C语言-哈希表
了解c语言哈希表的常见用法
目录
一、什么是哈希表
哈希表(Hash table,也叫散列表)是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
在C语言中,可以使用数组+链表数据结构来实现哈希表。通常长这样:
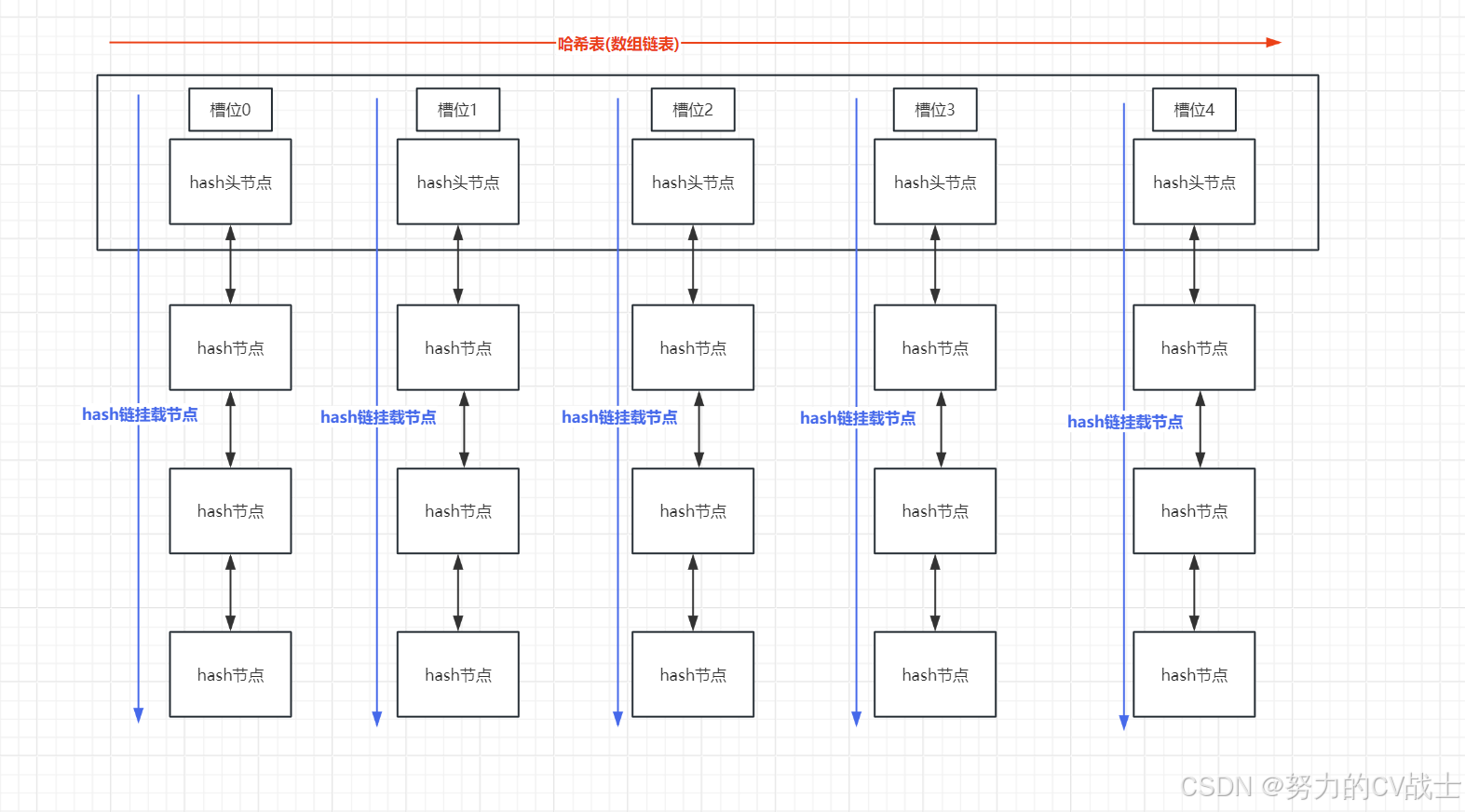
其中hash节点都使用内核链表中的表示方式如下,和大家之前接触到的数据结构可能有所区别。
//内核链表节点
struct my_list_head
{
struct my_list_head *next;
struct my_list_head *prev;
};
//数据节点
typedef struct _DataNode
{
struct my_list_head list;
uint32_t data;
}DataNode;普通的双向链表:
//普通数据节点
typedef struct _DataNode
{
uint32_t data;
struct _DataNode *prev;
struct _DataNode *next;
}DataNode;对于普通的双向链表,每个链表的节点就是一个数据结构;而在内核链表中,链表的节点只是数据结构的一部分。普通的带数据域的链表降低了链表的通用性,不容易扩展。linux内核定义的链表结构不带数据域,只需要两个指针完成链表的操作。将链表节点加入数据结构,具备非常高的扩展性,通用性。
下面我们来定义一个hash表:
#define MAX_HASH_SIZE 5
struct my_list_head *hash_map[MAX_HASH_SIZE];其中hash_map就代表定义的hash表,其实就是指针数组,本质意义就是存放hash头节点的数组,数组大小代表hash表大小。我们结合第一张图来理解,横向表示数组,存放了每个槽位(链表)的头节点,纵向存放了hash节点,也就是链表节点,我们在添加节点、遍历节点或者删除节点时,其实就是对纵向的双向链表的操作。
二、为什么要使用哈希表
刚才提到,我们在添加节点、遍历节点或者删除节点时,其实就是对纵向双向链表的操作。那么如果有大量的数据,我们仅仅存储在一条链表上,去遍历链表,效率可想而知,会非常慢。
如果考虑使用hash表存储呢?通过hash表存储大量的数据,我们可以根据某个key值,把数据挂载到不同的hash链表上,当我们需要遍历时再根据同一个key值算出数据所处的槽位,这样我们在遍历链表时就会快很多。
其实我理解这个过程就是典型的空间换时间的做法,将数据分散到多个hash链储存,在遍历时可以显著提高效率。下面可以结合具体示例理解:
三、哈希表使用实践
先上代码:
#include <stdio.h>
#include <string.h>
#include <stdint.h>
#include <malloc.h>
#include "mylist.h"
#define MAX_HASH_SIZE 5
struct my_list_head *hash_map[MAX_HASH_SIZE];
typedef struct _DataNode
{
struct my_list_head list;
uint32_t data;
}DataNode;
//0返回成功 -1返回失败
int init_hash_map()
{
for (int i = 0; i < MAX_HASH_SIZE; i++)
{
hash_map[i] = (struct my_list_head *)malloc(sizeof(struct my_list_head));
if (!hash_map[i])
{
return -1;
}
else
{
memset(hash_map[i], 0, sizeof(struct my_list_head));
MY_INIT_LIST_HEAD(hash_map[i]);
}
}
return 0;
}
DataNode* create_data_node(uint32_t data)
{
DataNode *new_node = (DataNode *)malloc(sizeof(DataNode));
if (!new_node)
{
return NULL;
}
else
{
memset(new_node, 0, sizeof(DataNode));
new_node->data = data;
return new_node;
}
}
int add_node_to_hash_map()
{
for (int i = 0; i < 50 ; i ++)
{
DataNode *node = create_data_node(i);
if (node)
{
my_list_add_tail(&node->list, hash_map[node->data%MAX_HASH_SIZE]);
}
else
{
printf("Create data node failed!\n");
return -1;
}
}
return 0;
}
// 销毁哈希表并释放所有节点
void destroy_hash_map()
{
for (int i = 0; i < MAX_HASH_SIZE; i++)
{
DataNode *tmp_node = NULL;
// 遍历列表并释放节点
my_list_for_each_entry(tmp_node, hash_map[i], list)
{
// 获取当前节点的下一个节点
DataNode *next_node = (DataNode *)tmp_node->list.next;
if (tmp_node)
{
my_list_del(&tmp_node->list); // 从链表中删除
free(tmp_node); // 释放节点
}
tmp_node = next_node; // 不再使用这个赋值
}
// 释放哈希头节点
if (hash_map[i])
{
free(hash_map[i]);
hash_map[i] = NULL;
}
}
}
int main()
{
if (init_hash_map() != 0)
{
printf("Init hash map failed!\n");
return -1;
}
if (add_node_to_hash_map() != 0)
{
printf("Insert node to hash map failed!\n");
return -1;
}
uint32_t hash_key = 100;
uint32_t hash_size = 0;
DataNode *tmp_node = NULL;
my_list_for_each_entry(tmp_node, hash_map[hash_key%MAX_HASH_SIZE], list)
{
hash_size++;
printf("data:%u\n", tmp_node->data);
}
printf("hash_size:%u\n", hash_size);
destroy_hash_map();
return 0;
}代码中讲解如下:
3.1.创建hash表并初始化
创建了一个全局的hash表,大小为5,然后调用init_hash_map接口初始化hash表,此时将hash表中的所有头节点初始化,将头节点的prev指针和next指针指向自己。
#define MAX_HASH_SIZE 5
struct my_list_head *hash_map[MAX_HASH_SIZE];static inline void MY_INIT_LIST_HEAD(struct my_list_head *list)
{
list->next = list;
list->prev = list;
}3.2.生成hash节点
通过create_data_node接口创建hash数据节点,申请内存成功将其初始化为0,然后将数据data赋值给新的节点new_node,最终返回数据节点new_node。
DataNode* create_data_node(uint32_t data)
{
DataNode *new_node = (DataNode *)malloc(sizeof(DataNode));
if (!new_node)
{
return NULL;
}
else
{
memset(new_node, 0, sizeof(DataNode));
new_node->data = data;
return new_node;
}
}3.3.创建hash节点并插入hash表
循环50次,创建50个hash数据节点。然后将50个hash数据节点以node->data为key计算hash值,插入到hash表中。这里选用的hash算法比较简单,只是为了模拟散列算法,工作中需要根据实际情况选用更优的hash算法,使散列更加均匀。
int add_node_to_hash_map()
{
for (int i = 0; i < 50 ; i ++)
{
DataNode *node = create_data_node(i);
if (node)
{
my_list_add_tail(&node->list, hash_map[node->data%MAX_HASH_SIZE]);
}
else
{
printf("Create data node failed!\n");
return -1;
}
}
return 0;
}3.4.遍历hash表
上述提到,每个数据计算的hash值可能是不一样的,因此我们在遍历hash表的时候要确认遍历的纵向链表是准确的,否则永远也无法获取到自己想要的数据。那么这就需要在添加hash节点时,选择的hash-key值和hash算法和遍历时选择的hash-key值和hash算法保持一致。
这里我们模拟选择key为100,取模运算,最后得到的hash值为0,因此其实就是遍历槽位0上
挂载的链表节点。理论上应该输出我们刚才插入的节点:0 5 10 15 20 25 30 35 40 45
uint32_t hash_key = 100;
uint32_t hash_size = 0;
DataNode *tmp_node = NULL;
my_list_for_each_entry(tmp_node, hash_map[hash_key%MAX_HASH_SIZE], list)
{
hash_size++;
printf("data:%u\n", tmp_node->data);
}
printf("hash_size:%u\n", hash_size);输出结果:
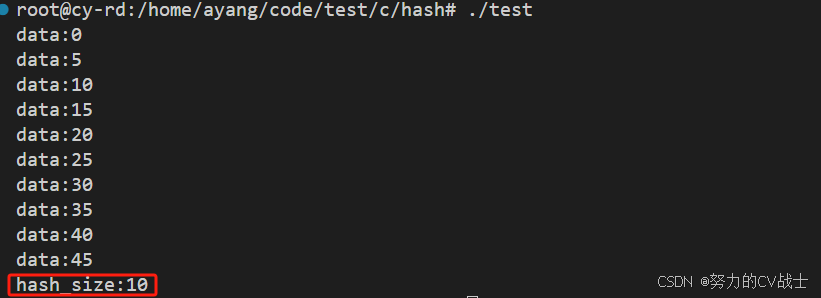
和预期一致,这里hash_size表示桶深,表示槽位0(也就是数组下标为0的纵向链表)下挂载了多少个数据节点。感兴趣的同学可以自己试验一下,理论上每个槽位下都挂载了10个数据节点,一共5个槽位,加起来正好50个数据节点。
四、哈希冲突
通过上面遍历hash表的操作,相信大家对hash冲突应该有一定的了解了。hash冲突其实就是指一个纵向槽位下挂载了多个数据节点,一条链表上如果挂载了几百万个hash节点,这个时候我们就认为有hash冲突了,频繁的哈希冲突会导致查找、插入和删除操作的性能下降,因为需要遍历链表或进行探测。
所以我们在选择hash算法的时候,一定要尽可能的让数据散列开,将数据节点均匀的挂载到哈希表中。日常工作中可以通过日志打印,监控桶的深度,来观察hash冲突的情况。
五、小结
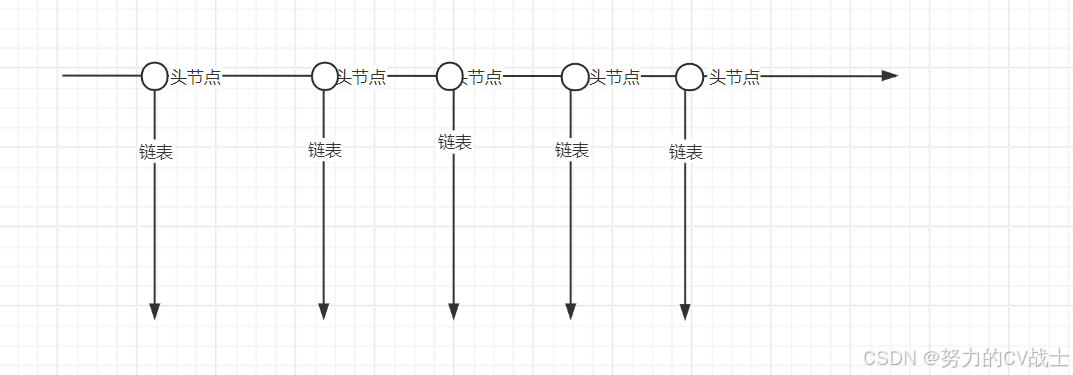
通过对上面的描述,hash表可以抽象的理解成:横着一条绳子,下面又挂了很多纵向的绳子。就像这样:
哈希表是一种强大的数据结构,适合多种应用场景。通过理解其基本概念、优缺点和最佳实践,可以有效地利用哈希表来提高数据处理的效率和性能。也希望大家可以动手实践同时结合内核链表原理更进一步掌握hash表的用法。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 39
39 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)