注意力机制详解(Attention详解)
注意力机制;Attention
注意力机制与人眼类似,例如我们在火车站看车次信息,我们只关注大屏的车次信息,而忽略大屏外其他内容,从而导致钱包被偷。。。
注意力机制只关注重点信息,忽略不重要的信息,关注最核心的内容。
主要就是这个公式,下面我来详细解释:
看不懂没关系,先看下面的示例也可以
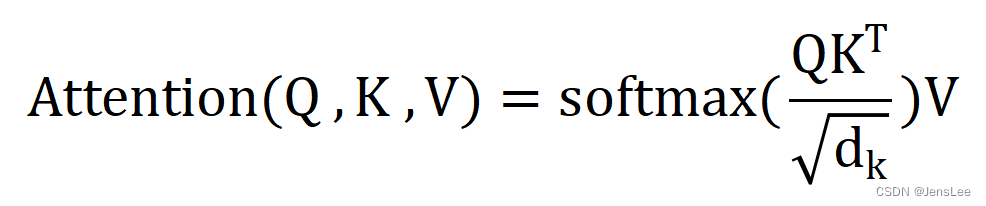
Q是查询语句,K是关键字,V是值。其中dk等于词向量的长度。
Q、K、V概念来源于检索系统,其中Q为Query、K为Key、V为Value。可以简单理解为Q与K进行相似度匹配,匹配后取得的结果就是V。举个例子我们在某宝上搜索东西,输入的搜索关键词就是Q,商品对应的描述就是K,Q与K匹配成功后搜索出来的商品就是V。
一、示例
第一步:搜索
淘宝搜索“笔记本”,就会弹出来一堆笔记本的列表。Q就是查询语句,就是“笔记本”,即Q=“笔记本”。
计算机不认识笔记本的中文,他就知道二进制,我们比如给笔记本赋一个向量Q=“笔记本”=[1,0,1,0,0,0,0,1];这个向量是我们随便拟定的,数值什么无所谓。
第二步:计算相似性
淘宝后台拿到这个查询Q,并用这个查询Q去和后台的所有的商品的关键字K一一的来对比,找到物品和我们查询的相似性(或者说物品对应的相似性的权重),相似性越高,越可能推送给我们。
第三步:得到价值
并且这个时候还要考虑物品的价值V,这个V不是指物品值几块钱,而是这个物品在算法中的价值。如果商家给了淘宝广告钱,或者商品物美价廉,评论好,点赞高,购买多,等等,那么算法就越有可能把物品排在前面推送给我们。
第四部:计算带权重的价值
查询语句Q乘以K,得到了相似性数值。我们拿刚刚的相似性,乘上物品在算法中的价值V,计算结果就是每件物品的最后的带相似性权重的价值,淘宝最后的算法就是返回这个带权重的价值,也就是把排好序的这些商品推送给我们。
这就是一个最典型的注意力的过程。它推送在最前面给我们的商品,肯定就是它最希望获得我们注意力的商品。当然,淘宝内部的算法肯定不是这样的,但是他们的本质都是一样的,都是基于注意力,并且我们看到的现象也都是一样的。
二、网络架构:
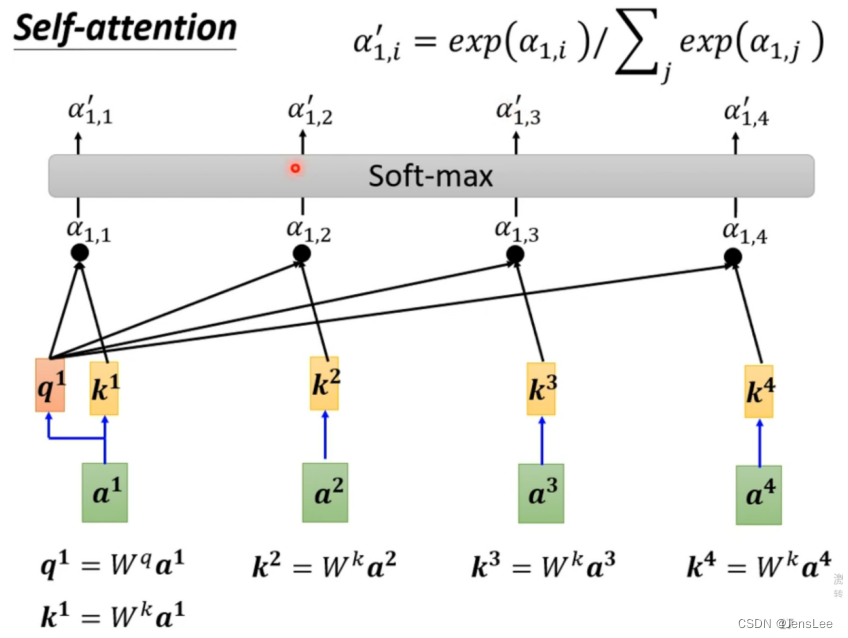
向量a1与向量a2,就是下面绿色的两个方块,分别乘以Wq与Wk(这两个矩阵是随机生成的,里面的参数会随着训练而改变),变成了q与k。q与k就包含了a1与a2本来的信息,他们点乘后变成a.
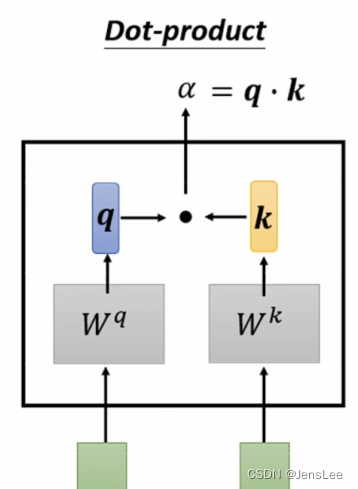
a就是注意力分数
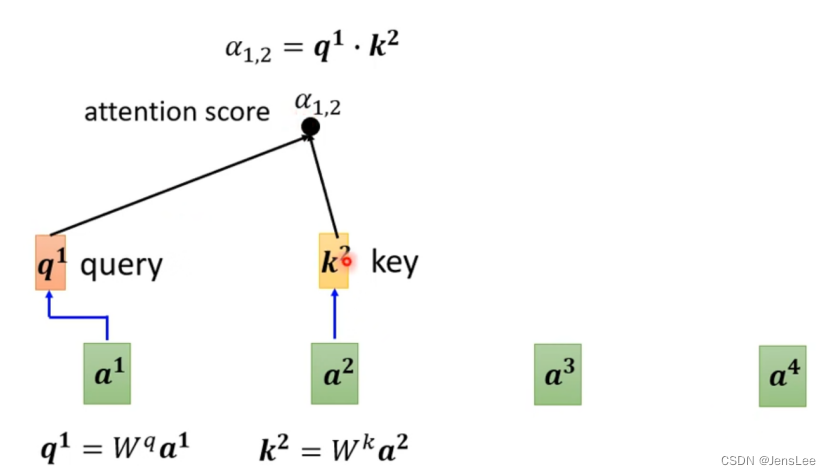
然后a1分别与a2,a3,a4分别相乘。同时a1还要跟自己做关联性计算。即q1要与k2,k3,k4分别进行点乘,获得a12, a13, a14。
三、具体数值计算
我们现在搜索“Note Book”,首先按照“Note”、“Book”来搜索。他们在论文中用64位来表示,我们这里简化一下,简化成三位:
首先生成词向量,不知道什么是词向量的可以百度一下,搞懂词向量概念再继续看。
Note 词向量为 [1,0,0,1];这个数值我随便起的,你们可以随意定长度与内部数值。
Book 词向量为 [0,1,1,1]
然后随机生成三个不同的权重矩阵;他们的大小是4*3;里边的数我随机编的。
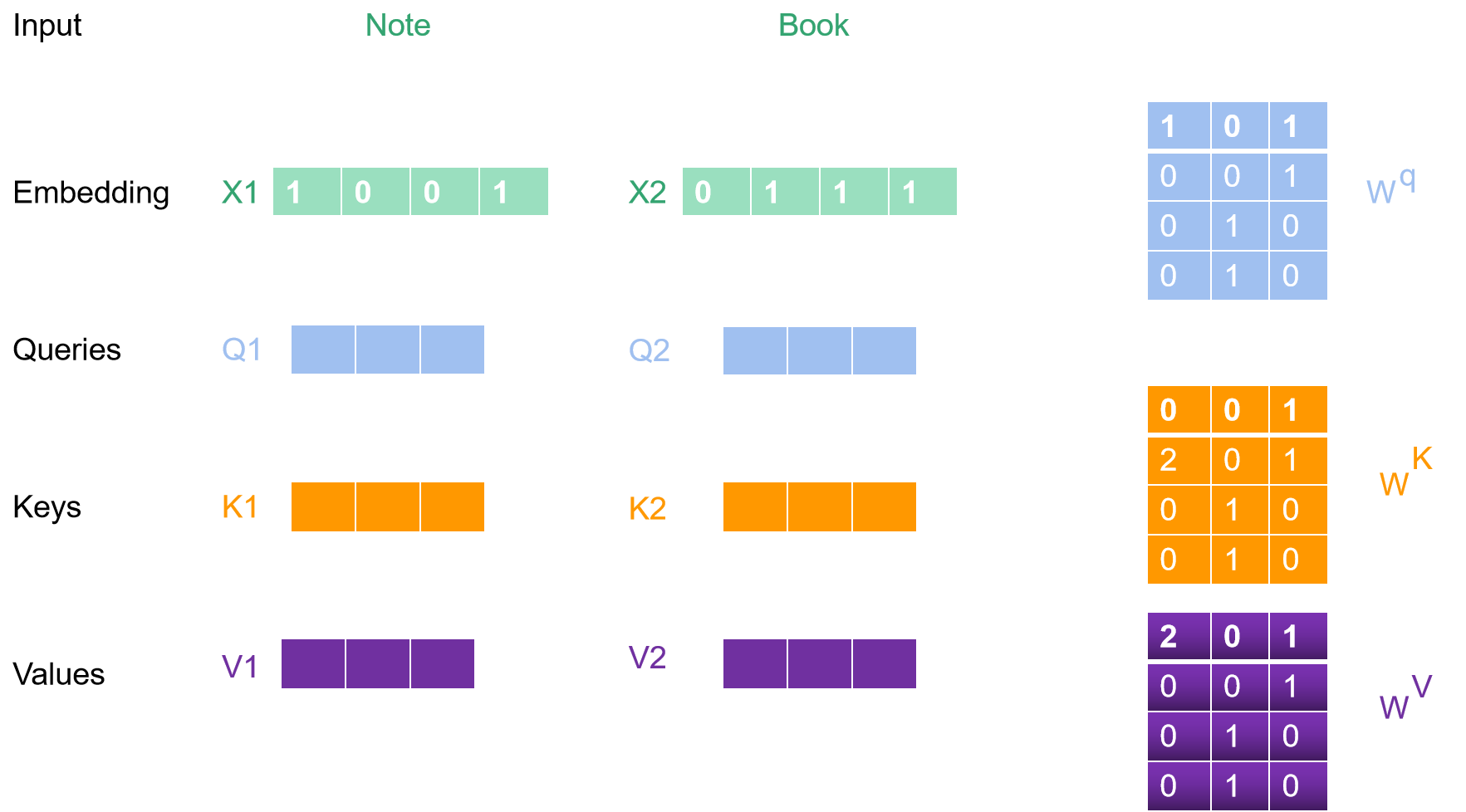
初始化 X1, X2 , 还有 ;
Q,K,V初始化公式如下所示,很简单,看一看就能明白:
计算完毕后的如下图所示:
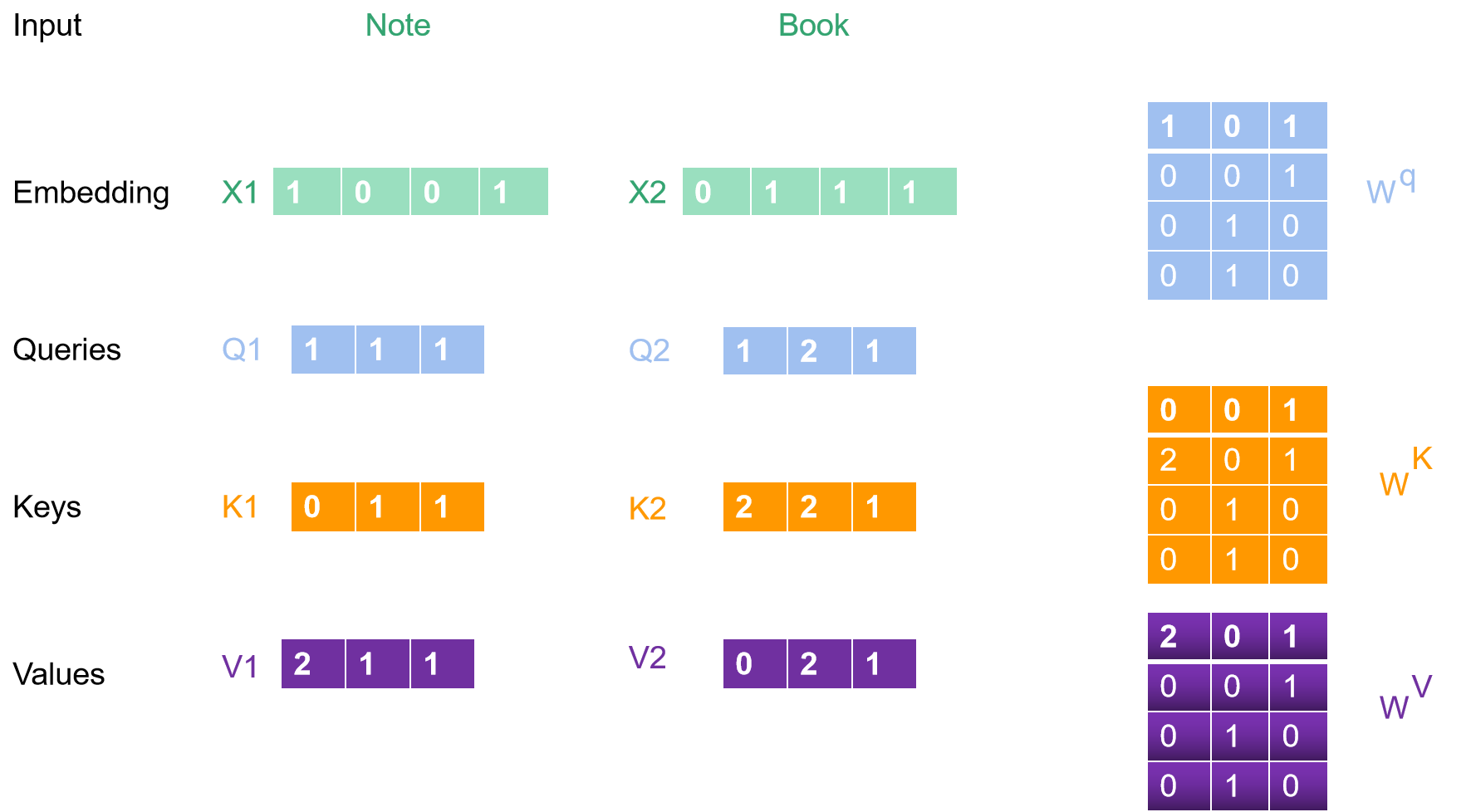
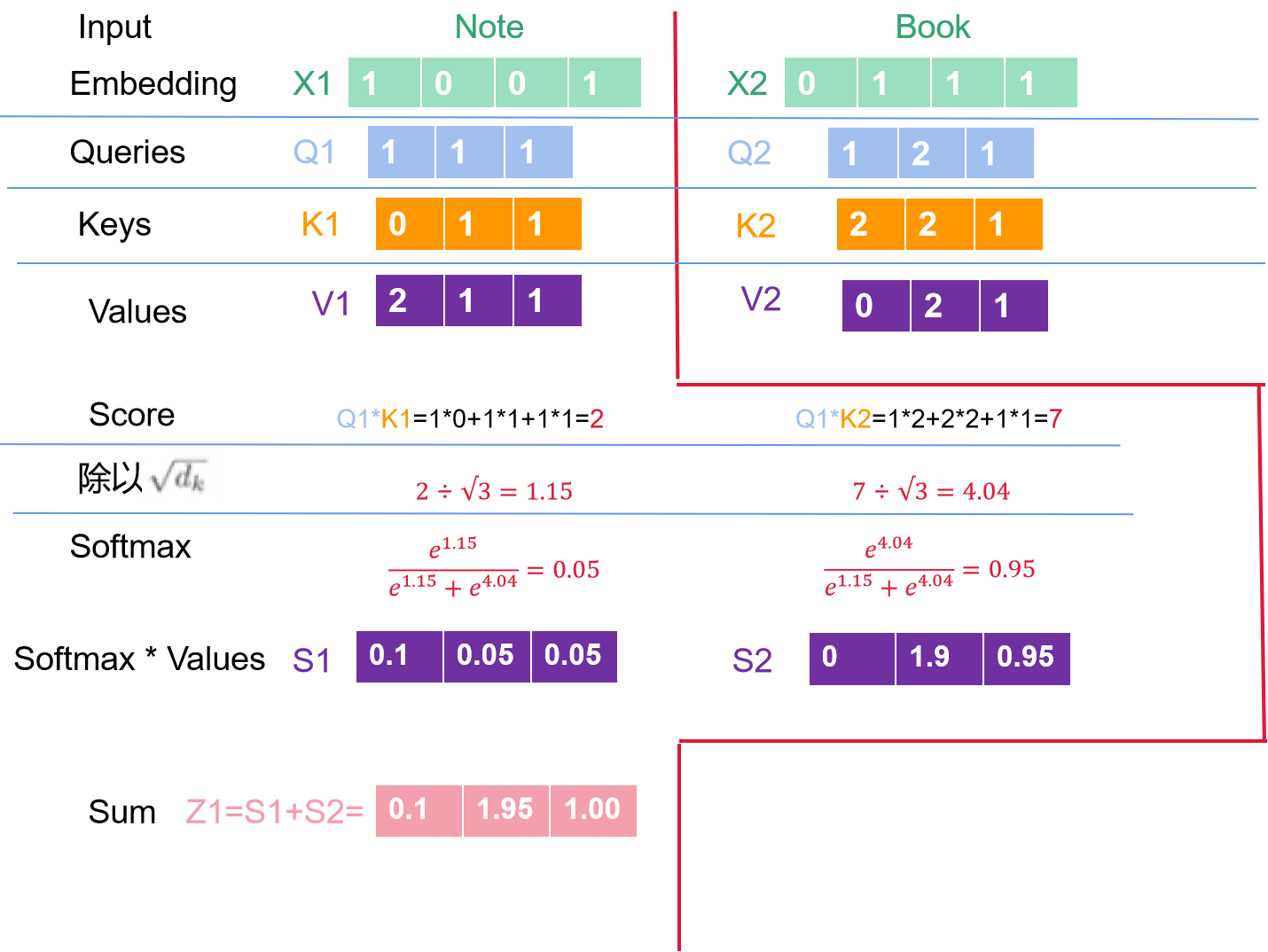
我们获取到了各个完整的值了,下一步我们要将Q1跟不同的K相乘,得到score,即score=Q*K。
各个计算步骤如下图所示:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)