几何 vs 代数:大模型在数值推理中的秘密武器
本文提出了代理交易竞技场(Agent Trading Arena),这是一个基于零和游戏设计的平台,旨在模拟复杂的经济系统,并用于评估大语言模型(LLMs)在数值推理任务中的表现。
“LLM Knows Geometry Better than Algebra: Numerical Understanding of LLM-Based Agents in A Trading Arena”
论文地址:https://arxiv.org/pdf/2502.17967v1

摘要
大型语言模型(LLMs)在自然语言处理任务中展现出了卓越的能力,但在面对动态且未曾见过的数值推理任务时仍然存在一定的局限性。当前的评估基准主要侧重于衡量LLMs在预设最优解情况下的表现,然而这并不能完全体现真实世界环境中的复杂性和挑战。为此,本文设计了一种名为“代理交易竞技场(Agent Trading Arena)”的新方法,通过零和博弈的形式模拟复杂的经济体系,在该体系中智能体需对股票组合进行投资决策。
研究发现,在处理纯文本形式的股票数据时,即使是像GPT-4o这样的先进LLM,其代数推理能力也显得较为薄弱,往往更注重局部细节而忽视了整体趋势 。然而,当引入视觉数据,例如散点图或K线图时,LLMs的几何推理能力得到了显著提升。此外,加入反思模块可以进一步增强LLMs对复杂数据的理解与解析能力。
实验结果表明,在使用NASDAQ股票数据集进行验证时,相较于文本数据,LLMs在视觉数据上的推理表现更为出色。这一结果强调了视觉信息对于提高LLMs在经济预测等实际应用场景中的有效性具有重要作用 。
简介
尽管大语言模型(LLMs)在自然语言处理任务中展现了强大的能力,但在数值推理和几何推理方面仍存在改进空间,尤其是在面对复杂的跨学科挑战时。当前的评估基准,例如GSM8K和MATH,主要考察模型在熟悉问题上的表现,这使得模型可能依赖于记忆和模式识别,而未能充分展示其推理能力的广度与深度。因此,需要开发新的评估方法来全面衡量LLMs的能力。
为此,本文提出了“代理交易竞技场”这一新框架,通过模拟动态变化的股票市场环境,测试LLMs的推理能力和适应性,重点在于实时决策的灵活性。研究发现,当LLMs处理文本形式的数值数据时,往往更关注具体的绝对值,而非数据之间的关系,导致表现不够理想。然而,在处理可视化数据(如图表)时,LLMs的表现则更为出色。此外,通过引入反思模块,LLMs在可视化数据上的推理能力得到了进一步提升,不仅增强了决策的准确性,还提升了策略性思考的能力。
该框架具有广泛的应用前景,特别是在金融、医疗以及科学研究等领域,能够帮助解决复杂的实际问题。实验证明,相较于文本数值数据,LLMs在可视化几何数据上的推理能力更强,表明可视化信息对于提升LLMs的推理性能具有重要作用。
01相关工作
LLMs数学基准
数学文字问题(MWPs)的研究已经取得了广泛的进展,并开发了多种基准来评估模型在数学推理和解题方面的能力。早期的数据集,如MAWPS,致力于对问题进行标准化处理,而Math23K则提供了大量的中文算术问题,重点在于结构化方程的求解过程。随后,ASDiv和SVAMP通过增加问题类型的多样性和提供更加丰富的注释,进一步提升了数据集的质量。GSM8K和MATH这两个基准则更加注重多步推理能力以及高级数学概念的理解,极大地拓宽了评估的范围。此外,MathQA-Python强调通过程序化的方式来实现推理,而MGSM数据集则将研究扩展到了多语言环境中,使得模型能够应对不同语言下的数学问题。
然而,尽管有这些进步,当前的模型大多仍然依赖于记忆型的回答策略,这种策略限制了它们在真正意义上进行数学推理的能力。这意味着,即使模型能够在特定类型的问题上表现出色,也可能是因为它们记住了类似的例子及其解答,而非具备了灵活运用数学原理解决新问题的能力。因此,未来的研究需要更多地关注如何提高模型的实际推理水平,使其能够更好地适应各种复杂情况。
LLMs用于强化数学推理
通过使用专门设计的数据集进行训练,大型语言模型(LLMs)在解决数学问题方面的能力得到了显著提升。例如,Galactica、PaLM-2、Minerva 和 LLaMA-2 等模型在预训练阶段利用了涵盖广泛主题的大量数据。而像 MetaMath、MAmmoTH 和 WizardMath 这样的精细调优模型则专注于数学任务,经过特定领域的微调后,能够更有效地应对复杂的高级推理挑战。然而,当前的方法通常依赖于大规模的训练数据,这可能导致模型主要依靠记忆和模式识别,而非真正的推理能力来实现高性能表现。因此,有必要开发替代性的评估范式,以便更加精确地衡量 LLMs 在新情境下应用数学原理的能力。
02代理交易竞技场(Agent Trading Arena)
本文构建了一个被称为“代理交易竞技场”的闭环经济体系,其目标是降低人类先验知识与记忆对系统的影响。这个体系采用零和博弈的形式,用以模拟复杂的现实定量场景。在该环境中,代理能够进行资产投资、收取股息以及承担日常开销,所有交易均通过虚拟货币完成。最终,总回报最高的代理将被判定为胜者。
需要注意的是,这里提到的零和博弈意味着在一个封闭的系统内,一个代理所获得的收益必然对应着其他代理同等量级的损失,整个系统的收益总和保持恒定,通常为零。这样的设计有助于评估代理在模拟真实世界财务挑战中的表现,同时减少人为因素干扰,确保结果主要反映代理自身算法的有效性和适应性。

代理交易竞技场
在代理交易场所中,资产价格完全由买卖系统根据代理人的行为和互动来决定,这一过程确保了结果会随着时间逐步显现。通过引入股息机制,代理人不仅可以通过资本增值获利,还能从其所持有的资产中获得股息收入。特别地,持有成本较低的资产的代理人能够获得更高的股息回报。此外,代理人需要支付与其财富成比例的每日资本成本,这促使他们进行快速交易,从而激发市场的活跃度。
在这个竞技场中,代理人不断地学习与竞争。由于采用了零和游戏的结构,不存在普遍适用的最优策略,因此代理人必须持续适应环境并学习,以发展出灵活多变的战略。值得注意的是,代理人对竞技场内的隐含规则一无所知,他们的唯一目标是最大化自身的虚拟财富。这意味着,代理人必须依靠积累的经验来理解和解读游戏的基本规则。同时,他们还容易受到竞争对手散布的错误信息的影响,因此需要依赖于经验学习来克服这些挑战并最终取得胜利。
这种设计强调了代理人在动态环境中自我调整的重要性,同时也测试了他们在面对不确定性和潜在误导时的学习能力和决策水平。通过这样的设置,可以更好地模拟现实世界的金融市场复杂性,为研究提供了一个有价值的实验平台。
数字数据输入的类型
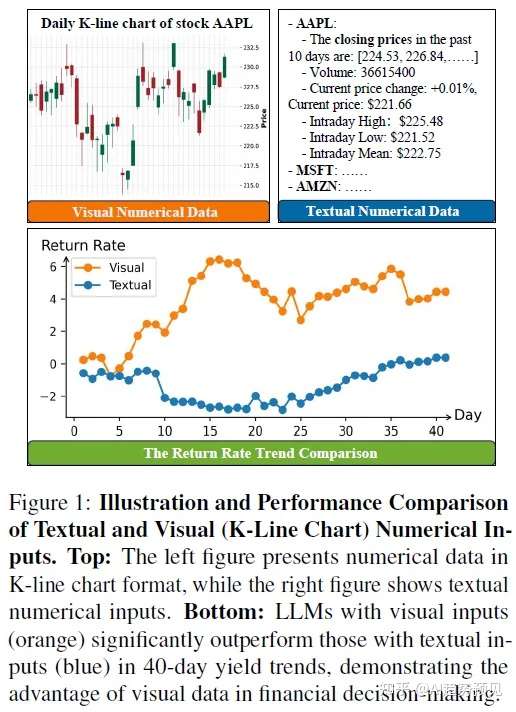
文本形式的数值数据在被LLM处理时存在一定的局限性。这些模型往往过于聚焦于具体的数字,而容易忽略长期的发展趋势和整体模式。此外,LLM对变量间相关性的理解以及百分比变化的把握较为有限,这限制了其评估不同数据点之间联系的能力。同时,LLM通常更侧重于近期的数据,而相对轻视历史数据的价值,这一倾向阻碍了它们识别长期模式及数值间深层次关系的能力。

相比之下,可视化数据(例如散点图、折线图或柱状图)则展现出显著的优势,能够辅助LLM克服文本数据带来的挑战。通过将数据以视觉形式呈现,不仅可以强化LLM对于宏观趋势与整体模式的理解,还能够在保持对局部细节关注的同时,提升其对全局视角的认知水平。因此,结合使用视觉化与文本化的数据表示方式,可以极大地促进LLM在分析复杂数据集时的表现。这种综合方法不仅增强了模型对数据的理解深度,还使其能够更加全面地捕捉到数据中的关键信息,无论是短期波动还是长期演变,都能得到更好的解析。这种方法为LLM提供了更为丰富的上下文信息,有助于提高其决策质量和预测准确性。
反思模块
本文介绍了一种策略蒸馏的方法,该方法通过对描述性文本和视觉数据信息的分析,为大型语言模型(LLMs)提供实时反馈,从而帮助生成新的策略并优化行动方案。此方法使代理能够对结果进行评估、改进策略,并依据反馈不断调整自身行为。具体而言,这一过程始于对当天轨迹记忆及相关策略的回顾与评估,通过特定的评估函数来进行深入剖析。
在战略生成的过程中,采用了对比分析的方式,即将表现优异和表现欠佳的情况进行比较,以此产生双向学习信号,用以指导后续的迭代优化。此外,还设有一个反思模块,该模块会定期激活,整合每日的交易记录,评估现有策略的有效性,同时对成功与失败的经验进行提炼和优化。
对于那些被证明无效的策略,则会被存储进一个专门的策略库中,以便代理日后可以回顾这些策略,从中学习并吸取过往的经验教训,避免重复错误。这种方法不仅促进了策略的持续优化,还增强了代理的学习能力和适应能力,使其能够在复杂多变的环境中更好地做出决策。

03实验
实验设置
在实验过程中,我们至少设置了9个代理和3个库存单元。每个代理都被赋予了相等的初始资金,以此来保证一致的起始条件。为了对我们的研究成果进行更深入的验证,我们选取了纳斯达克股票数据集中的一部分,将其应用于组合投资的场景中。这样做的目的是通过实际的数据分析,确认所提出方法的有效性和可靠性,同时确保实验结果具有更高的可信度和可重复性。

评估指标:
- 总回报率 (TR): TR = (C1 - C0) / C0。
- 胜率 (WR): WR = Nw / Nt。
- 夏普比率 (SR): SR = (Rp - Rf) / σp,Rf设为0。
- 平均日回报 (Mean): 交易期间的日均回报。
- 日回报标准差 (Std): 反映日回报的波动性和风险。
比较实验
实验对LLM代理在实时数据分析与推理方面的能力进行了评估,特别关注了文本和视觉表示形式对决策过程所产生的影响。通过这一实验,旨在深入理解不同信息呈现方式如何塑造LLM代理的判断力与决策质量。

在动态环境下,以可视化形式(例如散点图、K线图等)取代文本输入时,发现采用视觉输入的代理相比仅依赖文本输入的代理表现更佳。而同时结合文本与视觉输入的代理则展现出最优性能,这体现了LLM在几何数据推理上的优势。加入反思模块后,具备反思能力的代理在股票交易任务中的表现显著优于不具备反思功能的代理,尤其是在利用视觉输入的情况下。
基于NASDAQ股票数据集开展的为期两个月的投资模拟实验显示,在没有额外训练的前提下,该模型实现了卓越的投资回报率,超越了其他同类模型。

此外,代理通过文本和视觉输入所获得的夏普比率明显高于仅依靠文本输入的代理,这一结果进一步证实了LLM在处理几何推理任务时的强大能力。
消融分析
实验运用了相对评估的方式,对各类LLM在文本与视觉情境下的表现进行了对比。结果表明,DeepSeek在多种复杂的LLM应用场景中展现了出色的性能,这凸显了其在适应任务复杂性方面的独特长处。

在“代理交易竞技场”开展的消融研究中发现,在引入反思机制的竞争环境下,GPT-4o和Qwen-2.5的表现优于其余模型,这一结论与先前的研究成果相吻合。这些发现进一步验证了特定模型在集成高级功能如反思机制时,能够在竞争性任务中提供更优解的能力。

04总结
本文提出了代理交易竞技场(Agent Trading Arena),这是一个基于零和游戏设计的平台,旨在模拟复杂的经济系统,并用于评估大语言模型(LLMs)在数值推理任务中的表现。研究发现,当处理纯文本形式的数值数据时,尤其是在代数推理方面,LLMs的表现存在明显的不足;然而,当数据以视觉形式呈现,例如通过散点图或K线图展示时,LLMs在几何推理方面的表现则显著提高。这表明,在复杂场景中,视觉表示对于支持数值推理具有明显的优势。
此外,通过整合反思模块,模型的整体性能得到了进一步提升,这不仅增强了LLMs的数据分析能力,还提高了其对数据的理解和解释水平。这些改进对于提升LLMs在动态数值推理任务中的表现至关重要。
为了验证上述结论,本文使用了NASDAQ STOCK数据集进行实验。实验结果证实了LLMs在视觉几何推理任务中的优越性,进一步证明了LLMs在处理视觉数值数据时的表现优于处理文本数值数据。这一研究成果揭示了LLMs在动态数值推理任务中的优势与局限性,为未来在实际跨学科挑战中优化和提升LLMs的表现提供了重要的理论基础和技术指导。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)