ANTLR4详细介绍(二)语法规则
Antlr4的强大建立在灵活的语法定义和可扩展性的基础之上。这一版本新增了import功能,且语法(parser)、词法(lexer)可拆分成独立的文件,从而增加规则的可复用性。引入访问者、监听器模式,使解析与应用代码分离。语法规则表述也更为简单,更贴近自然语言的习惯。本文将以 Antlr4.9.3 版本为基础环境进行讲解。
Antlr4的强大建立在灵活的语法定义和可扩展性的基础之上。这一版本新增了import功能,且语法(parser)、词法(lexer)可拆分成独立的文件,从而增加规则的可复用性。引入访问者、监听器模式,使解析与应用代码分离。语法规则表述也更为简单,更贴近自然语言的习惯。
本文将以 Antlr4.9.3 版本为基础环境进行讲解。
一、解析流程
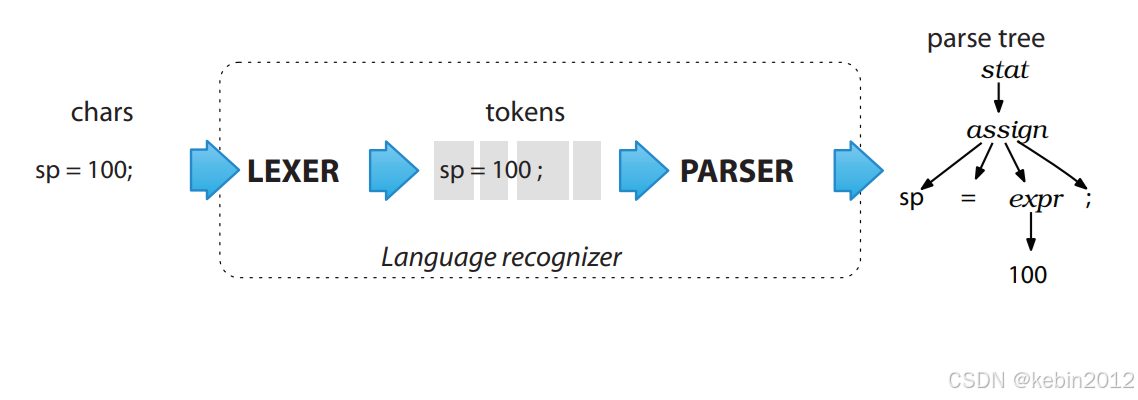
上图简要的描述了语法解析的流程。规则由词组和语法组成,词组由更小的子词组和词汇符号组成;语法由词组构成且包含特定语义的语句。词组和语法分别由对应的解析器来完成分析,这两个解析器就是词法解析器和语法解析器。
开发人员首先要做的是理清规则的组成词汇,以及语义间的逻辑关系,然后编写逻辑严谨的规则文档,最后通过Antlr自带编译工具自动生成词法解析器和语法解析器。
解析器生成后,待解析内容首先通过词法解析器拆分为词汇流(即一段不可再分的词汇符号组成的序列),然后通过语法解析器识别语句的结构,并根据语义条件及优先级完成解析输出语法树。开发人员通常会自定义监听器(或访问者)完成语法树遍历操作,从而实现特定的业务逻辑。
规则文件的基本结构如下:
[parser | lexer] grammar Name; // 规则名
options {...} // 选项
import ... ; // 导入其它规则文件
tokens {...} // 词条,主要用于定义动作描述用到的类型
channels {...} // 通道,给词组划分类别
@actionName {...} // 动作,嵌入解析器的代码块
rule1: // 规则
...
ruleN
fragment f1 // 片段(只能由其他规则引用,不可直接用于解析)
...
fragment fN二、基本指令
规则文件支持下列基本指令:grammer、options、import、tokens、channels、fragment、mode、type,这些指令用于设定文件属性、词汇属性。此外还有returns、locals、throws、catch、finally等指令,这些通常配合动作(action)为解析类增加语法修饰功能。
规则文件内,grammer必须出现且只能出现1次,options、tokens、import 至多只能出现1次,其余指令可出现多次。
熟练掌握各个指令的用法是编写有效规则的关键。下面就分别介绍这些指令的作用和使用场景。
grammer
用于声明文件类型,必须位于文档首行,只能出现一次。前面可以加 parser 或 lexer 关键字修饰,代表当前文档是一个语法文件还是词法文件。如果没有加关键字修饰,则表明这是一个混合型规则文件(combined grammers),既可编写词法规则,也可编写语法规则。
grammer修饰的名称必须和当前规则文件名保持一致。
不同类型的规则文档使用限制如下:
grammer xxx; 混合型,该文件可 import 混合型、词法、语法文件,但不允许 import 包含mode、channels指令的词法文件。
lexer grammer xxx; 词法文件,该文件不能包含语法规则,允许使用mode、channels指令,允许 import 词法文件。
parser grammer xxx; 语法文件,该文件不能包含词法规则,不允许使用mode、channels指令。不允许 import 词法文件、包含词法规则(包括mode、channels指令)的混合型文件——如果混合型文件仅仅包含语法规则,是可以引入的。如须引入词法文件,应使用下面的设置替代 import:
options { tokenVocab=xxx; }
options
用于配置规则文件的属性,既可以编写在规则文件内,也可在命令行编译时通过传入参数的方式使用。
指令格式如下:
options { name1=value1; name2=value2; ... nameN=valueN; }
常用的设置项有以下内容:
* language:指定编译目标语言,例:
options { language = Cpp; }* superClass: 指定编译生成解析类的父类, 例:
@header {
import org.test.antlr.parse.MyParser;
}
options { superClass= MyParser; }* TokenLabelType:指定自定义Token类,例:
@header {
import org.test.antlr.token.MyToken;
}
options { TokenLabelType = MyToken; }* tokenVocab:语法文件引入词汇文件,例:
options { tokenVocab = MyLexer; }* caseInsensitive: 词法是否大小写敏感, 该设置项从4.10本版开始支持,想要在前面的版本实现大小写不敏感应使用下面的第二种写法,例:
options { caseInsensitive = false; } case: C A S E
A: 'A' | 'a';
B: 'B' | 'b';
...
Z: 'Z' | 'z';import
用于引入其它语法文件、词法文件,但须注意的是语法文件只能导入语法文件或不包含词法规则的混合型文件,词法文件只能导入词法文件,混合型文件可以导入语法或词法文件。
指令格式如下:
import rule1, rule2..., ruleN; // antlr4支持导入多个规则文件
注:想要在语法文件中引入词法文件,应使用tokenVocab选项,参看上一节中的说明
tokens
用于定义那些未被任何语法规则使用的标记类型,通常用于定义动作描述用到的自定义属性
指令格式如下:
tokens { token1, token2, ... tokenN }
tokens { BEGIN, END, IF, THEN, WHILE }
@lexer::members { // keywords map used in lexer to assign token types
Map<String,Integer> keywords = new HashMap<String,Integer>() {{
put("begin", KeywordsParser.BEGIN);
put("end", KeywordsParser.END);
...
}};
}channels
Antlr编译器有通道的概念,是指编译器将词组按通道设定划归到不同的集合中,以便各类词组的集中处理。编译器默认内置了两个通道:DEFAULT_TOKEN_CHANNEL(默认通道)、HIDDEN(隐藏通道)。未设定通道的词汇被送入默认通道中。
指令格式如下:
channels { channel1, channel2, ... channelN }
channels { COMMENT_CHANNEL, ERROR_CHANNEL }
ID : [a-zA-Z_][a-zA-Z0-9_]*;
COMMENT : '/*!' .+? '*/' -> channel(COMMENT_CHANNEL); // 注释送入注释通道
...
ERROR : . -> channel(ERROR_CHANNEL); // 文件最后一行,未识别的词汇送入异常通道
自定义channel的使用位于词法规则定义之后(结尾分号之前),包含channel指令的词法规则格式如下:
rule :expresstion -> channel(xxx);
注:channels只能定义在词汇文件中
fragment
用于定义不能独立识别为词组(token),只能被其它词组引用的字符。这种对外不可见属性,导致无法在语法树中单独读取这些字符。
如果只想设定词汇中的某一类型,但在编译器层面并不关心解析到的具体值是什么(或者说值对规则的设定没有影响),则可以采用fragment来描述,例如字符集编码、颜色编码等。fragment 修饰的词汇不可直接用于语法规则。
fragment 词汇的格式与普通词汇相似,只是在前面加了fragment关键字:
fragment tokenName: tokenValue;
charsetting: '<?xml' CHARSET? '>';
CHARSET: 'encoding=' CHARSET_NAME;
fragment CHARSET_NAME: ARMSCII8 | ASCII | BIG5 | BINARY | CP1250
| CP1251 | CP1256 | CP1257 | CP850
| CP852 | CP866 | CP932 | DEC8 | EUCJPMS
| EUCKR | GB2312 | GBK | GEOSTD8 | GREEK
| HEBREW | HP8 | KEYBCS2 | KOI8R | KOI8U
| LATIN1 | LATIN2 | LATIN5 | LATIN7
| MACCE | MACROMAN | SJIS | SWE7 | TIS620
| UCS2 | UJIS | UTF16 | UTF16LE | UTF32
| UTF8 | UTF8MB4;
ARMSCII8: 'armscii8';
ASCII: 'ascii';
...
UTF8MB4: 'utf8mb4';mode
用于定义模式,配合 pushmode 和 popmode 指令实现切换栈顶模式(栈用来实现正则表达式无法处理的场景,如嵌套结构处理)。指令格式如下:
mode: xxx;
下面是对内嵌脚本处理的样例:
mode SCRIPT;
START: '<' SCRIPT -> pushMode(SCRIPT); // 解析至 <script 进入脚本模式
END: '>' -> popMode; // 解析至 > 退出脚本模式
SCRIPT: 'script';
自定义mode的使用位于词法规则定义之后(结尾分号之前),包含channel指令的词法规则格式如下:
rule :expresstion -> pushmode(xxx); // 栈顶切换为xxx模式
rule :expresstion -> popmode; // 栈顶跳出xxx模式
注:mode只能定义在词汇文件中
type
type操作符用来设定词汇的类型,已设定了类型的词汇,在编码时可以通过 Token.getType()方法获取所属类型。
lexer grammar Arco;
tokens { QUOTATION }
CHARACTER : ~ [!#:=\r\n];
DOUBLE : '"' .*? '"' -> type(QUOTATION);
SINGLE : '\'' .*? '\'' -> type(QUOTATION);
SLASH_DELIMITER : ~[\r\n] -> type(CHARACTER);
WS : [ \r\t\n]+ -> skip;注:type指令设定的类型值既可以使用已定义的词法规则,也可以使用tokens指令中设定的名称
三、语法
前面提到,Antlr4规则分为词法规则和语法规则。词法规则是语法规则的基本组成单元——即多个词汇、范式符号组成的词组。语法规则是由分支结构、范式符号、修饰动作等组成的的词组流。
1. 编写规范
Antlr4的规则使用扩展巴科斯范式(EBNF)描述。关于巴科斯范式本文不做详述,下面简单的列举一下范式的要点。
• 规则名和描述内容中间以 : 分开,每一条规则以 ; 结尾
• 具有相同左部的规则可共用一个左部,各个右部之间以 | 隔开
• () 表示产生式组成
• ? 表示产生式出现0次或1次
• + 表示产生式出现1次或多次
• * 表示产生式出现0次或多次
• . 表示任意一个字符
• ~ 表示不出现后面的字符
• .. 表示字符范围
词法规则名称必须是大写字母,语法规则名称必须是小写字母,规则名称和规则描述语句允许使用 Unicode 字符。词法规则描述只能由词法规则组成,语法规则描述既可以包含词法规则,也可以包含语法规则。
contact : mobile EOF;
mobile : prefix MASK DIGIT;
prefix : (CMCC | UNICOM | TELECOM);
MASK : '****';
CMCC : '134' | '135' | '136' | '137' | '138' | '139' | '147' | '150' | '151' | '152' | '157' | '158' | '159' | '182' | '187' | '188';
UNICOM : '130' | '131' | '132' | '155' | '156' | '185' | '186';
TELECOM : '133' | '149' | '153' | '173' | '177' | '180' | '181' | '189' | '199' | '193';
DIGIT : [0-9]+;字面量是指由字符组成的常量词汇(类似于Java语言中的字符串常量),用于描述代表固定语义的规则内容,不可用作规则名称。
字面量不区分字符和字符串,也不像一些高级语言那样划分数值、字符、布尔等类型。不管字面量是由一个字符还是多个字符组成,也不管其真实意义是代表数值、字符串、布尔还是其它类型,都应当用单引号包裹。字面量允许包含Unicode字符,还可以使用特殊的转义符。
IF: 'if';
BOOLEAN: 'true' | 'false';
EQ: '=';
LT: '<';
LE: '<=';
GT: '>';
GE: '>=';
NE: '<>'
NEWLINE: '\r'? '\n';2. 语法规则
语法规则可以是一条单独的规则,也可由多条子规则组成。规则通过 | 划分为多条子规则,每个子规则是一条可选的语义。
语法文件须至少包含一条规则——规则集合不能为空。文件的第一条规则很特殊,是语法解析树的根节点。由于每个规则都对应解析器类的一个方法,因此根节点规则通常用作api调用的入口。
parser grammar Test;
options { tokenVocab=Common; }
func: funcExpr EOF; // 第一条规则
...String input = "funcTest()";
Common source = new Common(new ANTLRInputStream(input));
CommonTokenStream stream = new CommonTokenStream(source);
Test parser = new Test(stream);
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(new MyListener(), parser.func()); // 遍历时从根节点开始语法规则格式如下(规则名及子规则语句后面可接指令或动作,但不是必须的)
rule [command]: subRule1 -> command or action
| subRule2 -> command or action
| ...
| subRuleN -> command or action;
下面的例子是Javascript对象访问操作的简单规则(本例只用于演示,实际解析规则要复杂的多),例子中的 attribute 就是一条包含多个分支的语法规则。
expr : ID attribute EOF;
attribute : DOT ID // obj.attribute
| LS_BRACKET SEQ RS_BRACKET // obj['name']
| LS_BRACKET ID RS_BRACKET // obj[variableName]
;
DOT : '.';
LS_BRACKET : '[';
RS_BRACKET : ']';
SEQ : '\'' ID '\'';
ID : [a-zA-Z_][a-zA-Z0-9_]*;
SPACE : [ \t\r\n]+ -> skip;2. 左递归的限制
左递归是指产生式规则中,产生式的左侧直接或间接地引用了自身。在语法分析中,左递归可能导致无限循环和栈溢出等问题,因此需要进行消除或转换。
Antlr支持消除直接左递归,但无法消除间接左递归,这意味不允许采用类似下面的设置方式来描述规则:
expr : expo ;
expo : expr '^'<assoc=right> expr ; // 错误的用法包含左递归的语法应至少存在一个不包含自身的分支。
operation : expr EOF;
expr : <assoc=right> expr '^' expr
| expr '*' expr
| expr '/' expr
| expr '+' expr
| expr '-' expr
| INT // 如果去掉这个分支就会报错
;
INT : [1-9][0-9]*;3. 优先级
Antlr词法分析器是从上向下标记输入,分析器总是尝试匹配先出现的规则,因此排在前面的规则比排在后面的规则具有更高的优先级。
词法规则优先级低于语法规则,混合型规则文件中,无论词法规则写在哪里,编译时都会重排到所有语法规则之后。
规则内部的子规则匹配也符合从上向下的规律,这意味着排在前面的子规则比后面的子规则有更高的优先级。当同一个子规则出现多次,可以用过左(右)结合指令来控制结合运算的方式:
expr: <assoc=right> expr '^' expr // 右结合
| <assoc=left> expr '*' expr // 左结合
| <assoc=left> expr '/' expr // 左结合
| <assoc=left> expr '+' expr // 左结合
| <assoc=left> expr '-' expr // 左结合
| INT
;
...上例中的<assoc=xxx>即结合指令。从例子中可以看出,^运算具备最高的优先级,乘除运算紧随其后,加减运算的优先级最低。相同类型的(加/减/乘/除)操作采用左结合律——即从左向右计算,^运算采用右结合率,即从右向左计算。
4. 断言
断言用于判断规则是否满足运行环境下的特定条件,如果当前环境断言判断为真,该规则(或分支)有效,否则无效。断言应放置在规则或分支内容的前面。
断言的格式如下:
rule: { ... }? expression; // ... 即目标语言的代码块
下面是验证输入是否支持接口中default方法(JDK8新特性)的例子
grammar Test;
@parser::members {
private int javaVersion = 8;
public void setJavaVersion(int version) {
this.javaVersion = version;
}
}
intlfunc : defaultmodifier? returntype ID '(' ID? (',' ID)* ')' ';';
defaultmodifier : { this.javaVersion >= 8 }? DEFAULT;
returntype : VOID | ID;
DEFAULT : 'default';
VOID : 'void';
ID : [a-zA-Z][a-zA-Z0-9_]*;
WS : [ \r\t\n]+ -> skip;测试代码如下:
String input = "default void test();";
TestLexer source = new TestLexer(new ANTLRInputStream(input));
TokenStream stream = new CommonTokenStream(source);
TestParser parser = new TestParser(stream);
parser.setJavaVersion(8); // 此处设置JDK版本
ParseTreeWalker walker = new ParseTreeWalker();
MyTestListener listener = new MyTestListener();
walker.walk(listener, parser.intlfunc());上例中如果将javaVersion设置为7,则解析抛出异常,因为此时intlfunc规则已经无效了,解析器在尝试匹配其它规则时未找到可匹配的规则。
5. 标签
Antlr通过标签区分规则的各个分支,这些标记的作用表现在自动生成的编译器代码中,编译器会为每一个子规则单独创建以标签名命名的方法。规则中的分支要么全部添加标签,要么都不添加标签。
标签的格式如下:
rule: rule1 # tag1
| rule2 # tag2
| rule3 # tag3
;
下面是SQL查询语句解析的一个例子(Select 关键字后面所接查询内容的解析)
selectElement
: fullId DOT STAR #selectStarElement // select table.*
| fullColumnName (AS? uid)? #selectColumnElement // select table.field as f1
| functionCall (AS? uid)? #selectFunctionElement // select sum(table.field)
| (LOCAL_ID VAR_ASSIGN)? expression (AS? uid)? #selectExpressionElement // select table.field1 + table.field2
;
public interface SQLParseListener extends ParseTreeListener {
...
void enterSelectElement(SQLParse.SelectElementContext ctx);
void exitSelectElement(SQLParse.SelectElementContext ctx);
// 规则中添加标签后,解析类会多出下列方法,每个标签对应一组出入方法
void enterSelectStarElement(SQLParse.SelectStarElementContext ctx);
void exitSelectStarElement(SQLParse.SelectStarElementContext ctx);
void enterSelectColumnElement(SQLParse.SelectColumnElementContext ctx);
void exitSelectColumnElement(SQLParse.SelectColumnElementContext ctx);
void enterSelectFunctionElement(SQLParse.SelectFunctionElementContext ctx);
void exitSelectFunctionElement(SQLParse.SelectFunctionElementContext ctx);
void enterSelectExpressionElement(SQLParse.SelectExpressionElementContext ctx);
void exitSelectExpressionElement(SQLParse.SelectExpressionElementContext ctx);
}上例可以看出,标签改变了监听器类的结构,开发人员可以直接在标签对应的出入方法中编写逻辑。如果没有使用标签,那就不得不在父规则中做繁琐的分支判断和内置上下文环境取值处理。标签使类结构层次更清晰,并显著提升了开发效率。
6. 动作
动作是一段由 { } 包裹的代码,就像是嵌在规则文件中的脚本,当Antlr编译规则文件时,这些内嵌的脚本会被解析并移植到源码文件中,从而增强或改变最终的编译结果。可以这样理解,动作就是将本可以通过人工编码实现的代码移到了规则文件中。
动作的正确执行和编译目标语言紧密相关,尽管官方文档支持在非Java类语言环境中使用诸如header,member, returns等动作,但必须谨慎使用和仔细验证。笔者建议尽可能只在Java语言环境中使用动作。
* 具名动作
Antlr定义了两种具名动作:header、member,具名动作顾名思义就是在描述内容 { } 前方设置有名称的动作。header在生成的识别程序类定义之前插入代码,member在识别程序类定义之中插入代码。
混合型规则文件中,具名动作前面可以用 lexer:: 或 parser:: 来修饰,代表是否插入编译后的词法解析类(XxxLexer)和语法解析类(XxxParser)代码中,如果未添加修饰则词法解析类和语法解析类都会插入这段代码。
下面是具名动作使用的例子
@parser::header { // 这段代码插入语法解析类
import net.test.antlr.model;
}
@lexer::header { // 这段代码插入词法解析类
import com.hik.Digits;
}
@parser::members {
boolean valid = true; // 定义类变量, 插入语法解析类中
}注:未加修饰的 header、member 指令只能在规则文件中出现一次,且不能再出现带修饰的同名指令。如规则中只存在带修饰的指令,则当前修饰符 + 同名指令只能出现一次。
* 规则嵌入动作
这一类的动作通常紧跟在规则或分支的末尾,但必须在规则结尾分号或下一个分支分隔符 | 之前),如下例所示:
decl: type ID ';' { System.out.println("found a decl"); } ;
type: 'int' { System.out.println("integer type"); }
| 'float' ;
ID : [a-zA-Z_][a-zA-Z0-9_]*;编译后的语法解析类代码如下,可以看到类中对应的解析方法已经嵌入了动作代码块
...
public final DeclContext decl() throws RecognitionException {
DeclContext _localctx = new DeclContext(_ctx, getState());
enterRule(_localctx, 0, RULE_decl);
try {
enterOuterAlt(_localctx, 1);
{
setState(4);
type();
setState(5);
match(ID);
setState(6);
match(T__0);
System.out.println("found a decl"); // 解析类中嵌入的代码
}
}
catch (RecognitionException re) {
_localctx.exception = re;
_errHandler.reportError(this, re);
_errHandler.recover(this, re);
}
finally {
exitRule();
}
return _localctx;
}* 动作及属性配合使用
配合member、returns指令和动作设定,可以为解析类(XxxParser)或上下文类(XxxParserContext)定义变量并修改其值。
下面是一个例子,目的是获取方法定义嵌套层次的深度
grammar Common;
@parser::members {
public int layer = 0; // 定义一个类变量(总层数)
}
expr : def
| func ';'
;
def returns [ String currentLayer ] // 定义一个上下文环境变量(当前层数)
: func '{' expr? '}' {
layer++; // 每次进入func则总层数 + 1
$currentLayer = layer; // 赋值记录当前层数
};
func : ID '(' ID? (',' ID)* ')' ;
ID : [a-zA-Z_][a-zA-Z0-9_]*;
SPACE : [ \t\r\n]+ -> skip;
NEWLINE : '\r'? '\n';测试类如下:
package net.kebin.antlr;
import org.antlr.v4.runtime.ANTLRInputStream;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTreeWalker;
import net.coffen.router.antlr4.CommonParser.DefContext;
public class MyListener extends CommonBaseListener {
@Override
public void exitDef(DefContext ctx) {
System.out.println("当前层数为: " + ctx.currentLayer);
}
public static void main(String[] args) {
String input = "outer(x,y) { \r\n"
+ " medium() { \r\n"
+ " inner(y, u) { \r\n"
+ " } \r\n"
+ " } \r\n"
+ " }";
CommonLexer source = new CommonLexer(new ANTLRInputStream(input));
CommonTokenStream stream = new CommonTokenStream(source);
CommonParser parser = new CommonParser(stream);
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(new MyListener(), parser.expr());
System.out.println("总层数为: " + parser.layer);
}
}测试结果如下
当前层数为: 1
当前层数为: 2
当前层数为: 3
总层数为: 3
上例可以看出,@member 为解析类增加了公共类变量layer, returns 为DefContext增加了变量currentLayer,并在语法树遍历中对这两个变量进行了一定的处理。定义公共变量是危险的操作,本例仅作为演示,实际开发中应注意访问安全等问题。
* 异常处理动作
配合catch指令,可以为规则 / 分支添加异常处理逻辑
@parser::header {
import org.antlr.v4.runtime.misc.ParseCancellationException;
}
...
expr : alternative1
| alternative2 { // 为规则分支添加异常处理代码
if (...) {
throw new ParseCancellationException();
}
}
| alternative3
;
...
alternative3 : value;
catch [ Exception e ] { // 为规则添加异常捕获和处理代码
throw new ParseCancellationException(e);
}
...注:规则文件中抛出的异常应当是RuntimeException的子类(上例中 ParseCancellationException就是RuntimeException的子类),否则源文件虽然能生成,但编译时会报未处理异常的错误提示。
7. 注释
Antlr4的注释和Java非常相似,也分为多行注释和单行注释。
/*
* 这是多行注释
*/
// 这是单行注释
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)