HIT 计算机系统 二进制炸弹 sum栈溢出问题
HIT 计算机系统 二进制炸弹 sum栈溢出问题
前言
二进制炸弹BombLab,网上有很多资源,而且与CMU本身的BombLab很相似,但是这个通过sum递归函数来看栈溢出的实验,似乎是新加的,笔者在这写下自己的分析思路。
笔者做整个实验的时候,后面的BombLab都迎刃而解,非独这个新加的sum栈溢出实验充满了问题。
- 首先这个sum函数本身调用的空间就不大,因此n会循环很多次,这就导致在调试的过程中设置条件断点
break sum if $rdi == 1会让gdb运行很久,甚至在运行过程中就会抛出段错误(也许是gdb本身调试的过程中也会保存临时数据而占用一部分资源) - 很多同学反应自己的n会发生变化,笔者在最初
./bomblab并直接输入n与用gdb打开bomblab输入n得到的溢出n值并不一样,最后以gdb中运行的结果为准。 - 老师并没有给出具体思路,有同学最初是直接在main函数枚举n 反复调用n,直至栈溢出,这样不仅效率很低(当然也可以二分查找来加快速率),但是本身也占用了一些栈空间,这不一定能计算出最终的准确结果。
实验思路
首先是老师为了避免同学之间抄袭而添加的略显滑稽的编译优化选项,根据学号来选择优化级别,然而老师没有想到的是现代编译器太强大了,直接将这个简单的尾递归函数编程迭代了,导致一部分同学很久都没有找到n的值,笔者在最初使用
gcc -O4 bufbomb.c -o bufbomb
编译后同样发现了这个问题,然后查看汇编代码 发现果然如此
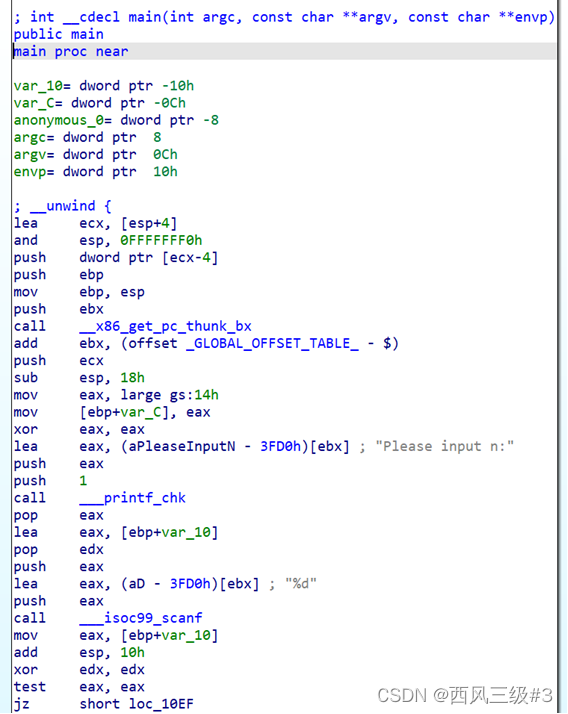
使用ida反编译得到的C语言伪代码
可以看到已经变成循环了,那根本就不能发生栈溢出。
因此跟老师沟通后,可以降级,最后选择
gcc -O1 bufbomb.c -o bufbomb
得以使实验继续进行下去。
首先回顾linux的内存模型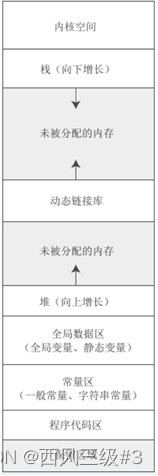
栈由高地址向低地址生长,因此我们可以调试程序,首先输入一个特别大的数,让栈溢出,然后程序会报出段错误,此时我们查看rsp的值记为r1r_1r1,这个代表栈顶的极限地址,然后我们再重新运行程序启动调试,输入一个相对小的n,将断点设在第一次进入sum函数中,查看rsp的值记为r2r_2r2,将这个rsp值和先前的rsp相减,也就是 M=r2−r1M = r_2-r_1M=r2−r1(因为栈从高地址向低地址伸展),得到的值就是我们一直递归下去,sum最多能有的栈空间大小 MMM,然后我们让程序进入下一个sum函数,此时rsp值为r3r_3r3,然后计算出m=r2−r3m=r_2-r_3m=r2−r3也就是调用一次sum需要分配的栈空间,将Mm\frac{M}{m}mM计算出来,就是n的值。
- 计算出发生段错误时esp的地址
如图,我们进入程序,输入5201314 发现调试程序终止,报出段错误 此时记录esp的值为0xff7fdff4。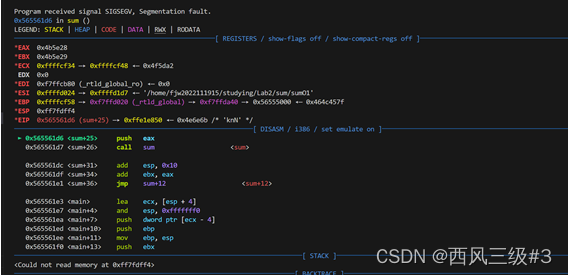
然后,键入r重新运行程序,输入b sum,将断点断在第一次sum时,记录下esp的值为0xffffcf2c,输入命令p 0xffffcf2c - 0xff7fdff4 可以快速计算出地址差,8384312(十进制),这就是最大空间。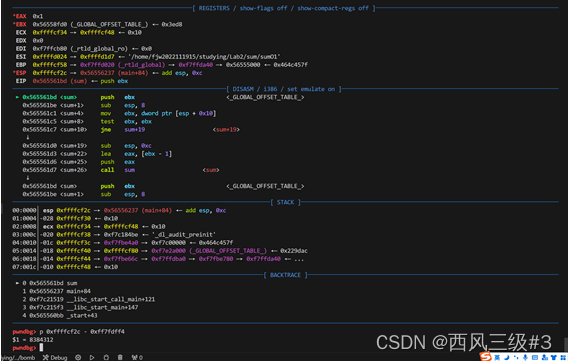
然后我们输入c,进入下一次sum,发现esp值为0xffffcf0c,计算出差值为32,也就是一次sum占用空间,然后相除,得出结果为n=262008.5。我们进行验证,输入n=262009,程序可以运行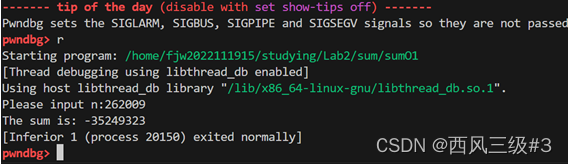
然后,输入262010,发现程序抛出段错误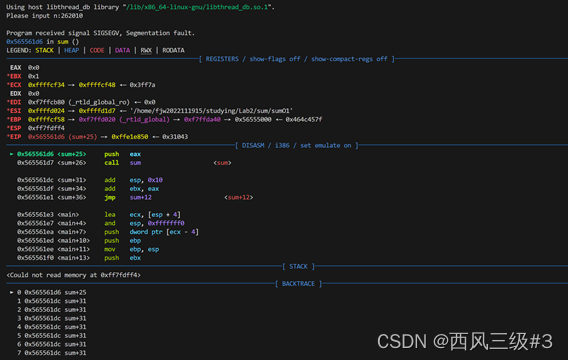
因此,最后确定了是在本机器下,有nmin=262010n_{min}=262010nmin=262010。
此时esp是0xff7fdff4,跟刚才输入5201314时的esp值一致,说明当输入n为262009时,剩余的栈空间已经不够32bytes。
为什么是这个值?通过gdb调试验证并分析说明(10分)
其实求得时候就已经说明这个问题了,整理语言就可以,同时也可以结合gdb调试来说(然而我下条件断点根本就达不到那个条件就会卡死…)笔者仅放出我的实验报告内容共读者参考。
其实利用gdb寻找这个n值的时候已经说明了问题,也就是在上一问找的过程中已经可以说明问题了,下面进行更加详细的阐释。使用gdb调试工具下一个条件断点,我们知道,第一个参数传参在edi中,所以b sum if $edi==1 发现
看起来gdb不堪重负了(在我的电脑上gdb和pwndbg还有edb都没法到这么深的栈)。选择一种间接方式更清晰的阐释整个过程。利用gdb调试阐释整个sum调用过程
首先在sum处下断点 输入16(0xa),
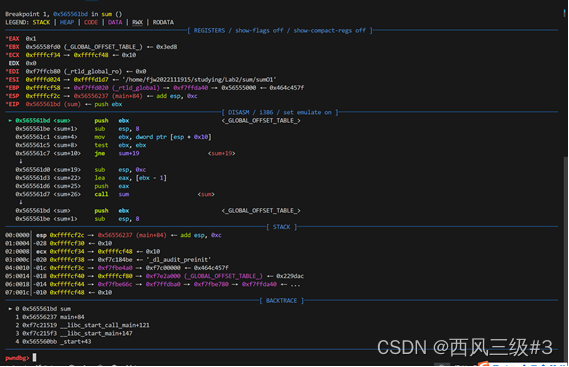
此时刚到sum门口,输入ni单步执行汇编
push ebx (0x565561bd <sum>):
这条指令将ebx寄存器的值压入栈中。ebx寄存器在许多调用约定中用于保存需要在函数调用之间保持不变的值。由于递归调用会改变寄存器的值,因此在函数开始时保存这些值是必要的。
然后esp由 0xffffcf2c变为 0xffffcf28 ,减少四个字节。
sub esp, 8 (0x565561be <sum+1>):
减少栈指针esp,为局部变量分配8字节的空间。
mov ebx, dword ptr [esp + 0x10] (0x565561c1 <sum+4>):
将参数n(位于esp+0x10的位置,考虑到之前的push和栈帧调整)的值移动到ebx寄存器中。这里ebx被用来存储函数的参数。
jne sum+19 (0x565561c7 <sum+10>):
如果n不等于0(ebx不为0),跳转到sum+19继续执行。如果n等于0,由于没有提供相应的代码,理论上应该是直接返回0。
sub esp, 0xc (0x565561d0 <sum+19>):
进一步减小esp,为递归调用准备空间。
lea eax, [ebx - 1] (0x565561d3 <sum+22>):
将n-1的值计算出来,并存储在eax寄存器中,准备作为下一个递归调用的参数。
push eax (0x565561d6 <sum+25>):
将n-1(存储在eax中)的值压入栈中,作为下一次递归调用sum函数的参数。
call sum (0x565561d7 <sum+26>):
递归调用sum函数自身,参数是n-1。
这个递归过程会一直重复,直到n等于0为止。每次递归调用都会计算n+sum(n-1),最终当n减至0时,开始逐层返回并累加这些值,最终计算出从1到n的累加和。
综上所述 ,这段代码可以总结为:
保存ebx寄存器:4字节
为局部变量分配空间:8字节
为递归调用的参数分配空间:12字节(sub esp, 0xc)+ 4字节(push eax)
递归调用(保存返回地址):4字节。
可以看到 到下一个sum执行前,esp确实减小了32个字节。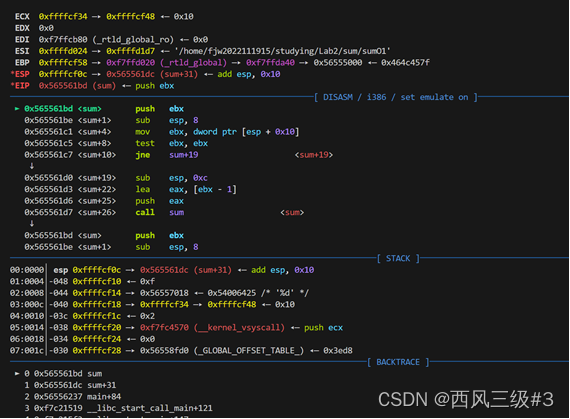
整个sum函数就一个n,他的位置在[esp+0x10]的位置上,这是因为在函数调用时,call指令会自动将返回地址压栈,而sum函数本身在开始时又压栈保存了ebx寄存器的值,并且通过sub esp, 8为局部变量分配了更多空间。然后是递归调用的参数准备
对于递归调用sum(n-1):
- 计算n-1:
• lea eax, [ebx - 1]:这行代码计算n-1的值,并将结果存储在eax寄存器中。 - 参数压栈:
• push eax:将n-1的值压入栈中,作为下一次递归调用的参数。
递归调用
• call sum:这条指令实际上执行了递归调用。call指令会做两件事:首先,它将返回地址(即下一条指令的地址)压入栈中;然后,它将指令指针跳转到sum函数的开始进行下一次调用。
所以,一次调用占了32个字节,我的计算方式,恰好能够找到临界值,然后得出最终答案为262010.
下面是一些探索。
当时由于记错了,用的-m64,忘截图了,但是注意到一次递归占了80个字节,其实浪费蛮大的。
另外,现代编译器很智能,相对不复杂的尾递归都能被优化成迭代。
小结
我觉得这个实验设计的是有一些问题的,其实可以将sum函数里面塞入一些比较大的局部变量来让栈空间占用大一些,这样可以减小n的值。
另外,希望有生之年我可以用markdown来写实验报告。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)