transformer入门详解
transformer是大模型的基础,由encoder和decoder组成,以翻译任务为例,输入一句话经过transformer生成其翻译内容。实际应用中,都是由多个encoder和多个decoder构成编码器和解码器。
文章目录
前言
transformer是大模型的基础,由encoder和decoder组成,
以翻译任务为例,输入一句话经过transformer生成其翻译内容。
实际应用中,都是由多个encoder和多个decoder构成编码器和解码器
一、Encoder
每个encoder实际上是由两个层构成,第一层是自注意力层,第二层是FFN前馈网络层。编码器的输入会先流经自注意力层,它可以让编码器在对特定词编码时使用输入句子中其他的信息。可以理解成翻译一个词的时候,不仅关注当前词而且还会关注其他词的信息。
二、Decoder
每个解码器有三层,除了self-attention层(mask的)和FFN外,还有Encoder-Decoder Attention层(交叉注意力层),该层用于帮助解码器关注输入句子的相关部分的。
流程
1.一般我们在处理NLP问题时,都要先把它变成在空间上可以计算的向量,即通过embedding词嵌入的形式。而词嵌入只发生在最底层的编码器中,即最下面的编码器接受的是词嵌入向量embedding,其他编码器接收的是下层编码器的输出。
2.每层encoder会将接收到的向量先经过self-attention再经过FNN后输出给下一个编码器。
输入的句子的embedding向量表示和每个词位置的向量表示相加得到可以输入进transformer模型中的矩阵X,输出编码信息矩阵C,C大小为(n*d),n是单词个数(5),d是embedding所转换为的维度(如768,512等等)即提取的特征,C后续会用到Decoder中。
3.注:decoder翻译时,依次会根据当前翻译过的单词1~i翻译下一个单词i+1,如下图所示。在使用过程中,翻译到单词i+1的时候需要通过Mask掩盖i+1后面的单词,不能用它后面的单词信息,只能用它本身及i+1之前的单词信息,因为后面的信息被mask了,由于decoder的mask-selfattention层会防止解码器在生成时“看到”未来信息,只能利用前面出现过的进行计算。
下图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 “”,预测第一个单词 “I”;然后输入翻译开始符 “” 和单词 “I”,预测单词 “have”,以此类推。这是 Transformer 使用时候的大致流程,接下来是里面各个部分的细节。
流程1 embedding
可以将词转换成空间维度中相同维度的向量。与bert的词embedding不完全相同
Transformer 中使用位置 Embedding 保存单词在序列中的相对或绝对位置
通过训练或利用公式生成,之前的bert项目位置编码采用的便是绝对编码,为序列中的每个位置分配一个唯一的编码向量,直接与词向量相加,使模型感知每个词的绝对位置。

二者相加得到transformer的输入矩阵x
为什么transformer的encoder相比bert不需要句子编码
主要原因就是bert用于文本分类,输入常是多个句子,且bert的预训练方式NSP和MLM都需要句子编码的参与,Segment Embedding 的核心作用便是支持 NSP 任务和跨句推理。
而transformer无显式句子编码:编码器通常处理单句输入(如机器翻译的源语言句子),无需区分多句子。它常用于序列到序列任务(如机器翻译),其输入通常为单句或单段文本。
特殊情况下用如下方法代替句子编码:

【cls】本质就是Bert将一整句话压缩为一个向量特征
流程2 注意力机制
红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
1.注意力机制:
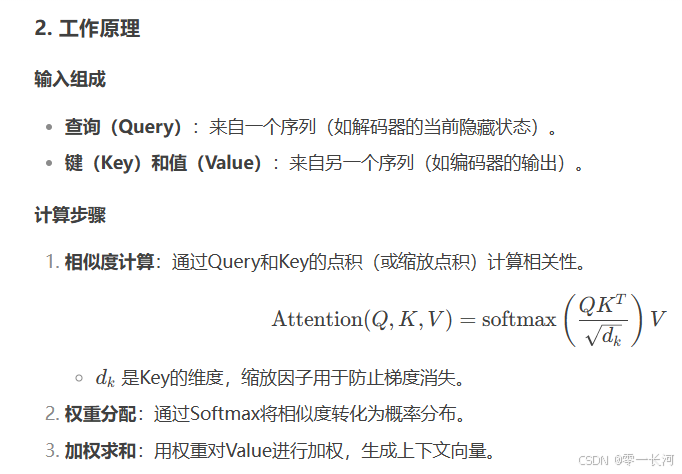
在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的。
Q、K、V 是通过输入X与可学习的权重矩阵Wq,Wk,Wv计算得到的,模型会根据任务目标(如分类、生成等)调整这些权重,从而提取有用的特征。而权重矩阵(如 Q、K、V 的权重矩阵)的初始化是随机的,但它们的值并不是固定的,而是会在训练过程中通过梯度下降等优化算法不断更新,最终学习到适合任务的值。
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词。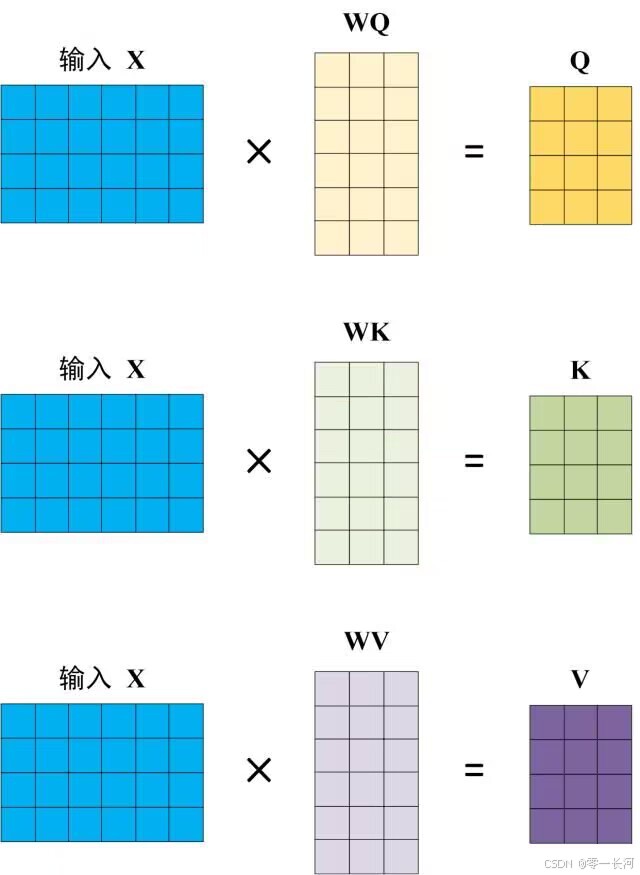
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下:
公式中计算矩阵Q和K每一行向量的内积,为了防止内积过大,因此除以 dk 的平方根。Q乘以K的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。下图为Q乘以 Kt ,1234 表示的是句子中的单词。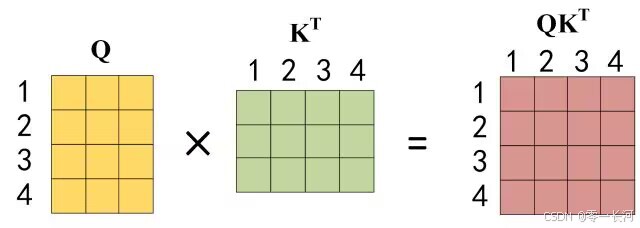
得到QKt 之后,使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1.使得每行分配的注意力之和为1.第一行表示第一个字给其他字以及自己所分配的注意力,第二行…以此类推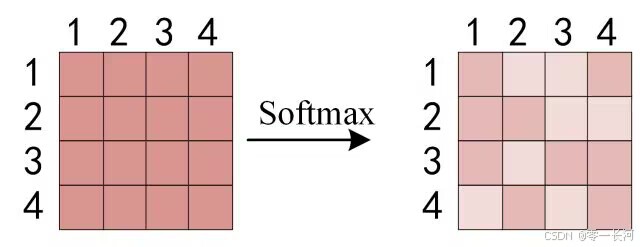
得到 Softmax 矩阵之后可以和V相乘,得到最终的输出Z。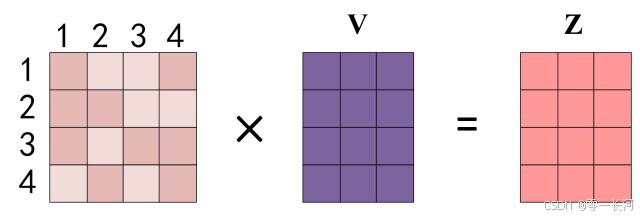
即一个单词i对其他单词分配的注意力与他们的值V相乘后相加,得到该单词的输出Zi.
multi-self attention
Multi-Head Attention 包含多个 Self-Attention 层,首先将输入X分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵Z。下图是 h=8 时候的情况,此时会得到 8 个输出矩阵Z。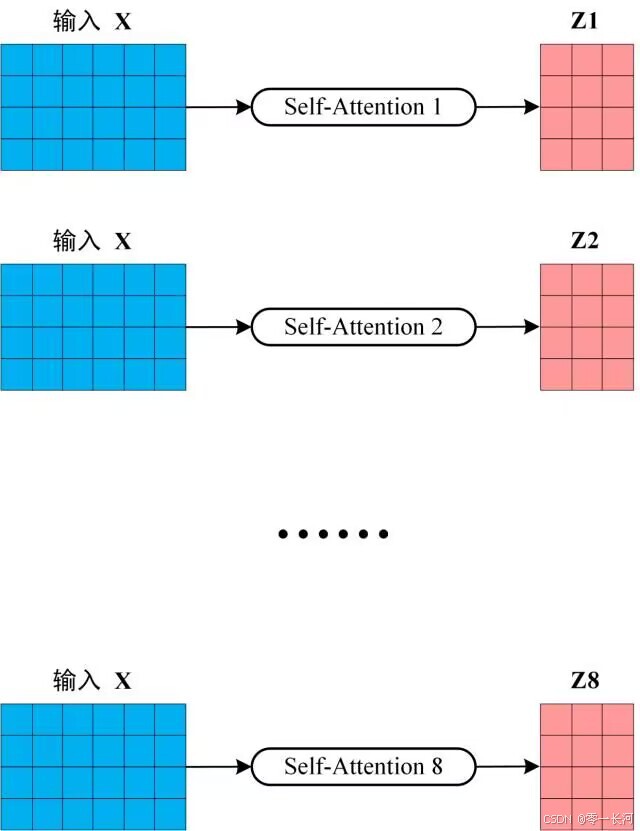
得到 8 个输出矩阵Z1 到 Z8之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z。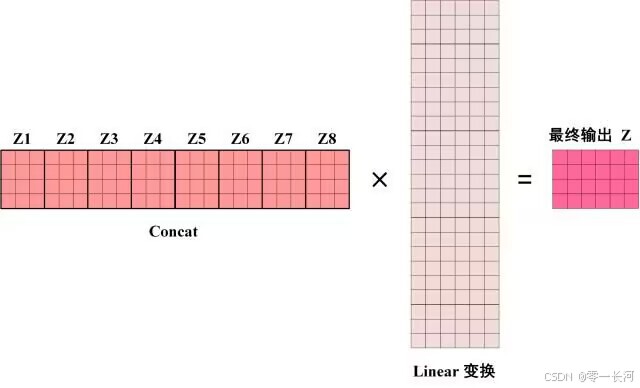
可以看到 Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的。
2.ADD NORM
每个多头注意力机制后面会紧跟一个ADD NORM,如下图,了解残差链接和层归一化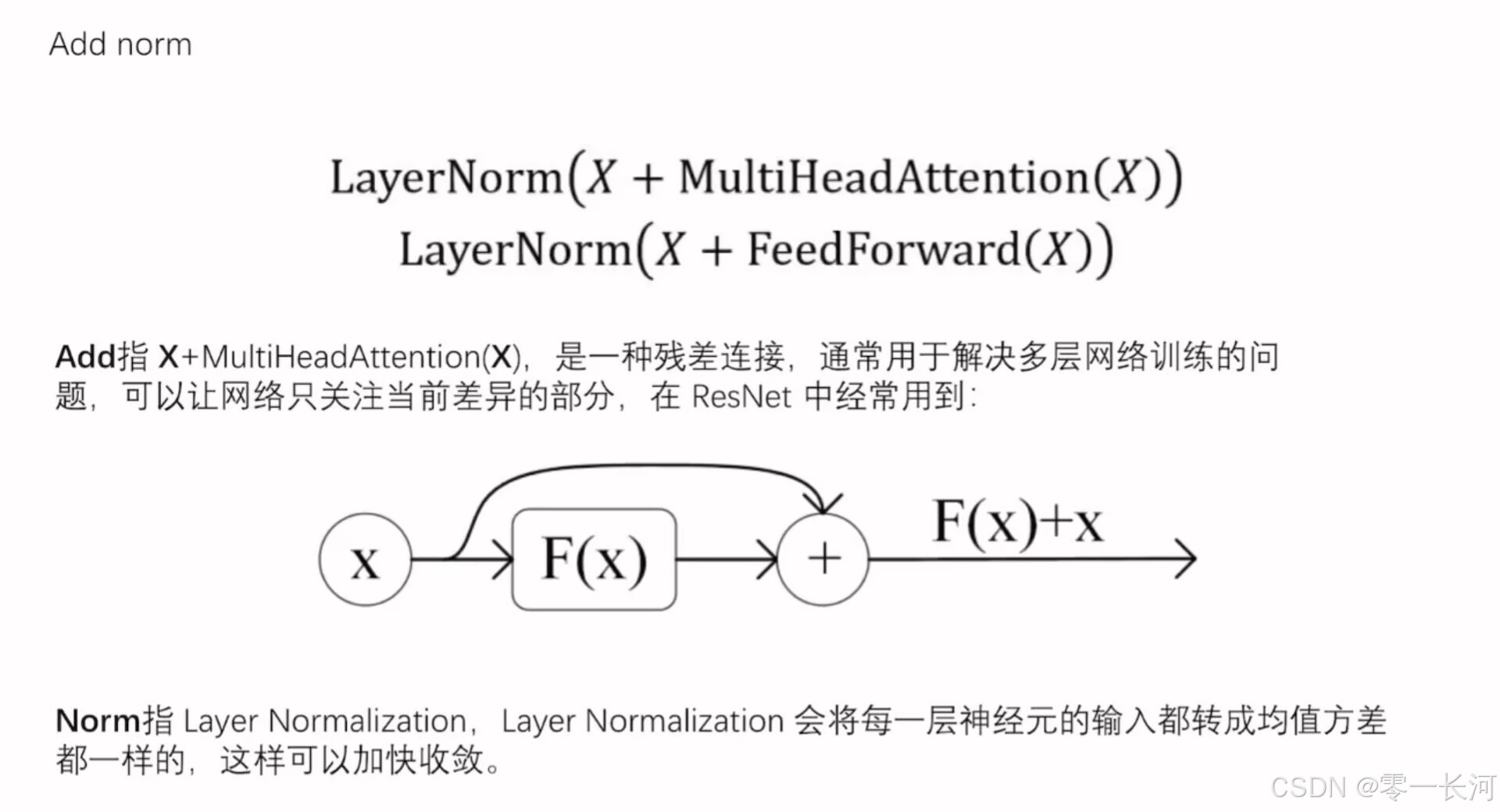
层归一化与批归一化区别:
LN是在同一个样本中不同神经元之间进行归一化,而BN是在同一个batch中不同样本之间的同一位置的神经元之间进行归一化。
BN是对于相同的维度进行归一化,但是咱们NLP中输入的都是词向量,一个300维的词向量,单独去分析它的每一维是没有意义地,在每一维上进行归一化也是适合地,因此这里选用的是LN。
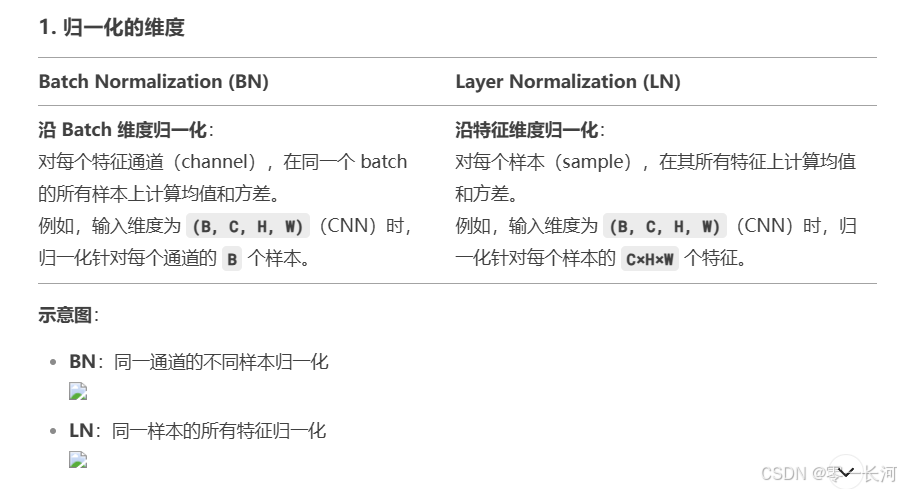

层归一化用于transformer。
3.FNN:前向反馈神经网络层
是一个两层的全连接层,第一层使用激活函数Relu,将输入维度扩展到一个较大的维度,第二层不再使用激活函数,将其压缩回原始维度,乘以权重+偏执后直接输出。
X是输入,FFN最终得到的输出矩阵维度与X一致
流程3 decoder
包含两个 Multi-Head Attention 层。
第一个 Multi-Head Attention 层采用了 Masked 操作。
第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
最后有一个 Softmax 层计算下一个翻译单词的概率。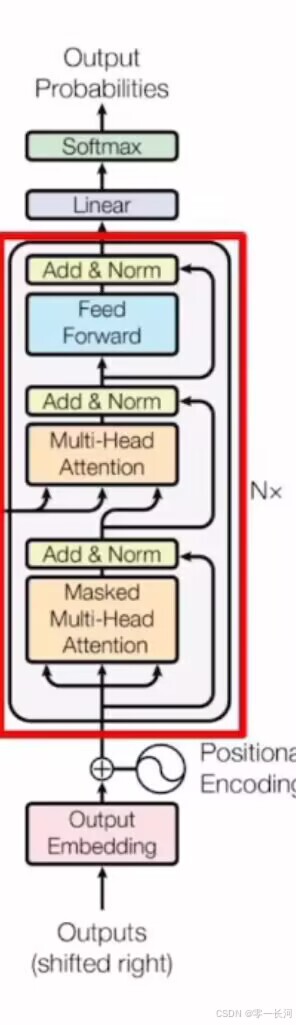
第一个Mluti-head attention
Decoder block 的第一个 Multi-Head Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。下面以 “我有一只猫” 翻译成 “I have a cat” 为例,了解一下 Masked 操作。
在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入 “” 预测出第一个单词为 “I”,然后根据输入 “ I” 预测下一个单词 “have”。
Decoder 可以在训练的过程中使用 Teacher Forcing 并且并行化训练,即将正确的单词序列 ( I have a cat) 和对应输出 (I have a cat ) 传递到 Decoder。那么在预测第 i 个输出时,就要将第 i+1 之后的单词掩盖住,注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的,下面用 0 1 2 3 4 5 分别表示 “ I have a cat ”。
第一步:是 Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 “ I have a cat” (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息,以此类推
因为在decoder训练时,会将一整句target输入,但实际上呢,又不能让模型在训练的过程中看到这一整句话target,不然就会作弊,生成的注意力矩阵会包含这句话的所有信息。我们应该一个字一个字的预测,所以就不能让模型看全这整句话,于是就通过计算出来的QKt矩阵对它用上三角进行mask,使得当前的预测的注意力只能看见自己和之前的词语关系,看不到与后面词语的注意力。然后mask后的注意力得分再与target生成的V矩阵相乘得到输出Z,得到当前每一个词在自己所能看得到的范围内所得到的特征向量
encoder的注意力用于捕捉输入序列的内部关系,Decoder的自注意力用于生成输出序列,同时避免信息泄露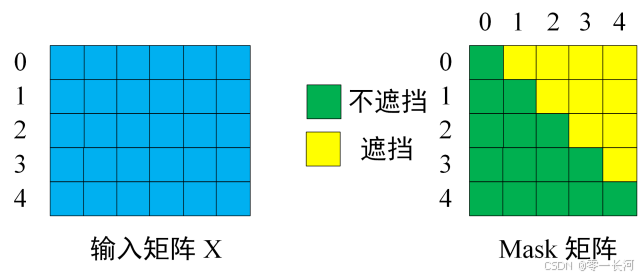 第二步:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵X计算得到Q,K,V矩阵。然后计算Q和 Kt的乘积Qkt 。
第二步:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵X计算得到Q,K,V矩阵。然后计算Q和 Kt的乘积Qkt 。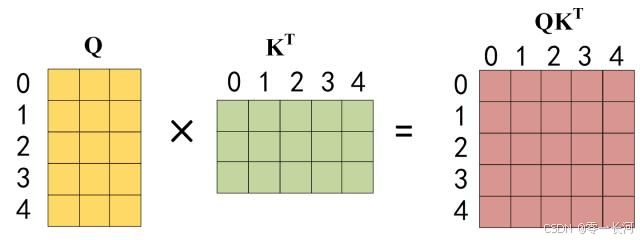
第三步:在得到 QKt之后需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:
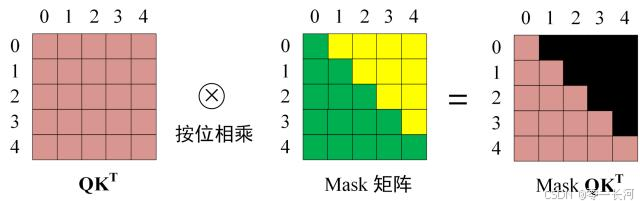

因为单词0是begin开始符。所以mask主要就是指的decoder的第一个注意力层在计算注意力时的结果(QKt)进行mask,目的是在训练时防止看到后面的文本信息。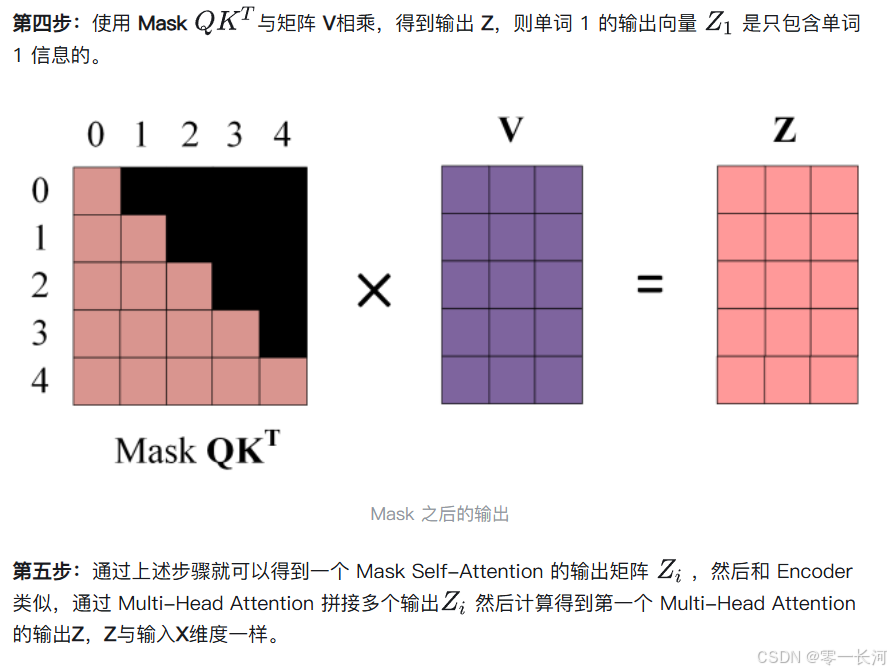
得到输出Z后作为下一个decoder block的输入。
第二个Mluti-head attention
Decoder block 第二个 Multi-Head Attention 变化不大, 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。使用了交叉注意力机制
根据 Encoder 的输出 C计算得到 K, V,和上一个 Decoder block 的输出 Z 传入第二个注意力层,由Z计算出来的 Q (如果是第一个 Decoder block 则使用输入矩阵 X 进行计算)与encoder传入的kv进行计算,来进行预测输出。后续的计算方法与之前描述的一致。
因为Z可以理解为第一层的mask注意力层在防止作弊的前提下,得到的一个要预测的特征向量,将这个向量经过第二层交叉注意力层中生成一个Q向量,用Q向量去和源语句全体经过encoder生成的KV进行计算得到预测输出。而源于句是汉语,不是target(目标英文翻译),可以不被mask,所以整体可被用于辅助预测。
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。翻译对象可以看到所有源语句来辅助进行预测输出。
也就是encoder的KV向量辅助帮助decoder进行预测
交叉注意力机制


softmax 预测输出单词
Decoder block 最后的部分是利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出 Z,因为 Mask 的存在,使得单词 0 的输出 只包含单词 0 的信息,如下: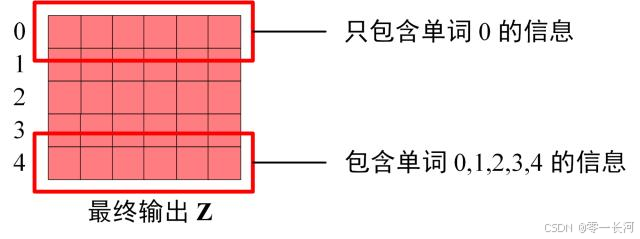
Softmax 根据输出矩阵的每一行预测下一个单词: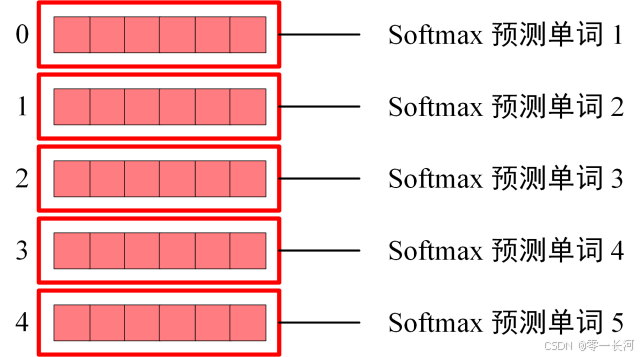
这就是 Decoder block 的定义,与 Encoder 一样,Decoder 是由多个 Decoder block 组合而成。
Transformer 总结
Transformer 与 RNN 不同,可以比较好地并行训练。
Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。
一个生成翻译任务的训练和验证流程
将设输入英文句子A,目标label为翻译的句子B
一:训练阶段:


因为Q是被MASK后的Z经过交叉注意力层生成。
teach forcing

Teacher Forcing 是一种在训练序列生成模型(如机器翻译、文本生成)时使用的策略,其核心思想是:在训练阶段,Decoder每一步的输入不是模型自己生成的上一步结果,而是直接使用真实的目标序列(标签)作为输入。这种设计大幅提高了训练效率和模型稳定性。

二:验证推理部分



训练与验证的差异

训练时候的输入是右移+真实label又称为【ground truth】。
teach force 与自回归生成的区别
自回归(Autoregressive):模型在生成序列时,每一步的输出仅依赖之前生成的序列。例如,GPT 生成文本时,每个新词基于已生成的上文。
Teacher Forcing:一种训练策略,在训练序列生成模型时,将真实标签(Ground Truth)作为下一步的输入,而非模型自身的预测结果。
两者的关系:自回归是生成方式(推理阶段的行为)。Teacher Forcing 是训练策略(训练阶段的优化手段)。两者均用于训练和优化序列生成模型(如语言模型、机器翻译模型)。
Teacher Forcing 在训练时依赖真实数据,可能导致推理时(自回归生成)的暴露偏差(Exposure Bias)(模型未学会处理自身预测的误差)。
解决方案:引入 计划采样(Scheduled Sampling) 或 课程学习(Curriculum Learning),逐步减少对真实数据的依赖。
之所以采用自回归生成的原因:

翻译实例

可知:训练的时候并不是把上一步预测的结果拿来作为输入,而是用对应的真实标签加入进来充当输入进行预测下一个单词,防止上一步万一预测错误,如应预测weather结果预测为weother,导致后续训练也会预测错。
验证阶段,就没有真实标签作为输入了,而是预测下一个单词的时候,就把上一次预测的结果加入进来作为输入,这就是自回归
计划采样,强化学习可以使得模型的训练效果更好
常见问题回答
- 为什么训练时Decoder输入要右移?
为了构造”根据历史词预测下一个词”的任务。例如,输入就是预测Comment,输入
和Comment预测allez,依此类推。 - 验证时如何避免使用真实标签?
验证时完全依赖模型自回归生成:每一步将当前预测的词添加到输入中,作为下一步的输入。 - Mask机制在验证阶段是否生效?
是的!无论是训练还是验证,Decoder的Masked自注意力始终会遮蔽未来词,确保生成时只能看到历史信息。
综上,在生成任务中无论训练还是验证,encoder都负责提供KV,用于交叉自注意力机制。
而decoder在训练过程中,通过真实标签进行训练,防止因为预测一步错步步错,会导致训练效果很差,即采用teach force。
在测试阶段,decoder则用自回归生成,每一步将当前预测的词添加到输入中,作为下一步的输入。
decoder在训练/验证过程中只提供mask后的Q,用其和encoder提供的KV进行计算预测,结果再经过
softmax后转换为概率,进入词典查表查找输出预测的字。



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 43
43 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)