机器学习(三)信用卡欺诈检测项目
本实验旨在通过对信用卡欺诈检测数据集(creditcard.csv)的应用,研究对比不同机器学习算法在处理类别不平衡问题上的表现,并通过多种评估指标比较这些算法的有效性,最后得出最优的算法。
1.项目背景
1)背景概要
项目名称:信用卡欺诈检测项目
项目内容:使用卡进行大量交易的公司需要发现系统中的异常情况。该项目旨在建立信用卡欺诈检测模型。项目使用的数据集包含欧洲持卡人在 2013 年 9 月通过信用卡进行的交易。
此数据集显示了两天内发生的交易,其中 284,807 笔交易中有 492 笔欺诈。数据集高度不平衡,正类(欺诈)占所有交易的 0.172%。我们将使用交易及其标签作为欺诈或非欺诈来检测客户进行的新交易是否为欺诈。
数据集:信用卡欺诈检测数据集
Credit Card Fraud Detection | Kaggle
2)实验摘要
本实验旨在通过对信用卡欺诈检测数据集(creditcard.csv)的应用,研究对比不同机器学习算法在处理类别不平衡问题上的表现,并通过多种评估指标比较这些算法的有效性,最后得出最优的算法。
在导入数据集后,我们首先观察数据,包括查看数据集前几行,检查类别分布,从而对数据集的特征,标签和类别分布有充分了解,此处可以看出数据集分类标签分布高度不平衡,其中Amount的浮动范围很大,因此在稍后的过程中,我们先进行归一化处理。针对类别不平衡,我们分别对数据集进行集成欠采样(Cluster Centroids)和过采样(SMOTE),后续分别训练模型。
接着我们分别使用逻辑回归,决策树和随机森林这三种算法构建模型,对每种算法分别进行了网格搜索(GridSearchCV)以寻找最优超参数组合,其中使用了交叉验证和roc_auc作为评分标准。在找到最佳参数后,使用这些参数重新训练模型,并对测试集进行预测。期间计算并记录了整个模型训练和预测的运行时间。
最后通过打印分类报告、混淆矩阵,计算AUC-ROC值以及绘制了ROC曲线图等方式,对模型性能进行了全面评估,并得出对过采样处理后的数据训练得到的逻辑回归分类模型检测信用卡欺诈的最佳模型。
2.实验过程
以下为处理数据集和训练模型的实验过程:
1.数据加载与预处理:
首先导入数据集,加载数据集
file_path=r' '# 本地文件路径
data = pd.read_csv(file_path)查看数据集前几行
print(data.head())
Time V1 V2 V3 ... V27 V28 Amount Class
0 0.0 -1.359807 -0.072781 2.536347 ... 0.133558 -0.021053 149.62 0
1 0.0 1.191857 0.266151 0.166480 ... -0.008983 0.014724 2.69 0
2 1.0 -1.358354 -1.340163 1.773209 ... -0.055353 -0.059752 378.66 0
3 1.0 -0.966272 -0.185226 1.792993 ... 0.062723 0.061458 123.50 0
4 2.0 -1.158233 0.877737 1.548718 ... 0.219422 0.215153 69.99 0
可见V1、V2、...V28 是使用 PCA 获得的主成分,未使用 PCA 转换的特征是 'Time' 和 'Amount',这样的数据有好处也有坏处,好处是我们不需要对数据再进行预处理,坏处就是数据具体代表的含义就不是很清楚了,可能是 PCA 降维以保护用户身份和敏感特征的结果,这个案列中我们不再追究V1,V2….分别代表什么含义。
其中'Amount' 是交易金额A,浮动范围很大,因此在稍后的过程中要进行归一化处理。特征 'Class' 是响应变量,在欺诈的情况下取值 1,否则取值 0。
检查类别分布并可视化类别分布
print(data['Class'].value_counts())
sns.countplot(x='Class', data=data)
plt.show()[5 rows x 31 columns]
Class
0 284315
1 492
Name: count, dtype: int64
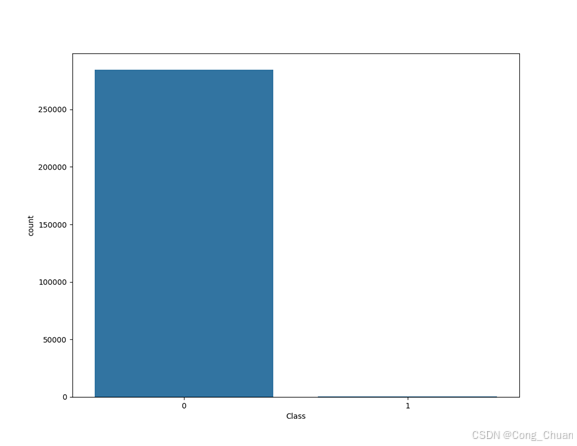
输出显示标签为0的很多,而标签为1的却很少,从柱状图中也可以看出,说明样本的分布情况是非常不均衡的,模型在训练时更容易学习到类别0的特征,忽略类别1,从而导致分类性能下降,所以在构建分类器的时候要特别注意一个误区,即使将结果全部预测为0也会出现很好的分类结果,为了解决这个问题,我们将对样本进行采样处理。
将特征与标签分离,并对数值型特征进行标准化处理
X = data.drop('Class', axis=1)
y = data['Class']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)StandardScaler的作用是去均值和方差归一化,且是针对每一个特征维度来做的,所以在标准化处理前我们要先将分类标签'Class'分离。
2. 解决类别不平衡问题:
提升不平衡类分类准确率的方法有三大类:采样、阈值移动、调整代价或权重。
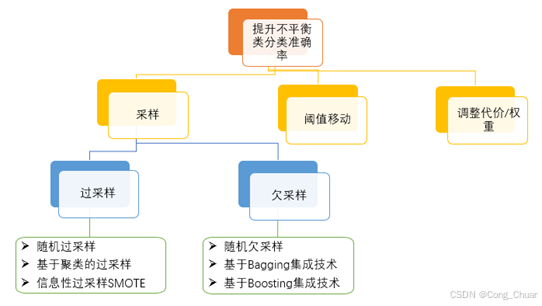
过采样,会增加训练集中少数群体成员的数量。过采样的优点是不会保留原始训练集中的信息,因为会保留少数和多数类别的所有观察结果。另一方面,它容易过度拟合。
欠采样,与过采样相反,旨在减少多数样本的数量来平衡类分布。由于它正在从原始数据集中删除观察结果,因此可能会丢弃有用的信息。
对本次实验我们分别使用集成欠采样(Cluster Centroids)和过采样(SMOTE)。
集成欠采样(Cluster Centroids):通过聚类算法将多数类样本聚类为若干个簇,并用簇的中心代替原始样本,从而减少多数类样本的数量。
SMOTE(Synthetic Minority Over-sampling Technique):通过在少数类样本之间插值生成新的样本。SMOTE不仅复制少数类样本,还生成新的合成样本,从而减少了过拟合的风险。
代码如下:
(我们将采样后的数据集按7:3的比例随机划分为训练集和测试集)
# (1)针对类别不平衡使用集成技术进行欠采样处理
model_CC = ClusterCentroids() # 实例化
X_CC_resampled, y_CC_resampled = model_CC.fit_resample(X_scaled, y)
# 输入数据进行欠抽样处理
# 划分训练集和测试集
X_train,X_test, y_train, y_test = train_test_split(X_CC_resampled, y_CC_resampled, test_size=0.3, random_state=0)
# (2)针对类别不平衡使用过采样
smote = SMOTE(random_state=0)
X_SMOTE_resampled, y_SMOTE_resampled = smote.fit_resample(X_scaled, y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_SMOTE_resampled, y_SMOTE_resampled, test_size=0.3, random_state=0)3. 模型训练与调优:
逻辑回归是一种经典的分类算法。在这一部分,我们首先初始化逻辑回归模型,接着定义了逻辑回归的参数网格parameters,包括正则化强度 C、正则化类型 penalty和最大迭代次数 max_iter,网格参数的范围通过查阅scikit-learn的官方文档得到。
然后,我们使用 GridSearchCV 进行参数调优。GridSearchCV 是一种交叉验证技术,它通过尝试所有可能的参数组合来寻找最佳模型参数。我们使用5折交叉验证,并以roc_auc作为评估指标 (scoring= ‘roc_auc ')。训练完成后,我们输出了最优参数,使用最佳参数重新训练模型并在测试集上进行了预测。
# (1)使用逻辑回归算法
# 初始化逻辑回归模型
log_reg = LogisticRegression(solver='liblinear', random_state=0)
# 使用网络搜索调优模型
# 定义参数网格
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100], 'penalty': ['l1', 'l2'], 'max_iter': [50, 100, 250, 500]}
# 使用网络搜索调优模型
grid_search = GridSearchCV(estimator=log_reg, param_grid=param_grid, cv=5, scoring='roc_auc', n_jobs=-1)
grid_search.fit(X_train, y_train)
# 输出最佳参数
print("Best parameters found: ", grid_search.best_params_)
# 使用最佳参数重新训练模型
best_log_reg = grid_search.best_estimator_
best_log_reg.fit(X_train, y_train)
# 预测测试集
y_pred = best_log_reg.predict(X_test)
y_pred_proba = best_log_reg.predict_proba(X_test)[:, 1]
决策树(Decision Tree)是一种流行的机器学习算法,以其简单、直观的特点,在分类和回归任务中得到了广泛应用。在这一部分,我们创建决策树的实例Decision_tree。然后,定义了决策树的参数网格 parameters,包括分裂节点的标准criterion、树的最大深度 max_depth和内部节点再划分所需的最小样本数 min_samples_split,网格参数的范围通过查阅scikit-learn的官方文档得到。
我们使用 GridSearchCV 对随机森林模型进行参数调优,我们使用5折交叉验证,并以roc_auc作为评估指标 (scoring= ‘roc_auc ')。训练完成后,我们输出了最优参数,使用最佳参数重新训练模型并在测试集上进行了预测。
# (2)使用决策树算法
# 初始化决策树模型
Decision_tree = DecisionTreeClassifier(random_state=0)
# 定义多参数网格
parameters = {'max_depth': [3, 5, 7, 9, 11], 'criterion': ['gini', 'entropy', 'log_loss'],
'min_samples_split': [2, 5, 8, 11, 14]}
# 使用网络搜索调优模型
grid_search = GridSearchCV(Decision_tree, parameters, scoring='roc_auc', cv=5, n_jobs=-1)
grid_search.fit(X_train, y_train)
# 输出最佳参数
print("Best parameters found: ", grid_search.best_params_)
# 使用最佳参数重新训练模型
best_Decision_tree = grid_search.best_estimator_
best_Decision_tree.fit(X_train, y_train)
# 预测测试集
y_pred = best_Decision_tree.predict(X_test)
y_pred_proba = best_Decision_tree.predict_proba(X_test)[:, 1]随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法。随机森林非常简单,易于实现,计算开销也很小,但是它在分类和回归上表现出非常惊人的性能,因此,随机森林被誉为“代表集成学习技术水平的方法”。
在这一部分,我们创建随机森林分类器的实例Forest。然后,定义了随机森林的参数网格 parameters,包括树的数量 n_estimators、树的最大深度 max_depth、内部节点再划分所需的最小样本数 min_samples_split和叶子节点最少样本数 min_samples_leaf,网格参数的范围通过查阅scikit-learn的官方文档得到。
类似于逻辑回归,我们使用 GridSearchCV 对随机森林模型进行参数调优,为了减少训练时间,我们使用3折交叉验证,并以roc_auc作为评估指标 (scoring= ‘roc_auc ')。训练完成后,我们输出了最优参数,使用最佳参数重新训练模型并在测试集上进行了预测。
# (3)使用随机森林算法
# 初始化随机森林模型
Forest = RandomForestClassifier(random_state=0)
# 定义多参数网格
parameters = {'n_estimators': range(50, 151, 20), 'max_depth': range(2, 11, 2), 'min_samples_split': range(2, 11, 2),
'min_samples_leaf': range(1, 11, 1)}
# 使用网络搜索调优模型
grid_search = GridSearchCV(Forest, parameters, scoring='roc_auc', cv=3, n_jobs=-1)
grid_search.fit(X_train, y_train)
# 输出最佳参数
print("Best parameters found: ", grid_search.best_params_)
# 使用最佳参数重新训练模型
best_Forest = grid_search.best_estimator_
best_Forest.fit(X_train, y_train)
# 预测测试集
y_pred = best_Forest.predict(X_test)
y_pred_proba = best_Forest.predict_proba(X_test)[:, 1]由于过采样处理后的训练数据太大,使用随机森林进行调优训练花费时间非常长,我们训练了两小时也没有完成,所以实验结果没有“过采样随机森林”这一部分。
3.实验结果
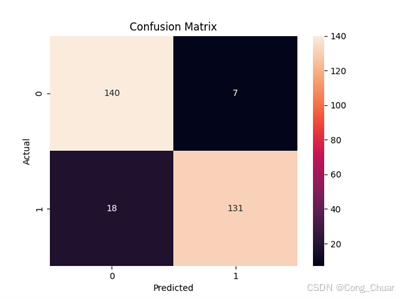
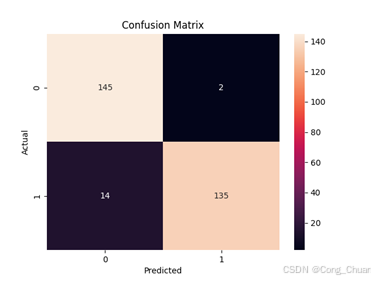
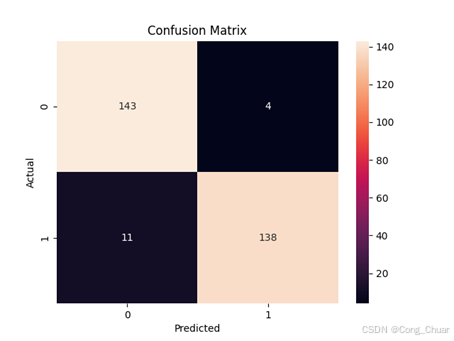
混淆矩阵:
欠采样数据集:
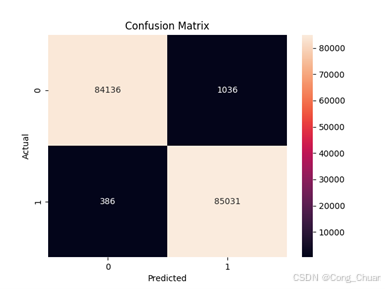
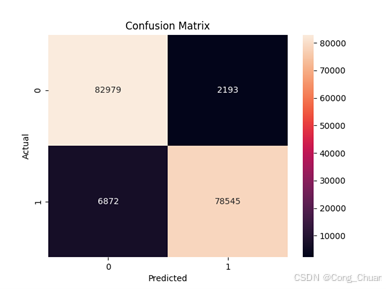
过采样数据集:
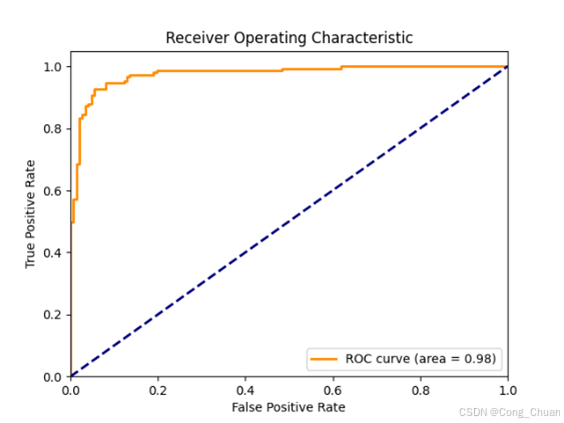
接收者操作特征曲线及曲线下面积(AUC-ROC):
欠采样数据集:
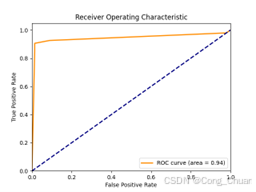
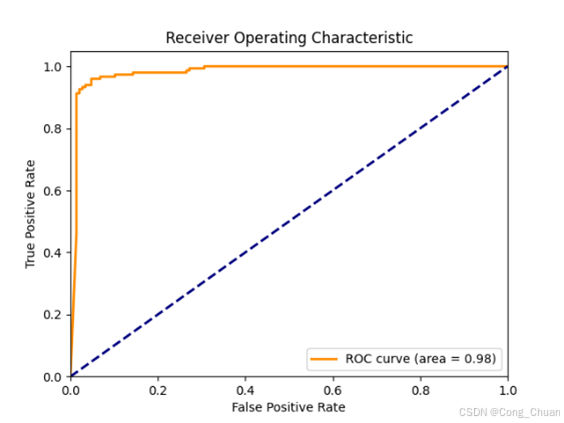
过采样数据集
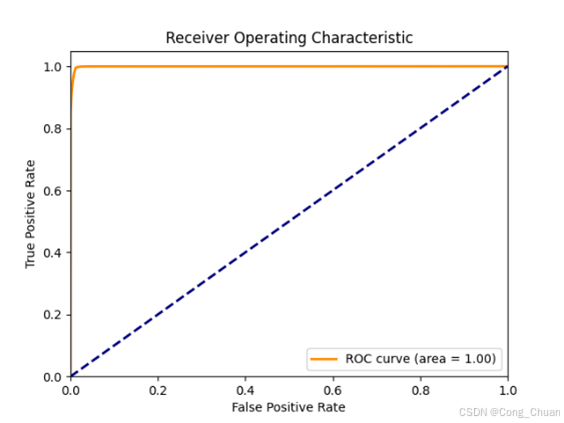
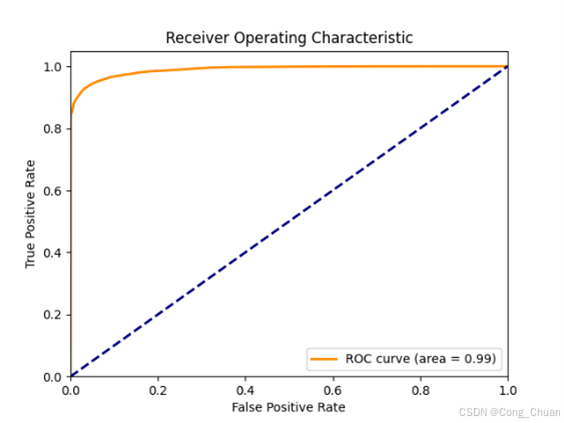
详细数据:
|
precision |
recall |
f1-score |
support |
|
|
0 |
0.89 |
0.95 |
0.92 |
147 |
|
1 |
0.95 |
0.88 |
0.91 |
149 |
|
accuracy |
0.92 |
296 |
||
|
macro avg |
0.92 |
0.92 |
0.92 |
296 |
|
weighted avg |
0.92 |
0.92 |
0.92 |
296 |
|
precision |
recall |
f1-score |
support |
|
|
0 |
0.91 |
0.99 |
0.95 |
147 |
|
1 |
0.99 |
0.91 |
0.94 |
149 |
|
accuracy |
0.95 |
296 |
||
|
macro avg |
0.95 |
0.95 |
0.95 |
296 |
|
weighted avg |
0.95 |
0.95 |
0.95 |
296 |
|
precision |
recall |
f1-score |
support |
|
|
0 |
0.93 |
0.97 |
0.95 |
147 |
|
1 |
0.97 |
0.93 |
0.95 |
149 |
|
accuracy |
0.95 |
296 |
||
|
macro avg |
0.95 |
0.95 |
0.95 |
296 |
|
weighted avg |
0.95 |
0.95 |
0.95 |
296 |
|
precision |
recall |
f1-score |
support |
|
|
0 |
1.00 |
0.99 |
0.99 |
85172 |
|
1 |
0.99 |
1.00 |
0.99 |
85417 |
|
accuracy |
0.99 |
170589 |
||
|
macro avg |
0.99 |
0.99 |
0.99 |
170589 |
|
weighted avg |
0.99 |
0.99 |
0.99 |
170589 |
|
precision |
recall |
f1-score |
support |
|
|
0 |
0.92 |
0.97 |
0.95 |
85172 |
|
1 |
0.97 |
0.92 |
0.95 |
85417 |
|
accuracy |
0.95 |
170589 |
||
|
macro avg |
0.95 |
0.95 |
0.95 |
170589 |
|
weighted avg |
0.95 |
0.95 |
0.95 |
170589 |
模型训练及预测所用时间:
|
算法 |
时间(s) |
|
欠采样逻辑回归 |
13.64 |
|
欠采样决策树 |
3.07 |
|
欠采样随机森林 |
75.12 |
|
过采样逻辑回归 |
322.30 |
|
过采样决策树 |
1251.69 |
4.分析总结
1.模型性能评估
AUC - ROC 指标:欠采样数据集上随机森林最优(0.9813),逻辑回归次之,决策树较弱;过采样数据集上逻辑回归(0.9892)与决策树(0.9889)接近且高,表明模型分类能力较好,解决类别不平衡后逻辑回归和决策树性能提升。
混淆矩阵:欠采样随机森林真正例多,假正例和假反例少,这意味着模型在预测欺诈交易时准确性较高,能有效检测欺诈且减少对正常交易干扰。
其他指标:欠采样逻辑回归精确率、召回率高,F1 - score 达 0.95;过采样决策树各项指标平衡,整体准确率高,如欠采样随机森林达 0.99,表明模型在测试集上的预测正确比例较高。
综合当前实验结果来看,过采样逻辑回归是检测信用卡欺诈的最佳算法。
2.采样方法影响
欠采样:提升决策树和逻辑回归指标,训练时间短,但可能丢失部分信息,不过本实验中影响较小,可能是因为数据集本身特征维度较高,部分样本的删除未对关键特征学习造成严重阻碍。
过采样:提升逻辑回归和决策树性能,但易过拟合,决策树训练时间大幅增加,随机森林两小时未完成调优训练,可能影响泛化能力。
3.算法特点表现
逻辑回归:欠采样训练时间短,正则化调优可防过拟合,不同数据集性能稳定良好,过采样后 AUC - ROC 值高,说明其在解决类别不平衡问题后能有效处理该信用卡欺诈检测任务。
决策树:不同数据集准确率和 AUC - ROC 值不错,参数调优可控制生长,但过采样训练时间长,可能增加过拟合风险,通过调整参数(如本实验中对max_depth、criterion、min_samples_split等参数的调优)可以控制树的生长,避免过拟合,提高模型性能。。
随机森林:欠采样数据集表现佳,准确性和可靠性高,但计算开销大,处理大规模数据训练时间显著增加。
4.实验总结展望
本实验通过对信用卡欺诈检测数据集的处理和分析,综合运用了数据预处理(如归一化、解决类别不平衡问题)、多种机器学习算法(逻辑回归、决策树、随机森林)以及模型调优(网格搜索)和评估(混淆矩阵、AUC - ROC等指标)方法,取得了一定的成果。在解决类别不平衡问题上,欠采样和过采样方法各有优劣,不同算法在不同采样数据集上的表现也有所差异,为实际应用中选择合适的算法和数据处理方式提供了参考。
5.实验代码
完整实验代码如下:
import pandas as pd
import time
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix, roc_auc_score
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import ClusterCentroids
from sklearn.metrics import roc_curve, auc, precision_recall_curve
# 导入数据集
file_path = r' '# 本地文件路径
# 加载数据
data = pd.read_csv(file_path)
# 查看数据集前几行
print(data.head())
# 检查类别分布
print(data['Class'].value_counts())
# 可视化类别分布
sns.countplot(x='Class', data=data)
plt.show()
# 分离特征和标签
X = data.drop('Class', axis=1)
y = data['Class']
# 标准化数值型特征
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# (1)针对类别不平衡使用欠采样
# 通过减少分类中多数类样本的数量来实现样本均衡,例如随机去掉一些多数类中的样本,缺点是会丢失多数类样本中的一些重要信息。
# 使用集成技术进行欠采样处理
model_CC = ClusterCentroids() # 实例化
X_CC_resampled, y_CC_resampled = model_CC.fit_resample(X_scaled, y) # 输入数据进行欠抽样处理
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_CC_resampled, y_CC_resampled, test_size=0.3, random_state=0)
# (2)针对类别不平衡使用过采样
# 通过增加分类中少数类样本的数量来实现样本均衡,缺点在于:如果样本特征少则可能导致过拟合的问题。可通过在少数类中加入随机噪声、干扰数据或通过一定规则产生新的合成样本。
smote = SMOTE(random_state=0)
X_SMOTE_resampled, y_SMOTE_resampled = smote.fit_resample(X_scaled, y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_SMOTE_resampled, y_SMOTE_resampled, test_size=0.3, random_state=0)
# 记录开始时间
start = time.time()
# (1)使用逻辑回归算法
# 初始化逻辑回归模型
log_reg = LogisticRegression(solver='liblinear', random_state=0)
# 使用网络搜索调优模型
# 定义参数网格
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000], 'penalty': ['l1', 'l2'], 'max_iter': [100, 250, 500, 1000]}
# 使用网络搜索调优模型
grid_search = GridSearchCV(estimator=log_reg, param_grid=param_grid, cv=5, scoring='roc_auc', n_jobs=-1)
grid_search.fit(X_train, y_train)
# 输出最佳参数
print("Best parameters found: ", grid_search.best_params_)
# 使用最佳参数重新训练模型
best_log_reg = grid_search.best_estimator_
best_log_reg.fit(X_train, y_train)
# 预测测试集
y_pred = best_log_reg.predict(X_test)
y_pred_proba = best_log_reg.predict_proba(X_test)[:, 1]
# (2)使用决策树算法
# 初始化决策树模型
Decision_tree = DecisionTreeClassifier(random_state=0)
# 定义多参数网格
parameters = {'max_depth': [3, 5, 7, 9, 11], 'criterion': ['gini', 'entropy', 'log_loss'],
'min_samples_split': [2, 5, 8, 11, 14]}
# 使用网络搜索调优模型
grid_search = GridSearchCV(Decision_tree, parameters, scoring='roc_auc', cv=5, n_jobs=-1)
grid_search.fit(X_train, y_train)
# 输出最佳参数
print("Best parameters found: ", grid_search.best_params_)
# 使用最佳参数重新训练模型
best_Decision_tree = grid_search.best_estimator_
best_Decision_tree.fit(X_train, y_train)
# 预测测试集
y_pred = best_Decision_tree.predict(X_test)
y_pred_proba = best_Decision_tree.predict_proba(X_test)[:, 1]
# (3)使用随机森林算法
# 初始化随机森林模型
Forest = RandomForestClassifier(random_state=0)
# 定义多参数网格
parameters = {'n_estimators': range(50, 151, 20), 'max_depth': range(2, 11, 2), 'min_samples_split': range(2, 11, 2),
'min_samples_leaf': range(1, 11, 1)}
# 使用网络搜索调优模型
grid_search = GridSearchCV(Forest, parameters, scoring='roc_auc', cv=3, n_jobs=-1)
grid_search.fit(X_train, y_train)
# 输出最佳参数
print("Best parameters found: ", grid_search.best_params_)
# 使用最佳参数重新训练模型
best_Forest = grid_search.best_estimator_
best_Forest.fit(X_train, y_train)
# 预测测试集
y_pred = best_Forest.predict(X_test)
y_pred_proba = best_Forest.predict_proba(X_test)[:, 1]
# 记录结束时间
end = time.time()
# 计算并显示运行时间
print('运行时间: {:.2f} 秒'.format(end - start))
# 打印分类报告
print(classification_report(y_test, y_pred))
# 打印混淆矩阵
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
def show_roc_auc(prob, actual):
# 计算AUC-ROC
roc_auc = roc_auc_score(actual, prob)
print(f"AUC-ROC: {roc_auc:.4f}")
# 绘制ROC曲线
# 计算ROC曲线
fpr, tpr, _ = roc_curve(actual, prob)
roc_auc = auc(fpr, tpr)
# 绘制ROC曲线
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()
show_roc_auc (y_pred_proba, y_test)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)