DH_Live部署与训练方法详述
致力于让每个人都能够轻松创建和使用数字人,推动数字人技术的普及和应用,为用户提供一个全面的数字人解决方案
一、环境部署
权重下载
环境配置
conda create -n dh_live python=3.12
conda activate dh_live
pip install torch --index-url https://download.pytorch.org/whl/cu124
pip install -r requirements.txt
根据缺失的库进行补充即可
二、模型推理
视频准备
使用data_preparation.py脚本准备你的视频。将YOUR_VIDEO_PATH替换为你视频的实际路径:
python data_preparation.py <YOUR_VIDEO_PATH>
结果(Video)将存储在 ./video_data 目录下。
合成视频
-
demo
使用音频文件运行demo.py脚本。确保音频文件为.wav格式,采样率为16千赫兹,且是16位单声道。将video_data/test替换为你的视频信息文件的路径,将video_data/audio0.wav</font>替换为你的音频文件的路径,并将1.mp4替换为期望的输出视频路径:python demo.py <video_data/test> <video_data/audio0.wav> <1.mp4> -
demo_mini
使用音频文件运行demo_mini.py脚本。确保音频文件为.wav格式,采样率为16千赫兹,且是16位单声道。将video_data/test替换为你的视频信息文件的路径,将video_data/audio0.wav替换为你的音频文件的路径,并将1.mp4替换为期望的输出视频路径:python demo_mini.py <video_data/test> <video_data/audio0.wav> <1.mp4>
使用麦克风实时运行
如需使用麦克风进行实时操作,只需运行以下命令:
python demo_avatar.py
三、模型训练
涉及为一个人脸生成系统训练两个独立的模型:一个是用于提取嘴部动作模式的音频模型,另一个是用于生成最终人脸的渲染模型。每个模型都需要其各自的数据准备和训练流程。
Train Audio
cd train_audio
数据准备(Data Preparation)
- 使用超过1万个由不同说话者录制的短音频片段,每个音频片段时长至少为5秒,采用16千赫兹单声道的wav格式。
- 将这些文件放置在
train_audio/train_data文件夹中。 - 从 Wav2Lip 项目(https://github.com/Rudrabha/Wav2Lip)下载 wav2lip.pth 文件,并将其放置在
train_audio/checkpoints文件夹中。
具体步骤(Steps)
1. Face Video Generation
python preparation_step0.py <face_path> <wav_16K_path>
# Example: preparation_step0.py face.jpg train_data
2. Mouth Region Extraction and PCA Modeling
python preparation_step1.py <data_path>
# Example: preparation_step1.py train_data
Now ensure the file directory is as follows:
|--/train_audio
| |--/checkpoints
| | |--/wav2lip.pth
| | |--/pca.pkl
| | |--/wav2lip_pca_all.gif
| |--/train_data
| | |--/000001.wav
| | |--/000001.avi
| | |--/000001.txt
| | |--/000002.wav
| | |--/000002.avi
| | |--/000002.txt
| | |--/000003.wav
| | |--/000003.avi
| | |--/000003.txt
3. Training LSTM Model
python train_lstm.py <data_path>
# Example: train_lstm.py train_data
4. Testing Audio Accuracy
python test.py <wav_path> <ckpt_path>
# Example: python test.py D:/Code/py/test_wav/0013.wav checkpoints/audio.pkl
Train Render
cd train
预训练权重准备(Downloading the Pre-trained Model)
Baidu Netdisk Extraction Code: ym7k
放在checkpoints,最终目录结构
|--/train
| |--/checkpoints
| | |--/epoch_160.pth
| |--/dir_to_data
| | |--/video0.mp4
Render Model Training (simplified DiNet)
原始数据结构(Original Data Structure)
确保数据目录结构按如下方式进行组织:
|--/dir_to_data
| |--/video0.mp4
| |--/video1.mp4
| |--/video2.mp4
数据准备(Data Preparation)
使用data_preparation_face.py脚本准备视频。将 dir_to_data替换为你视频的实际路径。
python train/data_preparation_face.py <dir_to_data>
运行该脚本后,数据目录结构应更新为:
|--/dir_to_data
| |--/video0
| | |--/keypoint_rotate.pkl
| | |--/face_mat_mask.pkl
| | |--/image
| | |--/000000.png
| | |--/000001.png
| | |--/...
| |--/video1
| | |--/keypoint_rotate.pkl
| | |--/face_mat_mask.pkl
| | |--/image
| | |--/000000.png
| | |--/000001.png
| | |--/...
数据测试(Data Validation)
使用以下脚本验证准备好的数据:
python train/train_input_validation_render_model.py dir_to_data
得到以下图像: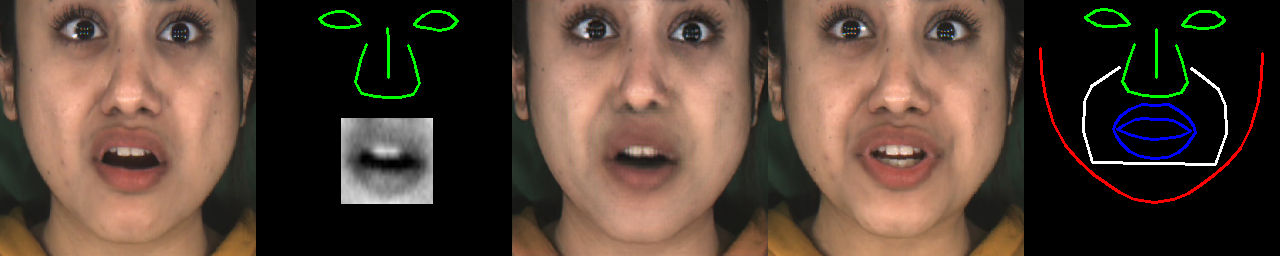
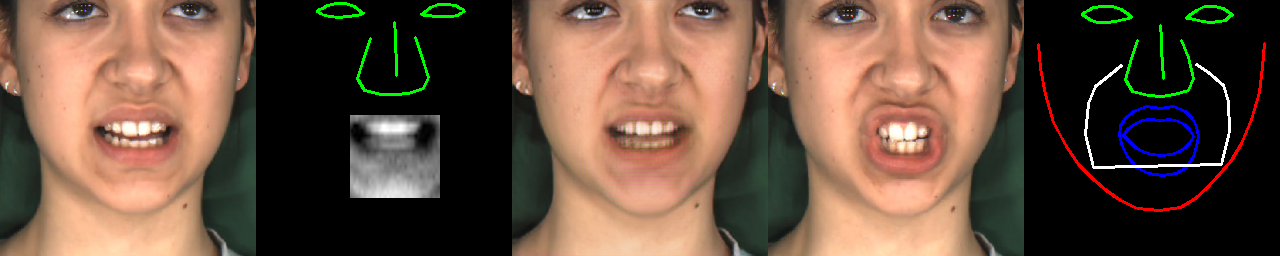

训练(Training)
python train/train_render_model.py --train_data dir_to_data
监视训练进程(Monitoring Training Progress)
tensorboard --logdir=checkpoint/Dinet_five_ref
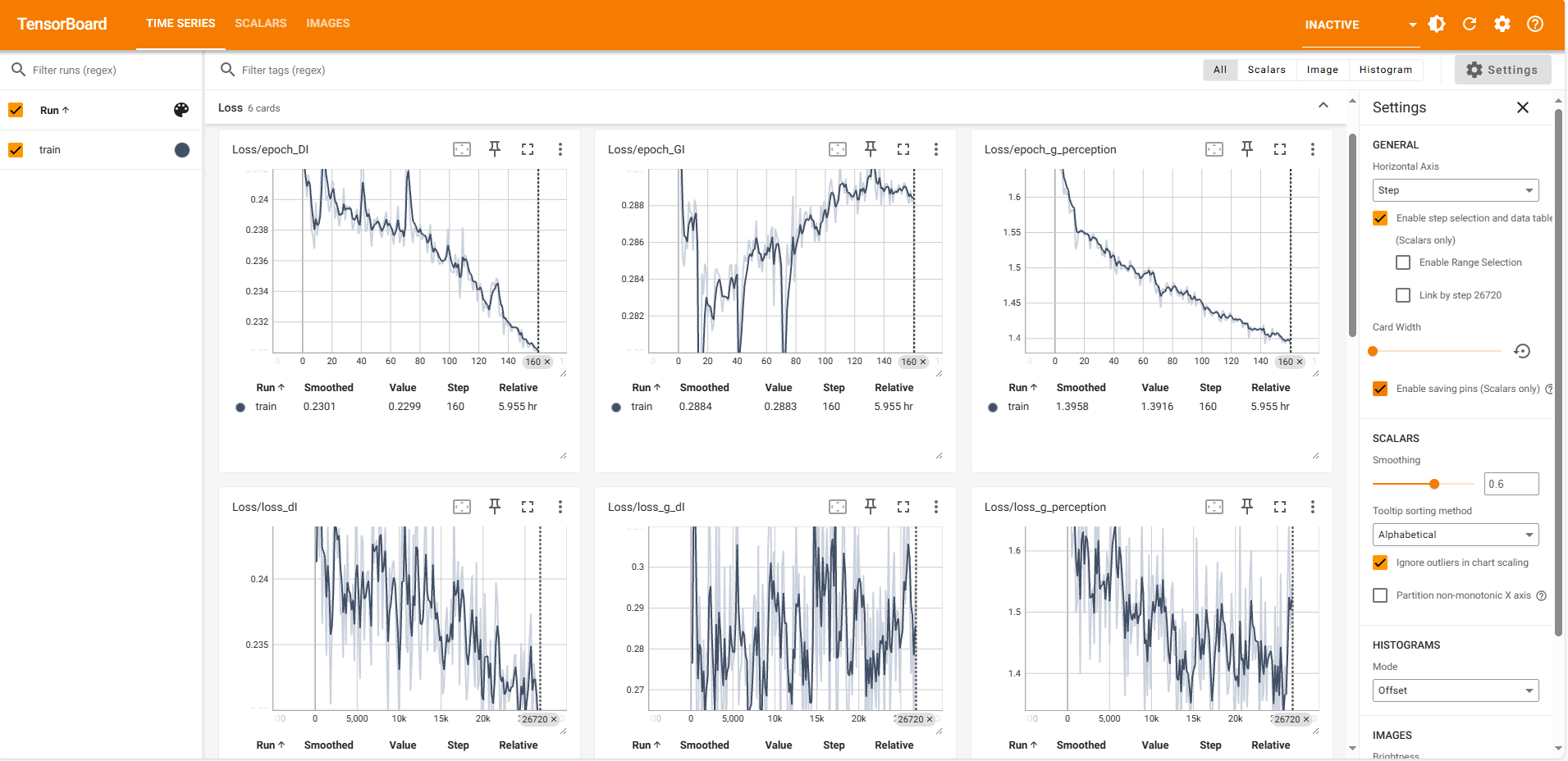
问题(Problems)
偏色较为严重

测试数据和训练数据颜色差别较大,导致该问题

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 46
46 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)