优化算法---粒子群算法
粒子群优化算法(PSO)是一种基于群体智能的全局优化算法,模拟鸟群觅食行为,通过粒子在解空间中的迭代更新,实现最优解搜索。该算法具有计算简单、易于实现、收敛速度快等特点,广泛应用于函数优化、神经网络训练、路径规划等领域。本文介绍了PSO的基本原理、求解过程及改进方法,并探讨其在复杂优化问题中的应用与优势。
目录
优化算法—遗传算法
优化算法—蚁群算法
优化算法—粒子群算法
优化算法—模拟退火算法
一、基本定义
粒子群优化算法(PSO)是一种模拟自然界鸟群觅食行为的全局优化算法,属于群体智能算法的一种。PSO 是由James Kennedy 和 Russell Eberhart 于1995年提出的。在 PSO 中,每个“粒子”代表一个潜在的解,粒子通过不断更新自己的位置和速度,寻找最优解。算法的目标是通过群体中个体的相互协作来逐渐找到问题的最优解。PSO的基础:信息的社会共享。
1.1 粒子、群体
在 PSO 中,粒子是一个表示候选解的个体。每个粒子都有一个位置和速度,代表了搜索空间中的一个点或解。粒子的位置通常用向量表示。例如,在一个二维空间中,粒子的坐标可以表示为 [ x , y ] [x,y] [x,y],而在多维空间中,粒子的坐标可以表示为一个向量[ x 1 x_1 x1, x 2 x_2 x2, x 3 x_3 x3… x n x_n xn],其中 n 是问题的维度。每个粒子都会根据自己历史上找到的最优解(个体最优)和群体中最优的解(全局最优)来更新自己的位置,逐步逼近全局最优解。
在 PSO 中,群体指的是所有粒子集合。每个粒子代表一个解,并且通过相互协作和信息交流,整个群体最终收敛到最优解。群体的所有粒子共同作用,协同搜索最优解。群体的信息共享和互相学习使得 PSO 具有较强的全局搜索能力。
1.2 位置、速度
粒子的当前位置即为它当前在搜索空间中的解。位置通常表示为一个向量。粒子的当前位置会随着每次迭代而更新。更新过程基于当前速度和位置的变化,通常是通过位置更新公式来完成:
- 位置更新公式:
x i t + 1 = x i t + v i t + 1 x_i^{t+1}=x_i^t+v_i^{t+1} xit+1=xit+vit+1
其中, x i t + 1 x_i^{t+1} xit+1为粒子 i i i在 t + 1 t+1 t+1时刻的位置, v i t + 1 v_i^{t+1} vit+1为粒子 i i i在 t + 1 t+1 t+1时刻的速度
粒子的速度决定了它在搜索空间中移动的方向和步长。每个粒子都有一个速度向量,表示其在每个维度上的移动量。速度是通过考虑当前速度、个体最优解和全局最优解来更新的。 - 速度更新公式:
v i t + 1 = w ⋅ v i t + c 1 ⋅ rand 1 ⋅ ( p B e s t i − x i t ) + c 2 ⋅ rand 2 ⋅ ( g B e s t − x i t ) v_i^{t+1} = w \cdot v_i^t + c_1 \cdot \text{rand}_1 \cdot (pBest_i - x_i^t) + c_2 \cdot \text{rand}_2 \cdot (gBest - x_i^t) vit+1=w⋅vit+c1⋅rand1⋅(pBesti−xit)+c2⋅rand2⋅(gBest−xit)
v i t + 1 v_i^{t+1} vit+1:粒子 i i i在第 t + 1 t+1 t+1 时刻的速度。
w w w:惯性权重,控制粒子保持当前运动状态的惯性。
v i t v_i^t vit:粒子 i i i在第 t t t 时刻的速度。
c 1 c_1 c1和 c 2 c_2 c2:个体学习因子和社会学习因子,用于控制粒子向个体最优解 p B e s t i pBest_i pBesti和群体最优解 g B e s t gBest gBest靠拢的速度。
rand 1 \text{rand}_1 rand1和 rand 2 \text{rand}_2 rand2:[0,1]之间的随机数。
p B e s t i pBest_i pBesti:粒子 i i i的个体最优位置。
g B e s t gBest gBest:全局最优位置。
x i t x_i^t xit:粒子 i i i在第 t t t 时刻的位置。
1.3 个体最优解、全局最优解
每个粒子在搜索过程中的最佳位置被称为个体最优解(Personal Best,pBest)。个体最优解是该粒子历史上找到的最优解,通常是基于该位置的目标函数值(适应度)计算得到的。更新规则:如果粒子当前位置的适应度比其历史上的个体最优解更好,则更新个体最优解。
全局最优解(Global Best,gBest)是指整个粒子群体中所有粒子历史上找到的最优解。它是所有粒子中适应度最好的粒子的最优位置。更新规则:每当某个粒子的个体最优解优于当前的全局最优解时,就更新全局最优解。
1.4 惯性权重
惯性权重是控制粒子当前速度的一个参数,决定了粒子对当前速度的保持程度。它是用来平衡粒子在搜索空间中探索和利用之间的权衡。
- 较大的惯性权重可以使粒子更倾向于保持当前的运动状态,从而增强搜索空间的广泛探索能力。
- 较小的惯性权重则可以使粒子更快速地朝个体最优解和全局最优解收敛,但可能会导致局部最优。
1.5 学习因子(c1 和 c2)
学习因子是影响粒子向个体最优解(pBest)和全局最优解(gBest)移动的速度的参数。通常, c 1 c_1 c1和 c 2 c_2 c2的值会影响粒子对自身和 其他粒子知识的依赖程度。
- c 1 c_1 c1:个体学习因子,控制粒子朝向自己历史最优解的引力。
- c 2 c_2 c2:社会学习因子,控制粒子朝向全局最优解的引力。
1.6 随机数(rand1, rand2)
随机数是[0,1]之间的随机值,通常用于引入随机性和多样性,使粒子不会一直朝同一个方向探索。通过引入随机性,粒子能够更好地避免陷入局部最优解。每个粒子根据随机数决定其更新方向和步长,以增加搜索的多样性和探索性。
1.7 适应度
适应度是用来评估一个粒子解的质量的标准。在 PSO 中,粒子的适应度通常通过目标函数来衡量,目标函数的值越小或越大,表示解越优。适应度用来判断粒子是否更新其个体最优解(pBest)以及是否更新全局最优解(gBest)。
二、算法简介
2.1 基本原理
PSO 基于以下两个核心原理:
- 局部学习:每个粒子会记住自己历史上找到的最优解(即粒子的个体最优解)。
- 全局学习:粒子还会根据群体中所有粒子的最优解来调整自己的搜索方向。
粒子通过这些机制不断调整自己的位置,从而逐步逼近全局最优解。
2.2 算法步骤
1、初始化
- 粒子群初始化:首先,需要在搜索空间内随机生成一定数量的粒子(个体),并为每个粒子初始化位置和速度。位置通常是一个随机生成的向量,速度通常也随机生成,但要限制在一定的范围内。
- 初始化个体最优(pBest):每个粒子会记录自己初始位置处的适应度(目标函数值),即初始的个体最优解。
- 初始化全局最优(gBest):全局最优解是所有粒子中适应度最好的粒子的最优位置。
2、更新速度与位置
3、评估适应度
评估每个粒子当前位置的适应度,通常是通过目标函数来计算。适应度越高的粒子表示解越好。
4、更新个体最优(pBest)和全局最优(gBest)
- 个体最优更新:如果粒子当前的位置优于之前的个体最优解,则更新个体最优解。
- 全局最优更新:如果某个粒子的个体最优解比当前的全局最优解更好,则更新全局最优解。
5、检查停止条件
如果满足停止条件(如达到最大迭代次数或达到预设的精度要求),则停止算法。否则,回到步骤2,继续迭代。
2.3 算法案例
求解:函数 y = 15 x 4 − 238 x 3 − 24 x 2 − 19 x + 16 y=15x^4 -238x^3 -24x^2 -19x+16 y=15x4−238x3−24x2−19x+16的最小值,x在[0,20]之间。
import numpy as np
import matplotlib.pyplot as plt
# 定义函数 y = -11*x^3 + 580*x^2 - 42*x + 19
def func(x):
return 15*x**4 -238*x**3 -24*x**2 -19*x+16
# 生成 x 轴数据
x = np.linspace(0, 20, 400) # x 值从 -10 到 20,共 400 个点
# 计算 y 轴对应的值
y = func(x)
# 创建图形并绘制曲线
plt.plot(x, y,color="b")
# 添加标题和标签
plt.xlabel("x")
plt.ylabel("y")
# 显示网格
plt.grid(True)
plt.show()
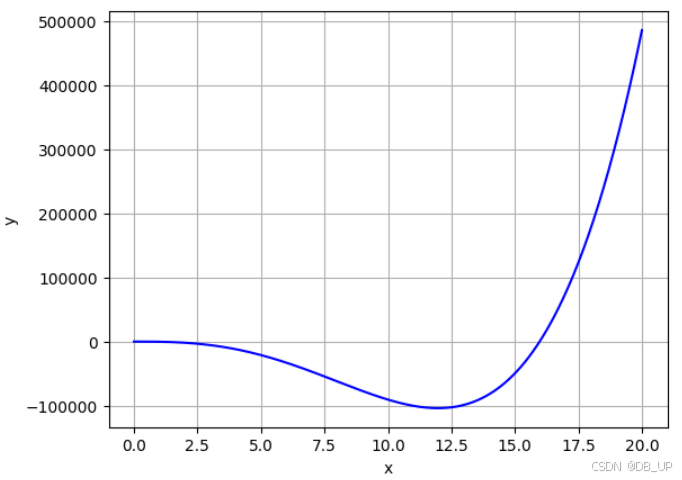
从图中可以看出曲线大概在12左右取得最小值。
import numpy as np
import random
# 目标函数:我们要最小化的目标函数
def objective_function(x):
return 15*x**4 -238*x**3 -24*x**2 -19*x+16
# 粒子群算法 (PSO) 实现
class PSO:
def __init__(self, num_particles, num_iterations, w, c1, c2, min_bound, max_bound):
# 初始化粒子群参数
self.num_particles = num_particles # 粒子数
self.num_iterations = num_iterations # 迭代次数
self.w = w # 惯性权重
self.c1 = c1 # 个体学习因子
self.c2 = c2 # 社会学习因子
self.min_bound = min_bound # 搜索空间下界
self.max_bound = max_bound # 搜索空间上界
# 初始化粒子位置和速度
self.particles = np.random.uniform(min_bound, max_bound, num_particles) # 随机位置
self.velocities = np.random.uniform(-1, 1, num_particles) # 随机速度
# 初始化个体最优解和全局最优解
self.pbest = self.particles.copy() # 个体最优位置
self.pbest_value = np.array([objective_function(x) for x in self.particles]) # 个体最优值
self.gbest = self.particles[np.argmin(self.pbest_value)] # 全局最优位置
self.gbest_value = min(self.pbest_value) # 全局最优值
def update_velocity(self, particle_idx):
# 更新速度
r1 = random.random()
r2 = random.random()
self.velocities[particle_idx] = (self.w * self.velocities[particle_idx] +
self.c1 * r1 * (self.pbest[particle_idx] - self.particles[particle_idx]) +
self.c2 * r2 * (self.gbest - self.particles[particle_idx]))
def update_position(self, particle_idx):
# 更新位置
self.particles[particle_idx] += self.velocities[particle_idx]
# 确保粒子位置在边界内
self.particles[particle_idx] = np.clip(self.particles[particle_idx], self.min_bound, self.max_bound)
def optimize(self):
# 迭代优化
for iteration in range(self.num_iterations):
for i in range(self.num_particles):
# 计算当前粒子的适应度值
fitness_value = objective_function(self.particles[i])
# 更新个体最优解
if fitness_value < self.pbest_value[i]:
self.pbest[i] = self.particles[i]
self.pbest_value[i] = fitness_value
# 更新全局最优解
if fitness_value < self.gbest_value:
self.gbest = self.particles[i]
self.gbest_value = fitness_value
# 输出当前迭代的结果
print(f"Iteration {iteration + 1}: Best Position = {self.gbest}, Best Value = {self.gbest_value}")
# 更新粒子的速度和位置
for i in range(self.num_particles):
self.update_velocity(i)
self.update_position(i)
# 初始化PSO参数
num_particles = 30 # 粒子数
num_iterations = 50 # 迭代次数
w = 0.5 # 惯性权重
c1 = 1.5 # 个体学习因子
c2 = 1.5 # 社会学习因子
min_bound = 0 # 搜索空间下界
max_bound = 20 # 搜索空间上界
# 创建PSO优化器并开始优化
pso = PSO(num_particles, num_iterations, w, c1, c2, min_bound, max_bound)
pso.optimize()
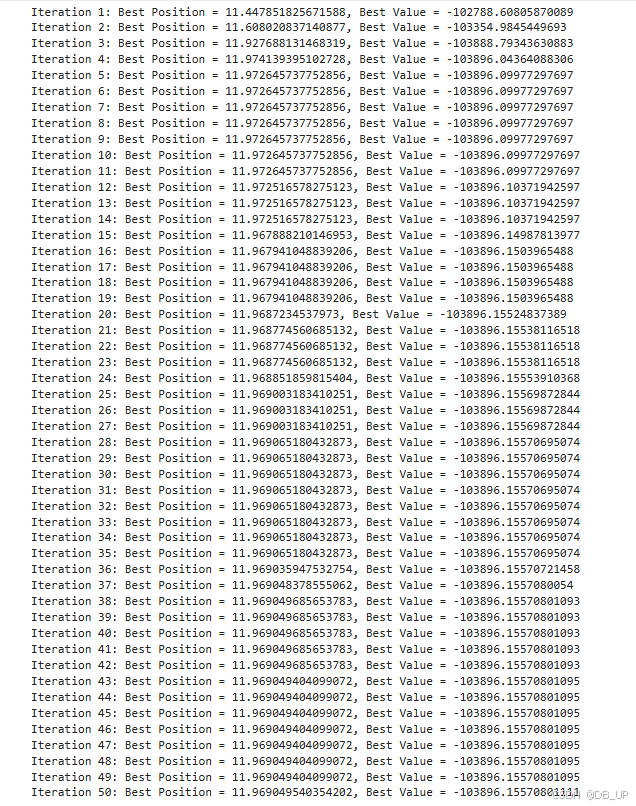
算法迭代50次,最小值在x=11.9690时,y最小为-103896。
2.4 算法优缺点
优点:
全局搜索能力强:由于粒子群体的全局信息共享,PSO 可以有效避免局部最优解的问题。
简单易实现:相比遗传算法、模拟退火等,PSO 算法结构简单,设置参数少、容易实现。
适应性强:PSO 对问题的结构没有强烈假设,能够广泛应用于函数优化、约束优化等多种问题。
缺点:
易陷入局部最优:在某些复杂的高维问题中,粒子可能会陷入局部最优解,尤其是当启发式参数(如惯性权重和学习因子)设置不当时。
收敛速度可能较慢:在一些情况下,粒子群收敛到最优解所需的时间较长,尤其是在搜索空间较大时。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 62
62 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)