深度学习实验:中文预料的情感分析
(1)实验基本要求:中文语料情感分析,需要完成语料预处理(分词、索引化,分词推荐采用jieba分词,注意分词前去掉标点符号和特殊字符)。(2)自由探索(非基本要求):针对课堂IMDB情感分析演示和中文语料情感分析的各种提高效率的改进,比如RNN→LSTM→BiLSTM→BERT→GPT分别作为序列处理方法的性能比较期望达到的结果:label为0表示结果消极(neg)反之为积极(pos)其中数据库的
目录
Bert的测试准确率(使用官方的训练模型准确率可以到100%):
(1)实验基本要求:中文语料情感分析,需要完成语料预处理(分词、索引化,分词推荐采用jieba分
词,注意分词前去掉标点符号和特殊字符)。
(2)自由探索(非基本要求):针对课堂IMDB情感分析演示和中文语料情感分析的各种提高效率的改进,比如RNN→LSTM→BiLSTM→BERT→GPT分别作为序列处理方法的性能比较
数据库地址:icloud.qd.sdu.edu.cn:7777/#/link/34E7E7E43E513ECEBD08B07B943174DA
期望达到的结果:
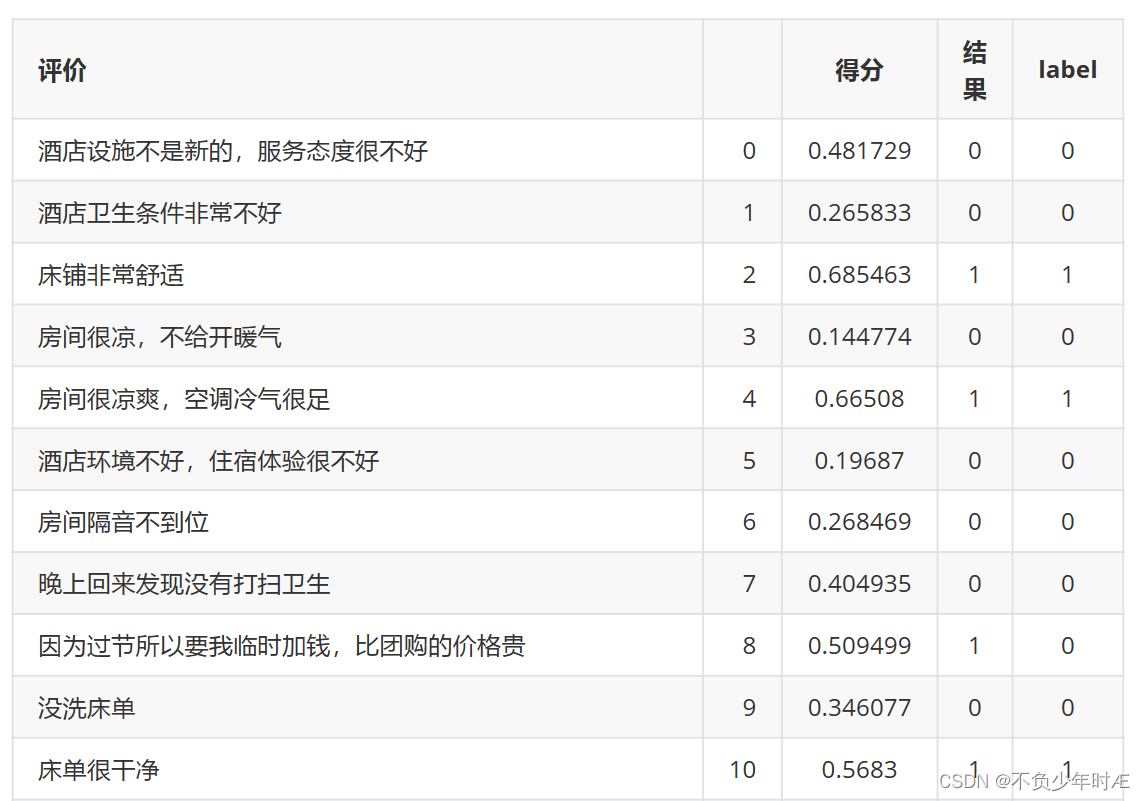
label为0表示结果消极(neg)反之为积极(pos)
其中数据库的文件格式如下,文件名为datanew,文件下分为两个文件neg(消极)和pos(积极)
每个txt文件内容如下:

实验背景介绍完毕,下面就是对实验进行训练了:
一、对数据进行预处理
无论何时,我们做实验的第一步都是要对数据进行预处理,对于一个原始文本而言,文本内有标点符号和各种非常用词,表情等,我们都不需要,而且txt文本肯定是不能直接作为输入进入神经网络的,我们要把他们转换成向量,下面我用一个图表示数据预处理的过程:
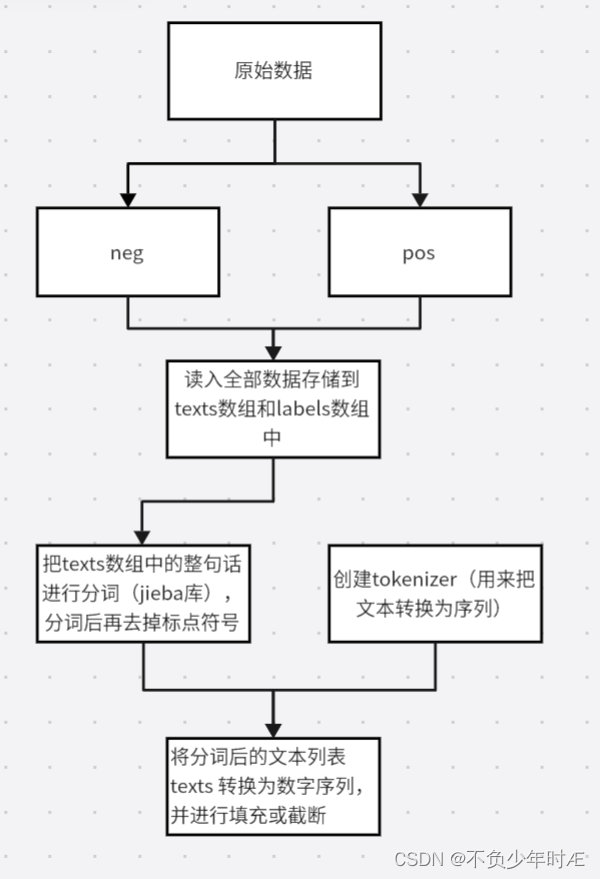
处理过后输出的sequences(文本包括原句和数组化后)如下:
原文本:

去标点符号后并且索引化:

下面是代码详解:
import os
import jieba
import numpy as np
from keras import Sequential
from keras.src.layers import Embedding, LSTM, Dense
from keras.src.legacy.preprocessing.text import Tokenizer
from keras.src.utils import pad_sequences
# 读取文件并分为输入文本和情感标签
def load_data(data_dir):
texts = []
labels = []
for label in ['neg', 'pos']:
label_dir = os.path.join(data_dir, label)
for file in os.listdir(label_dir):
with open(os.path.join(label_dir, file), 'r', encoding='utf-8') as f:
text = f.read().strip()
texts.append(text)
labels.append(0 if label == 'neg' else 1)
return texts, labels
# 对文本进行分词和预处理
def preprocess_text(texts):
processed_texts = []
for text in texts:
# 分词
words = jieba.lcut(text)
# 去除标点符号
words = [word for word in words if word.strip()]
# 可以加入去除停用词等其他预处理步骤
processed_texts.append(" ".join(words))
return processed_texts
# 将文本转换为数字向量
def text_to_sequences(texts, tokenizer, max_length):
sequences = tokenizer.texts_to_sequences(texts)
sequences = pad_sequences(sequences, maxlen=max_length, padding='post', truncating='post')
return sequences
# 数据预处理
def preprocess(data_dir, max_words, max_length):
texts, labels = load_data(data_dir)
texts = preprocess_text(texts)
tokenizer = Tokenizer(num_words=max_words, oov_token='<UNK>')
tokenizer.fit_on_texts(texts)
sequences = text_to_sequences(texts, tokenizer, max_length)
return sequences, np.array(labels), tokenizer二、模型选择和网络搭建
在对数据进行训练前,选择好我们要使用的网络也是至关重要的,不同的网络会对数据产生不同的拟合效果和准确率,下面是我训练的四种网络结构
2.1RNN
RNN这个网络相比其他循环神经网络最大的特点就是简单:因为他是其他神经网络的基石
和他简单的网络结构相对应的是,他训练占用的资源很少,训练快速,结构简单,但是在代码上体现的并不明显
他的训练效果如下:

可以看到最后训练20次的准确率为0.6253

使用测试语句“这家酒店服务特别好!下次我还会来的”测试模型得到该语句为正向的指数为0.554507,这表名这个语句为正向语句的概率为0.554507,但是这句话明显为正向语句,所以这说明这个语句的训练效果并不出彩,这个指数应该非常接近于1才对,所以得出结论,RNN的训练效果非常一般,但并不是没有作用。
下面是代码详解:
#建立 LSTM 模型
def build_RNN_model(max_words, embedding_dim, max_length):
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=max_length))
model.add(SimpleRNN(128, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
return model
#对新文本进行情感分析预测
def predict_sentiment(text, model, tokenizer, max_length):
# 对文本进行预处理和转换
processed_text = preprocess_text([text])
sequences = text_to_sequences(processed_text, tokenizer, max_length)
# 进行情感分析预测
prediction = model.predict(sequences)[0][0]
if prediction >= 0.5:
sentiment = 'positive'
else:
sentiment = 'negative'
return sentiment, prediction
def main():
# 设定参数
data_dir = 'datanew'
max_words = 10000
max_length = 100
# 数据预处理
sequences, labels, tokenizer = preprocess(data_dir, max_words, max_length)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(sequences, labels, test_size=0.2, random_state=42)
# 设定参数
embedding_dim = 100
# 构建 LSTM 模型
model = build_RNN_model(max_words, embedding_dim, max_length)
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 查看模型结构
print(model.summary())
# 训练 RNN 模型
history = model.fit(X_train, y_train, epochs=20, batch_size=64, validation_data=(X_test, y_test))
# 保存模型
model.save('RNN.h5')
# 加载模型
model = load_model('RNN.h5')
print("Model loaded successfully.")
# 加载测试数据
# 评估模型
test_loss, test_accuracy = model.evaluate(X_test, y_test)
print("Test Loss:", test_loss)
print("Test Accuracy:", test_accuracy)
text='这家酒店服务特别好!下次我还会来的'
sentiment, prediction=predict_sentiment(text,model,tokenizer,max_length)
print(sentiment)
print(prediction)
if __name__ == "__main__":
main()2.2LSTM
1.LSTM网络比RNN强的地方在于LSTM拥有(遗忘门、输入门和输出门)帮助网络决定信息的添加或移除,这使得LSTM能够更有效地学习长期依赖性
2.RNN在处理长序列时面临“梯度消失”或“梯度爆炸”的问题,这使得它难以学习和保持长期的依赖关系。但是LSTM通过其门控机制可以较好地解决长期依赖问题。遗忘门帮助网络遗忘不相关的信息,而输入和输出门帮助网络保持有用的长期依赖。
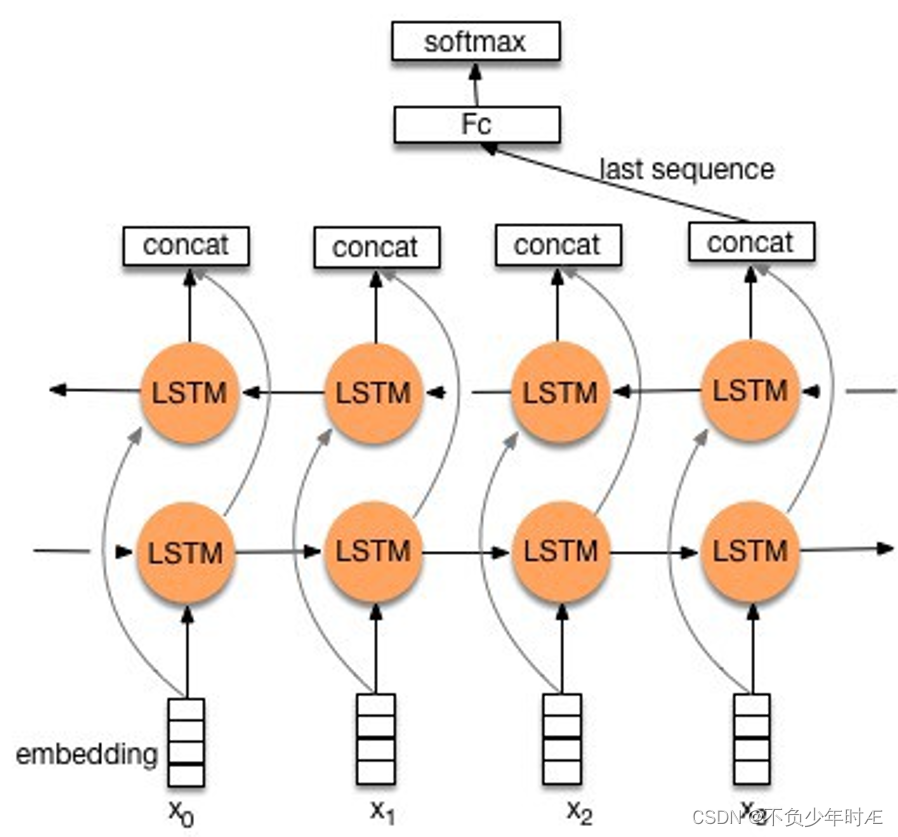
LSTM网络我使用了一个embedding层,一个LSTM层,和一个dense层
这里的?是因为我在搭建网络的时候并没有指定每一层的输出shape,这并不影响之后的训练
LSTM层 LSTM 单元的数量为128,设置了 20% 的 dropout 比率以防止过拟合,设置了 20% 的 recurrent_dropout 比率
全连接(Dense)层级,用于输出最终的情感预测结果
loss值使用binary_crossentropy
训练方式使用adm
训练十次的loss和准确率如下:

可以看到最后到达了0.9558的准确率,还是可以的
使用测试语句“这家酒店服务特别好!下次我还会来的”

可以看到测试的准确率也非常可以
下面是代码详解:
#建立 LSTM 模型
def build_lstm_model(max_words, embedding_dim, max_length):
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=max_length))
model.add(LSTM(128, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
return model
def predict_sentiment(text, model, tokenizer, max_length):
# 对文本进行预处理和转换
processed_text = preprocess_text([text])
sequences = text_to_sequences(processed_text, tokenizer, max_length)
# 进行情感分析预测
prediction = model.predict(sequences)[0][0]
if prediction >= 0.5:
sentiment = 'positive'
else:
sentiment = 'negative'
return sentiment, prediction
def main():
# 设定参数
data_dir = 'datanew'
max_words = 10000
max_length = 100
# 数据预处理
sequences, labels, tokenizer = preprocess(data_dir, max_words, max_length)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(sequences, labels, test_size=0.2, random_state=42)
# 设定参数
embedding_dim = 100
# 构建 LSTM 模型
model = build_lstm_model(max_words, embedding_dim, max_length)
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 查看模型结构
print(model.summary())
# 训练 LSTM 模型
history = model.fit(X_train, y_train, epochs=20, batch_size=64, validation_data=(X_test, y_test))
# 保存模型
model.save('LSTM.h5')
# 加载模型
model = load_model('LSTM.h5')
print("Model loaded successfully.")
# 加载测试数据
# 评估模型
test_loss, test_accuracy = model.evaluate(X_test, y_test)
print("Test Loss:", test_loss)
print("Test Accuracy:", test_accuracy)
text='这家酒店服务特别好!下次我还会来的'
sentiment, prediction=predict_sentiment(text,model,tokenizer,max_length)
print(sentiment)
print(prediction)
2.3bert
Bert的特殊之处在于他加入了attention注意力机制,什么是注意力机制呢?
attention是一种能让模型对重要信息重点关注并充分学习吸收的技术,它不算是一个完整的模型,应当是一种技术,能够作用于任何序列模型中
那什么是bert呢?
bert在本质上是一个transformer模型,也是一种预训练的语言模型,它通过在大规模文本数据上的预训练来捕捉语言的深层双向表征,然后再针对不同的自然语言处理(NLP)任务进行微调(fine-tuning)。BERT的出现标志着NLP领域的一个重要进步,因为它能够更好地理解语言的上下文和语义关系
既然他是一个transformer模型,那就代表他是一个seqtoseq模型,用于encoder和decoder两种结构,其实 BERT 就是 transform 解码器部分,表示 BERT 结构没有采用 LSTM 这样。 RNN 结构,而是采用了 Transformer 这样结构来实现双向循环神经网
那么如何把bert应用到我们的情感分析项目当中呢?
我们可以用官方的接口直接进行调用(调用pytorch的官方模型):
>>> from transformers import pipeline
# 使用情绪分析流水线
>>> classifier = pipeline('sentiment-analysis')
>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]很明显,官方的bert模型效果是远远大于我们自己训练的模型的,可以做到100%的正确率
那如果不用官方的接口api,我们自己可不可以训练一个模型出来呢?
当然可以,我们可以导入transformer里的bert库,然后加载我们自己的数据集进行训练,但是数据预处理的方式要发生改变(主要是用torch库里的torkernizer):
Bert数据预处理:
import os
import jieba
import numpy as np
import torch
from transformers import BertTokenizer, BertForSequenceClassification, AdamW
from sklearn.model_selection import train_test_split
# 读取文件并分为输入文本和情感标签
def load_data(data_dir):
texts = []
labels = []
for label in ['neg', 'pos']:
label_dir = os.path.join(data_dir, label)
for file in os.listdir(label_dir):
with open(os.path.join(label_dir, file), 'r', encoding='utf-8') as f:
text = f.read().strip()
texts.append(text)
labels.append(0 if label == 'neg' else 1)
return texts, labels
# 对文本进行分词和预处理
def preprocess_text(texts):
processed_texts = []
for text in texts:
# 分词
words = jieba.lcut(text)
# 去除标点符号
words = [word for word in words if word.strip()]
# 可以加入去除停用词等其他预处理步骤
processed_texts.append(" ".join(words))
return processed_texts
训练模型:
# 对新文本进行情感分析预测
def predict_sentiment(text, model, tokenizer, max_length):
# 对文本进行预处理和转换
processed_text = preprocess_text([text])
inputs = tokenizer(processed_text, padding=True, truncation=True, return_tensors="pt")
# 进行情感分析预测
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=1)
prediction = predictions.item()
sentiment = 'positive' if prediction == 1 else 'negative'
return sentiment, outputs.logits[0][prediction].item()
def main():
# 设定参数
data_dir = 'datanew'
max_length = 100
epochs = 20
# 加载预训练的BERT模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=2)
# 数据预处理
texts, labels = load_data(data_dir)
texts = preprocess_text(texts)
sequences = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
labels = torch.tensor(labels)
# 提取张量数据
input_ids = sequences['input_ids']
attention_mask = sequences['attention_mask']
# 将 PyTorch 张量转换为 NumPy 数组
input_ids_np = input_ids.numpy()
attention_mask_np = attention_mask.numpy()
# 划分训练集和测试集
X_train_input_ids, X_test_input_ids, X_train_attention_mask, X_test_attention_mask, y_train, y_test = train_test_split(
input_ids_np, attention_mask_np, labels, test_size=0.2, random_state=42)
X_train_input_ids_tensor = torch.tensor(X_train_input_ids)
X_train_attention_mask_tensor = torch.tensor(X_train_attention_mask)
# 微调BERT模型
optimizer = AdamW(model.parameters(), lr=5e-5)
model.train()
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(input_ids=X_train_input_ids_tensor, attention_mask=X_train_attention_mask_tensor,
labels=y_train)
loss = outputs.loss
loss.backward()
optimizer.step()
# 评估模型
model.eval()
with torch.no_grad():
outputs = model(input_ids=X_test_input_ids, attention_mask=X_test_attention_mask)
predictions = torch.argmax(outputs.logits, dim=1)
test_accuracy = (predictions == y_test).float().mean().item()
print("Test Accuracy:", test_accuracy)
# 对新文本进行情感分析预测
text = '这家酒店服务特别好!下次我还会来的'
sentiment, prediction = predict_sentiment(text, model, tokenizer, max_length)
print("Sentiment:", sentiment)
print("Prediction:", prediction)
if __name__ == "__main__":
main()2.4GPT
对于调用GPT进行文本分析,我采用的方法为前往openai官网注册openai账户:https://platform.openai.com/api-keys
根据手机号我们可以得到专属于自己的密钥(每个人的各不相同)
我们把申请的密钥复制下来通过很短的语句就可以实现用代码和chatgpt对话了:
from openai import Client
from openai import Client
# 创建 OpenAI 客户端并传递 API 密钥
client = Client(api_key="这里写你申请到的密钥")
text_file_path='datanew'
#从文本文件中读取待处理的文本
with open(text_file_path, "r", encoding="utf-8") as file:
text_to_process = file.read()
# 向 ChatGPT 发送消息并获取响应
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="我下面这段话的情感分类为:" + text_to_process,
max_tokens=2000 # 可选参数,控制生成文本的长度
)
print(response.choices[0].text)最后的打印结果为:

三、不同网络的效果分析
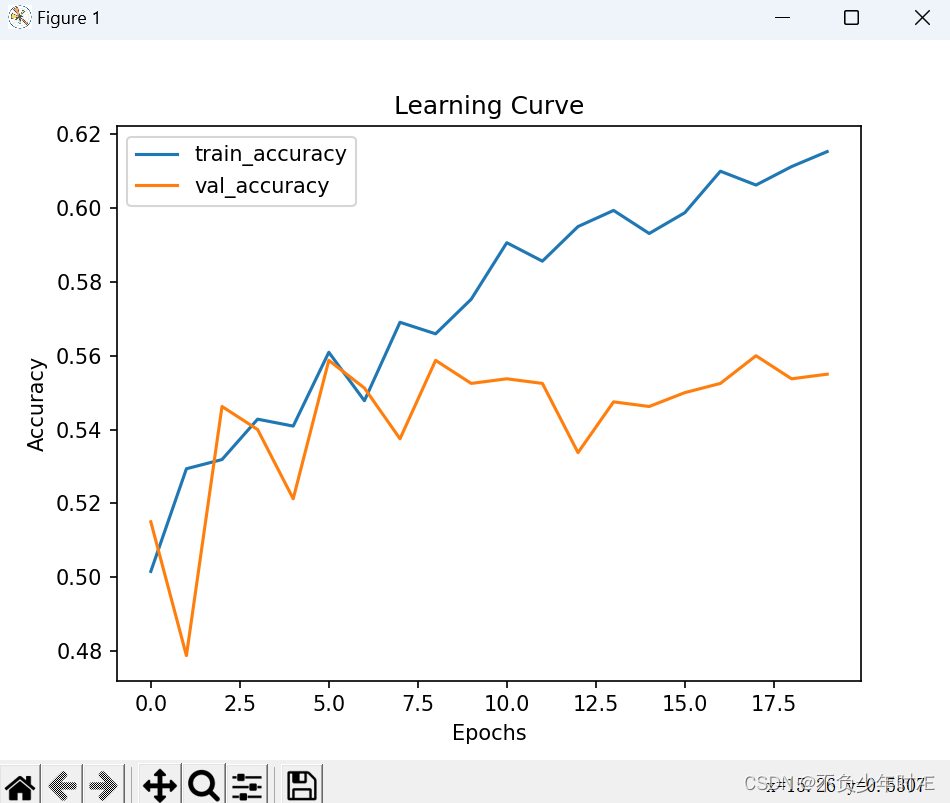
RNN的测试准确率:
学习准确率曲线如下:
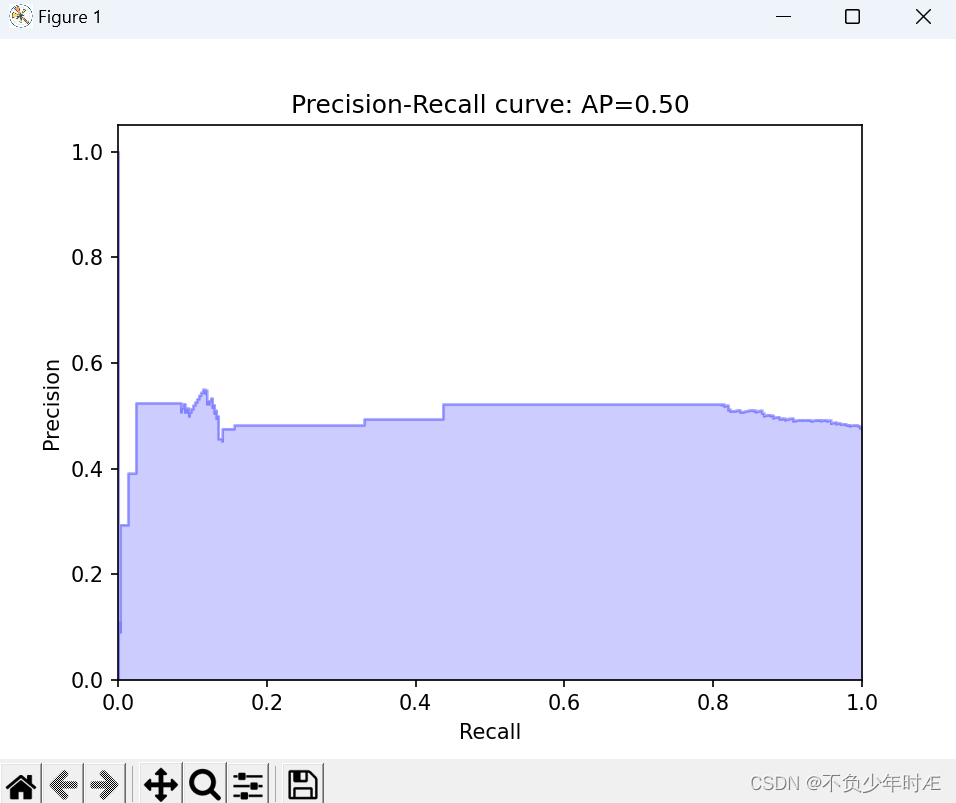
Recall曲线如下:
ROC曲线如下:
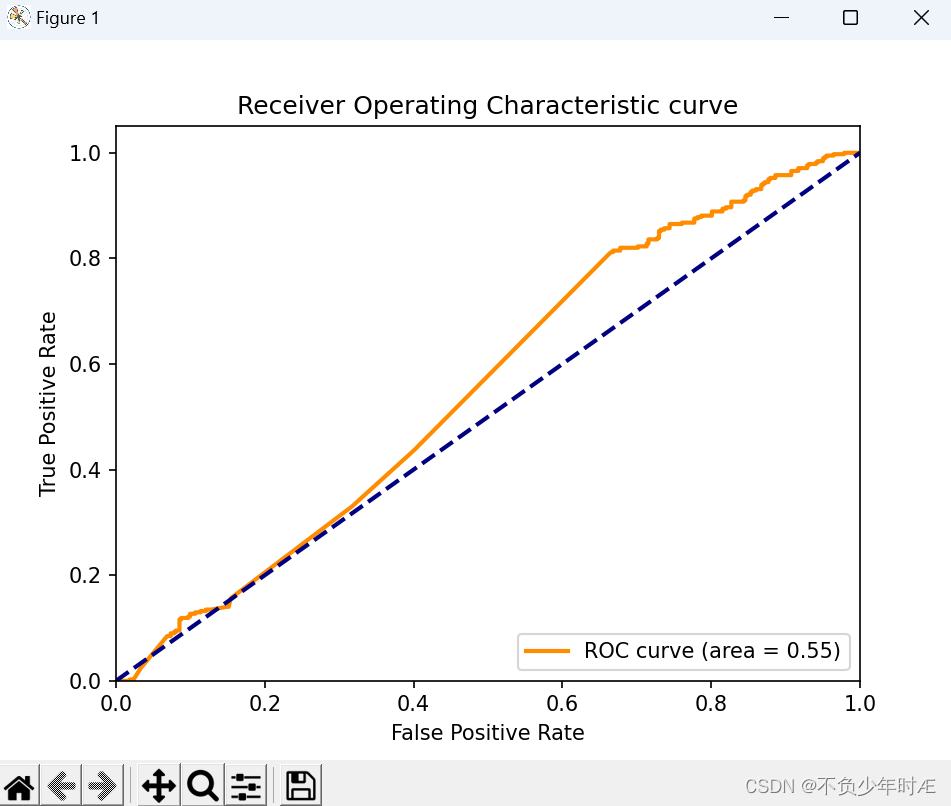
LSTM的测试准确率:
学习准确率曲线如下:
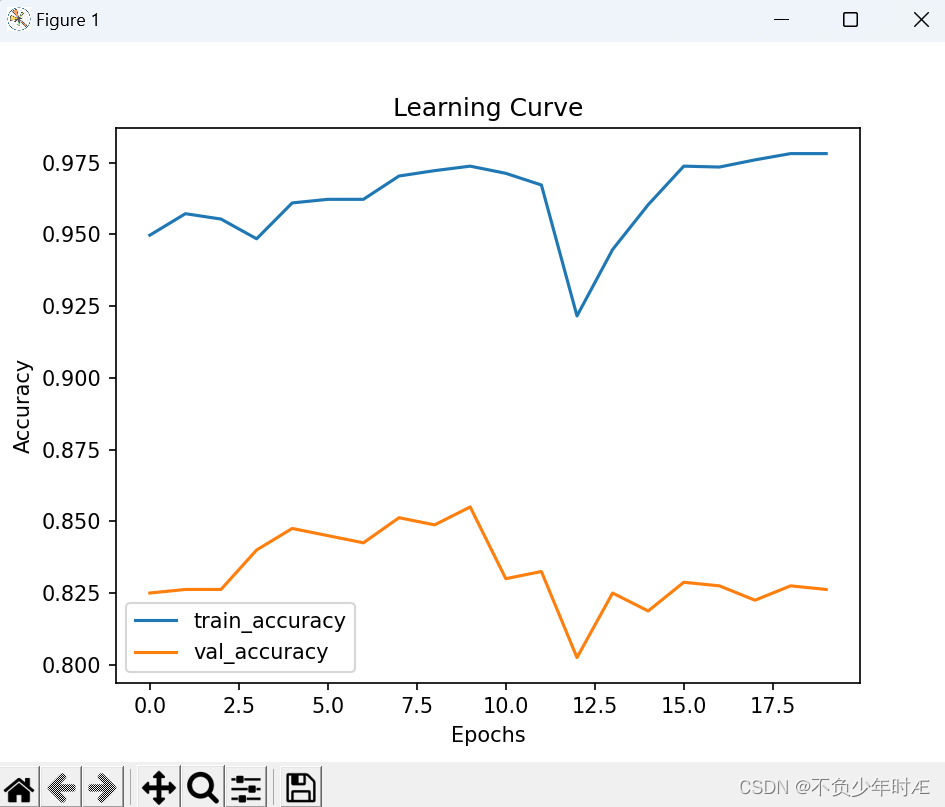
Recall曲线如下:
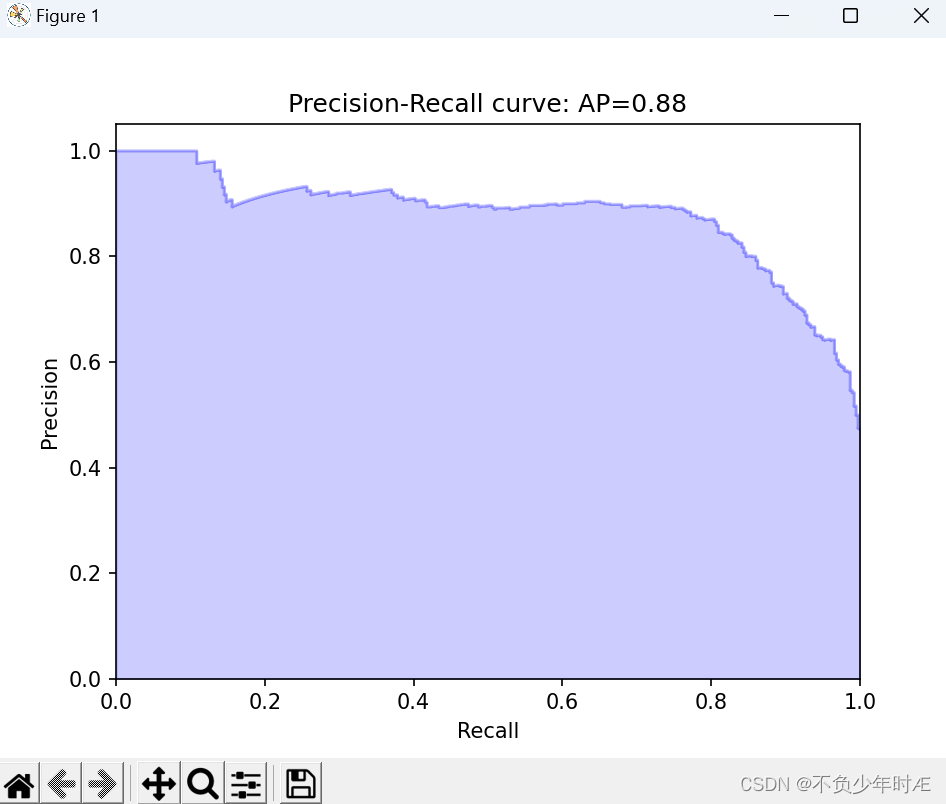
ROC曲线如下: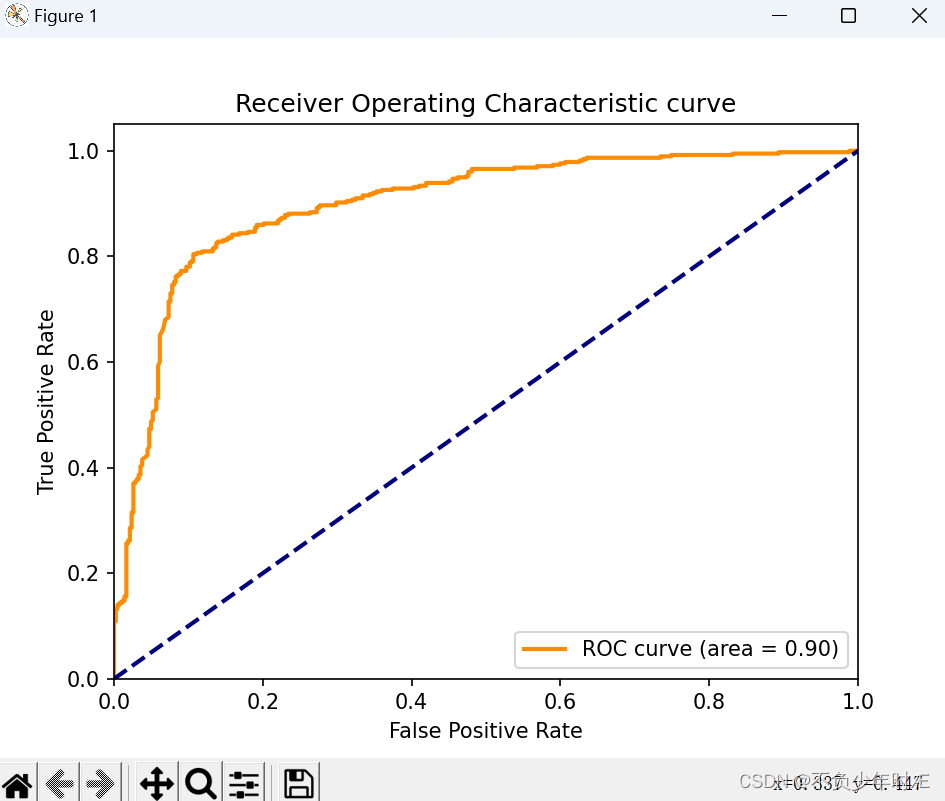
我们可以看到ROC的area有足足0.9,非常出色
Bert的测试准确率(使用官方的训练模型准确率可以到100%):

GPT的测试准确率:
可以达到100%
其实以上的实验结果总共就两个大类,一种是通过循环神经网络对文本进行情感分类,一种是通过transformer模型直接进行分析,显而易见,Transformer的训练模型的效果远远大于循环神经网络,出现这种情况的主要原因也是在于seqtoseq模型和attention机制的强大,他使得模型可以联系上下文,并且通过巨量模型的训练,达到超高的准确率和媲美人类水平的辨识率

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)