混淆矩阵实例解释
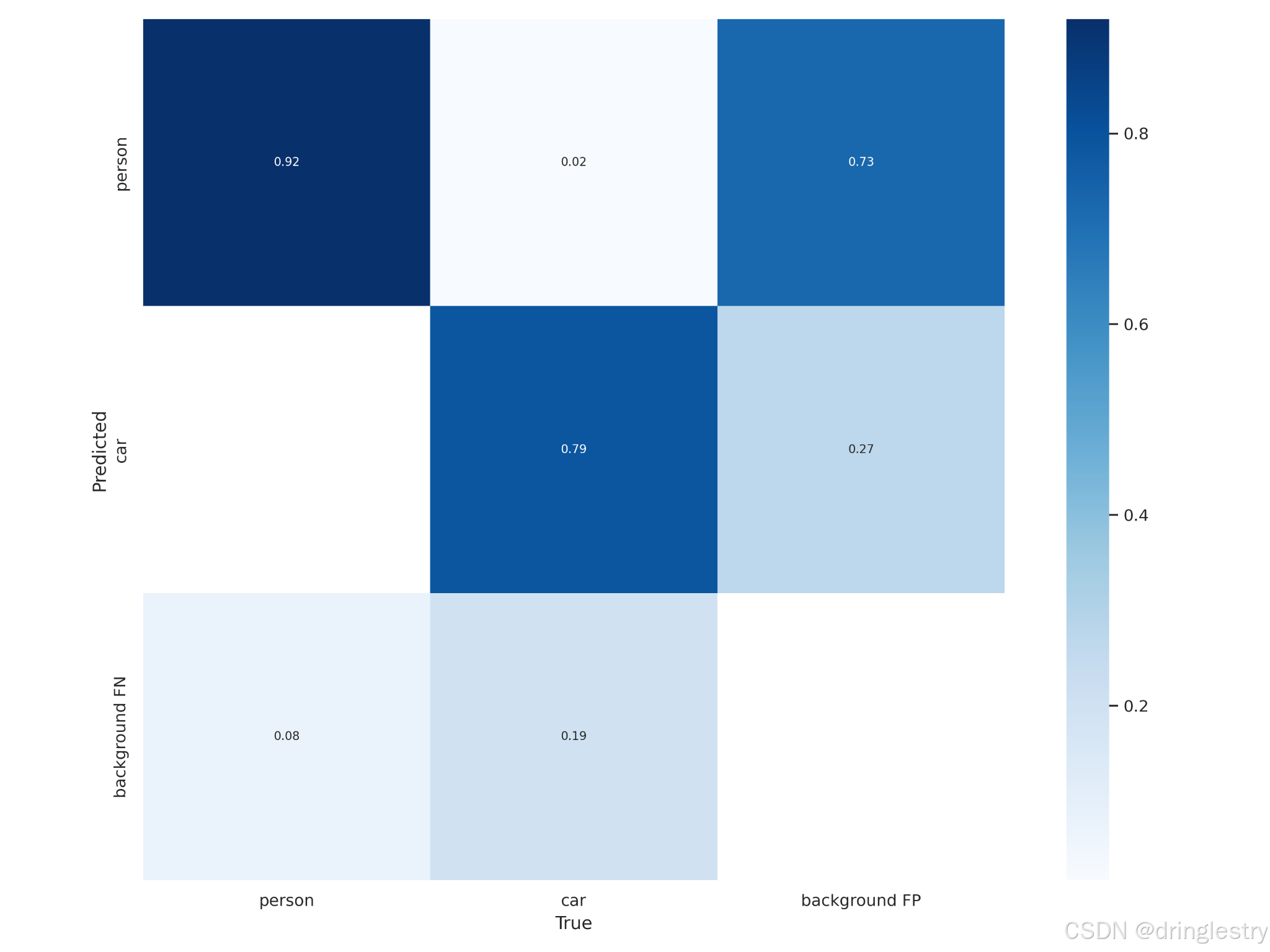
这张图展示了一个三类分类问题的归一化混淆矩阵,用于评估模型的分类性能。混淆矩阵包含三种真实标签(personcar和)和三种预测标签。
·
一、示例图
二、该图混淆矩阵解释以及相关的指标
这张图展示了一个三类分类问题的归一化混淆矩阵,用于评估模型的分类性能。混淆矩阵包含三种真实标签(person、car 和 background FP)和三种预测标签。以下是它的内容及指标的说明:
混淆矩阵解析
矩阵中的每个单元格表示:
- 行表示模型的预测类别(如预测为
person、car或background FN)。 - 列表示数据的真实类别(如实际是
person、car或background FP)。 - 每个值是该分类情况的归一化比例。
例如:
-
第一行表示模型预测为
person的结果:0.92表示模型预测为person且真实为person的比例。0.02表示模型预测为person但真实为car的比例。0.73表示模型预测为person但真实为background FP的比例。
-
第二行表示模型预测为
car的结果:0.79表示模型预测为car且真实为car的比例。0.27表示模型预测为car但真实为background FP的比例。
-
第三行表示模型预测为
background FN的结果:0.08表示模型预测为background FN且真实为person的比例。0.19表示模型预测为background FN且真实为car的比例。
常用评估指标
-
准确率 (Accuracy)
定义:正确分类的样本数占总样本数的比例。
计算公式:
-
精确率 (Precision)
对于每个类别,定义为模型预测为该类别的样本中实际属于该类别的比例。
例如,对于person:
-
召回率 (Recall)
对于每个类别,定义为实际属于该类别的样本中被模型正确预测为该类别的比例。
例如,对于person: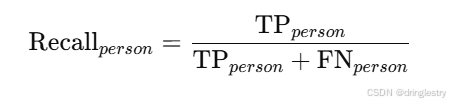
-
F1 分数 (F1-Score)
精确率和召回率的调和平均,用于平衡两者:
-
类别间表现差异
从矩阵中可以观察到各类别的混淆程度(如person与background FP的高混淆),帮助定位模型弱点。
三、background FP 、background FN详细解释
在这张混淆矩阵中,background FP 和 background FN 是两个特殊的分类标签,它们通常在目标检测或分类任务中与背景相关的错误情况有关。以下是它们的含义:
1. background FP(Background False Positive)
- 定义:指模型将某些背景区域 误分类为目标 的情况。
- 含义:
- 背景区域中没有目标物体,但模型错误地预测为某个目标类别(比如
person或car)。 - 这种情况常见于背景噪声或具有类似于目标的特征时。
- 背景区域中没有目标物体,但模型错误地预测为某个目标类别(比如
- 示例:在图片中,模型把一棵树或一个阴影预测为
car或person。
2. background FN(Background False Negative)
- 定义:指模型将实际为目标的区域 误分类为背景 的情况。
- 含义:
- 真正的目标物体(比如
person或car)存在,但模型未能检测到,认为它是背景。 - 这种情况常见于目标不明显(如部分遮挡、光照不足)或模型未能学习到该特征时。
- 真正的目标物体(比如
- 示例:图片中确实有一辆
car,但模型认为这个区域是纯背景。
为什么需要这两类标签?
在目标检测任务中,背景信息的处理对模型性能影响很大:
background FP和background FN的区分 能帮助模型开发者了解:- 模型是否容易过度拟合背景(FP问题)。
- 或是否错过真正的目标(FN问题)。
- 应用场景:
- 在自动驾驶中,减少
background FN对行人和车辆识别至关重要。 - 在监控中,减少
background FP可以降低误报率。
- 在自动驾驶中,减少

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)