如何对机器学习模型进行评估?
分类正确的样本占总样本的比例。
本篇的母文章如下,想要系统了解机器学习的理论基础和行为手册的可以参考:
机器学习基础-CSDN博客在阅读这里之前,需要了解机器学习(神经网络)架构的相关知识,以及数据是如何进行变换从而得到我们期望的结果的:从问题的逻辑上看,我对下面这张图进行详细的阐释:https://blog.csdn.net/weixin_65259109/article/details/145665998
你只能控制可以观察到的东西。因为你的目标是开发出能够成功泛化到新数据的模型,所以能够可靠地衡量模型的泛化能力是至关重要的。
1 用什么数据训练?用什么数据评估?
- 评估模型的重点是将可用的数据划分成训练集、测试集,再把训练集划分成真训练集和验证集。这样做是为了防止信息泄露影响模型评估的科学性。这三个部分的样本应该是互斥的,不能出现重复的部分。
- 模型训练与评估的流程如下:先在真训练集上训练数据,在验证集上得到评估训练的分数;再挑选出具有最优配置的模型,使用这个配置,输入‘真训练集+验证集’将模型再训练一遍从而得到最优模型;最后将这个最优模型放在测试集上进行评估得到评估分数,这个分数用于最终的横向和纵向比较。
下面介绍三种划分训练集(真)、验证集、测试集的方法。数据集均以boston_housing数据集为例。
关于这个数据集的介绍请见:
认识波士顿房价数据集-CSDN博客![]() https://blog.csdn.net/weixin_65259109/article/details/144978152
https://blog.csdn.net/weixin_65259109/article/details/144978152
1.1 简单的留出验证
先将数据集打乱,然后根据比例去划分训练集、验证集和测试集。
这个方法一般是keras的内置方法,不需要自己编写代码。常见的方式是在fit时设置validation_split或者validation_data参数。两者的区别如下:


两者的区别一般是输入的不同,对于前者而言,只需要给出训练集即可,而后者需要你先拆分训练集为真训练集和验证集。而且,后者需要后面选择出最佳的模型后对所有的数据进行重新训练。
使用split:
from tensorflow.keras.datasets import boston_housing
from sklearn.utils import shuffle
import tensorflow.keras as keras
from tensorflow.keras import layers
(train_data,train_targets),(test_data,test_targets) = boston_housing.load_data()#回归问题目标值记为target,分类问题记为label
#数据标准化,包括训练集和测试集,不包括标签(预测值)
#先计算均值和方差
mean = train_data.mean(axis=0)
std = train_data.std(axis=0)
#对训练集、测试集进行标准化,减去均值除以标准差
train_data -= mean
train_data /= std
test_data -= mean
test_data /= std
# 打乱训练数据和目标值
train_data, train_targets = shuffle(train_data, train_targets, random_state=42)
def get_model():
model = keras.Sequential([
layers.Dense(64,activation='relu'),
layers.Dense(64,activation='relu'),
layers.Dense(1)
])
model.compile(
optimizer="rmsprop",
loss="mse",
metrics=['mae']
)
return model
model = get_model()
history_validation_split=model.fit(
x=train_data,
y=train_targets,
batch_size=128,
epochs=50,
validation_split=0.2
)使用data:
from tensorflow.keras.datasets import boston_housing
from sklearn.utils import shuffle
import tensorflow.keras as keras
from tensorflow.keras import layers
(train_data,train_targets),(test_data,test_targets) = boston_housing.load_data()#回归问题目标值记为target,分类问题记为label
#数据标准化,包括训练集和测试集,不包括标签(预测值)
#先计算均值和方差
mean = train_data.mean(axis=0)
std = train_data.std(axis=0)
#对训练集、测试集进行标准化,减去均值除以标准差
train_data -= mean
train_data /= std
test_data -= mean
test_data /= std
# 打乱训练数据和目标值
train_data, train_targets = shuffle(train_data, train_targets, random_state=42)
training_data=train_data[:len(train_data)-num_validation_samples]
training_targets=train_targets[:len(train_data)-num_validation_samples]
validation_data = train_data[len(train_data)-num_validation_samples:]
validation_targets = train_targets[len(train_data)-num_validation_samples:]
def get_model():
model = keras.Sequential([
layers.Dense(64,activation='relu'),
layers.Dense(64,activation='relu'),
layers.Dense(1)
])
model.compile(
optimizer="rmsprop",
loss="mse",
metrics=['mae']
)
return model
history_validation_data=model.fit(
x=training_data,
y=training_targets,
batch_size=128,
epochs=50,
validation_data=(validation_data,validation_targets)
)两者的结果可视化如下:
import matplotlib.pyplot as plt
epochs=range(1,51)
val_mae_split=history_validation_split.history['val_mae']
val_mae_data=history_validation_data.history['val_mae']
plt.plot(epochs,
val_mae_split,
'r-',
label="val_mae_split"
)
plt.plot(epochs,
val_mae_data,
'b-',
label="val_mae_data"
)
plt.title('MAE between val_split & val_data')
plt.xlabel('epochs')
plt.ylabel('MAE')
plt.legend()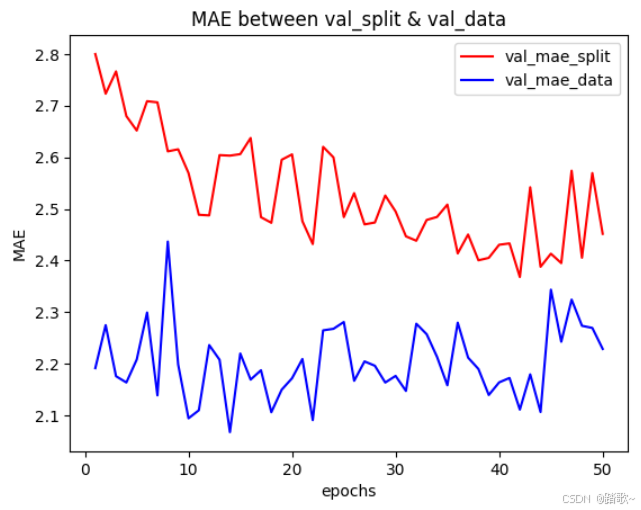
可以看出两种划分方法使得模型均处于拟合的状态。
1.2 K折交叉验证
请参考这篇博文:
什么是K折交叉验证_k折交叉验证 验证集或测试集-CSDN博客![]() https://blog.csdn.net/weixin_65259109/article/details/144983997K折交叉验证其实就是用不同的方法划分训练集和验证集,得到的指标在多个折后取平均得到最终的分数,这个分数是多个折按照相同epoch进行平均从而取得的。
https://blog.csdn.net/weixin_65259109/article/details/144983997K折交叉验证其实就是用不同的方法划分训练集和验证集,得到的指标在多个折后取平均得到最终的分数,这个分数是多个折按照相同epoch进行平均从而取得的。
当数据集很小,在划分一次验证集后用于训练的数据无法体现足够多的全局信息时,使用K折交叉验证的方法。或者你希望更精准地评估模型。
1.3 带有打乱数据的重复K折交叉验证
对于K折交叉验证可以这样理解,先将数据集按照索引升序进行排列,然后按照索引数量将数据集平均分成K段,从这K段中每次选出一段当作验证集进行验证,其他的当作训练集进行训练,得出分数后记录下来。按照上述流程选K次,每一段都有被选为验证集的可能(有且只有一次)。
那么,带有重复的K折交叉验证就是再一次精进了数据的排序顺序。它在考虑如果将数据集划分为K段之后,数据本身索引的顺序就固定下来了。这相较于从数据集中随机抽取作为验证集而言,缺少一定的随机性。为了融合随机抽取和K折交叉验证的优点,带有打乱数据的重复K折验证产生。其核心是:
- 将数据打乱
- 对打乱后的数据进行K折交叉验证
- 将分数记录下来
- 将数据打乱
- 对打乱后的数据进行K折交叉验证
- ……
假设这样的循环重复p次,每个循环都是k折交叉验证。那么,我需要去训练p*k个模型,每个模型记录评估分数。
但是!基本原理是这个原理,实现的话是否使用两个for循环进行实现呢?事实上这样的架构是可以的,但更方便的是sklearn中的RepeatedKFold函数。
其核心思想是设置一个列表用于记录每次K折交叉验证的索引顺序,索引顺序用于K折交叉验证。对于每次重新打乱,只需要重新排列这个索引顺序列表即可。
详细的原理和代码实现请见:
2 设置基准并超越
训练深度学习模型就好像在平行世界中按下火箭发射按钮,你听不到也看不到。你无法观察流形学习的过程,它发生在数千维的空间中,即使投影到三维空间中,你也无法解释它。唯一的反馈信号就是验证指标,就像隐形火箭的高度计。
2.1 验证指标如何设计
机器学习问题可以划分为分类问题和回归问题,我们需要设立合理的观察方式从而对模型应用于具体问题的可用性进行量化。
2.1.1 分类问题
-
准确率 (Accuracy)
-
定义: 分类正确的样本占总样本的比例。
-
公式:
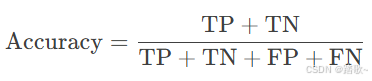
-
TP: 真正例 (True Positive)
-
TN: 真负例 (True Negative)
-
FP: 假正例 (False Positive)
-
FN: 假负例 (False Negative)
-
-
-
精确率 (Precision)
-
定义: 预测为正例的样本中实际为正例的比例。
-
公式:
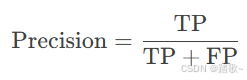
-
-
召回率 (Recall)
-
定义: 实际为正例的样本中被预测为正例的比例。
-
公式:
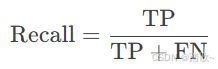
-
-
F1分数 (F1 Score)
-
定义: 精确率和召回率的调和平均数。
-
公式:
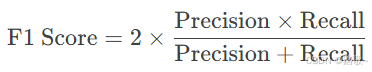
-
-
ROC曲线下面积 (AUC-ROC)
-
定义: ROC曲线下的面积,用于评估分类器的整体性能。
-
计算方法: 通过计算不同阈值下的真正例率 (TPR) 和假正例率 (FPR) 绘制ROC曲线,然后计算曲线下的面积。
-
2.1.2 回归问题
-
均方误差 (Mean Squared Error, MSE)
-
定义: 预测值与实际值之差的平方的平均值。
-
公式:
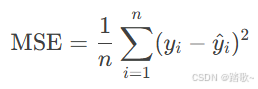
-
-
-
均方根误差 (Root Mean Squared Error, RMSE)
-
公式:
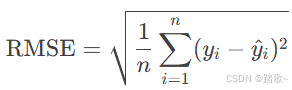
-
定义: MSE的平方根,量纲与实际值相同。
-
-
平均绝对误差 (Mean Absolute Error, MAE)
-
定义: 预测值与实际值之差的绝对值的平均值。
-
公式:
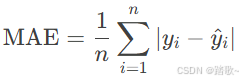
-
-
R² (决定系数)
-
定义: 表示模型解释目标变量方差的比例。
-
公式:
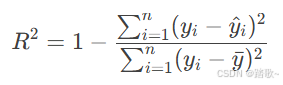
-
-
-
平均绝对百分比误差 (Mean Absolute Percentage Error, MAPE)
-
公式:
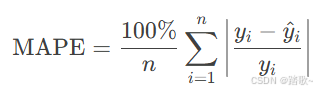
-
定义: 预测误差与实际值之比的平均值。
-
2.2 设置基线模型并超越
上述的验证指标只能衡量单个模型的可用性。假如对于一个模型在具体问题上的分类精度而言,假设这个模型取得了15%的精度,这个模型是好是坏?在构建一个模型时,你总需要设置一个基准去对这个模型做横向比较。如果你的模型始终无法超过一个简单的方案,那么你构建的模型毫无价值。得到这个让人伤心的结果后,你可以通过改变模型来再次尝试,或者直接放弃,因为可能这个问题根本无法使用机器学习的方法来解决,你需要重新思考解决问题的思路。
设置横向的其他模型的对照组可以称之为基线模型的选取。你总是应该去选择一个简单的基准,并努力超越它。如果跨过了这道门槛,你就知道你的方向对了,你的研究是有意义的,模型能够学习输入数据并作出有泛化能力的预测。这个基准既可以是非机器学习模型的性能,也可是简单的机器学习模型的性能。
那么,如何选择进行比较的模型呢?以下仍分为分类问题和回归问题进行讨论,举出常见的作为基准的模型。评价指标分类统一用ACC作为评价,回归问题一律用MSE进行评价。
2.2.1 分类问题——以MNIST数据集为例
2.2.1.0 数据准备
from tensorflow.keras.datasets import mnist
from sklearn.metrics import accuracy_score
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
(X_train,y_train),(X_test,y_test ) = mnist.load_data()
X_train=train_images.reshape((60000,28*28))
X_train=train_images.astype(("float32"))/255
X_test=test_images.reshape((10000,28*28))
X_test=test_images.astype(("float32"))/2552.2.1.1 非机器学习模型——随机分类器
你可以理解为对训练集中的类别进行统计,统计出一共有多少种类别,然后吧测试集的label清空随机填写这几种类别(按照一定的分布),然后计算ACC。
# 1. 随机分类(均匀分布)
labels_pred_random = np.random.randint(0, 10, size=len(y_test))
print("Random Accuracy:", accuracy_score(y_test, labels_pred_random))当然,你也可以选择使用其他分布来进行填充。
2.2.1.2 非机器学习——最频繁项类预测
用训练集中出现频率最高的类别作为所有测试样本的预测值。
# 2. 最频繁类预测
most_frequent = np.argmax(np.bincount(y_train))#得到训练集的最频繁的类别
y_pred_most_frequent = np.full_like(y_test, most_frequent)#创建一个数组形状为y_test,值全填most_frequent
print("Most Frequent Accuracy:", accuracy_score(y_test, y_pred_most_frequent))1.
most_frequent = np.argmax(np.bincount(y_train))
y_train: 这是训练集的标签数组,包含了每个样本的真实类别。
np.bincount(y_train):bincount函数用于计算每个类别的出现次数。假设y_train中的类别是整数(如 0, 1, 2, ...),bincount会返回一个数组,数组的索引表示类别,值表示该类别的出现次数。
例如,如果
y_train = [0, 1, 1, 2, 2, 2],那么np.bincount(y_train)将返回[1, 2, 3],表示类别 0 出现了 1 次,类别 1 出现了 2 次,类别 2 出现了 3 次。
np.argmax(...):argmax函数返回数组中最大值对应的索引。在这里,它返回出现次数最多的类别。
继续上面的例子,
np.argmax([1, 2, 3])将返回2,因为类别 2 的出现次数最多。
most_frequent: 这个变量存储了训练集中出现最频繁的类别。2.
y_pred_most_frequent = np.full_like(y_test, most_frequent)
y_test: 这是测试集的标签数组,包含了每个测试样本的真实类别。
np.full_like(y_test, most_frequent):full_like函数创建一个与y_test形状相同的数组,并将所有元素填充为most_frequent的值。
例如,如果
y_test = [0, 1, 2]且most_frequent = 2,那么y_pred_most_frequent将是[2, 2, 2]。
y_pred_most_frequent: 这个数组表示对测试集中所有样本的预测结果,即所有样本都被预测为训练集中出现最频繁的类别
2.2.1.3 非机器学习——最近邻均值分类
计算每个类别的特征均值,将测试样本分配到距离最近的类别均值。这是一种简单的启发式方法。
简单来说,通过训练集计算每个类别在所有维度上的特征均值,然后在测试集上哪个离得近就分为哪一类。
# 3. 最近邻均值分类
class_means = [X_train[y_train == i].mean(axis=0) for i in range(10)]
distances = np.array([[np.linalg.norm(x - mean) for mean in class_means] for x in X_test])
y_pred_nn = np.argmin(distances, axis=1)
print("Nearest Mean Accuracy:", accuracy_score(y_test, y_pred_nn))1.
class_means = [X_train[y_train == i].mean(axis=0) for i in range(10)]
X_train: 这是训练集的特征矩阵,每一行代表一个样本,每一列代表一个特征。
y_train: 这是训练集的标签数组,表示每个样本的真实类别。
y_train == i: 这是一个布尔索引,用于筛选出属于类别i的所有样本。
X_train[y_train == i]: 通过布尔索引,提取出所有属于类别i的样本。
.mean(axis=0): 对提取出的样本按列(axis=0)计算均值,得到类别i的均值向量。
[ ... for i in range(10)]: 这是一个列表推导式,遍历所有类别(假设类别编号为 0 到 9),计算每个类别的均值向量。
class_means: 这是一个列表,存储了每个类别的均值向量。例如,class_means[0]是类别 0 的均值向量,class_means[1]是类别 1 的均值向量,依此类推。
2.
distances = np.array([[np.linalg.norm(x - mean) for mean in class_means] for x in X_test])
X_test: 这是测试集的特征矩阵,每一行代表一个测试样本。
x: 遍历X_test中的每一个测试样本。
mean: 遍历class_means中的每一个类别的均值向量。
x - mean: 计算测试样本x与类别均值向量mean之间的差值向量。
np.linalg.norm(x - mean): 计算差值向量的欧几里得范数(即欧氏距离),表示测试样本x与类别均值向量mean之间的距离。
[ ... for mean in class_means]: 对于每个测试样本x,计算它与所有类别均值向量之间的距离,得到一个距离列表。
[ ... for x in X_test]: 对于测试集中的所有样本,重复上述过程,得到一个二维列表。
np.array(...): 将二维列表转换为 NumPy 数组。
distances: 这是一个二维数组,形状为(n_test_samples, n_classes),其中n_test_samples是测试样本的数量,n_classes是类别的数量。distances[i, j]表示第i个测试样本与第j个类别均值向量之间的距离。
3.
y_pred_nn = np.argmin(distances, axis=1)
distances: 这是上一步计算得到的距离矩阵。
np.argmin(distances, axis=1): 对每个测试样本(axis=1表示按行操作),找到距离最小的类别索引。
例如,如果
distances[i] = [1.2, 0.8, 3.4],那么np.argmin(distances[i])将返回1,表示第i个测试样本距离类别 1 的均值向量最近。
y_pred_nn: 这是一个一维数组,存储了测试集中每个样本的预测类别。
4.
print("Nearest Mean Accuracy:", accuracy_score(y_test, y_pred_nn))
y_test: 这是测试集的真实标签数组。
y_pred_nn: 这是通过最近邻均值分类得到的预测标签数组。
accuracy_score(y_test, y_pred_nn): 计算预测结果y_pred_nn与真实标签y_test之间的准确率。
print(...): 打印最近邻均值分类的准确率。
2.2.1.4 机器学习——逻辑回归
通过线性模型预测类别的概率,使用 Sigmoid 函数将线性输出映射到 [0, 1] 区间。
# 1. 逻辑回归
logreg = LogisticRegression(max_iter=1000, n_jobs=-1).fit(X_train, y_train)
print("Logistic Regression Accuracy:", accuracy_score(y_test, logreg.predict(X_test)))逻辑回归的原理其实和神经网络差不多,只是少了特定的损失函数的计算和优化器的操作,其也是有循环可以迭代进行参数的调整的(包括权重矩阵和偏置项),并且其也是通过求偏导(梯度)进行模型权重的更新。其详细的内部代码及解读如下:
import numpy as np
class LogisticRegression:
def __init__(self, learning_rate=0.01, max_iter=1000):
self.learning_rate = learning_rate # 学习率
self.max_iter = max_iter # 最大迭代次数
self.weights = None # 模型权重
self.bias = None # 模型偏置
def sigmoid(self, z):
# Sigmoid 函数,将线性输出映射到 [0, 1] 区间
return 1 / (1 + np.exp(-z))
def fit(self, X, y):
n_samples, n_features = X.shape
self.weights = np.zeros(n_features) # 初始化权重为 0
self.bias = 0 # 初始化偏置为 0
# 梯度下降优化
for _ in range(self.max_iter):
# 线性模型输出
linear_output = np.dot(X, self.weights) + self.bias
# 通过 Sigmoid 函数得到概率
y_pred = self.sigmoid(linear_output)
# 计算梯度
dw = (1 / n_samples) * np.dot(X.T, (y_pred - y)) # 权重梯度
db = (1 / n_samples) * np.sum(y_pred - y) # 偏置梯度
# 更新权重和偏置
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
def predict(self, X):
# 计算线性输出
linear_output = np.dot(X, self.weights) + self.bias
# 通过 Sigmoid 函数得到概率
y_pred = self.sigmoid(linear_output)
# 将概率转换为类别(0 或 1)
return np.round(y_pred)内部实现代码的逐步解释
1. 初始化 (
__init__)
learning_rate: 学习率,控制梯度下降的步长。
max_iter: 最大迭代次数,控制训练的轮数。
weights: 模型的权重向量,初始化为 0。
bias: 模型的偏置项,初始化为 0。2. Sigmoid 函数 (
sigmoid)
Sigmoid 函数将线性输出映射到 [0, 1] 区间,表示样本属于正类的概率。
公式:
3. 训练 (
fit)
线性输出: 计算输入特征与权重的点积,加上偏置项:
概率预测: 将线性输出通过 Sigmoid 函数转换为概率:
梯度计算:
权重梯度:
偏置梯度:
更新参数: 使用梯度下降更新权重和偏置:
4. 预测 (
predict)
计算线性输出并通过 Sigmoid 函数得到概率。
将概率四舍五入为 0 或 1,表示预测的类别。
2.2.1.5 机器学习——K近邻分类
根据测试样本与训练样本的距离,选择最近的 K 个样本,通过投票决定测试样本的类别。
其基本上不算一个学习的过程,而是一种分类的策略和方法 。先计算测试样本的特征和所有训练样本的欧氏距离,选出离得最近的前几个,看这几个离得最近的样本的类别出现哪个类别多,就把这个样本归为哪类。
import numpy as np
from collections import Counter
class KNeighborsClassifier:
def __init__(self, n_neighbors=5):
self.n_neighbors = n_neighbors # K 值,默认取 5 个最近邻
self.X_train = None # 训练集特征
self.y_train = None # 训练集标签
def fit(self, X, y):
# 存储训练数据
self.X_train = X
self.y_train = y
def predict(self, X):
y_pred = [self._predict(x) for x in X] # 对每个测试样本进行预测
return np.array(y_pred)
def _predict(self, x):
# 计算测试样本 x 与所有训练样本之间的距离
distances = [np.linalg.norm(x - x_train) for x_train in self.X_train]
# 找到距离最近的 K 个训练样本的索引
k_indices = np.argsort(distances)[:self.n_neighbors]
# 获取这 K 个训练样本的标签
k_labels = [self.y_train[i] for i in k_indices]
# 对标签进行投票,返回出现次数最多的标签
most_common = Counter(k_labels).most_common(1)
return most_common[0][0]1. 初始化 (
__init__)
n_neighbors: K 值,表示选择多少个最近邻样本进行投票。默认值为 5。
X_train: 存储训练集的特征矩阵。
y_train: 存储训练集的标签数组。2. 训练 (
fit)
KNN 是一种惰性学习算法,训练过程只是将训练数据存储起来,不进行任何计算。
3. 预测 (
predict)
predict: 对测试集中的每个样本调用_predict方法进行预测。
_predict:
计算距离: 对于测试样本
x,计算它与所有训练样本之间的欧氏距离。
欧氏距离公式:
找到最近邻: 使用
np.argsort对距离排序,找到距离最近的 K 个训练样本的索引。投票: 获取这 K 个训练样本的标签,使用
Counter统计标签的出现次数,返回出现次数最多的标签作为预测结果。
2.2.2 回归问题——以boston_housing数据集为例
2.2.2.0 数据准备
from tensorflow.keras.datasets import boston_housing
(X_train,y_train),(X_test,y_test ) = boston_housing.load_data()#回归问题目标值记为target,分类问题记为label
#数据标准化,包括训练集和测试集,不包括标签(预测值)
#先计算均值和方差
mean = X_train.mean(axis=0)
std = X_train.std(axis=0)
#对训练集、测试集进行标准化,减去均值除以标准差
X_train -= mean
X_train /= std
X_test -= mean
X_test /= std2.2.2.1 非机器学习模型——随机预测器
对于连续值,随机预测器会在最大值和最小值中间进行默认的均匀采样,然后随机分配作为预测值,随后进行评估指标计算。
# 1. 随机预测(训练集范围内均匀采样)
y_pred_random = np.random.uniform(low=y_train.min(), high=y_train.max(), size=len(y_test))
print("Random Prediction MSE:", mean_squared_error(y_test, y_pred_random))2.2.2.2 非机器学习模型——均值预测
创建一个形状为y_test的矩阵,然后里面全部使用训练集的标签的均值进行填充,随后进行评估指标计算。
# 2. 均值预测
y_pred_mean = np.full_like(y_test, y_train.mean())
print("Mean Prediction MSE:", mean_squared_error(y_test, y_pred_mean))2.2.2.3 非机器学习模型——中位数预测
和均值预测一样,只不过这次填充的是中位数。
# 3. 中位数预测
y_pred_median = np.full_like(y_test, np.median(y_train))
print("Median Prediction MSE:", mean_squared_error(y_test, y_pred_median))2.2.2.4 机器学习模型——线性回归模型
如果要使用线性回归模型,那么必须假设数据的误差均值为零的正态分布。
线性回归模型详解(Linear Regression)-CSDN博客![]() https://blog.csdn.net/iqdutao/article/details/109402570
https://blog.csdn.net/iqdutao/article/details/109402570
from sklearn.linear_model import LinearRegression
# 1. 线性回归
lr = LinearRegression().fit(X_train, y_train)
print("Linear Regression MSE:", mean_squared_error(y_test, lr.predict(X_test)))2.2.2.5 机器学习模型——随机森林模型
from sklearn.ensemble import RandomForestRegressor
# 2. 随机森林
rf = RandomForestRegressor(random_state=42).fit(X_train, y_train)
print("Random Forest MSE:", mean_squared_error(y_test, rf.predict(X_test)))
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)