图像处理即插即用模块1(图像增强,去噪,去雨,去雾等通用)TOPK稀疏注意力
论文题目:Learning A Sparse Transformer Network for Effective Image Deraining论文主要可用模块:TSAK稀疏注意力模块。
论文题目:Learning A Sparse Transformer Network for Effective Image Deraining
论文地址:https://arxiv.org/pdf/2303.11950
论文主要可用模块:TSAK稀疏注意力模块
论文讲解
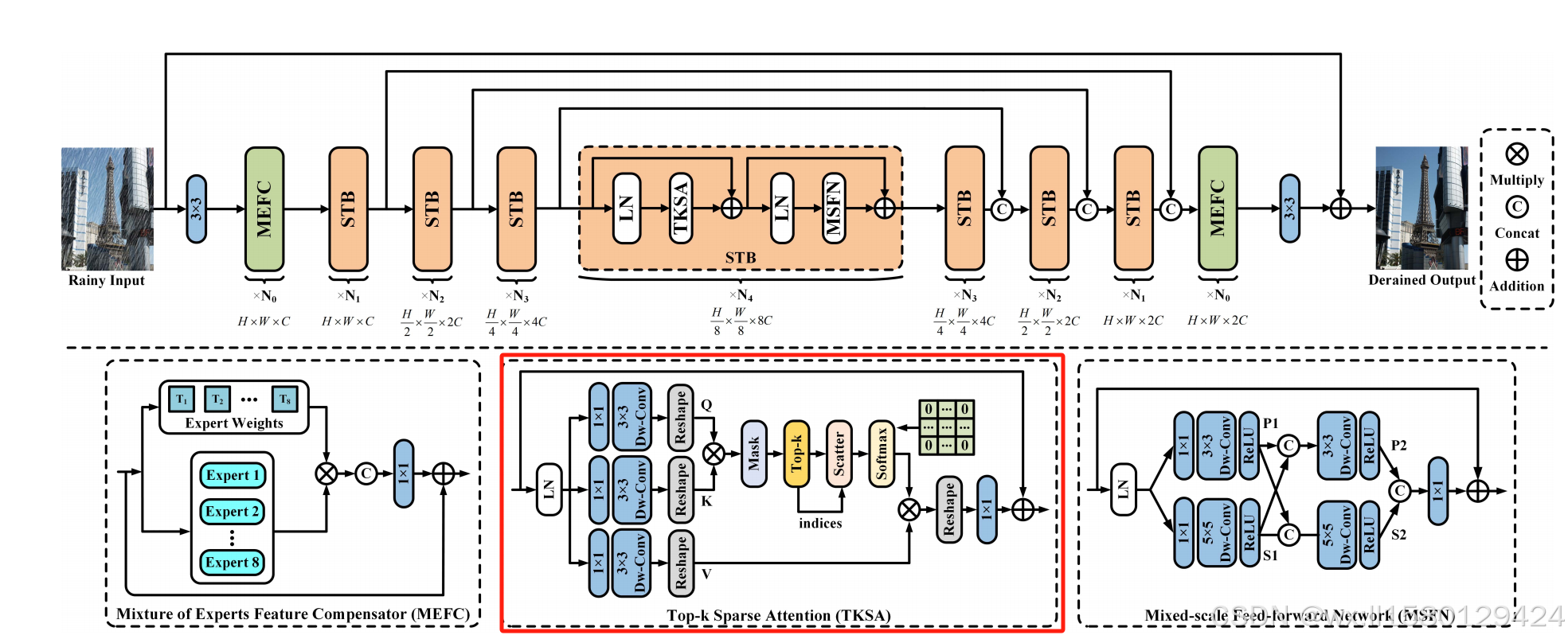
1.结构:
也是由常规的U-Net结构组成,对于编码器和解码器中的注意力层结构,也是很常规的线性层加注意力层加残差链接再接线性层,很适合才开始接触模块缝合的同学,只需要找到相似的注意力结构层,只需考虑维度即可直接替换。
2.创新点:
该论文提出了一种基于transformer的图像处理网络,其中核心思想是通过引入Top-k选择机制来选择最有用的自注意力值,从而避免无关特征对特征聚合过程的干扰。这使得网络在进行特征聚合时更加高效,能够更好地重建清晰的图像。
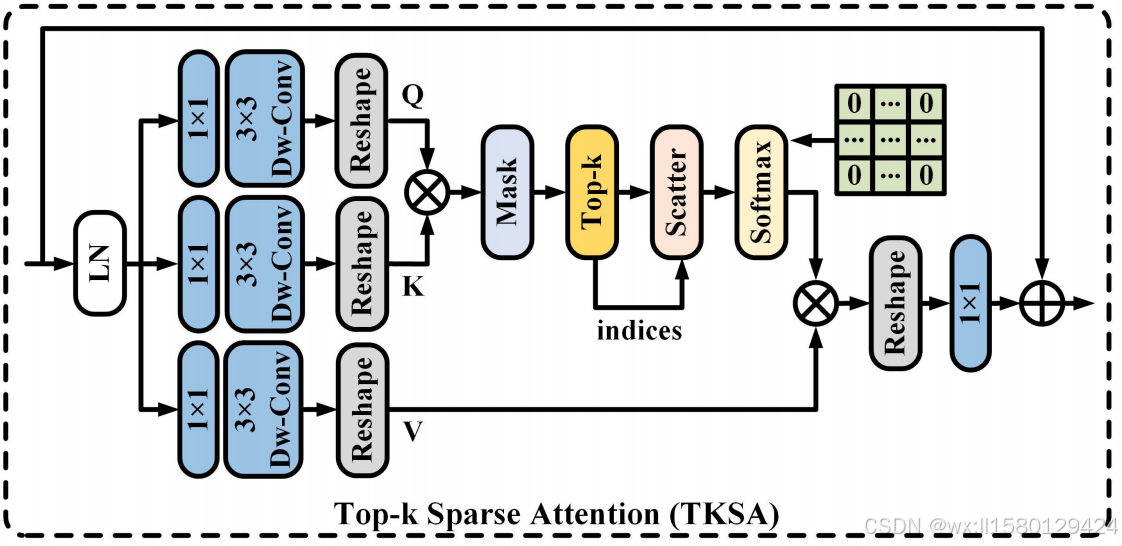
3.TKSA详解:
在标准的Transformer自注意力机制中,所有的query-key对都会被用来计算注意力,进行特征聚合。然而,因为图像处理方向的图片一般较为复杂这种密集计算方式容易受到无关特征的影响,影响处理效率。为了解决这个问题,论文提出了Top-k稀疏注意力(TKSA)机制,它通过以下几个步骤改进了注意力机制:
-
计算相似度:首先,对于每一对query和key,计算它们之间的相似度得分。
-
Top-k选择:然后,从这些相似度得分中选择最大的k个值。这些最重要的注意力值将用于后续的特征聚合。而其他的较小值将被丢弃,从而减少无关信息的干扰。
-
自适应选择:选择的k值是动态可调的,具体通过学习来确定。通过这种方式,网络能够自适应地调整稀疏性的程度,从而最大程度地保留有用的信息。
4.优点:
- 减少无关特征的干扰:通过保留最重要的注意力分数,TKSA可以减少无关特征对图像恢复过程的影响,从而提升去雨效果。
- 提高计算效率:稀疏注意力的引入使得计算更加高效,尤其是在图像去雨这种需要处理大量图像数据的任务中,显著减少了不必要的计算量。
- 增强特征聚合能力:由于Top-k选择机制专注于最相关的信息,能够更有效地聚合特征,从而有助于更清晰的图像恢复。
- 提高图像恢复的细节和纹理:通过减少不相关的噪声,改进的注意力机制能够更好地恢复图像中的细节和纹理,使得去雨后的图像更加自然。
实际应用
1.创新应用:
- 图像去噪:在图像去噪中,Top-k稀疏注意力机制可以帮助网络从大量的无关噪声中筛选出最重要的图像特征。标准的自注意力机制在处理图像时,会考虑所有位置的相似性,这对于图像去噪可能导致计算资源的浪费,并且在复杂的噪声环境中容易引入误差。通过引入Top-k选择机制,网络能够聚焦于那些最相关的图像区域,减少无关特征对图像恢复的干扰,提高去噪效果。
- 图像超分辨率:Top-k稀疏注意力可以用于从低分辨率图像中提取重要的空间信息,通过对相关性较高的区域进行关注,提高图像的细节恢复能力。相比于传统的全局自注意力,Top-k选择机制能够在较低的计算成本下,更精确地增强图像的高频细节,避免对不相关区域的过度关注。
- 目标检测:Top-k稀疏注意力可以帮助网络选择与目标对象高度相关的区域,从而提高检测准确性。在传统的自注意力机制中,所有区域都会被考虑,这可能导致不必要的计算和低效的特征选择。Top-k稀疏注意力可以更有效地聚焦于与目标对象相关的区域,尤其是在复杂场景下,有效减少误检和漏检现象。
- 图像去雨:标准的自注意力机制可能在处理雨滴时会出现不必要的信息干扰,而Top-k稀疏注意力机制可以自适应地选择与背景或清晰部分相关性较强的区域。通过选择Top-k最重要的注意力分数,能够有效去除雨滴的影响,恢复更清晰的图像。
- 图像分割:图像分割任务中,Top-k稀疏注意力机制可以帮助模型更有效地识别和分离图像中的不同区域,尤其是在处理复杂背景时。在标准的自注意力机制中,所有区域都会被纳入计算,这可能会导致背景噪声对分割结果的干扰。通过Top-k选择机制,网络可以只关注那些重要的区域或边缘,提高分割精度。
对于很多需要做深层网络的同学,比如说两层U-Net或是Siamese结构的同学,可以直接在自己的注意力部分添加Top-k选择信息部分,形成稀疏注意力,这样子可以提升你的模型的运行效率,同时加速训练。还有一部分同学对于模型的训练时间以及测试时间有需求的,也可以直接在注意力部分加入Top-k选择信息部分,帮助涨点。
2.实践展示:


加入增强网络中,对于复杂的水下图像增强,主观效果明显提升,同时平均SSIM能达到0.92,PSNR能达到30+


加入去雨网络中,对于主观效果明显提升,同时平均SSIM能达到0.94,PSNR能达到32+
大家可以尝试将这个TOPK稀疏注意力加入到自己的模型中做尝试,对于视觉图像处理方面,或许对你的模型会有很大的提升哦。下面将代码分享给大家。最后,需要论文或是代码模型辅导的可以直接在主页联系我哦!
class Attention(nn.Module):
def __init__(self, dim, num_heads, bias):
super(Attention, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.qkv = nn.Conv2d(dim, dim * 3, kernel_size=1, bias=bias)
self.qkv_dwconv = nn.Conv2d(dim * 3, dim * 3, kernel_size=3, stride=1, padding=1, groups=dim * 3, bias=bias)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
self.attn_drop = nn.Dropout(0.)
self.attn1 = torch.nn.Parameter(torch.tensor([0.2]), requires_grad=True)
self.attn2 = torch.nn.Parameter(torch.tensor([0.2]), requires_grad=True)
self.attn3 = torch.nn.Parameter(torch.tensor([0.2]), requires_grad=True)
self.attn4 = torch.nn.Parameter(torch.tensor([0.2]), requires_grad=True)
def forward(self, x):
b, c, h, w = x.shape
qkv = self.qkv_dwconv(self.qkv(x))
q, k, v = qkv.chunk(3, dim=1)
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
_, _, C, _ = q.shape
mask1 = torch.zeros(b, self.num_heads, C, C, device=x.device, requires_grad=False)
mask2 = torch.zeros(b, self.num_heads, C, C, device=x.device, requires_grad=False)
mask3 = torch.zeros(b, self.num_heads, C, C, device=x.device, requires_grad=False)
mask4 = torch.zeros(b, self.num_heads, C, C, device=x.device, requires_grad=False)
attn = (q @ k.transpose(-2, -1)) * self.temperature
index = torch.topk(attn, k=int(C/2), dim=-1, largest=True)[1]
mask1.scatter_(-1, index, 1.)
attn1 = torch.where(mask1 > 0, attn, torch.full_like(attn, float('-inf')))
index = torch.topk(attn, k=int(C*2/3), dim=-1, largest=True)[1]
mask2.scatter_(-1, index, 1.)
attn2 = torch.where(mask2 > 0, attn, torch.full_like(attn, float('-inf')))
index = torch.topk(attn, k=int(C*3/4), dim=-1, largest=True)[1]
mask3.scatter_(-1, index, 1.)
attn3 = torch.where(mask3 > 0, attn, torch.full_like(attn, float('-inf')))
index = torch.topk(attn, k=int(C*4/5), dim=-1, largest=True)[1]
mask4.scatter_(-1, index, 1.)
attn4 = torch.where(mask4 > 0, attn, torch.full_like(attn, float('-inf')))
attn1 = attn1.softmax(dim=-1)
attn2 = attn2.softmax(dim=-1)
attn3 = attn3.softmax(dim=-1)
attn4 = attn4.softmax(dim=-1)
out1 = (attn1 @ v)
out2 = (attn2 @ v)
out3 = (attn3 @ v)
out4 = (attn4 @ v)
out = out1 * self.attn1 + out2 * self.attn2 + out3 * self.attn3 + out4 * self.attn4
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out = self.project_out(out)
return out
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 34
34 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)