大语言模型基础之‘可扩展的训练技术’(一)
随着模型参数规模与数据规模的持续扩展,如何“优雅的”在有限计算资源下实现高效模型训练?
技术挑战概述
随着模型参数规模与数据规模的持续扩展,在有限计算资源下实现高效模型训练已成为制约大语言模型研发的关键挑战,主要体现为两个核心问题:
1. 训练效率优化
如何在保持模型性能的前提下加速训练过程-->>提高训练效率
2. 模型分布式加载
如何将超大规模模型有效部署到异构计算单元-->>将大模型有效的加载到不同的处理器中
主流高效训练技术
当前业界主要采用以下三种关键技术组合:
- ✅3D并行训练
- ✅ 激活重计算(Activation Checkpointing)
- ✅ 混合精度训练(Mixed Precision Training)
本篇介绍下:
3D并行训练
3D并行策略实际上是三个常用的并行训练技术的组合,即
- 数据并行(Data Parallelism)
- 流水线并行(Pipeline Parallelism)
- 张量并行(Tensor Parallelism)
数据并行
---可通过增加 GPU 数量来提高训练效率
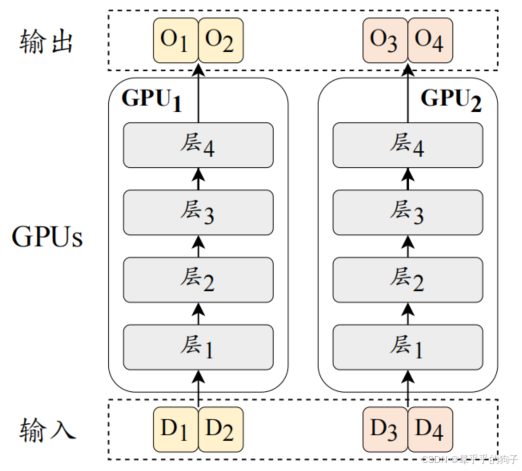
数据并行是一种提高训练吞吐量的方法,它将模型参数和优化器状态复制到多个 GPU 上,然后将训练数据平均分配到这些 GPU 上。
如上图,四条数据(D1、D2、D3、D4)被分成两份(D1D2、D3D4),由两张卡进行分别计算,然后我们会将两张卡的梯度进行平均后再更新模型,这样便等效于执行了批次为 4 的梯度更新。鉴于梯度计算在不同 GPU 上的独立性,数据并行机制展现出高度的可扩展性,可以通过增加 GPU 数量来提高训练效率。
流水线并行
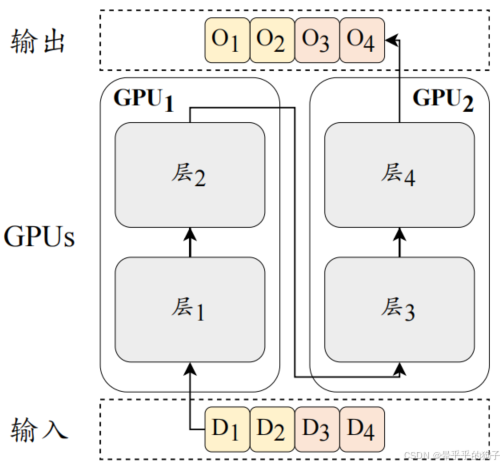
流水线并行是将大语言模型不同层的参数分配到不同的GPU上。
实际中,通常将transformer连续的层加载到同一GPU中,能够有效减少GPU之间隐藏状态或梯度的成本。
如上图,Transformer 的第 1-2 层部署在 1 号 GPU,将 3-4 层部署在 2 号 GPU。然而,朴素的流水线调度并不能达到真正的并行效果。以图为例,1 号 GPU 在前向传播后需要等待 2 号 GPU 反向传播的结果才能进行梯度传播,因此整个流程是“1 号前向->2 号前向->2 号反向->1 号反向”的串行操作,大大降低了 GPU 的利用率。
如何解决这个问题呢?
流水线并行配合梯度累计(Gradient Accumulation)技术即可优化。
该技术的主要思想是,计算一个批次的梯度后不立刻更新模型参数,而是累积几个批次后再更新,这样便可以在不增加显存消耗的情况下模拟更大的批次。也就是,在流水线并行中使用了梯度累积后,1 号卡前向传播完第一个批次后,便可以不用等待,继续传播第二个和后续的批次,从而提高了流水线的效率。
张量并行
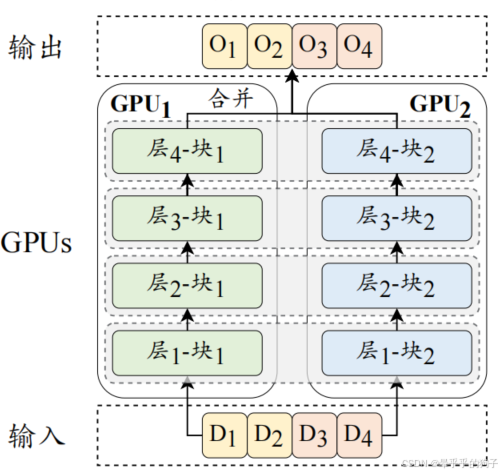
张量并行与流水线并行是两种将大模型参数加载到多个GPU上的训练技术。
流水线并行-->>侧重于将模型的不同层分配到不同的GPU上。
张量并行 -->>进一步分解了模型的参数张量(即参数矩阵)。
具体的,对于大语言模型中的某个矩阵乘法WH,参数矩阵W可以按照列分成两个子矩阵W1和W2,那么原矩阵乘法即可表示为[W1H,W2H]。进而,将参数矩阵W1和W2放置在两张不同的GPU上,并行的执行两个矩阵乘法操作,最后通过跨GPU通信将两个GPU的输出组合成最终的结果。
完成!!!
最佳实践原则
层级优先:优先使用数据并行->流水线并行->张量并行
做个记录,也希望给有需要的同学一点点帮助,我也在学习中。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)