今日头条爬虫实战(代码+知识点讲解)
网页可以分为三大部分 —— HTML、CSS 和 JavaScript。如果把网页比作一个人的话,HTML 相当于骨架,JavaScript 相当于肌肉,CSS 相当于皮肤,三者结合起来才能形成一个完善的网页。——崔庆才老师HTML(HyperText Markup Language) 是用来描述网页的一种语言,网页包括文字、按钮、图片和视频等各种复杂的元素,其基础架构就是 HTML。不同类型的元
目录
3.1 什么是html,什么构成了网页(不想看就直接跳过吧)
1. 声明
鄙人RUC大二萌新一枚,初学爬虫,900多页的爬虫实战仅仅啃了100页,比起久经科研战场、一爬就是两个月的大佬们还很粗糙,有模糊、不对或者更好的思路尽管指出。
本文代码基于Jupyter+Anaconda,本人非常推荐的一种很方便的写Python的方式,可根据不同项目的需求使用不同虚拟环境(当然你在哪里写都行,并不影响)。
本文是结合知识点+代码讲解的方式,各位如果只想要代码不想听我啰嗦的话,直接赞(粘)也行,看第5大点以后的代码就行,如果想深入了解一下爬虫的话不妨一看,也是不错的教学案例。
部分内容吸取于《Python3 爬虫教程》by崔庆才
2. 引子
同学有个小创项目,需要爬取今日头条的多条新闻,包括标题、时间、发布者、正文、点赞数、评论数(各位按需自取就行),我一听来了劲,正好练下手。
先展示成果:

爬取今日头条是个很常规的数据来源方式,网上想必有很多现成代码吧,想必copy下来改改就行,但是别人可不是吃素的,因为反爬机制的升级,很多代码都已经失效了,不如自己整。
话不多说,头条酱我来了!
3. html语言“地形考察”
这是爬虫里很重要很关键的一步,即通过查看网页源代码思考自己应该怎么爬,怎么写代码。
3.1 什么是html,什么构成了网页(不想看就直接跳过吧)
网页可以分为三大部分 —— HTML、CSS 和 JavaScript。如果把网页比作一个人的话,HTML 相当于骨架,JavaScript 相当于肌肉,CSS 相当于皮肤,三者结合起来才能形成一个完善的网页。 ——崔庆才老师
HTML(HyperText Markup Language) 是用来描述网页的一种语言,网页包括文字、按钮、图片和视频等各种复杂的元素,其基础架构就是 HTML。不同类型的元素通过不同类型的标签来表示,如图片用
img标签表示,视频用video标签表示,段落用p标签表示,它们之间的布局又常通过布局标签div嵌套组合而成,各种标签通过不同的排列和嵌套才形成了网页的框架。
我们打开头条首页网址 https://www.toutiao.com/(无需登录),按F12 快捷键打开浏览器开发者工具,切换到 Elements 面板就可以看到今日头条对应的 HTML,你可以将其看作由一个个节点组成。
通过不断点击每行开头的白色小三角可以逐步找到自己所需内容所在节点,我们找到了首页一则新闻的标题对应的代码。
3.2 确定基本思路
观察这行代码我们发现:

href后面的那串网址就是每则新闻的网址,因此基本思路确定了:
首先爬取头条首页代码,提取每则新闻的网址,再进入具体网址页爬取时间、标题、正文、点赞数、评论数。
4. 初步尝试(老规矩,不想看跳过就行)
尝试每个爬虫新手都会使用的request工具进行爬取。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
url = "https://www.toutiao.com/"
r = requests.get(url,headers=headers)
print(r.text)其中,headers中User-Agent字段可以模拟正常浏览器访问,为什么要设置这个呢?
这是为了避免被识别为爬虫,很多网站会对访问来源进行检测,如果发现请求来自于一个没有正常
User-Agent的客户端,就会将其判定为爬虫程序。一旦被识别为爬虫,网站可能会采取反爬措施,通过设置一个看起来像正常浏览器的User-Agent,可以让服务器认为请求是来自于真实用户使用的浏览器,从而减少被反爬机制拦截的可能性。
你应该能跑出来一个结果,那这个结果是否是我们想要的呢?你不妨将其复制粘贴下来,ctrl+f查找一下随便一则新闻标题中的某个词,发现啥都查不到,这是为什么呢?
前面我们提到了:网页可以分为三大部分 —— HTML、CSS 和 JavaScript。如果把网页比作一个人的话,HTML 相当于骨架,JavaScript 相当于肌肉,CSS 相当于皮肤,三者结合起来才能形成一个完善的网页。而
requests获取的是服务器最初返回的静态 HTML 代码,不包含经过 JavaScript 动态渲染后生成的内容。对于像今日头条这样的动态网页,很多内容是通过 JavaScript 在浏览器中加载和渲染的,所以使用requests得到的结果可能只是一个基础的页面框架,缺少动态加载的文章列表、广告等内容。
因此我们需要采用一个更加强大的工具——selenium。
5. selenium爬取(可以开粘了)
selenium是一个自动化测试工具,它模拟真实的浏览器行为。当使用
driver.get(url)时,selenium会启动一个浏览器实例,并在浏览器中打开指定的 URL。浏览器会完整地处理页面,包括解析 HTML、加载 CSS 样式和执行 JavaScript 代码。在执行 JavaScript 代码的过程中,页面会动态地加载和更新内容,比如通过 AJAX 请求获取更多的文章数据并插入到页面中。因此,selenium得到的结果更接近在浏览器中实际看到的页面。
代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
url = "https://www.toutiao.com/"
options = Options()#创建一个 Options 类的实例 options,用于配置 Chrome 浏览器的启动选项。
options.add_argument("--headless") # 无界面模式
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36") #这里模拟了 Chrome 120 浏览器在 Windows 10 系统上的请求,避免被网站识别为爬虫而限制访问。
driver = webdriver.Chrome(options=options)#创建一个 webdriver.Chrome 类的实例 driver,并将之前配置好的 options 传递给它
driver.get(url)#传入之前定义的 url 变量
time.sleep(3) # 等待 JavaScript 执行
html = driver.page_source # 获取渲染后的HTML
driver.quit()#关闭 Chrome 浏览器实例并释放相关资源。
print(html)多等一小会,就能看到和浏览器上一样的代码了。
6. 基于正则表达式的网址提取
6.1正则表达式(不想听我啰嗦的直接粘,想学的大可一听)
6.1.1 什么是正则表达式呢?
正则表达式是处理字符串的强大工具,用于实现字符串的检索、替换、匹配和验证。
可以使用开源中国提供的正则表达式测试工具在线正则表达式测试进行探索和尝试。
6.1.2 常用的匹配机制
| \w | 匹配字母、数字及下划线 |
| \W | 匹配不是字母、数字及下划线的字符 |
| \d | 匹配任意数字,等价于 [0-9] |
| * | 匹配 0 个或多个表达式 |
| . | 匹配任意字符,除了换行符。 |
| () | 匹配括号内的表达式,也表示一个组 |
| \S | 匹配任意非空字符 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f] |
这里仅仅展示了部分常见方式,更多匹配方式请自行查找更多文献。
6.1.3 案例展示
比如有如下字符串:
Hello 123 World paradise_wujie
通过匹配模式:
Hello\s\d\d\d\s\w{5}
即可得到:
Hello 123 World
6.1.4 案例代码
我主要提一下会用到的search方法和findall方法
search在匹配时会扫描整个字符串,然后返回第一个成功匹配的结果。也就是说,正则表达式可以是字符串的一部分,在匹配时,search方法会依次扫描字符串,直到找到第一个符合规则的字符串,然后返回匹配内容,如果搜索完了还没有找到,就返回None。
search方法可以返回匹配正则表达式的第一个内容,但是如果想要获取匹配正则表达式的所有内容,那该怎么办呢?这时就要借助findall方法了。该方法会搜索整个字符串,然后返回匹配正则表达式的所有内容。
以这里的提取新闻网址为例:

href后面既是我们需要提取的网址,我们发现每个网址前面都有一段特有的'feed-card-article-l',我们完全可以在匹配模式中加入这行字符串提高匹配效率。同时,我们可以顺便把后面的新闻标题给提取出来。
那么匹配模式可以表示为:
"feed-card-article-l".*?href="(.*?)".*?aria*-label="(.*?)">
其中有个匹配方式很有意思:
.*?
这是万能匹配的非贪婪写法,。
.*是万能匹配的贪婪写法,其中.可以匹配任意字符(除换行符),*代表匹配前面的字符无限次,所以它们组合在一起就可以匹配任意字符了。有了它,我们就不用挨个字符匹配了。非贪婪匹配的写法是
.*?区别在于贪婪匹配是尽可能匹配多的字符,非贪婪匹配就是尽可能匹配少的字符。
比如字符串helloworld,如果我的匹配方式为\w{5}.* 那么结果就是helloworld;如果是\w{5}.*? 那么结果就是hello。
好了,终于讲完这一块了,我们可以展示代码了(你们可以粘了)。
6.2 提取网址代码展示(拿走拿走)
import re
results=re.findall('"feed-card-article-l".*?href="(.*?)".*?aria*-label="(.*?)">',html,re.S)
print(results)
for result in results:
print(result)
print(result[0],result[1])结果如下:

7.模拟页面滚动(重点哦)
爬完过后你可能会发现,诶,怎么只有几条新闻?
这是因为今日头条的首页,你必须不断向下滚动才会新的新闻出现,所以我们需要用代码模拟滚动,怎么实现呢?这时候就要请我们的迪老师和豆老师了。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
url = "https://www.toutiao.com/"
# 配置 Chrome 选项
options = Options()
options.add_argument("--headless")
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
# 创建 Chrome 浏览器实例
driver = webdriver.Chrome(options=options)
# 打开网页
driver.get(url)
# 等待页面加载
time.sleep(3)
# 定义最大滚动次数
max_scrolls = 10
# 循环滚动页面
for _ in range(max_scrolls):
# 执行 JavaScript 代码将页面滚动到最底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 等待新内容加载
time.sleep(2)
# 获取渲染后的 HTML
html = driver.page_source
# 关闭浏览器
driver.quit()
print(html)结果如下:
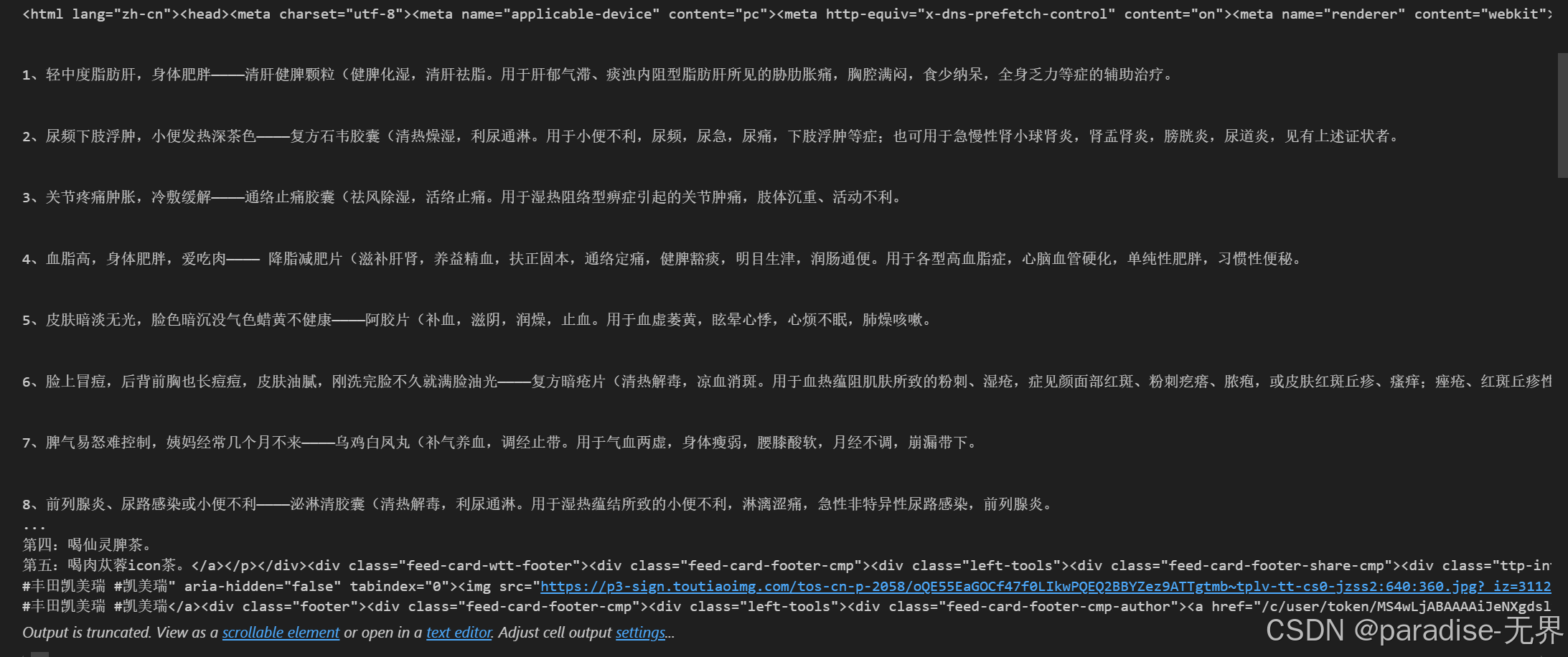
现在代码自动模拟了10次滚动,你也可以增加次数,多等一会就可以爬到更多新闻啦。
接下来再运行下6.2的代码即可。
8. 提取标题、时间、发布者、正文、点赞数、评论数
关于标题,时间,发布者,点赞数,评论数不再赘述,非常简单。
这里主要提一下关于正文的提取,我们随便提取两篇新闻,看一下正文的网页代码结构。

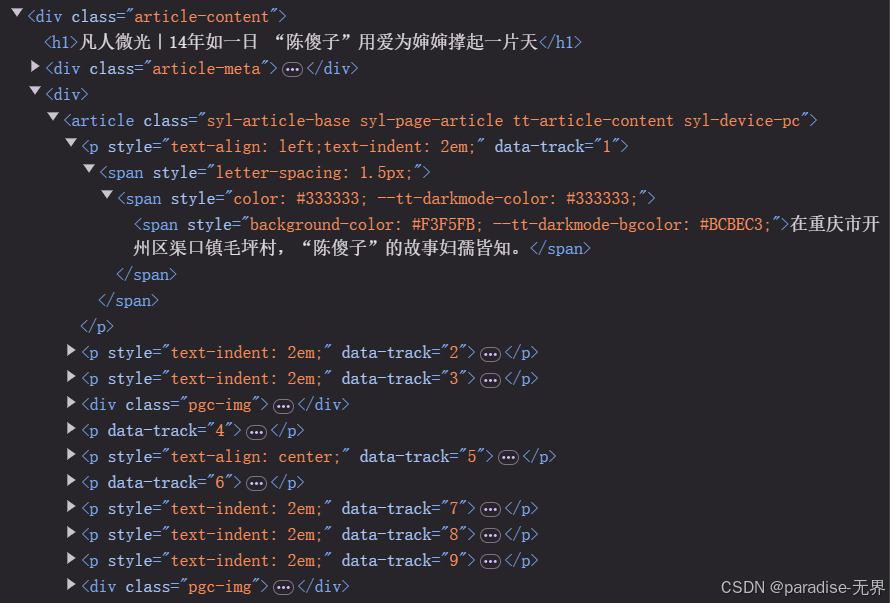
发现风格迥异,根本找不到一个通用的正则表达式进行提取,当然你可以通过专业文本提取库或者新闻专用解析库进行提取,但是如果想提取纯净的正文,这种方式远远不行。
这时候我们需要采取更强的工具——BeautifulSoup。
HTML 页面中通常包含
<script>和<style>标签,分别用于嵌入 JavaScript 代码和 CSS 样式。这些标签内的内容对于提取文本信息并无帮助,反而会干扰文本内容的获取。
BeautifulSoup的get_text()方法可以方便地从 HTML 文档中提取所有的文本内容。它会遍历 HTML 文档的树形结构,将所有标签内的文本信息提取出来并连接成一个字符串。这使得开发者无需手动编写复杂的代码来逐个查找和提取文本,大大简化了文本提取的过程。
为此我们可以撰写下面的函数:
def extract_content_with_bs(html):
soup = BeautifulSoup(html, 'html.parser')
# 移除脚本和样式标签
for script in soup(["script", "style"]):
script.extract()
# 提取文本
text = soup.get_text()
# 去除多余的空白字符
lines = (line.strip() for line in text.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
text = '\n'.join(chunk for chunk in chunks if chunk)
return text提取所有新闻完整代码如下(result是上面爬取首页再提取后的结果 )
import re
import time
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 定义一个函数来去除非法字符
def remove_illegal_characters(text):
ILLEGAL_CHARACTERS_RE = re.compile(r'[\000-\010]|[\013-\014]|[\01 6-\037]')
return ILLEGAL_CHARACTERS_RE.sub('', text)
data = []
for result in results:
url = result[0]
options = Options()
options.add_argument("--headless") # 无界面模式
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(3) # 等待 JavaScript 执行
html = driver.page_source # 获取渲染后的 HTML
driver.quit()
# 提取标题
title = re.search('article-content.*?<h1>(.*?)</h1>', html, re.S)
# 提取时间、发布者
ans = re.search('article-meta.*?<span>(.*?)</span>.*?nofollow">(.*?)</a>', html, re.S)
# 提取点赞数、评论数
num = re.search('工具栏.*?点赞(.*?)".*?打开评论面板,(.*?)评论', html, re.S)
# 提取正文
match = re.search(r'syl-device-pc">(.*?)</article>', html, re.S)
if match:
# 从匹配对象中提取实际的 HTML 内容
article_html = match.group(1)
else:
article_html = ""
def extract_content_with_bs(html):
soup = BeautifulSoup(html, 'html.parser')
# 移除脚本和样式标签
for script in soup(["script", "style"]):
script.extract()
# 提取文本
text = soup.get_text()
# 去除多余的空白字符
lines = (line.strip() for line in text.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
text = '\n'.join(chunk for chunk in chunks if chunk)
return text
content = extract_content_with_bs(article_html)
# 去除非法字符
title_text = title.group(1) if title else ""
time_text = ans.group(1) if ans else ""
publisher_text = ans.group(2) if ans else ""
like_count_text = num.group(1) if num else ""
comment_count_text = num.group(2) if num else ""
title_text = remove_illegal_characters(title_text)
time_text = remove_illegal_characters(time_text)
publisher_text = remove_illegal_characters(publisher_text)
like_count_text = remove_illegal_characters(like_count_text)
comment_count_text = remove_illegal_characters(comment_count_text)
content = remove_illegal_characters(content)
data.append({
"标题": title_text,
"时间": time_text,
"发布者": publisher_text,
"点赞数": like_count_text,
"评论数": comment_count_text,
"正文": content
})
df = pd.DataFrame(data)
df.to_excel("result.xlsx", index=False)
print("数据已保存到 result.xlsx")
结果如下:
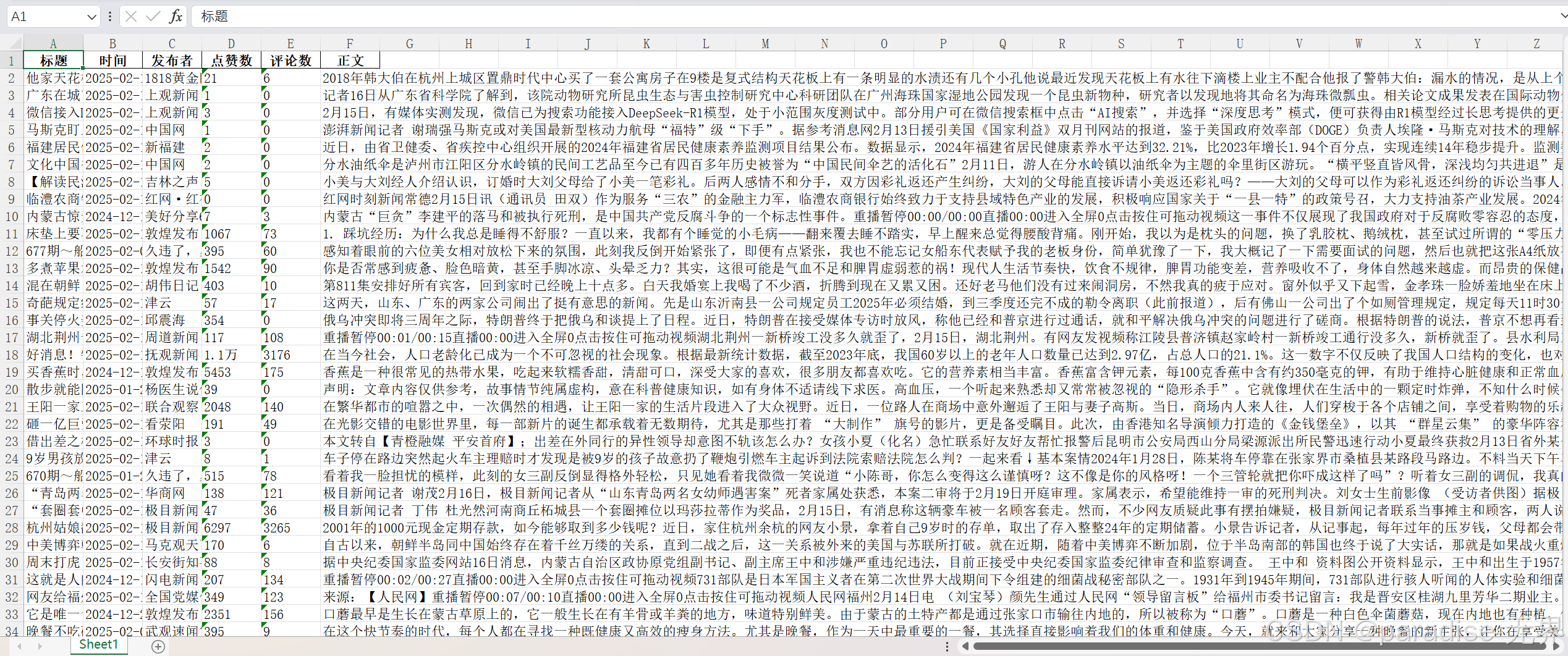
注意写入excel函数的时候,可能会出现IllegalCharacterError报错,这是因为要写入 Excel 文件的数据中包含了 Excel 不允许的非法字符。Excel 不允许在单元格中包含一些特定的控制字符,如 ASCII 码为 0 - 31 的字符。因此我加上了一个remove_illegal_characters函数。
9.结束语
代码和讲解已经全部放在正文啦,只需要大家按顺序拼凑一下(因为我确实不想大家copy了代码就走人所以没放整块完整代码)。有什么问题或者改进的地方可以发布在评论区,或者加我的微信一起探讨学习,如果想要最后的excel文件成果或者完整的jupyter代码可以加我本人微信:l13890000862(不是企业微信,不会发广告,特别渴望交流)
10. 为什么有第十点呢?
因为十全十美

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)