retro911 was founded in 2024.
。。。
。。。
model.layers.31.self_attn.v_proj.weight -> blk.31.attn_v.weight | BF16 | [4096, 4096]
model.norm.weight -> output_norm.weight | BF16 | [4096]
Writing training_results/final/ggml-model-f16.gguf, format 1
Padding vocab with 3 token(s) - <dummy00001> through <dummy00003>
INFO 2025-02-14 02:09:00,585 gguf.gguf_writer:101: gguf: This GGUF file is for Little Endian only
INFO 2025-02-14 02:09:00,681 gguf.vocab:60: Setting special token type bos to 1
INFO 2025-02-14 02:09:00,681 gguf.vocab:60: Setting special token type eos to 32000
INFO 2025-02-14 02:09:00,681 gguf.vocab:60: Setting special token type unk to 0
INFO 2025-02-14 02:09:00,681 gguf.vocab:60: Setting special token type pad to 32000
INFO 2025-02-14 02:09:00,681 gguf.vocab:68: Setting add_bos_token to False
INFO 2025-02-14 02:09:00,681 gguf.vocab:68: Setting add_eos_token to False
INFO 2025-02-14 02:09:00,682 gguf.vocab:72: Setting chat_template to {% for message in messages %}{% if message['role'] == 'system' %}{{'<|system|>'+ '
' + message['content'] + '
'}}{% elif message['role'] == 'user' %}{{'<|user|>' + '
' + message['content'] + '
'}}{% elif message['role'] == 'assistant' %}{{'<|assistant|>' + '
' + message['content'] + '<|endoftext|>' + ('' if loop.last else '
')}}{% endif %}{% endfor %}
INFO 2025-02-14 02:09:00,684 gguf.gguf_writer:180: Writing the following files:
INFO 2025-02-14 02:09:00,684 gguf.gguf_writer:185: training_results/final/ggml-model-f16.gguf: n_tensors = 291, total_size = 13.5G
[ 1/291] Writing tensor token_embd.weight | size 32008 x 4096 | type F16 | T+ 0
[ 2/291] Writing tensor blk.0.attn_norm.weight | size 4096 | type F32 | T+ 0
。。。
。。。
[291/291] Writing tensor output_norm.weight | size 4096 | type F32 | T+ 40
Wrote training_results/final/ggml-model-f16.gguf
INFO 2025-02-14 02:09:40,842 instructlab.model.simple_train:219: Save trained model to /home/lab-user/.local/share/instructlab/checkpoints/ggml-model-f16.gguf
ᕦ(òᴗóˇ)ᕤ Simple Model training completed successfully! ᕦ(òᴗóˇ)ᕤ
测试新模型
- 运行新的模型。
(venv) [lab-user@rhel9 ~]$ ilab model serve --model-path $HOME/.local/share/instructlab/checkpoints/ggml-model-f16.gguf
- 和新的模型进行对话。向其提 qna.yaml 中的问题,确认答复已符合要求。注意:答复内容和 qna.yaml 中的 answer 内容不一定完全一致,但符合实际情况;另外,可能由于生成的合成训练数据有限,部分答复和实际情况有别。
(venv) [lab-user@rhel9 ~]$ ilab model chat -m $HOME/.local/share/instructlab/checkpoints/ggml-model-f16.gguf
╭─────────────────────────────────────────────────────── system ──────────────────────────────────────────────────────────────────╮
│ Welcome to InstructLab Chat w/ GGML-MODEL-F16.GGUF (type /h for help) │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
>>> Who founded Retro911? [S][default]
╭────────────────────────────────────────────────── ggml-model-f16.gguf ──────────────────────────────────────────────────────────╮
│ Grant Shipley founded Retro911. │
╰───────────────────────────────────────────────────────────────────────────────────────────────────────── elapsed 7.786 seconds ─╯
>>> When was Retro911 founded? [S][default]
╭────────────────────────────────────────────────── ggml-model-f16.gguf ──────────────────────────────────────────────────────────╮
│ Retro911 was founded in 2024. │
│ │
│ Is there any additional information you would like to know about Retro911 or other companies? I'm here to help! │
╰───────────────────────────────────────────────────────────────────────────────────────────────────────── elapsed 7.786 seconds ─╯
参考
https://rhpds.github.io/showroom-lb1212-cooking-up-a-perfect-model
https://redhat-scholars.github.io/instructlab-tutorial/instructlab-tutorial/index.html
https://github.com/instructlab/instructlab?tab=readme-ov-file
https://www.redhat.com/en/blog/instructlab-tutorial-installing-and-fine-tuning-your-first-ai-model-part-2
https://developers.redhat.com/learning/learn:rhel-ai-try-llms-easy-way/resource/resources:optimizing-llms-accuracy
https://github.com/rhai-code/instructlab_knowledge
https://github.com/rhai-code/rhai-taxonomy/blob/main/taxonomy/knowledge/companies/retro911/qna.yaml
https://docs.google.com/document/d/1_Lr8iwF_7qxojjSt1piuQNR_y2hPeOsirBdqhb1qaTo/edit?tab=t.0
https://docs.instructlab.ai/adding-data-to-model/creating_new_knowledge_or_skills/
https://blog.instructlab.ai/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 20
20 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)