大模型入门:文本分类任务(基于fasttext与jieba)
本人认为将文本分类任务作为大模型的入门任务来说是不错的,因为这类任务的目的明确,数据获取较简单,模型回馈的结果明显,是很好的起点。 而“情绪分类”则是文本分类任务中的经典,我们下面就基于python的fasttext库与jieba分词器来完成一个“情绪分类”的任务。
前言
如果您是一个完全的新手,我建议你先阅读我同专栏下的关于大模型的笔记(这是远远不够的,还需要阅读其他人的博客以及更多的文献),对大模型的各种概念有一个简单的了解,再开始下面的任务。然后,在任务中遇到任何陌生的概念时(如不清楚什么是fasttext,什么是“文本分类任务”),请暂停你的脚步,在浏览器中搜索并阅读对应的概念。不需要完全理解,只需要有一个大概的印象即可,这些印象会随着你的学习慢慢串联起来,终有一天引起质变。
本人认为将文本分类任务作为大模型的入门任务来说是不错的,因为这类任务的目的明确,数据获取较简单,模型回馈的结果明显,是很好的起点。
而“情绪分类”则是文本分类任务中的经典,我们下面就基于python的fasttext库与jieba分词器来完成一个“情绪分类”的任务。
这篇博客不会教您如何下载fasttext与jieba分词器,如果您仍未下载请先查阅其他博客下载。但我可以为你分享踩过的坑:在下载fasttext我直接pip安装发现怎么都不行,最后是直接下载whl文件,也就是fasttext_wheel-0.9.2-cp310-cp310-win_amd64,然后在本地pip安装的。然后jieba分词器在下载之后pycharm无法识别出来,还需要手动把他的文件夹移到python\Lib\site-packages下才行。
训练一个大模型大致可以分为:数据收集,数据预处理,训练模型,模型评估,微调模型这几步,下面我将安装这几步来完成任务。
数据收集
巧妇难为无米之炊,没有数据就没有模型。数据是一个模型的核心。我已经将这个任务需要用到的数据集上传了,是关于某一酒店评论的数据集。至于这个数据集的源头,我很抱歉因为时间久远我已经忘记了。但是,下面有一些收集了数据集的网站,希望以后可以帮你找到你想要的数据集:
更多的网址可以自行查找
数据预处理
在压缩文件中有pos与neg两个文件夹,分别表示好评(正面情绪)与差评(负面情绪)。里面各有2000个txt文件,表示2000条评论。而faxttext需要的格式是下面这样的
__label__消极 服务态度极差,前台超级没礼貌!
__label__消极 再也不来了,根本就是骗钱的地方,什么东西都贵的要死。
__label__积极 房间整洁,风景优美,五星好评!所以我们需要对数据进行处理,将所有的评论全部整合到一个txt文件中去,并为他们添加标签。
from os import listdir
path = r"C:\Users\凡尘\PycharmProjects\pythonProject\课外\LLM\文本分类\fasttext\pos" # 更改为你的路径哟
path2 = "neg.txt" # 写入哪里?
files = listdir(path)
with open(path2, "w", encoding="utf-8") as f1: # 打开文件夹读取所有文件
for i in files:
with open(rf"{path}\{i}", "r", encoding="utf-8") as f2: # 写入
str_in = ""
for j in f2.readlines():
str_in += j.strip() # 吸收回车符
str_in = "__label__积极\t" + str_in + "\n" # 构造格式
f1.write(str_in)处理完后我们就获得了合适格式的数据。(同理使用以上代码处理neg文件夹)
接下来我们需要进行分词操作以提高模型的效率与训练速度。分词操作可以简单理解为为一个句子“断句”,将“广州大学是世界上最好的大学”断句为“广州 大学 是 世界上 最好 的 大学”,而且真正作用与详细原理这里限于篇幅就不展开讲了,希望你自行查阅其他资料。
在这里我选择的分词器是jieba分词器,修改一下下上面的代码来实现分词操作。:
from os import listdir
import jieba
path = r"C:\Users\陈瑞达\PycharmProjects\pythonProject\课外\LLM\文本分类\fasttext\pos"
path2 = "pos.txt" # 写入哪里?
files = listdir(path)
with open(path2, "w", encoding="utf-8") as f1: # 打开文件夹读取所有文件
for i in files:
with open(rf"{path}\{i}", "r", encoding="utf-8") as f2: # 写入
str_in = ""
for j in f2.readlines():
str_in += j.strip() # 吸收回车符
str_temp = ""
for k in jieba.cut(str_in):
# print(k) # 尝试保留这一行,看看输出的是什么?
str_temp += k + " " # 使用空格来分割
str_in = "__label__积极\t" + str_temp + "\n" # 构造格式
f1.write(str_in)
neg文件夹同理。在处理好之后我们还需要执行最后一步,对数据集进行划分,将其按一定比例划分为训练集与测试集(一般是8:2或7:3)。顾名思义训练集是用来训练你的模型的数据,而测试集是用来测试你模型的准确性的。
你需要将pos.txt与neg.txt的各1600条评论Ctrl+x出来贴到train.txt中去,剩下的400条也各自取出来贴到test.txt中去。
当然,如果您非常懒,我也为你准备好了脚本:
# 参数
train_txt_path = "train.txt" # 无需手动创建,当python发现你没有这个文件的时候它会帮你创建
test_txt_path = "test.txt"
rate = 0.8 # 以80%的数据作为训练集
total = 2000 # 2000条数据/每文件
# txt读写
with open(train_txt_path, "w", encoding="utf-8") as f_train:
with open(test_txt_path, "w", encoding="utf-8") as f_test:
with open("pos.txt", "r", encoding="utf-8") as f_pos:
for i, v in enumerate(f_pos.readlines()):
if i < total * rate:
f_train.write(v)
else:
f_test.write(v)
with open("neg.txt", "r", encoding="utf-8") as f_neg:
for i, v in enumerate(f_neg.readlines()):
if i < total * rate:
f_train.write(v)
else:
f_test.write(v)
这样我们就预处理好数据,可以开始进行模型的训练了。
为了避免你在上面的步骤中卡死而无法学习下面的关键内容,我已经将预处理好的train.txt与test.txt一并打包上传了。
模型训练
from fasttext import train_supervised
# 路径参数
train_data_path = 'train.txt'
# 模型训练
model = train_supervised(train_data_path) # 以默认的模型进行,不进行任何参数调整。train_supervised()直接构建模型,炒鸡方便
# model = train_supervised(train_data_path, lr=1, epoch=15, wordNgrams=2, verbose=2, minCount=1, dim=100) # 或者你想要我的参数?说实话不是特别好
model.save_model("model.bin") # 保存模型。(你也不想训练了两天的模型只能用一次吧)可以看到fasttext的训练代码非常少,非常清晰且萌新友好。
模型评估
from fasttext import load_model
# 路径参数
model_path = "model.bin"
test_data_path = 'test.txt'
# 加载模型
model = load_model(model_path)
# 数据读入
list_comment = [] # 用来存放评测集中评论的部分
list_emotion = [] # 存放情绪评价的部分,即label
with open(test_data_path, "r", encoding="utf-8") as f1:
for i in f1.readlines(): # 切分情绪标签与评价内容二者
list_comment.append(i.strip("__label__积极").strip("__label__消极").strip())
list_emotion.append(i[9:11])
# 变量记录
list_correct_rate = []
correct_num = 0 # 正确匹配的数量
recall_num = 0 # 召回数量
list_record = [] # 记录预测的结果
# 开始评测
list_ans = model.predict(list_comment)
for i, v in enumerate(list_ans[0]):
list_record.append(v[0].strip("__label__")) # 记录每条内容评测的结果
if v[0].strip("__label__") == list_emotion[i]: # 如果预测结果与标签结果相同则视为预测正确
correct_num += 1
if list_emotion[i] == "积极": # 用积极标签计算召回率(大概是这样吧?)
recall_num += 1
correct_rate = correct_num / len(list_comment)
recalling_rate = recall_num / list_emotion.count("积极")
list_correct_rate.append(correct_rate)
print(f"\n预测为积极的数量为:{list_record.count('积极')},应为{list_emotion.count('积极')}.\n"
f"预测为消极的数量为:{list_record.count('消极')},应为{list_emotion.count('消极')}.")
print(f"正确率为:{'%.4f' % correct_rate},召回率为:{'%.4f' % recalling_rate}")
print(f"由内置函数计算的精准正确率为:{model.test(test_data_path)[-1]}")
在我的电脑上跑出来的结果是这样的:
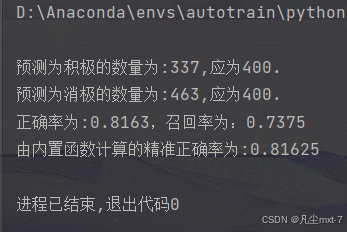
可以看到我们模型的准确率游八成左右,但是到这里你可能还是觉得没有一个清晰的概念,毕竟准确率是看不见摸不着的一个数字。那么我们就把模型对每一个评测集的判断结果输出出来看看吧。
(将以下代码加在模型评估代码的最后:)
for i, v in enumerate(list_record):
if v=="积极":
print(f"模型对于:\033[4;36m{list_comment[i]}的评估结果是\033[0m:\033[92m{v}\033[0m")
else:
print(f"模型对于:\033[4;36m{list_comment[i]}的评估结果是\033[0m:\033[31m{v}\033[0m")
print()输出结果:
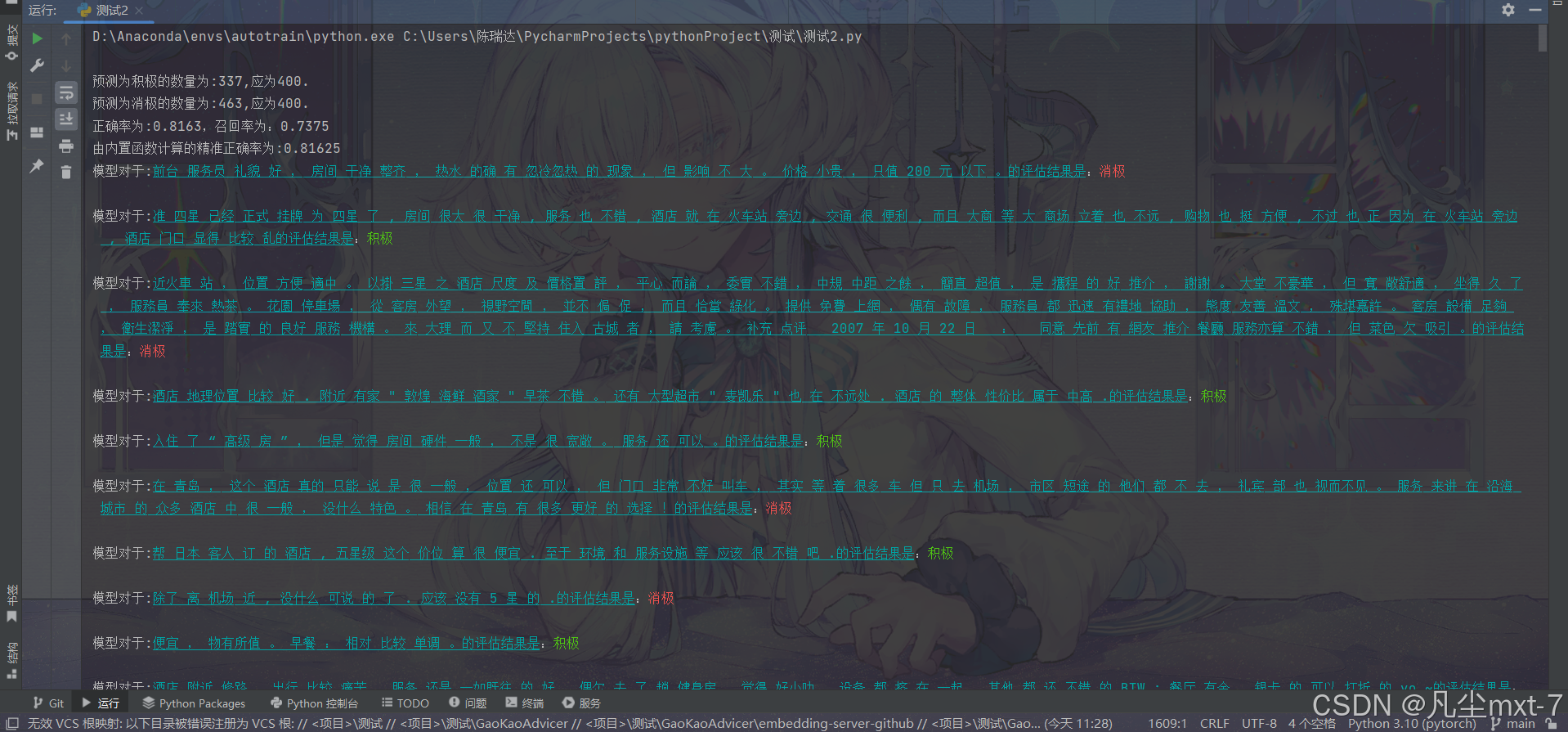
现在我们就能看到我们的模型对于每一条数据的评估结果了,你可以直观地感受到文本分类任务的作用了吗?
模型调整
尝试调整模型训练时的参数,调整训练于测试集的比例来提高模型的准确率吧,相信你能做到。
最后
希望本文对你学习人工智能和大模型有帮助。有任何问题可以向作者提出。
(PS:才发现你们下载我上传的文件是要积分的,我还以为是免费的,等过几天我有空了传网盘上给大家。)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)