Word2vec模型#词向量#相似度匹配
在自然语言处理任务中,首先需要解决的关键问题是如何让计算机理解人类语言。由于计算机的本质是进行数字运算,它无法直接理解自然语言。因此,解决这个问题的核心在于将人类语言转化为数学符号。词向量技术通过将自然语言中的每个单词转化为与之对应的向量,能够实现这一目标。简而言之,词向量就是将每个词表示为N维空间中的一个点,而相似的词则对应着在向量空间中较为接近的位置。这使得计算机能够通过对这些稠密向量的运算,
文章目录
词向量介绍
在自然语言处理任务中,首先需要解决的关键问题是如何让计算机理解人类语言。由于计算机的本质是进行数字运算,它无法直接理解自然语言。
因此,解决这个问题的核心在于将人类语言转化为数学符号。词向量技术通过将自然语言中的每个单词转化为与之对应的向量,能够实现这一目标。
简而言之,词向量就是将每个词表示为N维空间中的一个点,而相似的词则对应着在向量空间中较为接近的位置。这使得计算机能够通过对这些稠密向量的运算,理解和处理语言信息。
离散表示
在自然语言处理(NLP)中,将字词转换为离散且独立的符号表示的方法被称为独热编码(One-hot Encoding)。
其核心思想是用一个长向量来表示每个单词,该向量由一个“1”和N-1个"0"组成,其中“1”所在的位置对应于该单词在词汇表中的索引,而向量的维度N则等于词汇表的大小。
One-hot 编码生成的词向量是相互独立的,彼此之间没有任何潜在的联系,这导致其在实际应用中缺乏语义信息。此外,随着词汇量的增加,向量的维度也会迅速膨胀,容易引发维度灾难(curse of dimensionality)。
同时,由于 One-hot 编码形成的词向量使得特征空间极度稀疏,这在高维空间中可能会使许多线性任务变得可分。
分布式表示
为了解决离散表示的局限性,分布式表示(Distributed Representation)被提出。它的核心思想是通过训练,将单词嵌入到一个新的向量空间,并对其进行降维处理,通常从高维空间映射到低维空间,从而使单词能够被表示为固定长度的连续稠密向量。
这种方法的优势在于,它不仅能够减少因维度过高而带来的计算复杂度问题,还能使词与词之间形成有意义的“距离”关系,使其相似性可以通过数学计算来衡量。词向量的维度通常由人为设定,如 50 维或 100 维,每个维度都承载着特定的语义信息。
相比于传统的离散表示,分布式表示极大地增强了词向量的语义表达能力,为自然语言处理带来了重要的突破。
Word2vec模型发展
Word2Vec 是一种神经网络语言模型,它能够将单词映射到低维稠密向量空间,并通过向量之间的距离关系表达词语间的语义联系。2013 年,Mikolov 等人提出了这一工具,以解决离散表示和分布式表示在维度灾难、相似性计算以及模型适用性等方面的挑战。
该模型首先输入指定的语料库,采用特定的训练方法将词语转换为向量,随后通过向量计算衡量词语之间的相似性。随着大数据时代的迅猛发展,Word2Vec 已成为目前应用最广泛的词向量生成方法之一,并在自然语言处理领域发挥着重要作用。
训练模型
Word2vec 有两个训练模型[54]:连续词袋模型(Continuous Bag-of-Word Model, 简称CBOW)和跳字节模型(Skip-Gram Model)。
CBOW模型
CBOW模型包括输入层、隐含层和输出层,该模型根据上下文词语预测中词,在预测中学习新的词向量。CBOW模型结构如图所示。
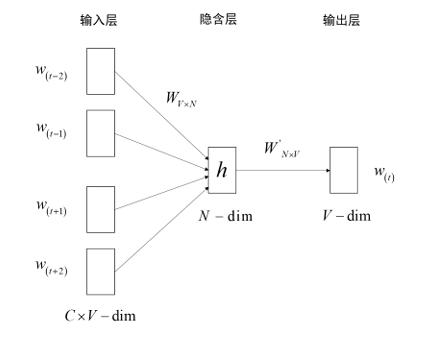
具体训练过程分成三步:
尽管模型的具体输出和预测结果并不是重点,我们关注的是模型训练过程中得到的输入权重矩阵,即词向量。词向量矩阵的每一行代表词汇表中对应词语的词向量,矩阵的行数等于词汇量的大小。
Skip-Gram 模型
Skip-gram 模型扭转 CBOW 模型的因果关系,该模型根据中心词预测上下文词语。它的模型结构如图所示。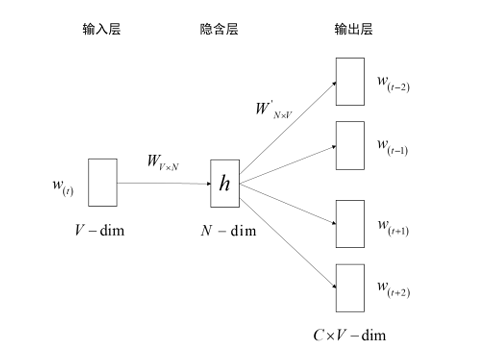
而这个步骤仍然与上个相似
总结
CBOW模型是根据(滑动窗口大小)周围词语,然后预测中心词,而Skip-Gram模型则是根据中心词,然后预测周围词(滑动窗口)
训练方法
在 Word2Vec 模型的训练过程中,当语料库的词汇表非常庞大时,输入层到隐含层和隐含层到输出层的权重矩阵也会变得非常庞大。这将导致梯度下降过程变得极其缓慢,训练过程的时间复杂度大幅增加。此外,还需要对大量训练数据进行权重调整,以避免出现数据拟合问题。
为了提高训练效率,常采用两种优化方法:负采样(Negative Sampling) 和 层序 Softmax(Hierarchical Softmax)。
负采样(Negative Sampling)
负采样(Negative Sampling)是一种通过减少输出层计算量来提高模型训练效率的优化方法。其基本思想是,在训练时,除了正样本(即正确的上下文词汇对),还从词汇表中随机选择一些负样本(即错误的词汇对)来进行训练。
具体步骤:
优点:
- 通过减少每次训练需要考虑的词汇数量,显著降低了计算量。
- 避免了对整个词汇表进行归一化计算,从而提高了训练速度。
缺点:
- 选择负样本的方式需要精心设计,可能会影响模型的效果。
层序 Softmax(Hierarchical Softmax)
层序 Softmax 是另一种提高训练效率的优化方法,其基本思想是通过使用二叉树结构代替传统的 Softmax 计算,来减少每次更新所需的计算量。
具体步骤:
Huffman结构如图所示。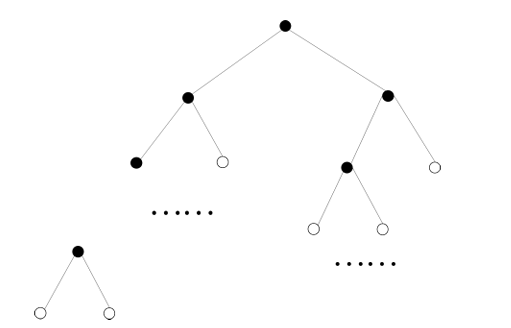
优点:
- 由于只需要经过树的路径,而非整个词汇表,可以大大减少计算量,尤其适用于大规模词汇表的情况。
- 训练速度比传统 Softmax 快,特别是在词汇表非常大的时候。
缺点:
- 构建哈夫曼树可能增加一定的额外复杂度。
- 可能对模型效果产生一定影响,因为它不是基于完整的概率分布。
基于Word2vec模型的数据处理流程
大数据背景下,数据形式越来越丰富多样,多呈现“文本+数值”的混合型数据,因此需要使用连续词袋模型或跳字节模型将分离出来的文本数据转化为计算机可以理解的向量,并与归一化后的数值型数据组合,得到完全数值型数据,方便对样本数据进行处理。
具体过程如图所示: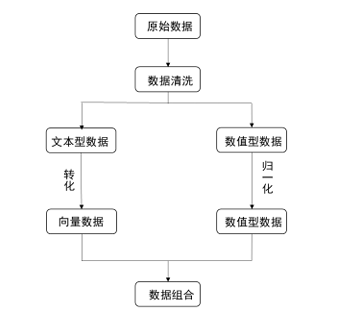
总结
- 负采样:通过选择一部分负样本来减少计算量,训练时只考虑正样本和少量负样本,提升效率。
- 层序 Softmax:通过使用哈夫曼树结构,减少了计算词汇表中每个词概率所需的时间,从而提高训练速度。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 38
38 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)