各类注意力机制详解
注意力机制是一种在神经网络的设计中被广泛使用的技术。在认知科学中,当信息输入规模超过大脑的处理能力时,人类倾向于有选择地将注意力集中于感兴趣的信息,并忽略其他信息。本文将详细介绍并梳理目前存在的各类注意力机制的原理,方便按需使用。
前言
注意力机制是一种在神经网络的设计中被广泛使用的技术。在认知科学中,当信息输入规模超过大脑的处理能力时,人类倾向于有选择地将注意力集中于感兴趣的信息,并忽略其他信息。
本文将详细介绍并梳理目前存在的各类注意力机制的原理,方便按需使用。
一、注意力机制概述
注意力机制可以增强部分神经网络输入数据中的权重,同时减弱其他部分的权重,从而使得神经网络能够关注数据中的关键部分。
1.1 计算过程
简单来说,注意力机制采用三元组 的形式表示,它们分别代表查询向量、键向量和值向量。注意力机制的计算过程可以分为两个步骤:
(1)首先使用查询向量和键向量计算相关性权重;
(2)使用相关性权重和值向量计算注意力输出值,如下图所示:
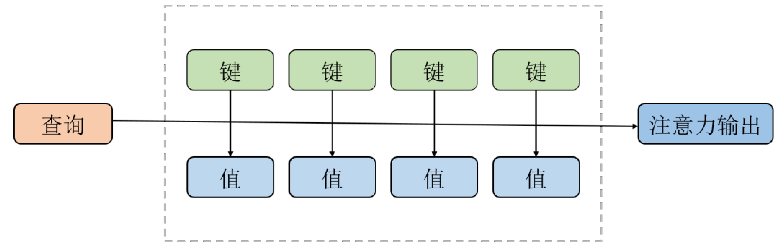
具体而言:
(1)首先通过相关性计算函数 和softmax标准化,将查询向量
和一组键值对
进行运算,计算出注意力权重
;
![]()
(2)使用注意力权重 对值
加权求和得到注意力输出值。
![]()
1.2 相关性计算函数
相关性计算函数 可分为五种类型的模型,即点积模型,缩放点积模型,双线性模型,拼接模型和加性模型:
1.2.1 点积模型
![]()
1.2.2 缩放点积模型
![]()
其中, 表示键向量
的维度。
1.2.3 双线性模型
![]()
1.2.4 拼接模型
![]()
1.2.5 加性模型
![]()
值得注意的是,在注意力机制的计算过程中,通常将向量进行批量化操作,将多个查询向量 和键向量
组成矩阵
和
进行并行化运算,以提高计算效率。
二、不同注意力机制分析
本文按照不同的分类体系,将注意力机制按结构特性和应用场景分别分为3类和5类:
2.1 按结构特性分类
按结构特性分类,注意力机制主要分为自注意力、交叉注意力、层次注意力和多头注意力:
2.1.1 自注意力
在自注意力机制中,Q、K和V来自同一模态。
自注意力机制的基本思想是,在处理序列数据时,每个元素都可以与序列中的其他元素建立关联,而不仅仅是依赖于相邻位置的元素。它通过计算元素之间的相对重要性来自适应地捕捉元素之间的长程依赖关系。
具体而言,对于序列中的每个元素,自注意力机制计算其与其他元素之间的相似度,并将这些相似度归一化为注意力权重。然后,通过将每个元素与对应的注意力权重进行加权求和,可以得到自注意力机制的输出。
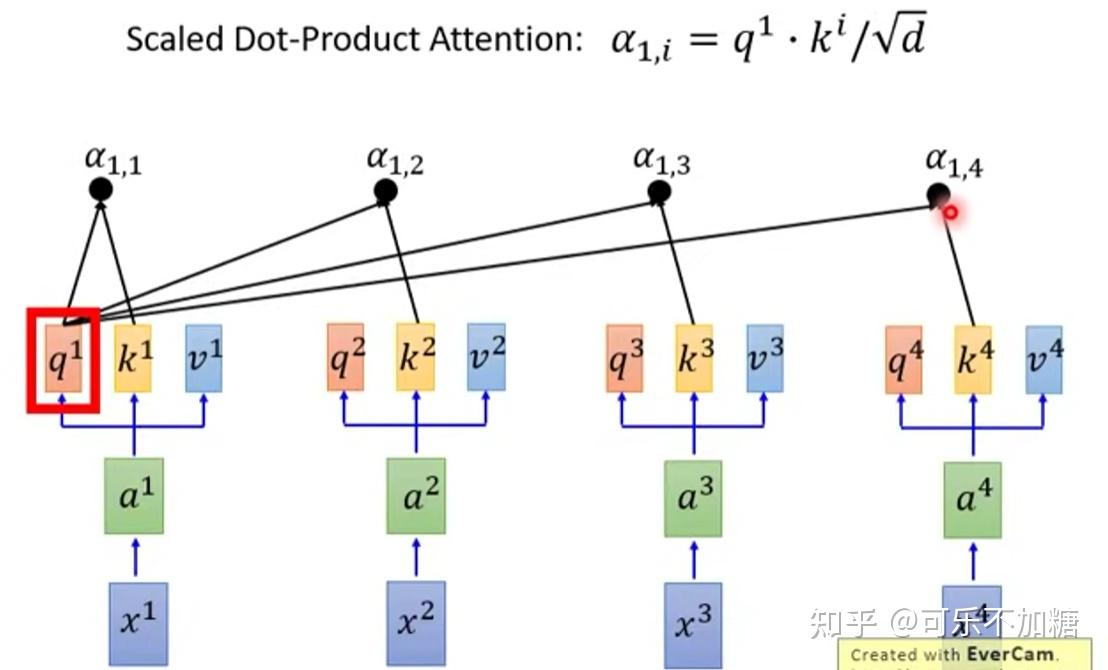
2.1.2 交叉注意力
在交叉注意力中,Q来自一个模态、K和V来自同一模态。
顾名思义,是一种“交叉”的注意力机制。与自注意力不同,交叉注意力是让两个不同的序列(或者数据来源)之间建立关注关系。换句话说,交叉注意力的核心在于:它允许一个序列(称为Query,查询)去关注另一个序列(称为 Key 和 Value,键和值),从而实现信息的融合。
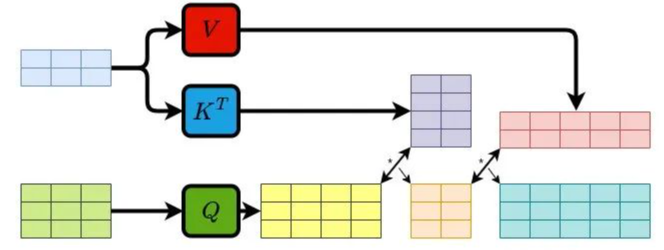
2.1.3 多头注意力
整体示意图如下:
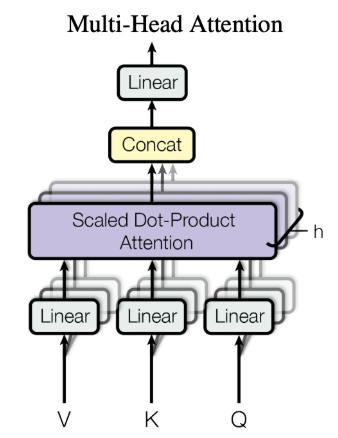
可以看出,多头注意力是由 个自注意力堆叠而成的。这
个自注意力的权重矩阵
、
和
不相同,将输入
分别传入
个自注意力中,然后分别计算得出
。下图是
的情况,此时会得出8个输出矩阵:
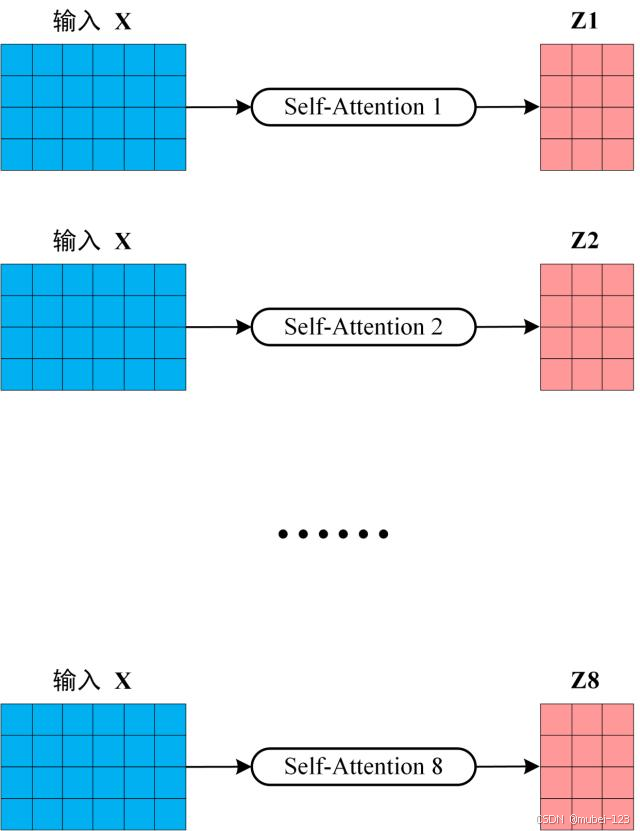
在得到8个输出矩阵后,多头注意力它们拼接在一起(Concat),然后传入一个Linear层,得到最终的输出矩阵
:
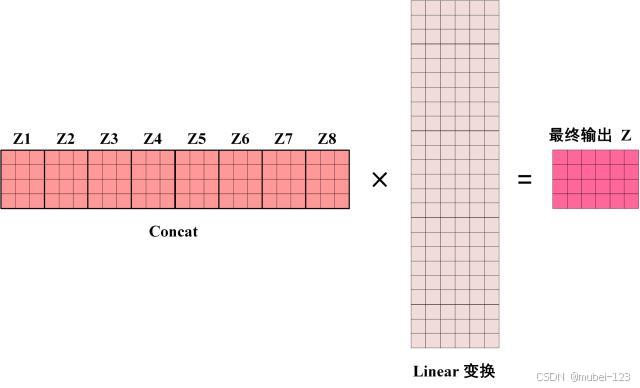
2.2 按应用场景分类
按照应用场景分类,将注意力机制主要分为位置感知注意力、空间注意力、通道注意力、空间-通道注意力和门控多模态注意力:
2.2.1 位置感知注意力
位置注意力机制通过编码位置信息,提升模型对序列结构的理解能力,这对于理解序列数据中的依赖关系和模式至关重要。具体实现方式包括位置编码和显式位置注意力机制:
(1)位置编码( 绝对位置增强型注意力)
位置编码通过为序列中的每个位置附加一个唯一的向量,这些向量携带了位置信息,并与输入的元素特征相加或拼接(仅在输入层相加)。在 Transformer 模型中,位置编码通常是通过正弦和余弦函数周期性生成的,确保了不同位置的向量在不同维度上有不同的频率。
def positional_encoding(max_seq_len, emb_dim):
position = tf.range(max_seq_len)[:, tf.newaxis]
div_term = tf.exp(tf.range(0, emb_dim, 2) * -(math.log(10000.0) / emb_dim))
PE = tf.zeros((max_seq_len, emb_dim))
PE[:, 0::2] = tf.sin(position * div_term)
PE[:, 1::2] = tf.cos(position * div_term)
return pos_encoding(2)显式位置注意力机制(相对位置编码注意力)
显式位置注意力机制设计一个独立的注意力机制,直接针对位置信息进行计算。可以为每个位置生成位置Key向量,计算相对位置注意力得分后与内容注意力得分一起参与注意力的计算。
import torch
import torch.nn as nn
class RelativePositionAttention(nn.Module):
def __init__(self, d_model, num_heads, max_rel_dist=4):
super().__init__()
self.d_head = d_model // num_heads
self.num_heads = num_heads
self.max_rel_dist = max_rel_dist
# 相对位置嵌入
self.rel_emb = nn.Embedding(2*max_rel_dist+1, self.d_head)
# 线性变换
self.qkv = nn.Linear(d_model, 3*d_model)
self.out = nn.Linear(d_model, d_model)
def forward(self, x):
B, N, _ = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.d_head)
q, k, v = qkv.unbind(2) # [B, N, H, D]
# 内容注意力得分
attn_content = torch.einsum('bnhd,bmhd->bhnm', q, k) # [B, H, N, N]
# 相对位置偏置
pos_ids = torch.arange(N, device=x.device)
rel_pos = pos_ids[:, None] - pos_ids[None, :] # [N, N]
rel_pos = torch.clamp(rel_pos, -self.max_rel_dist, self.max_rel_dist)
rel_pos += self.max_rel_dist # 转换为非负索引
rel_emb = self.rel_emb(rel_pos) # [N, N, D]
attn_bias = torch.einsum('bnhd,nmd->bhnm', q, rel_emb) # [B, H, N, N]
# 合并得分
attn = (attn_content + attn_bias) / (self.d_head ** 0.5)
attn = attn.softmax(dim=-1)
# 输出投影
out = torch.einsum('bhnm,bmhd->bnhd', attn, v)
out = self.out(out.reshape(B, N, -1))
return out2.2.2 空间注意力
空间注意力机制旨在通过引入注意力模块,使模型能够自适应地学习不同区域的注意力权重,这样,模型可以更加关注重要的图像区域,而忽略不重要的区域。
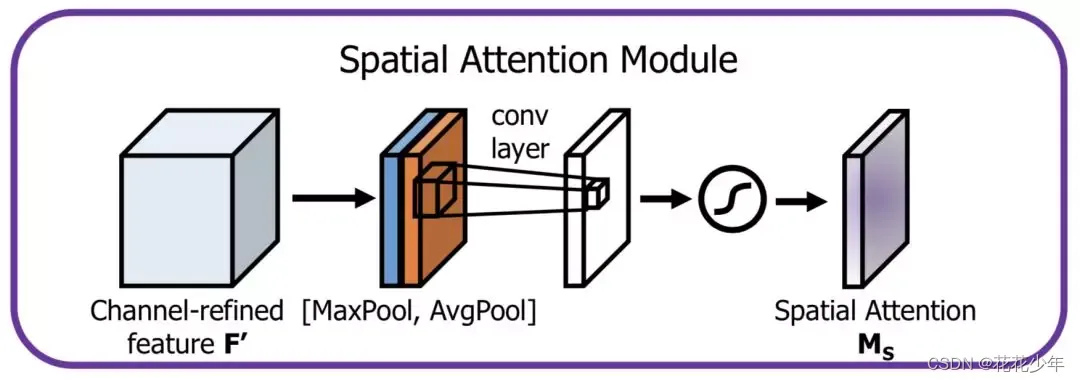
空间注意力的思路流程是:
(1)首先,对一个尺寸为 的输入特征图
进行通道维度的全局最大池化和全局平均池化,得到两个
的特征图(在通道维度进行池化,压缩通道大小,便于后面学习空间的特征);
(2)然后,将全局最大池化和全局平均池化的结果,按照通道拼接(concat),得到特征图尺寸为 ;
(3)最后,对拼接的结果进行的卷积操作,得到尺寸为 的特征图,接着通过Sigmoid激活函数 ,得到空间注意力权重矩阵
;
经过以上计算后,将形状为 的权重
和原始特征图
进行点乘 ,以得到加权后的特征图。
2.2.3 通道注意力
顾名思义,通道注意力机制是通过计算每个通道channel的重要性程度;因此,常常被用在卷积神经网络里面。
2.2.3.1 SENet
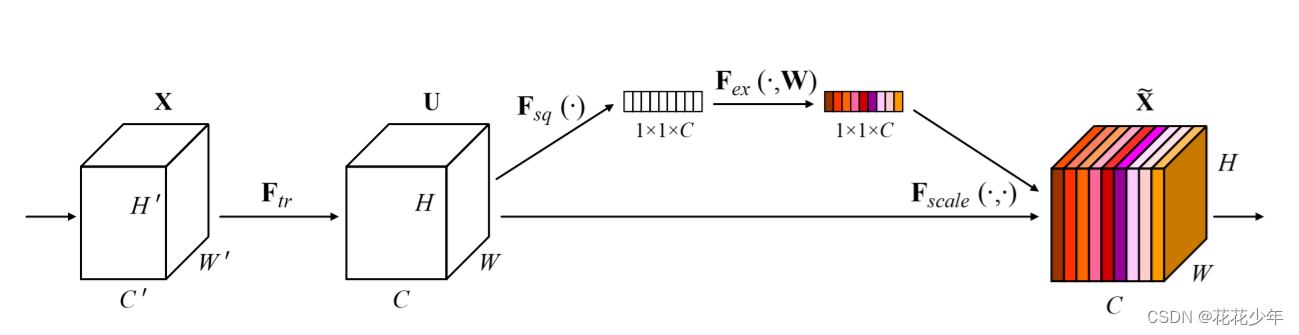
数据 经过卷积操作后,得到
的形状为
。此后,SENet引入了一个Squeeze模块
和一个Excitation模块
:
(1) 通过全局平均池化操作将每个通道的特征图转化为一个标量值,得到一个
的矩阵;
(2) 通过激活函数(如sigmoid或ReLU)对
的矩阵进行操作(其中W 表示激活函数),得到带有颜色的
的矩阵,表示每个通道的权重;
(3) 将
的权重和原始特征图
进行点乘 ,以得到加权后的特征图。
2.2.3.2 CAM
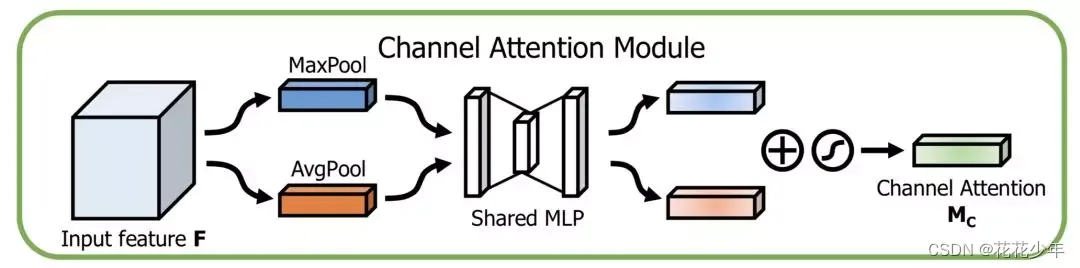
CAM的思路流程是:
(1)首先,对一个尺寸为 的输入特征图
进行空间维度的全局最大池化和全局平均池化,得到两个
的特征图(在空间维度进行池化,压缩空间尺寸,便于后面学习通道的特征);
(2)然后,将全局最大池化和全局平均池化的结果,分别送入一个共享的多层感知机(MLP)中学习,得到两个 的特征图。MLP的第一层神经元个数为
,激活函数为
,第二层神经元个数为
(基于MLP学习通道维度的特征,和各个通道的重要性);
(3)最后,将MLP输出的结果进行Add操作(形状依旧为 ),接着经过 Sigmoid 激活函数,最终得到通道注意力权重矩阵
。
经过以上计算后,将形状为 的权重
和原始特征图
进行点乘 ,以得到加权后的特征图。
2.2.4 空间-通道注意力
当同时考虑空间注意力和通道注意力,即CBAM模型时:
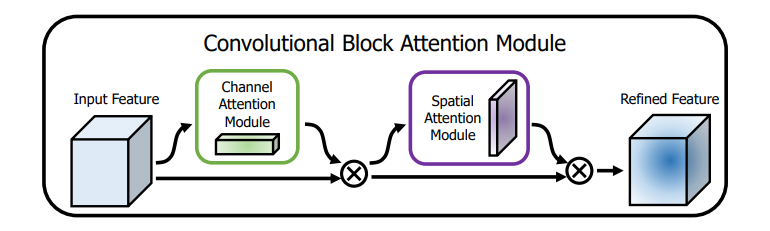
其中:
(1)CBAM中通道注意力使用全局平均池化和全局最大池化分别来获取每个通道的全局统计信息,并通过两层全连接层来学习通道的权重。然后,会将处理后产生的两个结果进行Add相加,通过使用Sigmoid函数将权重归一化到0到1之间,对每个通道进行缩放。最后,将缩放后的通道特征与原始特征相乘,以产生具有增强通道重要性的特征;
(2)CBAM中空间注意力模块是使用最大池化和平均池化来获取每个空间位置的最大值和平均值。具体地说,由于卷积之后会产生多个通道,CBAM中空间注意力会在每一个特征点的通道上进行最大池化和平均池化操作,得到两个matrix后,将两个matrix进行拼接,并通过一个卷积层和Sigmoid函数来学习每个空间位置的权重。最后,将权重应用于特征图上的每个空间位置,以产生具有增强空间重要性的特征。
2.2.5 门控多模态注意力
门控多模态注意力(Gated Multimodal Attention)是一种通过动态门控机制调节不同模态信息融合权重的注意力变体,其核心目标是自适应地选择关键模态特征并抑制噪声干扰。
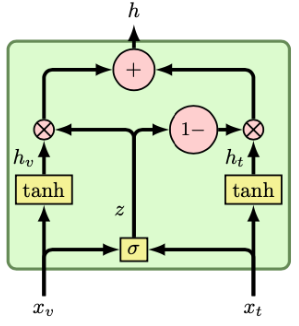
具体实现代码如下:
class GatedMultimodalLayer(nn.Module):
"""
Gated Multimodal Layer based on 'Gated multimodal networks,
Arevalo1 et al.' (https://arxiv.org/abs/1702.01992)
"""
def __init__(self, size_in1, size_in2, size_out=16):
super(GatedMultimodalLayer, self).__init__()
self.size_in1, self.size_in2, self.size_out = size_in1, size_in2, size_out
self.hidden1 = nn.Linear(size_in1, size_out, bias=False)
self.hidden2 = nn.Linear(size_in2, size_out, bias=False)
self.hidden_sigmoid = nn.Linear(size_out*2, 1, bias=False)
# Activation functions
self.tanh_f = nn.Tanh()
self.sigmoid_f = nn.Sigmoid()
def forward(self, x1, x2):
#编码两个模态的特征(根据特定的模态对内部表示特征进行编码)
h1 = self.tanh_f(self.hidden1(x1))
h2 = self.tanh_f(self.hidden1(x2))
#拼接特征生成门控
x = th.cat((h1, h2), dim=1)
z = self.sigmoid_f(self.hidden_sigmoid(x))
#加权融合
fused = z.view(z.size()[0],1)*h1 + (1-z).view(z.size()[0],1)*h2
return fused
三、总结
注意力机制已成为现代深度学习的核心组件,其演进呈现出"基础形式→领域优化→理论突破"的发展路径。因果注意力、哈希注意力等不同的前沿注意力正在发展......

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)