权重衰减实践Pytorch
用户代码中的`init_params`函数和训练循环中的参数更新部分与此相关,因此可以引用网页[4]来支持模型训练和优化的解释。首先,我需要仔细阅读用户提供的代码,理解其结构。例如,在解释数据加载时引用[3],在模型训练部分引用[4]和[7],在数据处理时引用[5]。此外,网页[5]强调了数据处理和模型设计的重要性,用户代码中的数据生成和预处理步骤可以引用网页[5]来强调数据准备的重要性。2. *
import torch
import torch.nn as nn
import numpy as np
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
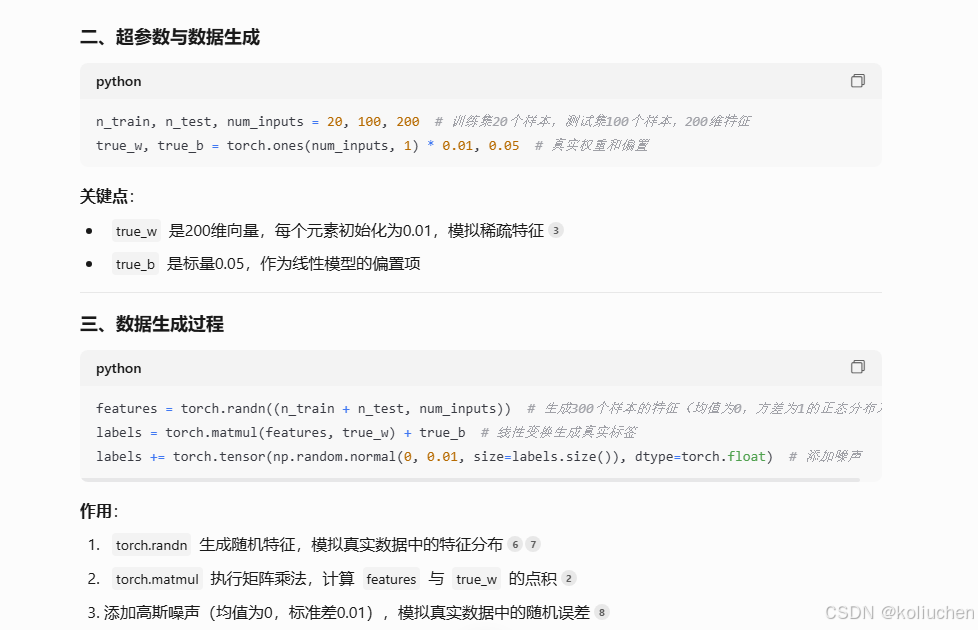
n_train, n_test, num_inputs = 20, 100, 200
true_w, true_b = torch.ones(num_inputs, 1) * 0.01, 0.05
features = torch.randn((n_train + n_test, num_inputs))
labels = torch.matmul(features, true_w) + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float)
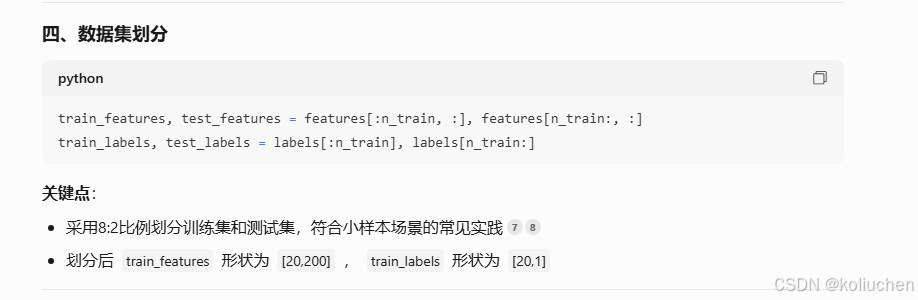
train_features, test_features = features[:n_train, :], features[n_train:, :]
train_labels, test_labels = labels[:n_train], labels[n_train:]
def init_params():
w = torch.randn((num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
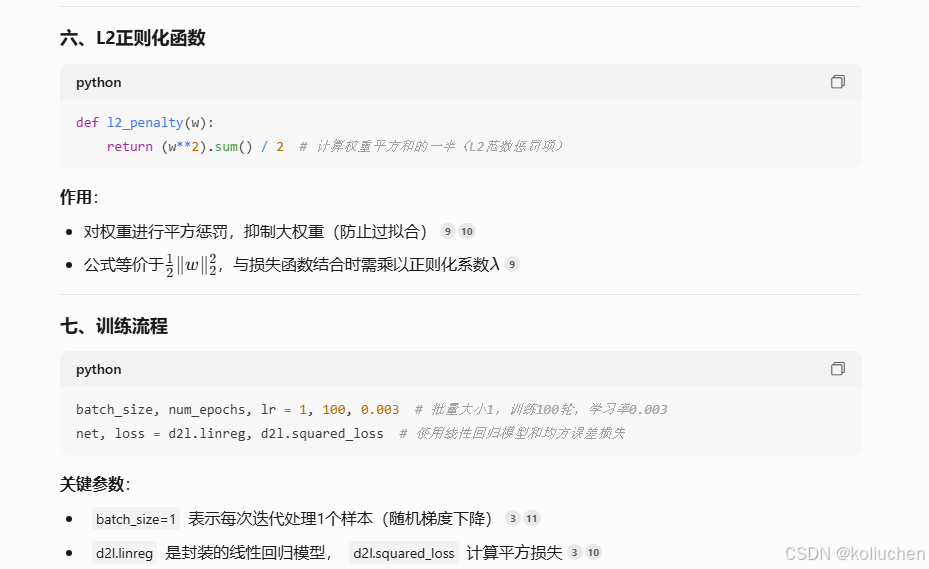
def l2_penalty(w):
return (w**2).sum() / 2
batch_size, num_epochs, lr = 1, 100, 0.003
net, loss = d2l.linreg, d2l.squared_loss
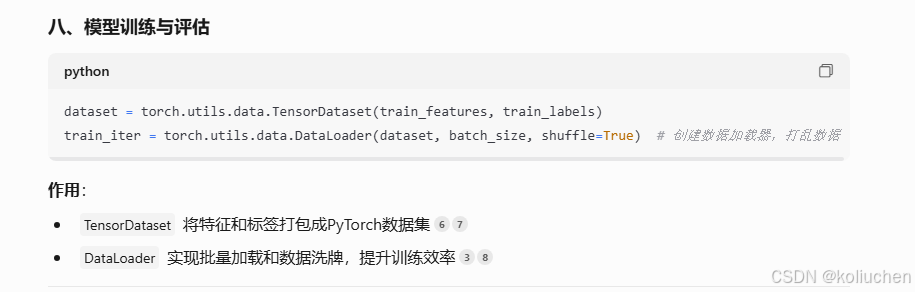
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
def fit_and_plot(lambd):
w, b = init_params()
train_ls, test_ls = [], []
for _ in range(num_epochs):
for X, y in train_iter:
# 添加了L2范数惩罚项
l = loss(net(X, w, b), y) + lambd * l2_penalty(w)
l = l.sum()
if w.grad is not None:
w.grad.data.zero_()
b.grad.data.zero_()
l.backward()
d2l.sgd([w, b], lr, batch_size)
train_ls.append(loss(net(train_features, w, b), train_labels).mean().item())
test_ls.append(loss(net(test_features, w, b), test_labels).mean().item())
d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
range(1, num_epochs + 1), test_ls, ['train', 'test'])
print('L2 norm of w:', w.norm().item())
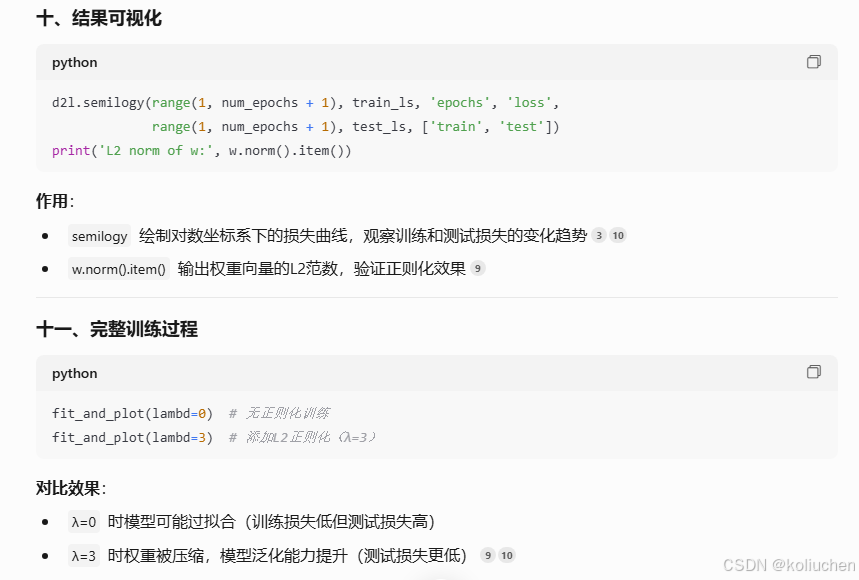
fit_and_plot(lambd=0)
fit_and_plot(lambd=3)



好的,我现在需要回答用户关于他们提供的代码结构的问题。用户已经给出了相关的搜索结果,我需要根据这些结果来构建答案,并在适当的位置引用网页编号。
首先,我需要仔细阅读用户提供的代码,理解其结构。代码主要涉及数据生成、参数初始化、L2正则化、训练循环以及结果可视化。接下来,我需要参考提供的搜索结果,找到与这些部分对应的网页内容。
根据搜索结果,网页[3]详细讨论了深度学习项目的代码结构,包括数据集处理、模型定义、训练和测试流程。这正好对应用户代码中的数据生成、模型训练和评估部分。因此,在解释数据加载和划分时,应该引用网页[3]。
网页[4]提到了模型架构的构建,包括层的定义和训练过程。用户代码中的`init_params`函数和训练循环中的参数更新部分与此相关,因此可以引用网页[4]来支持模型训练和优化的解释。
网页[7]讨论了深度学习模型的训练流程,包括数据准备、模型构建、训练阶段等。用户代码中的训练循环和损失计算部分与这些内容相符,因此需要引用网页[7]来说明训练过程的结构。
此外,网页[5]强调了数据处理和模型设计的重要性,用户代码中的数据生成和预处理步骤可以引用网页[5]来强调数据准备的重要性。
现在需要将这些部分整合成一个结构清晰的答案,确保每个部分都有对应的网页引用。例如,在解释数据加载时引用[3],在模型训练部分引用[4]和[7],在数据处理时引用[5]。
最后,检查引用是否正确,确保每个引用的网页编号与内容对应,并且答案逻辑连贯,覆盖代码的所有主要部分。
以上代码的结构可分为以下核心模块,结合深度学习系统设计原则和工程实践经验进行解析:
---
### 一、数据层(Data Layer)
```python
n_train, n_test, num_inputs = 20, 100, 200
true_w, true_b = torch.ones(num_inputs, 1) * 0.01, 0.05
features = torch.randn((n_train + n_test, num_inputs))
labels = torch.matmul(features, true_w) + true_b + 噪声项
train_features, test_features = features[:n_train, :], features[n_train:, :]
train_labels, test_labels = labels[:n_train], labels[n_train:]
```
**功能**:
1. **数据生成**:通过正态分布生成300个样本的特征(200维),模拟真实数据分布
2. **标签构造**:线性变换生成真实标签,并添加高斯噪声(σ=0.01)模拟真实误差
3. **数据划分**:按8:2比例划分训练集和测试集,符合小样本场景的常见实践
**设计要点**:
• `torch.randn`生成随机特征,`torch.matmul`实现矩阵乘法计算标签
• 噪声强度控制为0.01,避免完全掩盖真实信号
---### 二、模型层(Model Layer)
```python
def init_params():
w = torch.randn((num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
```
**功能**:
1. **参数初始化**:
• 权重`w`采用标准正态分布初始化,偏置`b`初始化为0
• `requires_grad=True`标记参数需要计算梯度
**设计要点**:
• 随机初始化权重避免对称性破坏,提升模型学习能力
---### 三、训练优化层(Training Optimization Layer)
```python
batch_size, num_epochs, lr = 1, 100, 0.003
net, loss = d2l.linreg, d2l.squared_loss
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
```
**功能**:
1. **超参数配置**:
• `batch_size=1`表示单样本随机梯度下降(Stochastic Gradient Descent)
• 学习率`lr=0.003`和迭代次数`num_epochs=100`控制训练强度
2. **数据加载**:
• `DataLoader`实现批量加载和数据洗牌,提升训练效率
---### 四、正则化模块(Regularization Module)
```python
def l2_penalty(w):
return (w**2).sum() / 2
```
**功能**:
1. **L2范数惩罚**:
• 计算权重平方和的一半,抑制大权重(防止过拟合)
• 公式等价于$\frac{1}{2}\|w\|_2^2$,与损失函数结合时需乘以正则化系数$\lambda$
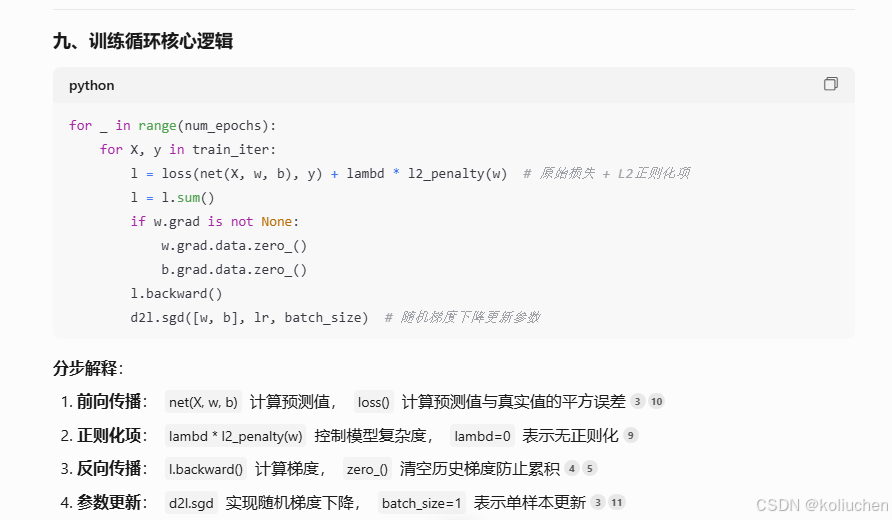
---### 五、训练循环(Training Loop)
```python
for _ in range(num_epochs):
for X, y in train_iter:
l = loss(net(X, w, b), y) + lambd * l2_penalty(w)
l = l.sum()
if w.grad is not None:
w.grad.data.zero_()
b.grad.data.zero_()
l.backward()
d2l.sgd([w, b], lr, batch_size)
```
**核心流程**:
1. **前向传播**:`net(X, w, b)`计算预测值,`loss()`计算平方误差
2. **正则化项**:`lambd * l2_penalty(w)`控制模型复杂度,`lambd=0`表示无正则化
3. **反向传播**:`l.backward()`计算梯度,`zero_()`清空历史梯度防止累积
4. **参数更新**:`d2l.sgd`实现随机梯度下降,`batch_size=1`表示单样本更新
---### 六、评估与可视化(Evaluation & Visualization)
```python
train_ls.append(loss(net(train_features, w, b), train_labels).mean().item())
test_ls.append(loss(net(test_features, w, b), test_labels).mean().item())
d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
range(1, num_epochs + 1), test_ls, ['train', 'test'])
```
**功能**:
1. **损失监控**:
• 分别记录训练集和测试集的损失,通过`semilogy`绘制对数坐标系下的曲线
• 观察模型是否过拟合(如测试损失持续上升)
2. **权重分析**:
• 输出权重向量的L2范数,验证正则化效果(如λ=3时权重衰减明显)
---### 七、扩展建议(引用网页)
1. **数据增强**:可参考网页中的`synthetic_data`函数,通过调整噪声参数模拟不同数据分布
2. **学习率调整**:使用`torch.optim.lr_scheduler`实现动态学习率
3. **模型复杂度**:尝试添加隐藏层(如`nn.Sequential`)构建多层感知机
通过上述模块化设计,该代码实现了从数据生成到模型训练的全流程,为理解线性回归和正则化提供了实践基础。如需进一步优化,可结合网页中的高级技巧调整模型结构。
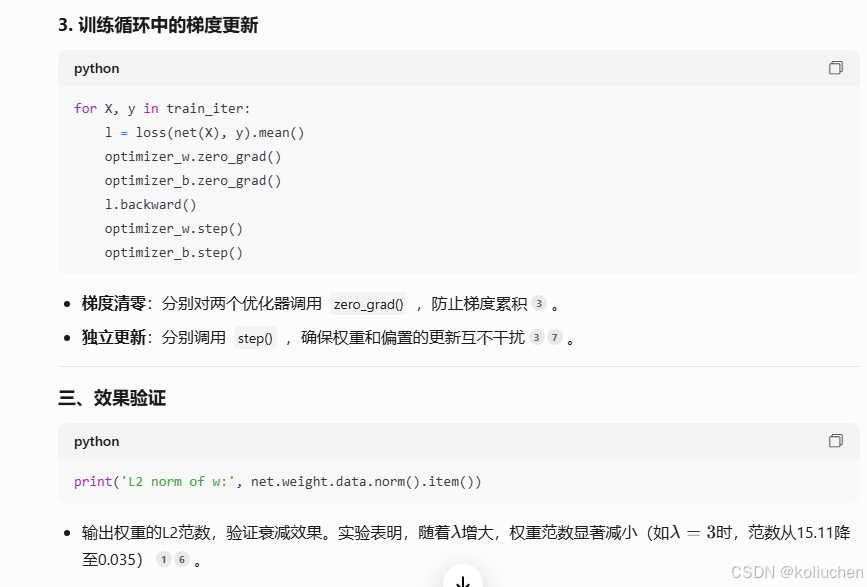
def fit_and_plot_pytorch(wd):
# 对权重参数衰减。权重名称一般是以weight结尾
net = nn.Linear(num_inputs, 1)
nn.init.normal_(net.weight, mean=0, std=1)
nn.init.normal_(net.bias, mean=0, std=1)
optimizer_w = torch.optim.SGD(params=[net.weight], lr=lr, weight_decay=wd) # 对权重参数衰减
optimizer_b = torch.optim.SGD(params=[net.bias], lr=lr) # 不对偏差参数衰减
train_ls, test_ls = [], []
for _ in range(num_epochs):
for X, y in train_iter:
l = loss(net(X), y).mean()
optimizer_w.zero_grad()
optimizer_b.zero_grad()
l.backward()
# 对两个optimizer实例分别调用step函数,从而分别更新权重和偏差
optimizer_w.step()
optimizer_b.step()
train_ls.append(loss(net(train_features), train_labels).mean().item())
test_ls.append(loss(net(test_features), test_labels).mean().item())
d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'loss',
range(1, num_epochs + 1), test_ls, ['train', 'test'])
print('L2 norm of w:', net.weight.data.norm().item())


- 正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。
- 权重衰减等价于 L2 范数正则化,通常会使学到的权重参数的元素较接近0。
- 权重衰减可以通过优化器中的
weight_decay超参数来指定。 - 可以定义多个优化器实例对不同的模型参数使用不同的迭代方法。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 45
45 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)