有关NEON并行加速优化的两个实例
本次neon优化针对两处循环重复性的工作进行并行加速处理
系统测试与分析
1.原理介绍:
NEON是ARM架构下的一种优化的指令集,主要是为了实现SIMD(Single Instruction Multiple Data,单指令多数据流),简单来说就是将多个操作数打包在大型寄存器中、在一条指令下同时操作多个操作数的指令集。在处理一些简单、重复性高的算法的时候,可以并行处理,大大提高效率。
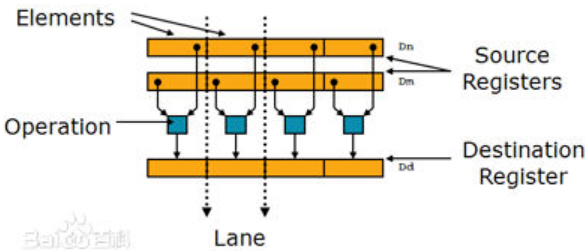
2.工作内容:
本次neon优化针对YGO_real.cpp,将该文件内两处循环重复性的工作进行neon优化加速。
第一处是:
for (int i = 0; i < 64; i++)
{
arr1[i] = (arr1[i] >= iAvg1) ? 1 : 0;
arr2[i] = (arr2[i] >= iAvg2) ? 1 : 0;
}NEON优化过程:
首先定义三个无符号整型16x4的寄存器v0,v1,v2以便后面操作使用。
uint16x4_t v0,v1,v2;
根据neon处理的基本思想,将数组arr1中的数存入NEON寄存器v0中。
v0 = vld1_u16(&arr1[i]);
再将常数iAvg1存入NEON寄存器v1中。
v1 = vdup_n_u16(iAvg1);
接下来就是对源代码中三目逻辑运算进行neon优化,从neon函数库中我们找到vcge这个函数,vcge 函数比较第一个输入向量与第二输入向量,然后将比较结果放在对应结果向量的对应元素,如果第一个向量元素大于等于第二个向量,则结果为 1, 否则为 0
v0 = vcge_u16(v0, v1);
由于范围问题,vcge得到的数据将大于255的数据判为-1,所以要把-1转换成1以供后续处理,于是将常数0存入NEON寄存器v2中来做一次减法
v2 = vdup_n_u16(0);
0-(-1)=1
v0 = vsub_u16(v2,v0);
最后把NEON寄存器v0的值存回数组num中:
vst1_u16(&arr1[i],v0);
对arr2数组的处理同上,此处不再赘述。
优化后的代码:
for (int i = 0; i < 64; i+=4)
{
//int16x4_t v0,v1;
uint16x4_t v0,v1,v2;
v0 = vld1_u16(&arr1[i]);//将数组arr1中的数存入NEON寄存器v0
v1 = vdup_n_u16(iAvg1);//将常数iAvg1存入NEON寄存器v1
v0 = vcge_u16(v0, v1);//三目逻辑运算
v2 = vdup_n_u16(0); //将常数0存入NEON寄存器v2
v0 = vsub_u16(v2,v0);//0-(-1)=1
vst1_u16(&arr1[i],v0);//将NEON寄存器v0的值存回数组num中
//arr1[i] = (arr1[i] >= iAvg1) ? 1 : 0;
uint16x4_t v3,v4,v5;
v3 = vld1_u16(&arr2[i]);//将数组arr1中的数存入NEON寄存器v0
v4 = vdup_n_u16(iAvg2);//将常数iAvg1存入NEON寄存器v1
v3 = vcge_u16(v3, v4);//三目逻辑运算
v5 = vdup_n_u16(0); //将常数0存入NEON寄存器v2
v3 = vsub_u16(v5, v3);//0-(-1)=1
vst1_u16(&arr2[i], v3);//将NEON寄存器v0的值存回数组num中
//arr2[i] = (arr2[i] >= iAvg2) ? 1 : 0;
}
第二处是:
for (int j = 0; j < 8; j++)
{
arr1[tmp1] = data1[j] / 4 * 4;
arr2[tmp1] = data2[j] / 4 * 4;
}
NEON优化过程:
首先定义两个无符号整型32x4的寄存器v0,v1,以便后面操作使用。
uint32x4_t v0,v1;
把数组data1中的数据存入到v1寄存器中:
v0 = vld1q_u32(&data1[j]);
将常数16(也就是4*4)存入v1:
v1 = vdupq_n_u32(16);
在网上搜资料得知neon中没有除法,只能先把除数取倒数,再进行乘法运算,这里选用函数vrecpe对向量内部每个元素求近似倒数,这里取16的倒数以便进行乘法运算:
v1 = vrecpeq_u32(v1);
data[j]乘以16的倒数,即data[j]/4*4:
v0 = vmulq_u32(v0, v1);
最后将计算得到的值写回arr1数组中:
vst1q_u32(&arr11[j], v0);
优化后的代码:
for (int j = 0; j < 8; j+=4)
{
unsigned int* data1 = matDst1.ptr<unsigned int>(i);
unsigned int* data2 = matDst2.ptr<unsigned int>(i);
//int16x8_t v0;
uint32x4_t v0,v1;
v0 = vld1q_u32(&data1[j]);
v1 = vdupq_n_u32(16); //将常数16 存入v1
v1 = vrecpeq_u32(v1); //取16的倒数以便进行乘法
v0 = vmulq_u32(v0, v1); //data1[j] 乘 16的倒数
vst1q_u32(&arr1[j], v0); //将计算的值回写到arr1数组中
uint32x4_t v3, v4;
v3 = vld1q_u32(&data2[j]);
v4 = vdupq_n_u32(16); //将常数16 存入v4
v4 = vrecpeq_u32(v4); //取16的倒数以便进行乘法
v3 = vmulq_u32(v3, v4); //data1[j] 乘 16的倒数
vst1q_u32(&arr2[j], v3); //将计算的值回写到arr2数组中
}
该处优化得到的效果与原代码有较大误差,在网上搜寻了许久没有找到问题的解决办法,猜想可能是vrecpe的精度问题,后来又换成vrecps求取倒数,结果显示由于循环次数太少报错,无奈在最终的代码方法中舍去掉了这部分的neon优化代码。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)