SpatialLM尝鲜版
复现和使用spatialLM
仓库链接:github.com/manycore-research/SpatialLM
部署推理
总体思路是按照readme一步一步整。此处仅仅记录几个注意事项:
Installation
(1)官方cuda版本挺高的,我这边nvidia-smi最高版本是12.2,所以没有利用12.4,而是改用了12.2,所幸依赖库的版本不需要修改,没有版本问题。
(2)conda install -y nvidia/label/cuda-12.4.0::cuda-toolkit conda-forge::sparsehash部分nvcc -V发现cuda-toolkit已经装好了,所以此处只安装了conda-forge::sparsehash。
(3) Install dependencies with poetry部分,由于poetry没用过,所以改用pip install -r requirements.txt进行安装的,只将pyproject.toml中dependencies部分写到requirements.txt中即可。
举例:
修改前:
toml = "^0.10.2"
tokenizers = ">=0.19.0,<0.20.4"
修改后:
toml==0.10.2
tokenizers>=0.19.0,<0.20.4
(4)此处需要注意transformers的版本,一开始安装的是允许的最低版本,推理的时候出现如下报错:
python inference.py --point_cloud pcd/scene0000_00.ply --output pcd/scene0000_00.txt --model_path manycore-research/SpatialLM-Llama-1B
Traceback (most recent call last):
File "/home/jovyan/scf/code/SpatialLM/inference.py", line 168, in <module>
tokenizer = AutoTokenizer.from_pretrained(args.model_path)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jovyan/.conda/envs/spatiallm/lib/python3.11/site-packages/transformers/models/auto/tokenization_auto.py", line 880, in from_pretrained
return tokenizer_class.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jovyan/.conda/envs/spatiallm/lib/python3.11/site-packages/transformers/tokenization_utils_base.py", line 2110, in from_pretrained
return cls._from_pretrained(
^^^^^^^^^^^^^^^^^^^^^
File "/home/jovyan/.conda/envs/spatiallm/lib/python3.11/site-packages/transformers/tokenization_utils_base.py", line 2336, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jovyan/.conda/envs/spatiallm/lib/python3.11/site-packages/transformers/tokenization_utils_fast.py", line 114, in __init__
fast_tokenizer = TokenizerFast.from_file(fast_tokenizer_file)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Exception: data did not match any variant of untagged enum ModelWrapper at line 1251003 column 3
升级transformers到4.46.1就可以解决,深层原因待研究。
复现&&自测
命令说明
下载模型:
huggingface-cli download --resume-download --local-dir-use-symlinks False manycore-research/SpatialLM-Llama-1B --local-dir D:\Code\KnowLM\knowlm-13b-ie
(注意:运行该命令之前,建立一个模型的文件夹,在这个文件夹下执行上述下载命令,防止文件散落各处。)
推理:
python inference.py --point_cloud pcd/gejian.ply --output pcd/gejian.txt --model_path ./SpatialLM-Llama-1B
可视化:
python visualize.py --point_cloud pcd/gejian.ply --layout pcd/gejian.txt --save pcd/gejian.rrd
rerun gejian.rrd
huggingface网络报错:
OSError: We couldn't connect to 'https://huggingface.co' to load the files, and couldn't find them in the cached files.
Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
❯ echo $HF_ENDPOINT
为空
❯ export HF_ENDPOINT=https://hf-mirror.com
可正常下载
复现scene0000_00.ply
整体效果还比较符合预期,如下图所示:
对于门的识别存在一些误检,如下图所示:
当前没得论文、技术报告以及训练脚本,不知道要从何查证啊!
SpatialLM Testset中相应layout文件的可视化结果如下图所示: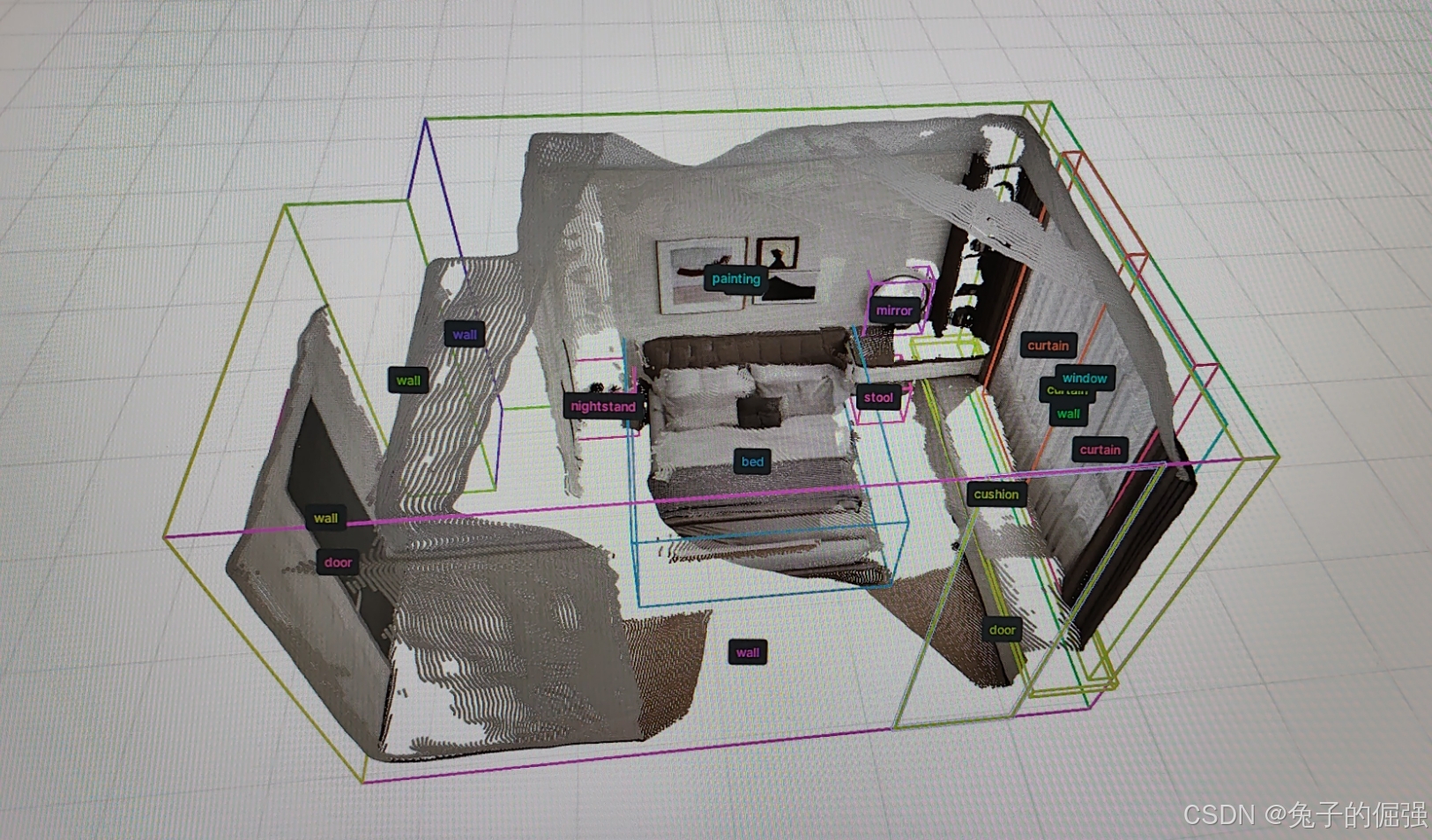
这个应该算是真值吧,嗯。。。。。感觉差距还是蛮大。
自采数据测试
厕所隔间数据检测结果如下:

可以看出,整体的位置存在较大偏差。
利用rgbd相机对一个隔间进行视角比较完整的数据采集,然后利用MASt3R-SLAM进行三维稠密重建,利用cloudcompare进行axis align,效果会怎样呢?待更新。
tum/rgbd_dataset_freiburg1_room/ 数据集
利用MASt3R-SLAM进行三维稠密重建,利用cloudcompare进行axis align,效果如下: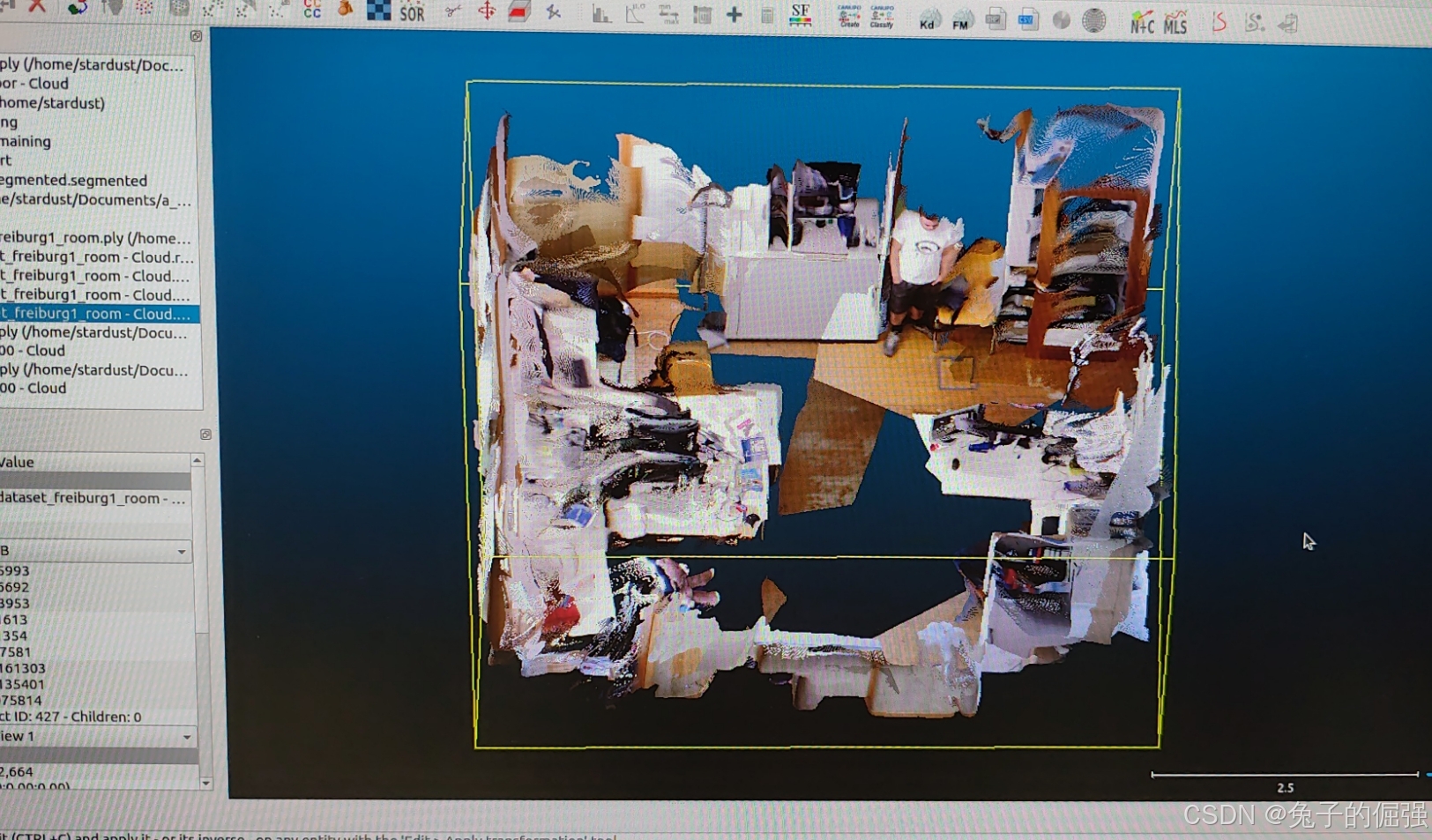
spatiallm效果如下:
突出一个乱七八糟吧,哈哈哈。(严重怀疑我的打开方式应该有点问题,需要再斟酌一下了)
部署MAST3R-SLAM
参考链接:https://kwanwaipang.github.io/MASt3R-SLAM/
pip install -e thirdparty/in3d
pip install --no-build-isolation -e .
上述两条命令真的要运行超久,而且没有进度提示,一度想要crtl+C,哈哈哈,耐心等下,我这边最终都可以顺利done.
补充问题
参考上述博客,感觉我这边远远没有上面说的那么顺利,一堆报错,暴风哭泣。
循环导入
CUDA_VISIBLE_DEVICES=0 python main.py --dataset datasets/tum/rgbd_dataset_freiburg1_room/ --config config/calib.yaml
Traceback (most recent call last):
File "/home/jovyan/scf/code/MASt3R-SLAM_comment/main.py", line 11, in <module>
from mast3r_slam.global_opt import FactorGraph
File "/home/jovyan/scf/code/MASt3R-SLAM_comment/mast3r_slam/global_opt.py", line 4, in <module>
from mast3r_slam.frame import SharedKeyframes
File "/home/jovyan/scf/code/MASt3R-SLAM_comment/mast3r_slam/frame.py", line 6, in <module>
from mast3r_slam.mast3r_utils import resize_img
File "/home/jovyan/scf/code/MASt3R-SLAM_comment/mast3r_slam/mast3r_utils.py", line 10, in <module>
from mast3r_slam.retrieval_database import RetrievalDatabase
File "/home/jovyan/scf/code/MASt3R-SLAM_comment/mast3r_slam/retrieval_database.py", line 8, in <module>
from mast3r_slam.frame import Frame
ImportError: cannot import name 'Frame' from partially initialized module 'mast3r_slam.frame' (most likely due to a circular import) (/home/jovyan/scf/code/MASt3R-SLAM_comment/mast3r_slam/frame.py) 请帮忙解决一下这个错误可以吗?
解决方法:
梳理上述import关系,发现frame.py 从mast3r_utils.py中导入resize_img与后面的RetrievalDatabase导入没有什么关系,所以修改了 from mast3r_slam.retrieval_database import RetrievalDatabase的位置到load_retriever函数中,如下所示:
def load_retriever(mast3r_model, retriever_path=None, device="cuda"):
from mast3r_slam.retrieval_database import RetrievalDatabase
retriever_path = (
"checkpoints/MASt3R_ViTLarge_BaseDecoder_512_catmlpdpt_metric_retrieval_trainingfree.pth"
if retriever_path is None
else retriever_path
)
retriever = RetrievalDatabase(retriever_path, backbone=mast3r_model, device=device)
return retriever
FFmpeg版本过低问题
CUDA_VISIBLE_DEVICES=0 python main.py --dataset datasets/tum/rgbd_dataset_freiburg1_room/ --config config/calib.yaml
Traceback (most recent call last):
File "/home/jovyan/scf/code/MASt3R-SLAM_comment/main.py", line 14, in <module>
from mast3r_slam.dataloader import Intrinsics, load_dataset
File "/home/jovyan/scf/code/MASt3R-SLAM_comment/mast3r_slam/dataloader.py", line 13, in <module>
from torchcodec.decoders import VideoDecoder
File "/home/jovyan/.conda/envs/mast3r-slam/lib/python3.11/site-packages/torchcodec/__init__.py", line 10, in <module>
from . import decoders, samplers # noqa
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jovyan/.conda/envs/mast3r-slam/lib/python3.11/site-packages/torchcodec/decoders/__init__.py", line 7, in <module>
from ._core import VideoStreamMetadata
File "/home/jovyan/.conda/envs/mast3r-slam/lib/python3.11/site-packages/torchcodec/decoders/_core/__init__.py", line 8, in <module>
from ._metadata import (
File "/home/jovyan/.conda/envs/mast3r-slam/lib/python3.11/site-packages/torchcodec/decoders/_core/_metadata.py", line 15, in <module>
from torchcodec.decoders._core.video_decoder_ops import (
File "/home/jovyan/.conda/envs/mast3r-slam/lib/python3.11/site-packages/torchcodec/decoders/_core/video_decoder_ops.py", line 59, in <module>
load_torchcodec_extension()
File "/home/jovyan/.conda/envs/mast3r-slam/lib/python3.11/site-packages/torchcodec/decoders/_core/video_decoder_ops.py", line 44, in load_torchcodec_extension
raise RuntimeError(
RuntimeError: Could not load libtorchcodec. Likely causes:
1. FFmpeg is not properly installed in your environment. We support
versions 4, 5, 6 and 7.
2. The PyTorch version (2.5.1+cu124) is not compatible with
this version of TorchCodec. Refer to the version compatibility
table:
https://github.com/pytorch/torchcodec?tab=readme-ov-file#installing-torchcodec.
3. Another runtime dependency; see exceptions below.
The following exceptions were raised as we tried to load libtorchcodec:
[start of libtorchcodec loading traceback]
libavutil.so.59: cannot open shared object file: No such file or directory
libavutil.so.58: cannot open shared object file: No such file or directory
libavutil.so.57: cannot open shared object file: No such file or directory
/lib/x86_64-linux-gnu/libgobject-2.0.so.0: undefined symbol: ffi_type_uint32, version LIBFFI_BASE_7.0
[end of libtorchcodec loading traceback].
由于我这边没法通过ppa进行版本升级,所以考虑通过源码进行安装。
编译安装教程如下:
参考链接:FFmpeg编译安装
sudo ln -s /home/XXX/ffmpeg-4.1/ffprobe ffprobe 处可以直接链接/usr/local/ffmpeg-4.1下面的文件
例如:sudo ln -s /usr/local/ffmpeg/bin/ffprobe /usr/bin/ffprobe
我这边的安装版本如下:
ffmpeg -version
ffmpeg version 5.1.6 Copyright (c) 2000-2024 the FFmpeg developers
built with gcc 9 (Ubuntu 9.4.0-1ubuntu1~20.04.2)
configuration: --enable-shared --prefix=/usr/local/ffmpeg
libavutil 57. 28.100 / 57. 28.100
libavcodec 59. 37.100 / 59. 37.100
libavformat 59. 27.100 / 59. 27.100
libavdevice 59. 7.100 / 59. 7.100
libavfilter 8. 44.100 / 8. 44.100
libswscale 6. 7.100 / 6. 7.100
libswresample 4. 7.100 / 4. 7.100
其他依赖包
其他需要安装的依赖,按照报错一个接一个的pip install即可。
举例:
pip install opencv-python
pip install git+https://github.com/princeton-vl/lietorch.git
此处重点说一下torchcodec
python3 main.py --dataset ../dataset_and_checkpoint/datasets/tum/rgbd_dataset_freiburg1_room/ --config config/calib.yaml
Traceback (most recent call last):
File "/home/jovyan/scf/code/MASt3R-SLAM_comment-comment/main.py", line 14, in <module>
from mast3r_slam.dataloader import Intrinsics, load_dataset
File "/home/jovyan/scf/code/MASt3R-SLAM_comment-comment/mast3r_slam/dataloader.py", line 13, in <module>
from torchcodec.decoders import VideoDecoder
File "/home/jovyan/.conda/envs/mast3r-slam-2/lib/python3.11/site-packages/torchcodec/__init__.py", line 10, in <module>
from . import decoders, samplers # noqa
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/jovyan/.conda/envs/mast3r-slam-2/lib/python3.11/site-packages/torchcodec/decoders/__init__.py", line 7, in <module>
from ._core import VideoStreamMetadata
File "/home/jovyan/.conda/envs/mast3r-slam-2/lib/python3.11/site-packages/torchcodec/decoders/_core/__init__.py", line 8, in <module>
from ._metadata import (
File "/home/jovyan/.conda/envs/mast3r-slam-2/lib/python3.11/site-packages/torchcodec/decoders/_core/_metadata.py", line 15, in <module>
from torchcodec.decoders._core.video_decoder_ops import (
File "/home/jovyan/.conda/envs/mast3r-slam-2/lib/python3.11/site-packages/torchcodec/decoders/_core/video_decoder_ops.py", line 59, in <module>
load_torchcodec_extension()
File "/home/jovyan/.conda/envs/mast3r-slam-2/lib/python3.11/site-packages/torchcodec/decoders/_core/video_decoder_ops.py", line 44, in load_torchcodec_extension
raise RuntimeError(
RuntimeError: Could not load libtorchcodec. Likely causes:
1. FFmpeg is not properly installed in your environment. We support
versions 4, 5, 6 and 7.
2. The PyTorch version (2.5.1+cu124) is not compatible with
this version of TorchCodec. Refer to the version compatibility
table:
https://github.com/pytorch/torchcodec?tab=readme-ov-file#installing-torchcodec.
3. Another runtime dependency; see exceptions below.
The following exceptions were raised as we tried to load libtorchcodec:
[start of libtorchcodec loading traceback]
libavutil.so.59: cannot open shared object file: No such file or directory
libavutil.so.58: cannot open shared object file: No such file or directory
/lib/x86_64-linux-gnu/libwayland-client.so.0: undefined symbol: ffi_type_uint32, version LIBFFI_BASE_7.0
/lib/x86_64-linux-gnu/libgobject-2.0.so.0: undefined symbol: ffi_type_uint32, version LIBFFI_BASE_7.0
[end of libtorchcodec loading traceback].
libtorchcodec加载失败,尝试了几次没有解决,看官方仓库该依赖是可选的,所以就没有继续深究了,把dataloader.py中下述类给注释掉,可以正常运行了:
# class MP4Dataset(MonocularDataset):
# from torchcodec.decoders import VideoDecoder
# def __init__(self, dataset_path):
# super().__init__()
# self.use_calibration = False
# self.dataset_path = pathlib.Path(dataset_path)
# self.decoder = VideoDecoder(str(self.dataset_path))
# self.fps = self.decoder.metadata.average_fps
# self.total_frames = self.decoder.metadata.num_frames
# self.stride = config["dataset"]["subsample"]
# def __len__(self):
# return self.total_frames // self.stride
# def read_img(self, idx):
# img = self.decoder[idx * self.stride] # c,h,w
# img = img.permute(1, 2, 0)
# img = img.numpy()
# img = img.astype(self.dtype)
# timestamp = idx / self.fps
# self.timestamps.append(timestamp)
# return img
后续需要的话,打算找一个平替,如果有时间的话,解一下。
常用命令理解
带着问题了解项目
未完待续

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)