还不懂深度学习里的梯度下降?从奇幻下山之旅开启模型优化秘籍!
批量梯度下降就像是一群人一起商量,方向比较准,但行动起来比较慢。随机梯度下降就像独行侠,行动迅速,但方向可能不太靠谱,容易走弯路。小批量梯度下降就像小队协作,既保证了一定的速度,又能让方向相对稳定。通过这三种不同的 “下山” 方式,我们可以根据实际情况选择最合适的方法,帮助我们更快、更准确地找到损失函数的最小值,优化我们的模型参数。
想象一下,你正置身于一座云雾缭绕的大山之中,你的目标是找到这座山的最低点,也就是山谷的位置。这座山就像是我们在机器学习里要优化的损失函数,而山的最低点就是损失函数的最小值,也就是我们模型参数的最优解。接下来,我们就借助这个有趣的场景,深入了解三种常见的梯度下降算法。
一、批量梯度下降(Batch Gradient Descent,BGD):众人齐心探谷底
原理
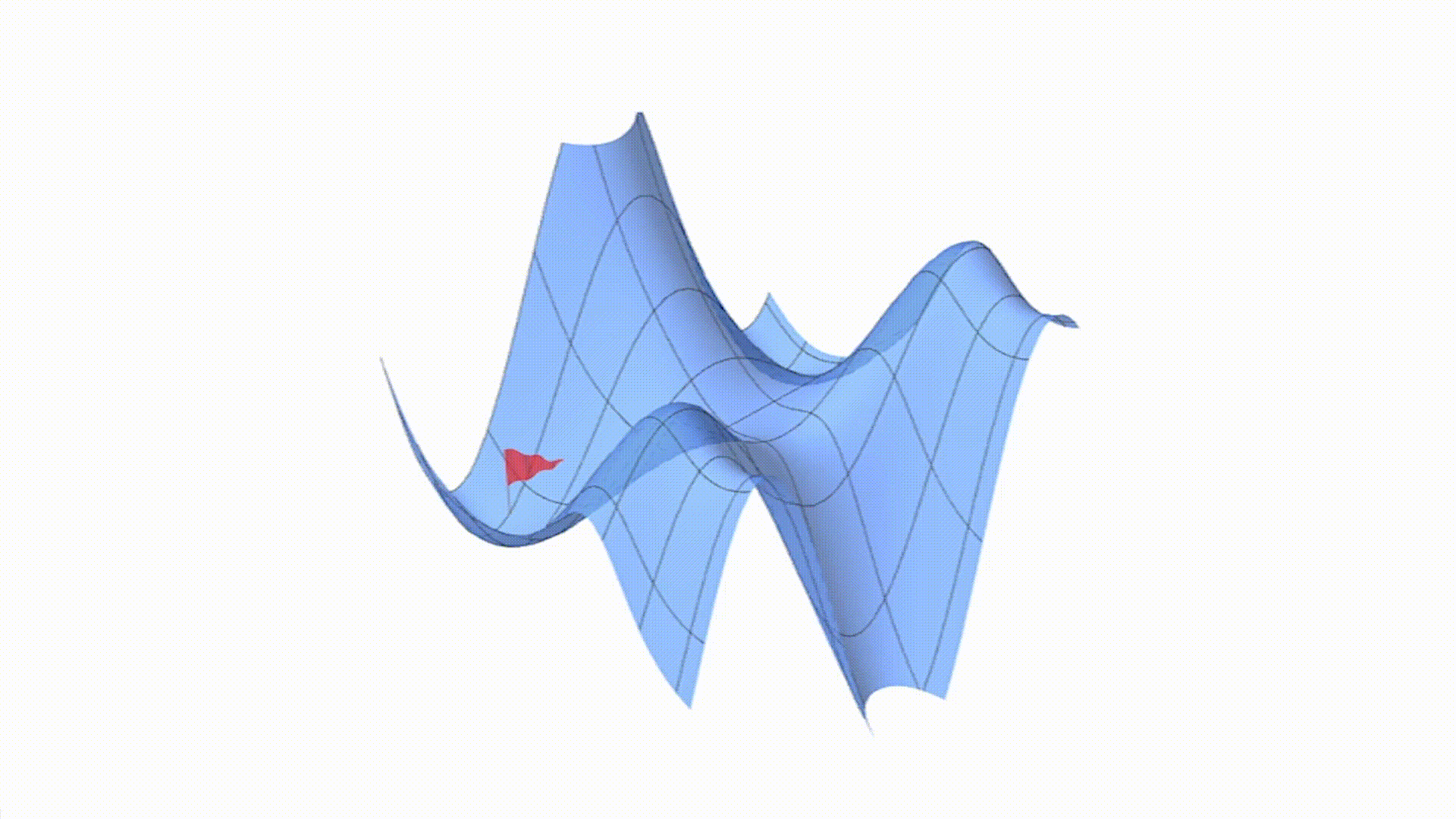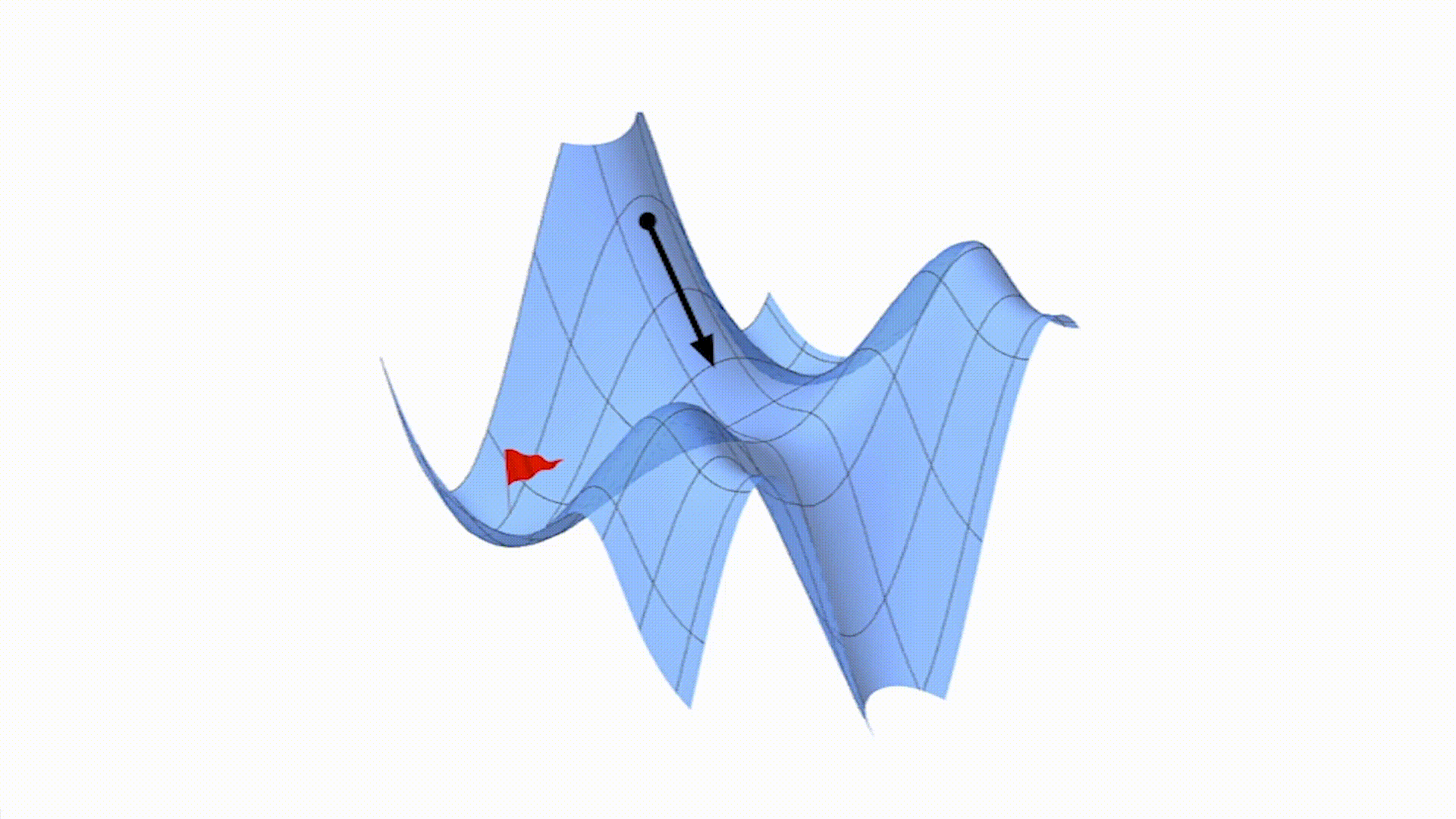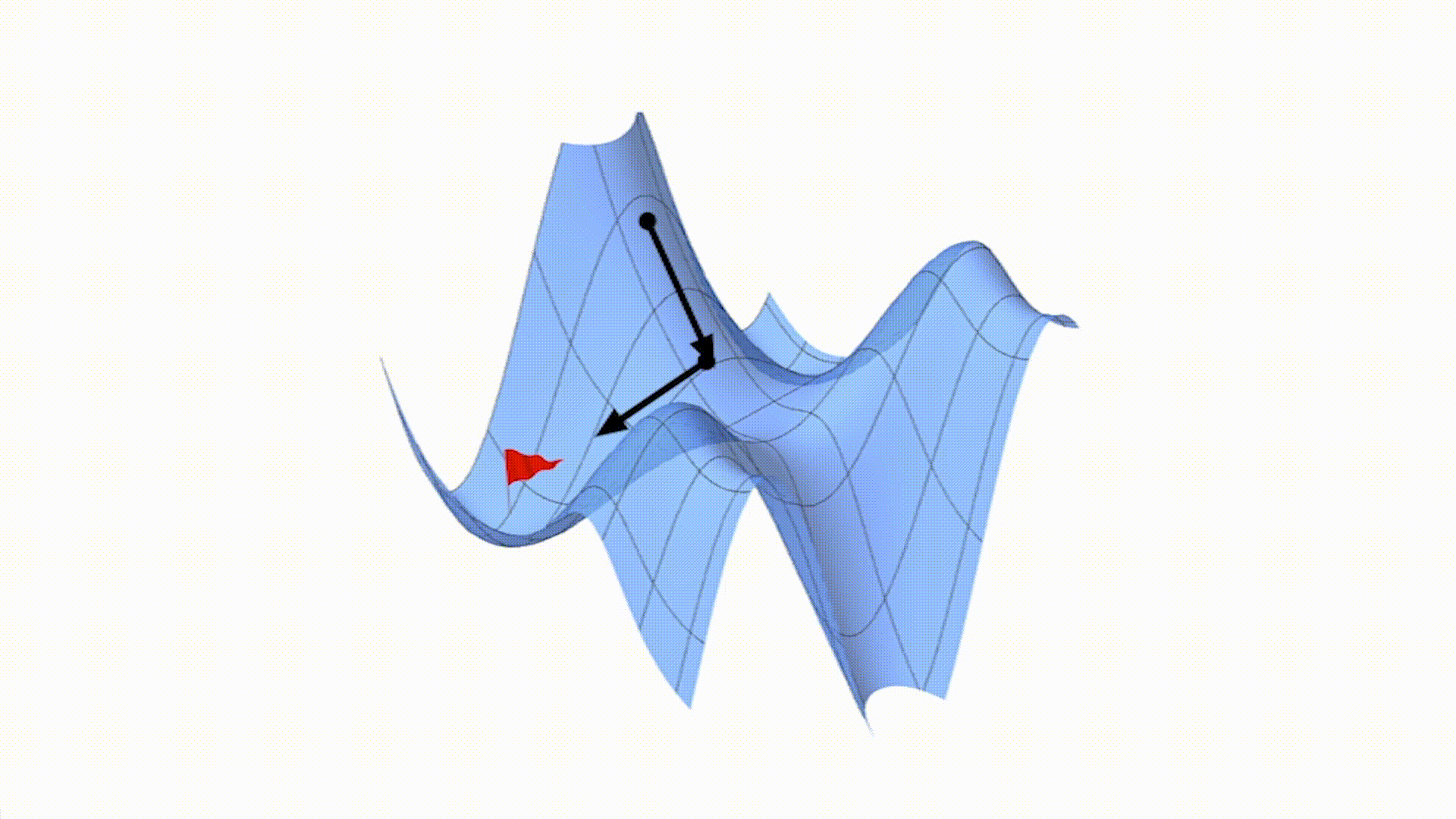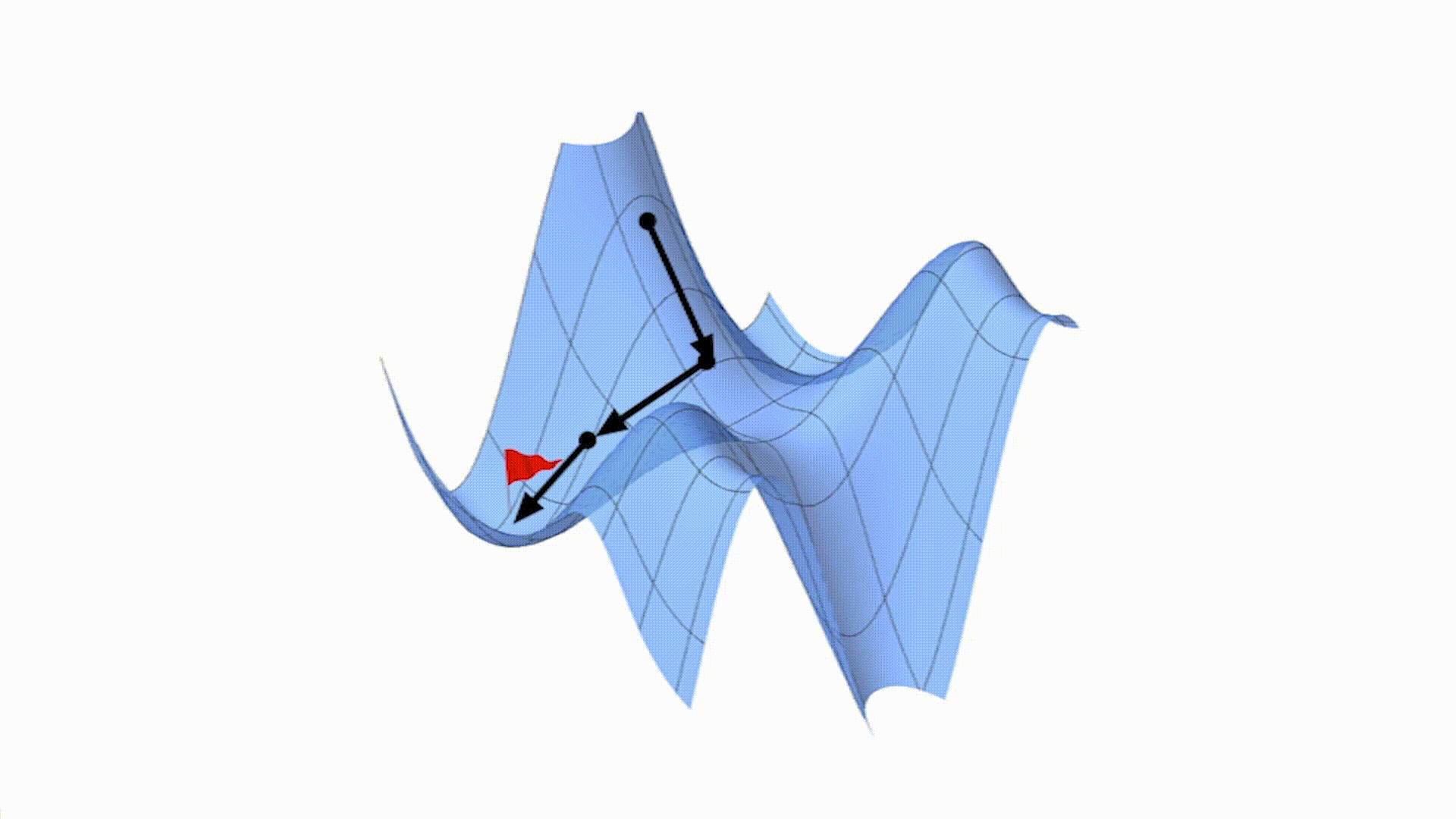
批量梯度下降就像是一群人一起行动,大家站在山上的同一个位置,每个人都仔细观察周围的地形,然后一起商量出一个大家都认为是最陡峭的下山方向。这里的 “一群人” 就代表了所有的训练数据。每一次决定往哪个方向走,都需要综合考虑所有训练数据给出的信息。
具体来说,每次我们要下山(更新模型参数)的时候,都要把所有的训练数据拿出来,根据这些数据计算出一个整体的下山方向(损失函数关于参数的梯度)。然后,朝着这个方向迈出一步(更新参数)。这个过程会不断重复,直到我们觉得已经接近或者到达了山谷(损失函数收敛)。
通俗化的数学公式
假设我们站在山上的位置用参数 θ 来表示,山的高度就是损失函数 J(θ)。我们要找到一个下山的方向,这个方向就是损失函数在当前位置的梯度 ∇J(θ)。梯度就像是一个箭头,它指向山上升最快的方向,而我们要下山,所以要朝着它的反方向走。
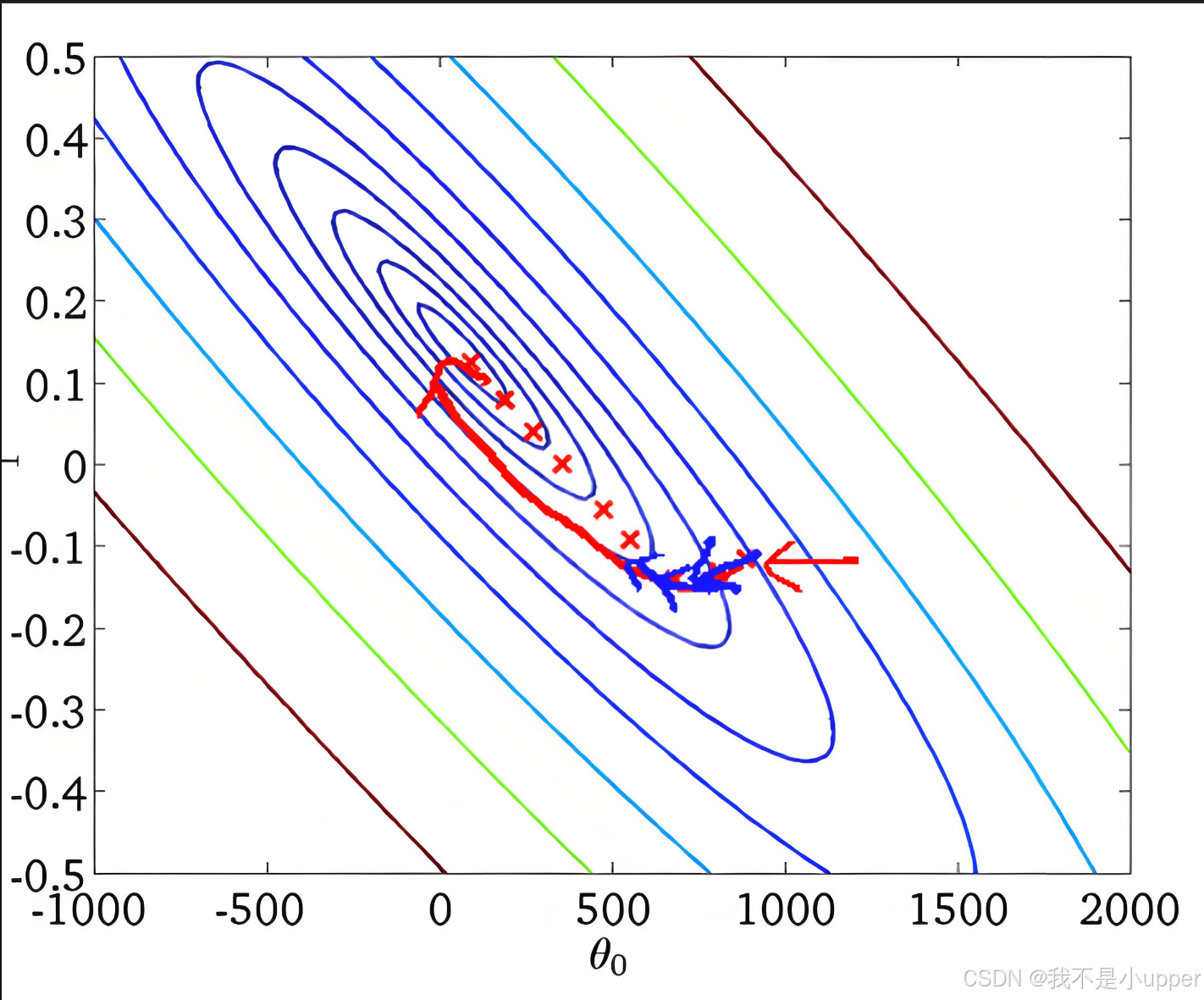
每走一步的大小由学习率 α 决定,学习率就像是我们每一步跨出去的距离。那么更新参数的公式就可以写成:
θ=θ−α∇J(θ)
这就好比我们先确定了下山的方向(梯度的反方向),然后按照学习率规定的步长,朝着这个方向跨出一步,到达一个新的位置(新的参数值)。
代码示例
import numpy as np
# 定义损失函数,这里以简单的线性回归均方误差为例
def loss_function(X, y, theta):
m = len(y)
# 计算预测值
predictions = X.dot(theta)
# 计算均方误差
loss = (1/(2*m)) * np.sum(np.square(predictions - y))
return loss
# 批量梯度下降算法
def batch_gradient_descent(X, y, theta, alpha, num_iters):
m = len(y)
loss_history = []
for iter in range(num_iters):
# 计算预测值
predictions = X.dot(theta)
# 计算梯度
gradient = (1/m) * X.T.dot(predictions - y)
# 更新参数
theta = theta - alpha * gradient
# 计算当前损失
loss = loss_function(X, y, theta)
loss_history.append(loss)
return theta, loss_history
# 示例数据
X = np.array([[1, 1], [1, 2], [1, 3], [1, 4]])
y = np.array([2, 4, 6, 8])
# 初始化参数
theta = np.zeros(X.shape[1])
# 学习率
alpha = 0.01
# 迭代次数
num_iters = 1000
# 运行批量梯度下降算法
theta, loss_history = batch_gradient_descent(X, y, theta, alpha, num_iters)
print("最终参数 theta:", theta)二、随机梯度下降(Stochastic Gradient Descent,SGD):独行侠的冒险之旅
原理
随机梯度下降就像是一个勇敢的独行侠,他在山上随机选择一个方向就开始往下走。每走一步,他就重新观察周围的地形,然后再随机选择一个新的方向继续走。这里的 “独行侠” 就代表了每次只使用一个训练数据来计算下山的方向。
这种方法的好处是速度非常快,因为每次只需要考虑一个数据,不需要像批量梯度下降那样综合所有数据。但是,由于每次只根据一个数据来决定方向,所以这个方向可能不是全局最优的,可能会让我们在下山的过程中走很多弯路,甚至在山谷附近来回震荡。
通俗化的数学公式
同样,我们还是用参数 \(\theta\) 表示我们在山上的位置,损失函数![]() 表示根据第 i 个训练数据计算出来的山的高度。我们随机选择一个训练数据
表示根据第 i 个训练数据计算出来的山的高度。我们随机选择一个训练数据,计算出这个数据对应的下山方向(梯度
),然后朝着这个方向按照学习率
规定的步长走一步,更新参数的公式为:
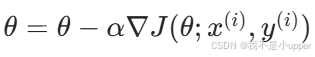
代码示例
import numpy as np
# 定义损失函数,这里以简单的线性回归均方误差为例
def loss_function(X, y, theta):
m = len(y)
# 计算预测值
predictions = X.dot(theta)
# 计算均方误差
loss = (1/(2*m)) * np.sum(np.square(predictions - y))
return loss
# 随机梯度下降算法
def stochastic_gradient_descent(X, y, theta, alpha, num_iters):
m = len(y)
loss_history = []
for iter in range(num_iters):
for i in range(m):
# 随机选择一个样本
random_index = np.random.randint(m)
xi = X[random_index:random_index+1]
yi = y[random_index:random_index+1]
# 计算预测值
predictions = xi.dot(theta)
# 计算梯度
gradient = xi.T.dot(predictions - yi)
# 更新参数
theta = theta - alpha * gradient
# 计算当前损失
loss = loss_function(X, y, theta)
loss_history.append(loss)
return theta, loss_history
# 示例数据
X = np.array([[1, 1], [1, 2], [1, 3], [1, 4]])
y = np.array([2, 4, 6, 8])
# 初始化参数
theta = np.zeros(X.shape[1])
# 学习率
alpha = 0.01
# 迭代次数
num_iters = 1000
# 运行随机梯度下降算法
theta, loss_history = stochastic_gradient_descent(X, y, theta, alpha, num_iters)
print("最终参数 theta:", theta)三、小批量梯度下降(Mini - Batch Gradient Descent,MBGD):小队协作寻幽谷
原理
小批量梯度下降就像是一群人分成了几个小队,每个小队都根据自己观察到的地形,商量出一个下山的方向。这里的 “小队” 就代表了一小批训练数据。每次更新参数的时候,我们不是使用所有的数据,也不是只使用一个数据,而是随机选择一小批数据(比如 16、32 或者 64 个),根据这一小批数据计算出下山的方向,然后朝着这个方向更新参数。
这种方法结合了批量梯度下降和随机梯度下降的优点。它不像批量梯度下降那样需要考虑所有数据,计算量相对较小;也不像随机梯度下降那样只根据一个数据做决定,更新相对更稳定,不容易在山谷附近震荡。
通俗化的数学公式
我们还是用参数 \(\theta\) 表示位置,损失函数![]() 表示根据一小批(b 个)训练数据计算出来的山的高度。我们随机选择一小批训练数据
表示根据一小批(b 个)训练数据计算出来的山的高度。我们随机选择一小批训练数据 ,计算出这一小批数据对应的下山方向
![]() ,然后按照学习率
,然后按照学习率规定的步长更新参数:
![]()
import numpy as np
# 定义损失函数,这里以简单的线性回归均方误差为例
def loss_function(X, y, theta):
m = len(y)
# 计算预测值
predictions = X.dot(theta)
# 计算均方误差
loss = (1/(2*m)) * np.sum(np.square(predictions - y))
return loss
# 小批量梯度下降算法
def mini_batch_gradient_descent(X, y, theta, alpha, num_iters, batch_size):
m = len(y)
loss_history = []
for iter in range(num_iters):
# 随机打乱样本顺序
permutation = np.random.permutation(m)
X_shuffled = X[permutation]
y_shuffled = y[permutation]
for i in range(0, m, batch_size):
# 选取一小批样本
xi = X_shuffled[i:i+batch_size]
yi = y_shuffled[i:i+batch_size]
# 计算预测值
predictions = xi.dot(theta)
# 计算梯度
gradient = (1/len(yi)) * xi.T.dot(predictions - yi)
# 更新参数
theta = theta - alpha * gradient
# 计算当前损失
loss = loss_function(X, y, theta)
loss_history.append(loss)
return theta, loss_history
# 示例数据
X = np.array([[1, 1], [1, 2], [1, 3], [1, 4]])
y = np.array([2, 4, 6, 8])
# 初始化参数
theta = np.zeros(X.shape[1])
# 学习率
alpha = 0.01
# 迭代次数
num_iters = 1000
# 批量大小
batch_size = 2
# 运行小批量梯度下降算法
theta, loss_history = mini_batch_gradient_descent(X, y, theta, alpha, num_iters, batch_size)
print("最终参数 theta:", theta)
总结
- 批量梯度下降就像是一群人一起商量,方向比较准,但行动起来比较慢。
- 随机梯度下降就像独行侠,行动迅速,但方向可能不太靠谱,容易走弯路。
- 小批量梯度下降就像小队协作,既保证了一定的速度,又能让方向相对稳定。
通过这三种不同的 “下山” 方式,我们可以根据实际情况选择最合适的方法,帮助我们更快、更准确地找到损失函数的最小值,优化我们的模型参数。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)