ES基础、高级特性及整合SpringBoot
ES基础、高级特性及整合SpringBoot
之前给服务器安好了ES和Kibana一直没来得及动手试试,这篇就系统性地介绍一下ES的基本使用和特性,以及如何将其与SpringBoot整合。
本文基于ElasticSearch 7.5.0 + Kibana 7.5.0,版本一定要一致!
目录
2.1 ElasticSearch/Kibana/分词器的安装与部署
2.3.2 byte/short/integer/long + half_float/float/double
3.4.7 基本数据统计 Stats(Statistics)
3.4.10 百分位排名统计 Percentiles Ranks
1 什么是ElasticSearch?
ElasticSearch是一个由Java编写的基于Lucene框架、天生支持分布式、RESTful风格的开源搜索和数据分析引擎,也是Elastic Stack的核心。Elastic Stack就是整个Elastic公司包含的所有技术栈,其中包括了最著名的ELK(ES + Logstash + Kibana),以及其他毛毛多的技术,就不提了。
搜索引擎大家应该都不陌生,打开Google输入几个关键词Google一下,就会根据相关度依次展示你搜索的内容,且会高亮标记你的搜索的关键词——ElasticSearch能够做到这件事,且不仅于此;他还提供了强大的数据分析功能:聚合,比如指标聚合中的Max、Min、Avg等典型计算功能,桶聚合中的Terms能统计指定字段的词频。
那么说到ES就不得不提他的底层框架Lucene,市面上大部分的搜索引擎都是基于Lucene实现的。顺便提一嘴创造Lucene的大神道格·卡丁(Doug Cutting),这位也创造了Hadoop(分布式计算框架)、HDFS(高容错分布式文件系统),虽然借鉴了Google算法实现,但也同样伟大。
Lucene是一个全文检索引擎,听起来就像是ES的核心,也确实如此。Lucene提供了关键的分词、倒排索引、匹配搜索功能。
首先要知道“分词”是什么。打比方说我现在要搜索附近的西餐厅,你可能会输入以下的语句:
“附近哪里卖牛排?”
“离我最近的西餐厅?”
如果你完整搜索这句话,估计啥玩意也搜不出来,除非有位和你心有灵犀的人提出了一模一样的问题。但如果把这句话分成许多个有意义的词组再搜索,“离我最近的西餐厅”分解成“最近”和“西餐厅”,就能搜出符合度较高的结果,如愿吃上近处的西餐。分词的作用就是如此,将一个句子分解成一个个有意义的词语。在英语中分词很好实现,因为每个单词间会被空格分隔开,而中文就不好说了,可能由各种词组组成。不过不用担心,咱们China有自己的“IK分词器”,后面我们就会介绍。
那么“倒排索引”又是什么?刚刚我们通过分词,将搜索的语句分成了许多个词语,保存的记录也同样需要分词并保存。例如现在库里有这样几条记录(仅代表个人喜好):
- 1:好吃的川菜馆
- 2:凑合的湘菜馆
- 3:一般的西餐厅
- 4:好吃的陕菜馆
这几条数据如果原封不动地放在那里也没法搜索,分词后变成了这样:
- 1:好吃、川菜
- 2:凑合、湘菜
- 3:一般、西餐厅
- 4:好吃、陕菜
这样以后搜索“好吃”,就能对应到1、4两条记录,但这样好像效率也不高啊,每次搜索遍历每条记录的每个词语。因此我们还需要下一步,将出现过的词语和ID再关联起来,通过词语寻找ID:
- 好吃:1、4
- 凑合:2
- 一般:3
- ......
现在再搜索“好吃”,就能直接查到这个词语对应的记录啦,再回到文档里寻找id为1和4的记录取出来即可。MySQL的非聚集索引的创建,其实就是上诉创建倒排索引的过程,根据被索引字段的值统计所有值对应的记录id,使用该索引时只需找到id再回表查询对应记录。Lucene的倒排索引不同之处在于,他会对整个文档先进行分词,再对分词的结果创建倒排索引;而MySQL只支持对列的数据创建索引,且不支持全文索引,一般全文搜索都会使用like “%abc%”,效率是令人发指的。MySQL5.7之后支持的全文索引match...against也是基于分词和倒排索引实现的!
至此我们有了分词逻辑,也有了分词后创建得倒排索引,只需要充分用起来即可,便到了最后一步匹配搜索。还是老例子,我们搜索“离我最近的西餐厅”,分词分出了“最近”和“西餐厅”, 拿着这两个词去倒排索引里寻找。匹配到“最近”对应的记录1/2/3,“西餐厅”对应的记录2/3/4,可以看到2和3出现了两次,说明这两条记录与我们搜索内容的相关性最高,经过综合打分评估以后,根据匹配度高低返回给用户。
介绍完Lucene后是不是觉得他很强大,ES的核心功能和思想基于Lucene构建,且做了极大地增强。再回到一开始说的天生支持分布式,部署过ES的小伙伴应该知道,配置文件中会让你指定集群名称、主节点名称、集群中子节点名称,可以看得出ES是天生支持集群化和分布式部署的,能够自动进行服务发现和主节点选举。这意味着只要你想,就可以无限上机器来水平扩展。但也不是越多越好哈,分片策略和复制策略也是需要考虑进去的。
ES本身也是极为简单易用的,因为其提供了RESTful API,正如我们认知中,查询文档和索引是GET请求、删除是DELETE请求、修改和发送是POST和PUT。这使得ES的入门和使用变得很简单,只需要学习基本的DSL语法(类似于SQL语句),便可以畅游ES的海洋。
说完了ElasticSearch的种种好处,我们再来总结一下为什么要使用ElasticSearch,再来和关系型数据库老大哥MySQL SOLO一下:
| MySQL | ElasticSearch | |
|---|---|---|
| 存储方式 | 仅允许单机存储,数据量到达百万级后需要分库分表 | 分布式存储,使用分片 + replica冗余存储 |
| 查询效率 | 聚集索引查询效率高,非聚集索引查询效率较低,全文匹配效率极低 | 拥有精准查询、模糊匹配、范围查询等查询方式,全文搜索效率高 |
| 分布式支持 | 支持主从、主主等 | 天生支持 |
| 事务支持 | 支持ACID四大特性 | 不支持 |
| 其他特性 | 支持多表关联查询 | 支持mapping动态映射,支持replica复制分片保证数据完整性,支持聚合计算功能 |
传统关系型数据库单表数据量达到百万条,操作效率就会大幅降低,而ES能够支持处理PB级别的数据(1PB = 1024TB)。刚刚做了个试验,1000w条记录的表查询非索引字段,搜索时间来到了恐怖的20多秒......但是需要事务或复杂关联逻辑的场景,MySQL一定是最好的,没有下位替代。
2 ElasticSearch基本概念
聊了这么多,气氛也热起来了,该介绍振奋人心的ElasticSearch了,下面我们就来介绍一下ES的基本概念。
2.1 ElasticSearch/Kibana/分词器的安装与部署
这篇之前讲过了哈,有兴趣的小伙伴可以看这篇 -> Linux Java常用服务安装与设置。
2.2 索引 Index
此索引非彼索引,ES中索引的概念类似于MySQL中的表,一个索引便对应着一张拥有完整字段结构约束的表。其实早期的ES索引更类似数据库,其中的Type对应着具体的表,但是这个概念并没有多大意义,反而因为一个Index中多个Type带来了许多困扰,因此在7.0版本被彻底移除。
既然Index类似于一张表,我们肯定要先创建好Index、指定每个字段的名称和类型、然后再做其他操作。但是强大的ES为我们提供了动态映射,就是个什么意思呢,你不用建索引,也不用建字段,你直接告诉他我今天就要往索引A里插一条文档B;然后你会惊奇的发现:
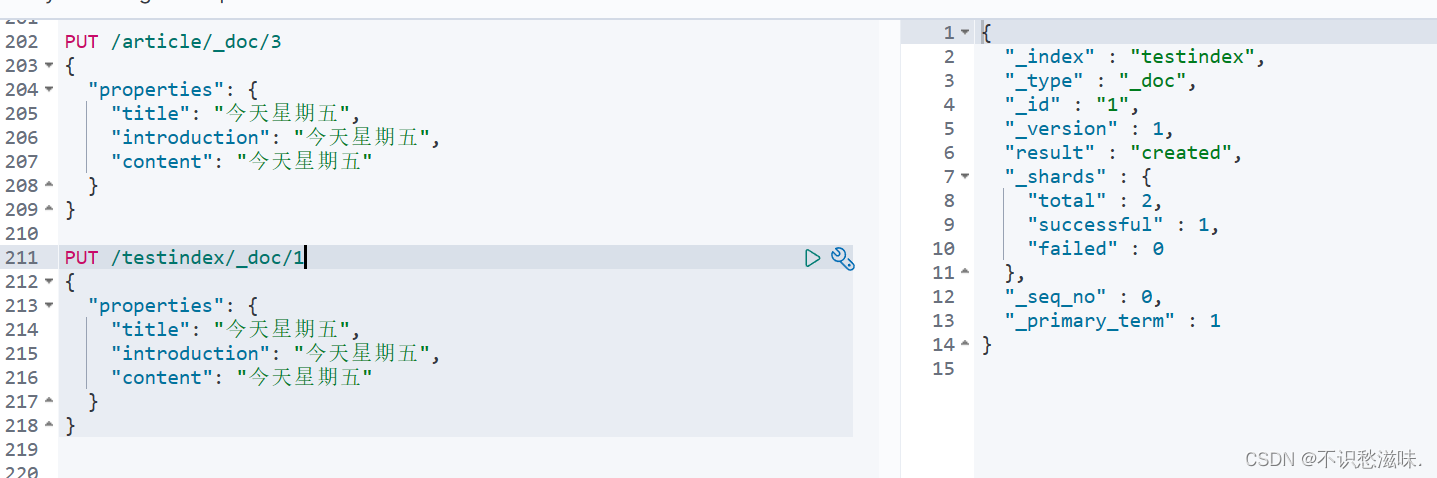
成功了!我事先是没有创建索引的,也可以看到结果的result字段显示“created”,意为索引在此时被创建并插入了文档。这便是ES动态映射带给我的自信,你只管插入,一切都由ES买单。当然,既然是人家自己动态生成的,那你用着也别挑了,咱们来看看索引的结构信息。
{
"testindex" : {
"aliases" : { },
"mappings" : {
"properties" : {
"properties" : {
"properties" : {
"content" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"introduction" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1681183635630",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "FL9VycRcRIek2WiiXlsS5g",
"version" : {
"created" : "7050099"
},
"provided_name" : "testindex"
}
}
}
}
不得不说,ES的动态映射是非常智能的,我们传入的几个字段都是字符串,他便自动帮我们将字段映射设置为了text + keyword类型的复合映射;简单来说就是这个字段既支持全文搜索、又支持精准匹配,是种非常理想的状态,我们自己创建索引时一般也会这样设置。
但还是存在一些问题,在使用text类型时是需要指定分词器的,之前说过ES对于中文的分词支持不佳,毕竟不是全世界都在说中国话;再看看分片策略,也不是很理想,主分片1复制分片1,等于说主数据都存在单节点上,对于单机存储的负载是很大的,且复制分片也只有1个,同时死两台机子这个索引就瘫痪了。因此还是建议自行创建索引,指定分片策略和字段映射等。
2.3 映射 Mapping
映射是索引中非常重要的概念,类似于MySQL中字段的约束,例如数据类型、分词器、是否存储、是否建立索引。其中最重要的就是数据类型,为字段建立合适和数据类型会使你的搜索快上加快。下面就介绍一些常用的数据类型及可配置属性。
2.3.1 text/keyword
text和keyword可以说是ES最核心的两种类型,在早期版本中两者被合并为String字符串类型,后来进行了拆分和优化。text和keyword最大的不同就是是否要分词,text对应需要分词,也就是text字段传入“今天星期四”,就会被分成“今天”和“星期四”两个词供匹配,搜索“今天”或“星期四”都可以匹配到该记录。而keyword字段不会进行分词,放进去什么样保存就是什么样,存“今天星期四”,查也得查“今天星期四”能找到记录。
看起来好像是text功能全面一点,但如果需要保存用户名、手机号这种信息,明显是不需要分词也不会被模糊查询,保存成keyword肯定更合理。且keyword支持聚合而text不支持,因此如果想同时享受聚合和分词查询,就可以设置一个复合类型的字段。
2.3.2 byte/short/integer/long + half_float/float/double
number类型,包括8/16/32/64位整型数,16位半精度/32位单精度/64位双精度浮点数。
2.3.3 boolean/date
boolean很简单,包括true和false。date类型类似于keyword,可以通过指定format来指定日期格式,如"format": "yyyy-MM-dd HH:mm:ss"。
2.3.4 array/object/nested/geo
俺也不会,以后再写。
数据类型介绍完还有几个可配置属性,如index属性可以指定字段是否要建立倒排索引,如果设置为false,再使用该字段进行任何查询都会失败,有些一定不会被作为查询条件的字段可以设置为不建立索引,能够节省磁盘空间。
store属性决定是否要单独存储该字段,一般我们取文档都是从"_source"中读取,那store是干嘛地呢?如果这条文档的字段我们都不想读取,只想看看有没有,就会将“_source”禁用掉,此时ES就只会对文档建立索引而不会保存原数据。但如果你又想要获取其中某一个字段的数据,就可以将store设置为true,在不存储整个文档的情况下,单独存储某个字段(好奇怪...但好吧...)。store属性默认为false,因为已经有source干这个活儿了。
P.S. 但其实我还是感觉怪怪的,因为_source有includes和excludes属性来决定是否保存某些字段,意义不是很明确。
2.4 文档 Document
建立好索引、设置完字段映射,就可以向索引中插入文档了,文档就类似于MySQL中的行数据。插入文档似乎就没什么好说的了,注意点不要写错字段名称就行,由于索引的字段添加后就无法删除,只能增加字段或者给字段追加新类型,一次插入错字段,这个字段就会跟你一辈子。错误次数多了,索引中就会多出很多莫名其妙的字段,只能通过重建索引数据迁移来强行修复,后面会介绍。
3 ElasticSearch的使用
3.1 创建索引
先来创建个索引,如之前所说,需要指定索引名称、索引配置、字段映射,这里仅介绍我使用过的方式。ES提供了RESTful API,使得操作十分清晰,就是一堆HTTP请求,加上请求体中的DSL语句,DSL语法本身其实没什么好介绍的,就是记住然后会用就行。
//创建索引
PUT /testindex
{
"settings" : {
"number_of_shards": 4,
"number_of_replicas": 1
}
}执行上面的命令,先建立索引并指定主分片和副分片数量,“number_of_shards”为主分片数量(默认为5),即该索引的数据需要分成多少个分片存储,像我们就设置了4个,就是把数据分成4片放在不同的服务器上;而“number_of_replicas”是副本数量(默认为1),设置为1意为每个主分片都需要有1个复制分片。那么现在这个索引就包含4主分片 + 4副分片共8个分片,且主分片不会保存在同一个机器上,相同的主分片和副分片也不会保存在一个机器上。这点也很好理解,ES为了安全做了这样的数据冗余,如果两个主分片在同一个机器上,这台机器故障就会导致大量数据不可用;如果主分片A和他的副分片在同一台机器上,这台机器故障A分片的所有数据都会不可用。
值得注意的是,主分片数量在设置完成后就不可再改变,而副分片数量是可以改变的,且副分片在查询时也可以被当做主分片分担查询压力。增加主分片和副分片数量固然有许多好处,比如减少单机磁盘占用量,将单机查询请求变为多线程并行请求多个分片,从而提高查询效率,但这并不意味着分片越多越好——副分片多了就意味着插入数据需要同步的分片越多,且查询请求的机器数量多了以后,网络和IO的开销会使得并行查询的效率变低。通俗地说,分片数量和查询效率的提升是对数增长关系,最开始提升分片数量确实会有效率地提升,但达到临界值后反而会降低,物极必反嘛。
//设置字段映射
PUT /testindex/_mapping
{
"properties" : {
"datetime" : {
"type" : "date",
"format": "yyyy-MM-dd"
},
"int": {
"type": "integer",
"index": true
},
"textandkeyword": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}创建好索引后需要指定字段和映射,设置好字段的名称、类型、分词器。例如上面的映射,我们给testindex索引中新增了名为“datetime”、“int”、“textandkeyword”的字段,“type”属性即为该字段的类型,“datetime”字段为“date”类型且指定了保存的格式为“yyyy-MM-dd”;“int”字段类型为“integer”32位整数,还配置了“index”属性意为该字段是否创建索引,默认为true,即默认所有字段都可以参与搜索,如果设置为false该字段就不能参与搜索。
重点想说“textandkeyword”字段,是ES中比较常见的字段类型:复合类型,可以看到他的第一个type为“text”,且指定了IK分词器,意思是这个字段会被分词存储,用于模糊查询和精确查询;但是如果只使用text,会出现精确匹配整个字段会查不到。比如我们给text类型的字段存入“今天星期四”,根据ik_max_word他会被拆分成如下的词语:
//查看分词结果
post /_analyze
{
"analyzer": "ik_max_word",
"text": "今天星期四"
}
{
"tokens" : [
{
"token" : "今天",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "星期四",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "星期",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "四",
"start_offset" : 4,
"end_offset" : 5,
"type" : "TYPE_CNUM",
"position" : 3
}
]
}
拆得很好,很合理,但是唯独少了这句话本身。 如果我们要精确匹配“今天星期四”,会惊奇地发现查不到,这就非常不合理了,明明是100%完全匹配的记录却查不到。
因此,在遇到某些完全不需要分词,或者也需要精准匹配、参与聚合的字段,可以设置为keyword类型,或者像上文那样设置成复合字段,既是text又是keyword;需要精确匹配时,单独查询“textandkeyword.keyword”,也就是该字段的关键词类型。keyword可以设置一个“ignore_above”属性,因为这个字段有可能长达500字,我们搜索也不可能暴打500字,因此完全没必要对整个keyword都创建索引;这时就会用到ignore_above,意为这些位数之后的字符我就忽略了,比如上文设置的“ignore_above = 256”,就是256位之后的字符不创建索引,能够大大节省磁盘空间。
创建好索引后,可以用GET /indexname来看看索引的信息:
{
"testindex" : {
"aliases" : { },
"mappings" : {
"properties" : {
"datetime" : {
"type" : "date",
"format" : "yyyy-MM-dd"
},
"int" : {
"type" : "integer"
},
"textandkeyword" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"analyzer" : "ik_max_word"
}
}
},
"settings" : {
"index" : {
"creation_date" : "1681197581820",
"number_of_shards" : "1",
"number_of_replicas" : "2",
"uuid" : "xcFNjShzSMqM5VwMTD-J3w",
"version" : {
"created" : "7050099"
},
"provided_name" : "testindex"
}
}
}
}
很理想,和我们设置得完全一致, 这不废话吗。
创建完我们用GET /_cat/indices?v&pretty看看所有索引信息,这个指令也是比较常用的,_cat和Linux里的查看差不多,就是猫一下全局状态;indices是index的复数形式,再加上pretty修饰词,意思是展示得美丽一点。
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open testindex xcFNjShzSMqM5VwMTD-J3w 1 2 2 0 3.7kb 3.7kb
green open .kibana_task_manager_1 85dqt05XTf2hmQloPVxCgg 1 0 2 0 31.6kb 31.6kb
green open .apm-agent-configuration WKEsv_oGQhSeva9aXSw72A 1 0 0 0 283b 283b
yellow open user 7orJbC_KQoa-Dkax9TDLzA 1 1 7 0 5.4kb 5.4kb
green open .kibana_1 cB0TGuF1TMSSIJvrn436FA 1 0 14 1 46.9kb 46.9kb
yellow open article 1lelxTi1TxC1tyHhG0ugwg 1 1 2 0 9.7kb 9.7kb
yellow open user_new cIKcpMZJThSk-5E6m4H-lQ 1 1 5 0 5.1kb 5.1kb
green open .tasks goX4wT5ETtaHFQT3KHQV8A 1 0 3 0 18.5kb 18.5kb
看到这有人就有疑问了,为啥那个“health”字段有人是yellow有人是green呢?还有亚健康的索引库? 这得说回我们刚设置的主分片和副本分片,一般情况下会均分在集群中不同的服务器上,尴尬的是我整个集群内一台机器,就那主分片和副分片就只能都放这一台机子上了。这就会造成数据实际是没有任何冗余的,机器不可用就会导致整个索引数据不可用,所以就呈现了“yellow”的亚健康状态。细心的小伙伴也可以观察出来,pri/rep(primary主分片/replica副本分片)加起来是1的索引就是“green”完全健康状态,因为他们不需要将数据分布存储,只需存在一台机子上即可。
3.2 插入/修改/删除文档
插入和修改实际上差不太多,就是输入对应索引结构的json字符串嘛,因此合并在一起说。
插入文档语法是PUT /indexname/_doc/id,请求体是数据json,记住要符合字段映射,比如刚刚datetime字段指定了format为“yyyy-MM-dd”年月日,如果我们插入年月日时分秒,就会报"mapper_parsing_exception",并告诉你你插入的数据和指定的格式不同,解析失败所以插入失败了;且不要插入不存在的字段,不然时间久了你的索引会出现一堆你不认识的字段。来个正确的插入示例:
PUT /testindex/_doc/3
{
"datetime": "2023-04-12", //要符合format和数据类型
"int": 11,
"textandkeyword": "你好吗"
}修改文档有两种修改方式,第一种是直接覆盖,第二种是只修改某些字段。覆盖就类似于重新插入整个文档,所以和插入文档语法一样使用PUT,id换成需要覆盖的文档id即可。只修改某些字段语法不太一样但也大差不差,要用POST /indexname/_update/id,请求体只写要修改的字段和值即可,注意外面还要套一层“doc”。
POST /testindex/_update/1
{
"doc": {
"int": 1234
}
}删除就不用多说了吧?DELETE /indexname删索引,DELETE /indexname/_doc/id删文档。
3.3 查询文档
重头戏来了,ElasticSearch既然是搜索引擎,那查询搜索自然是他最强大的核心功能,下面我们来重点介绍各种查询文档的方法。首先要记住,ES中所有查询指令都是GET /indexname/_search,这个是基础中的基础哈。
3.3.1 ids 根据ID批量查询
每个文档插入时都会指定或生成一个id,类似于关系型数据库的主键,最基础的就是根据id来查询;且这个查询是批量的,可以输入ids列表。
GET /testindex/_search
{
"query": {
"ids": {
"values": [1, 2, 3]
}
}
}如上述指令,所有查询最外层都要包一个“query”,再往内就是我们用到的“ids”查询,指定values列表[1, 2, 3]就可以查询到id为1/2/3的文档。
3.3.2 match 匹配查询
match查询会先将查询条件进行分词,再将分词后的词语与对应字段进行匹配,一般用于text类型的模糊查询。比如我输入“今天星期四”,就会去字段里查找含有“今天”或“星期四”的文档再返回。match大家族有许多成员,我们挨个介绍。
基础的match查询除了可以输入字段名和字段值以外,还有几个额外的属性:
GET /testindex/_search
{
"query": {
"match": {
"textandkeyword": "今天星期五"
}
GET /testindex/_search
{
"query": {
"match": {
"textandkeyword": {
"query": "今天星期五",
"operator": "and",
"minimum_should_match": 2 //operator为or时设置
}
}
}
}如上述代码,第一种是基本形式,直接输入字段键值对,分词后进行匹配查询;“今天星期五”被ik_max_word神功分成了“今天”、“星期五”、“星期”、“五”,和索引中的“今天星期四”明显是可以匹配的,因此能查询到。
再来看看第二种形式,除了字段值query属性,我们还设置了“operator”和“ minimum_should_match”,这俩是干嘛的?刚刚介绍match查询会先对查询条件进行分词,可能会被分成毛毛多的词语,默认情况下只要匹配到其中一个词语就算你匹配成功,但如果我们需要相关度很高的结果呢?再回到例子中,如果我就想搜索星期五相关的文档,默认的搜索方式却将“今天星期四”也搜索出来了,是不是不太合理呢?
这时operator就闪亮登场了,这个属性意思是匹配操作类型,默认为or,逻辑或匹配;分词结果中任何一个词语匹配上了,都会返回结果。我们将其设置为and,就成了逻辑与匹配,所有分词都能匹配到的文档才能返回。用and搜索时,就搜不到今天星期四对应的文档了。
但这种方式又有些过于极端,用户一般不会用那么精准凝练的语言来搜索,但凡句子里带点废话就啥也搜不到了。这种情况就可以使用较为折中的minimum_should_match,意为最少应该匹配到词语,默认为1,顾名思义最少匹配到1个词语就认为是符合的,等同于逻辑或。我们将其设置为2,就又能匹配到星期四的文档了。不过要注意的是,minimum_should_match只有在operator为or时才能使用,为and时就要全部匹配上,设置这个值也没啥意义,反而会导致啥也查不到。
match_all就是查询索引库中所有文档,只会默认返回10条,可以通过指定size来指定查询条数,也可以自定义一下排序规则;但由于ES的保护机制,单次返回不能超过10000条,可以通过配置来改变最大条数或使用滚动查询,后面我们会介绍。
GET /testindex/_search
{
"query": {
"match_all": {
}
},
"size": 100,
"sort": [
{
"datetime": {
"order": "asc"
}
}
]
}multi_match为批量查询,可以同时指定多个字段,并在这些字段内进行匹配,match则只能在对应一个字段内进行匹配搜索。
GET /textindex/_search
{
"query": {
"multi_match": {
"query": "今天",
"fields": ["title", "introduction", "content"]
}
}
}match_phrase短语匹配是一种更为精准的查询方式,这种查询方式需要匹配到所有的分词,且每个词的顺序要与文档中词语顺序保持一致。如文档为“今天星期四”,如果搜索“星期四今天”就搜索不到,因为虽然所有词都能匹配上,但是一个顺序是“今天”、“星期四”,一个是“星期四”、“今天”,不满足短语匹配的条件。
GET /testindex/_search
{
"query": {
"match_phrase": {
"textandkeyword": {
"query": "星期四今天" //顺序不同,查询不到!!!
}
}
}
}match_phrase_prefix和match_phrase比较类似,只是会给最后一个分词加上指定数量的通配符。举个例子,“喜欢吃”被分词后为“喜欢”、“吃”,match_phrase_prefix会搜索“喜欢” + “吃*”,这个“*”是代表任意字符的通配符,那么我们就可以搜索到“喜欢吃饭”、“喜欢吃菜”。属性“max_expansions”是最后一个词后面通配符的数量,默认为1,也就是“吃*”,也可以设置为自己的幸运数字,但由于性能不佳不太常用。
GET /testindex/_search
{
"query": {
"match_phrase_prefix": {
"textandkeyword": {
"query": "今天星期",
"max_expansions": 10
}
}
}
}上面的查询就能查到“今天星期四”对应的文档,而match_phrase不能,因为搜索的是“今天” + “星期********”。
3.3.3 term 精准查询
term查询不会对查询条件进行分词,即你输入什么查询条件就是什么,更多用于keyword类型的查询,因为keyword也不会被分词,可以精确匹配到文档。还有terms查询,可以输入多个查询条件同时在字段中搜索。
//term单条件
GET /testindex/_search
{
"query": {
"term": {
"textandkeyword.keyword": "今天星期四"
}
}
}
//terms多条件
GET /testindex/_search
{
"query": {
"terms": {
"textandkeyword.keyword": ["今天星期四", "你好吗"]
}
}
}要注意的是,term查询最好使用在keyword类型的字段上,就像我们之前说的,text类型会对字段进行分词存储,不会存储字段本身;而term查询又不会对查询条件进行分词,追求的就是高精准度,text类型显然没法满足。
3.3.4 range 范围查询
range查询用于范围查询,如查询某个日期范围内、某个价格区间内的文档,有gt/gte/lt/lte(大于/大于等于/小于/小于等于)四种逻辑符。
GET /testindex/_search
{
"query": {
"range": {
"datetime": {
"gte": "2023-04-11"
}
}
}
}3.3.5 bool 布尔查询
在日常的搜索中条件不可能只有一个,通常是将多个条件组合起来查询,类似SQL语句中的“WHERE a AND b AND c”,这时就可以用bool查询来拼接条件。
bool中含有must/should/must_not/filter:
- must:必须满足该条件,会进行分值计算。
- should:分含有must条件和不含must条件两种情况,在不含must条件时,只要满足should条件就会返回该文档;含有must条件时,满足should条件的文档会加分,说明相关性更高,返回的优先级也会变高
- must_not:必须不满足该条件。
- filter:必须满足该条件,但他不会进行分值计算,且常用filter会被缓存,非常推荐使用!能使用filter代替must的场景,尽量都使用filter。
来一个示例,现在要查询date为2023-04-12之后的、textandkeyword为“你好吗”的文档,可以使用两种方式来拼接条件:
GET /testindex/_search
{
"profile": "true",
"query": {
"bool": {
"must": [
{
"term": {
"textandkeyword.keyword": {
"value": "你好吗"
}
}
},
{
"range": {
"datetime": {
"gte": "2023-04-12"
}
}
}
]
}
}
}
GET /testindex/_search
{
"profile": "true",
"query": {
"bool": {
"must": [
{
"term": {
"textandkeyword.keyword": {
"value": "你好吗"
}
}
}
],
"filter": {
"range": {
"datetime": {
"gte": "2023-04-12"
}
}
}
}
}
}开启profile来查看一下两种方式的执行计划和耗时,可以看到不使用filter和使用filter的耗时相差确实很大。首先是因为filter不需要计算分数,满足条件就过不满足就爬;其次是常用过滤器会被缓存,但是第一次查询可能看不出效果,甚至must查询可能快于filter,但是第二次使用该filter条件时速度就会全方位领先。
不使用:
"time_in_nanos" : 303220使用:
"time_in_nanos" : 166729
3.3.6 size/scroll 分页查询
分页查询是非常常用的功能,用户也不想一次性看一万条记录。ES提供了两种分页方式,一种是from + size分页查询,一种是scroll滚动查询。
最常用的是用from + size,类似于SQL中的“LIMIT offset, rows”,from是开始读取的位置,size是需要读取的条数。from默认0,size默认10,意思是返回查询到的前10条,用起来还是比较简单方便的,但是存在几个问题。
这里就要先介绍两个知识点,深分页和ES的分页机制。拿MySQL的深分页问题举例,偏移量小的时候效率还是较高的,比如“LIMIT 100, 100”取第100到第200条数据,只需要查出200条再截取后100条返回。但是这种查询方式其实埋了个大雷,如果是“LIMIT 1000000, 100”,就意味着要查出1000100条记录再取后100条,服务端CPU要持续查,再一股脑塞进内存中。
知道深分页问题后,再了解一下ES分页机制,MySQL的查询是单机查询,一张表的记录只会从一台服务器的磁盘中读取;而ES就不一样了,ES是一个分布式搜索引擎,索引会被分片并存储在不同的服务器上。他遇到分页查询请求时,会从所有服务器的分片中获取符合查询条件的文档,再根据分页参数获取目标条数的文档,最后合并、排序、截取所需文档。
这样说可能还是不太明晰,来模拟一下ES的分页查询过程:
- 索引主分片数为4,分布在4台机器上。
- 构建查询条件,分页参数,如term查询 + from 10, size 10。
- 在4个分片中查询符合term条件的文档,并选取前10 + 10 = 20条。因为分页参数为从第10条开始向后取10条,因此需要查询20条才能满足。
- 合并到某一主节点进行排序,再取前20条。
- 根据分页参数,从第10条开始截取后10条文档。
了解了整个过程以后,我们来算算一共取了多少条文档。4个节点每个取20条一共80条,排序后再取10条。现在看起来这个数字并不大,如果from是100000,就起码要获取400000条,显然内存很容易会被打满,且每个分片传这么一堆文档网络开销也是巨大的,更不用说CPU哼哧哼哧搁那查了。
ES也深谙其道,你这分页参数大了我不得死啊?因此限制了from不能大于10000,你往10000条文档以后分页他就认为你在深分页,你别分了我不让。但万一我就要是10000条以后的数据,你总不能不让我看吧?当然也是有解决方案的。
一种是使用索引属性“index.max_result_window”解除限制,强行提高结果窗口最大值,默认不10000吗?我就给你整个100000。但是治标不治本,看是能看到了,但你也没考虑过服务器的死活,我们肯定是要寻找一种更美丽的方式的。
scroll滚动查询就出现了,这种查询方式和之前文章介绍的游标查询比较类似,就是指定一个类似fetchSize的值,服务端查好放那客户端分批取。scroll就更智能了,在你首次发起滚动查询时,会将所有符合条件的文档的id存放在内存中,再根据设置的size每次返回一部分给你,返回一次游标往后滚动一点,已经返回给你的文档id就被移除掉。且scroll还设置有过期时间,在一定时间没有使用该scroll且没有续期后,就会自动移除该scroll上下文来释放内存。
那有人就会问了,那这scroll也挺占吃内存啊,听起来效率也不是很高啊?再来和from + size方式对比一下,from + size每次查询都是一次独立的查询,意味着你翻10次页,同样的查询条件会重复10次,且获取的文档数会随着页数变深指数级变大;而scroll存放在内存中的是所有符合条件的文档id,那么只要你使用的是同一个scroll且他没有过期,每次向后滚动只会拿到id去索引里查对应文档。文档和单个id占用的内存大小自然是文档占用大,每次都重复查询term这个动作scroll也省去了,而且用id查询的效率自然是极高的——想想MySQL聚集索引和非聚集索引的区别,非聚集索引要回表和聚集索引不用,直接取就是对应记录。
这么一对比差距就很明显了吧?所以在大数据量查询场景下,我们最好是使用scroll滚动查询,一般用户的分页还是用from + size,因为scroll并不能支持指定页数的查询,只能一直滚啊滚。
scroll的使用方法就是在第一次查询时,在查询命令后面加上“?scroll=10m”,意为这次查询需要使用滚动查询,且过期时间为10分钟;方法体内指定每次查询条数size(size不可以超过10000,也就是查询窗口最大值),发起请求后会响应相对数量的文档,并额外返回一个“_scroll_id”,下次查询直接用这个id进行查询,便可以在该scroll未过期、且数据未查询完以前一直滚动。不过记得要续期哦,不然scroll过期了而你还没查完,他就不见了。
//传统分页
GET /testindex/_search
{
"query": {
"match_all": {
}
},
"from": 0,
"size": 100,
"sort": [
{
"datetime": {
"order": "asc"
}
}
]
}
//滚动查询1,返回了:
//"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAA88Wdjl2dW9EZzlTTHVoX3BfbzdvR0NFQQ=="
GET /testindex/_search?scroll=10m
{
"query": {
"match_all": {
}
},
"size": 1,
"sort": [
{
"datetime": {
"order": "asc"
}
}
]
}
//滚动查询2,直接使用该scroll并续期
GET /_search/scroll
{
"scroll": "10m",
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAA88Wdjl2dW9EZzlTTHVoX3BfbzdvR0NFQQ=="
}3.4 聚合 Aggregation
基本的增删改查说完了,还记得我们最开始说ES是搜索和数据分析引擎,现在光看到搜索了没看到数据分析,而聚合就是数据分析功能。聚合类似于MySQL的GROUP BY + 各种计算函数(sum/max/min等),对符合条件文档对应字段的值、或是脚本计算后的结果(比如一条文档中两个字段的值相加、某个字段的值乘以2倍、多个字段值求平均值)进行计算和分析。但是不建议用自定义脚本,效率很低容易给自己挖坑。常用的聚合被分为四大类:指标聚合、桶聚合、矩阵聚合和管道聚合,矩阵聚合被ES官方标记为实验性功能,未来可能会被更改或删除,因此不作介绍;管道聚合是对已计算出聚合结果的增强,属于高阶应用此篇不作介绍。本文仅介绍常用的指标聚合和桶聚合。
指标聚合主要作用于Number类型字段,一般用于计算和统计数据,如求最大值、最小值、平均值等。拿求最大值举例,对索引的“price”字段求中Max聚合,对应到SQL语句就是“SELECT MAX(price) FROM `stuff_info` GROUP BY stuff_type”,简单解释一下就是根据商品种类,求每个种类价格的最大值。
桶聚合作用就不太一样了,顾名思义桶聚合会将文档放进一个一个桶,有几个桶、每个桶放怎么样的文档,就要看使用哪种桶聚合、根据哪些查询条件了。
先来看看聚合的基本语法,从最外层向最内层介绍:
GET /indexname/_search
{
"aggs": {
"custom_name1": {
"agg_type": {
"field": "column_name1"
}
},
"custom_name2": {
"agg_type": {
"field": "column_name2"
}
}
}
}- 最外层的“aggs”是必须加的,表示该键值对里面的内容为聚合计算。
- 然后是“custom_name1”和“custom_name2”,意为自定义的聚合结果名称,因为我们可能会进行多个聚合运算,返回结果时需要显示名称。
- “agg_type”就是ES提供得各种聚合,例如sum/min/max等,我们要告诉ES我们要使用哪种聚合功能嘛。
- “field”内为需要做聚合的字段名称。
上面介绍得是最基础的聚合语法,还可以在聚合结果内再次聚合,例如我们先用Term聚合把每个商户文档塞到各自的桶里,再用Sum聚合求商户总营业额。
下面介绍常用的指标聚合和桶聚合。
3.4.1 最大值 Max
最大值聚合,求指定字段中的最大值。
3.4.2 最小值 Min
最小值聚合,求指定字段中的最小值。
3.4.3 平均值 Avg
平均值聚合,求指定字段的平均值。可以通过指定“missing”属性来设置默认值,该字段没有值的文档会使用设置得默认值。
3.4.4 求和 Sum
求和聚合,求指定字段值的总和。
3.4.5 求文档数 Value Count
求文档数聚合,这个听起来比较抽象,其实就是求指定字段有值的文档数。比如有些文档有“sexual”字段值,有些没有,计算sexual字段的Value Count,就可以计算出有该字段的文档数量。
3.4.6 去重统计 Cardinality
去重统计聚合,先对指定字段去重,再计算字段共有多少种值。
3.4.7 基本数据统计 Stats(Statistics)
基本数据统计聚合,能够一次计算出该字段的max/min/avg/sum/count并返回。
3.4.8 拓展数据统计 Extended Stats
扩展数据统计聚合,在基本数据统计的基础上增加了sum_of_squares(平方和)、variance(方差)、std_deviation(标准差)、std_deviation_bounds(平均值加/减两个标准差的区间)。
3.4.9 百分位统计 Percentiles
百分位统计聚合,会先将字段值进行DESC排序,并计算对应百分位的数据大小。
如统计学生成绩score字段,排序后发现记录100%处的分数为60分,50%处为80分,10%处为90分。这意味着100%的人达到了60及格线,50%的人能达到80分以上,仅有10%的人能获取90分以上。这就是百分位统计的含义,默认百分位为1.0/5.0/25.0/50.0/75.0/95.0/99.0%,也可以设置“percents”: [50, 100],来指定查看百分位。
3.4.10 百分位排名统计 Percentiles Ranks
百分位排名统计聚合,和上面那位正好相反,上面是给出百分比,返回百分比所处的数据;这个是给出数据,返回数据所处的百分比。
比如“您的等级已超越80%用户!”,这句话眼熟吧?我们现在的等级“Level”为80,通过Percentiles Ranks就可以计算80在Level这个字段中属于什么百分位。输入80,返回20.00,说明我们处于前20%,超越了80%用户。
常用指标聚合到这就介绍完了,下面来介绍桶聚合。
3.4.11 词频聚合 Terms
统计对应字段词频,每个词对应一个桶,每次遇到对应的词就扔进对应的桶,最后根据桶数量从大到小返回前10个桶的词频大小。可以通过设置size控制返回桶数量的大小,还可以设置order来自定义文档排序规则,默认为“_count”从大到小排序。
3.4.12 过滤器聚合 Filter/Filters
过滤器聚合和bool查询中的filter差不多,可以把符合条件的文档放进一个桶里,也可以设置多个过滤器对应多个查询条件,将文档放在多个桶里。
3.4.13 范围聚合 Range
范围聚合类似于range查询,可以查询对应字段对应范围内的文档,并放在该范围的桶中,可以同时创建多个桶并设置“from + to”(注意是左闭右开哈),符合条件的文档就会放进对应的桶并返回。
3.4.14 缺失值聚合 Missing
用于统计该字段没有值文档的数量,比如排查数据时,有些字段本不应为null却出现了没有值的异常现象,就可以通过该聚合排查这种异常现象出现的场景和频次。
3.4.15 命中文档聚合 Top Hits
Top Hits也是个很好用的聚合,来看这样一种场景,我们需要分析销量最高商品品类的记录,那首先需要用Terms聚合,对商品品类字段进行词频统计,计算出出现频率最高的品类为“食品”。但是Terms聚合只会返回词频,不会返回其他任何信息,而我们得拿到食品类中一部分信息进行分析。
此时就有几个方案,如再次嵌套一个其他类型聚合,或者直接拿到这个桶里的文档。那显然直接拿文档在程序中分析比较方便直观,这时就可以用到Top Hits聚合,该聚合会直接返回桶里的文档,我们可以指定返回前1000条拿出来分析,是不是很好使。
下面这个例子为获取词频最高记录下所有文档。
GET /user/_search
{
"aggs": {
"agg1": {
"terms": {
"field": "location.keyword",
"size": 1,
"order": {
"_count": "desc"
}
},
"aggs": {
"agg1inside": {
"top_hits": {
"size": 10
}
}
}
}
}
}3.5 多余字段的删除
记得我们前面提到的ES会对字段进行动态映射,插入不存在字段时会自动创建该字段并进行动态映射,但误操作创建得字段总不能就在那放着吧,前文提到ES的索引是不支持删除字段的,只能用曲线救国的方式来删掉多余的字段。需要以下几步:
- 创建一个副本索引myindex_temp,使用正确的索引设置和映射。
- 使用脚本删除原索引myindex中,误操作新增字段所有的值。如新增了wrong_column,则需要删除所有文档wrong_column对应的数据,因为如不删除,备份索引数据时会再次插入该错误的字段。
- 使用reindex将myindex中的数据同步到myindex_temp中,此时myindex_temp便有着正确的映射结构和文档数据。
- 删除myindex,创建一个新的myindex并使用正确的索引设置和映射。
- 将myindex_temp中的数据同步到myindex中,此时myindex便有着正确的映射结构和文档数据,问题解决了。
其实第4步也可以不用那么麻烦,直接给myindex_temp设置别名,即可当原来的索引库使用,可以节省一次数据同步的过程,毕竟索引库很大的话同步也是需要时间的,但这种方式仍然容易混淆,看大家如何考量了。使用这种方法也是无奈之举,ES严格要求了不允许删除字段,因此还是插入文档得时候多注意吧。
//删除多余字段的值
POST /test1/_update_by_query
{
"script": "ctx._source.remove('{wrong_column}')",
"query": {
"bool": {
"must": [
{
"exists": {
"field": "wrong_column"
}
}
]
}
}
}
//同步数据
POST /_reindex
{
"source": {
"index": "test1"
},
"dest": {
"index": "test1_temp"
}
}4 整合SpringBoot
上面我们已经介绍完了ElasticSearch所有的基础操作,所有的操作都是在Kibana里,最终肯定要将其整合进我们的Web应用中。ElasticSearch的集成主要使用到了ES的高阶客户端“elasticsearch-rest-high-level-client”,在Maven中引入下面的依赖即可,一定要与所使用的ES版本一致。
<!-- ES的高阶的客户端API -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.5.0</version>
</dependency>
得益于SpringBoot的自动配置,只需在yml文件中指定ES服务的ip地址即可以集群模式连接,但我们只有一台服务器,只配置一个就好。
spring:
elasticsearch:
rest:
uris: http://192.168.8.8:9200
配置完就可以愉快地使用RestHighLevelClient操作ES服务器了!通过下面的使用,可以发现其实这个客户端也是在帮助大家组装DSL语句,这使得发出一个完整的命令就如同使用Kibana编写DSL语句一样丝滑。按照上文介绍的ES使用方法,我们用RestHighLevelClient重新实现一次。
4.1 创建索引
所有操作进行之前,都要先引入RestHighLevelClient!因此我们先注入他。
@Autowired
private RestHighLevelClient client;想想之前使用语句是如何创建索引的:
指定索引名称 -> 设置索引属性 -> 创建映射 -> 创建完成
在高级客户端中也不例外,所有的操作都是先创建请求、构建请求体、使用客户端发送请求、接收响应结果,无非是不同的操作对应不同的请求方式,下面我们便要介绍创建索引使用得请求类型“CreateIndexRequest”。
由于绝大部分操作都要落到对应的索引库上,因此请求类需要设置索引库名称,可以通过构造方法指定,也可以通过调用方法来指定。在初始化CreateIndexRequest时便指定了待创建索引的名称,接下来则需要指定索引属性,手动设置主分片数和副本分片数;ES提供了快捷构造Settings的方法,其内部实现其实就是TreeMap,放置属性对应的键值对即可,在此不作赘述。
下面是创建映射,其实也没什么难点,整个过程就是在构建请求体的json字符串,Kibana里怎么写这里还怎么写就行,有兴趣的小伙伴可以debug一下代码,看看整个请求体构建得过程和参数。要记得告诉客户端你使用得参数类型供解析,我们这里为“XContentType.JSON”。
看看代码实现:
@PostMapping("/createIndex")
public Result<?> insertUserDetail(@RequestBody JSONObject json) {
if (json.isEmpty()) {
return Result.error("请指定索引信息");
}
if (Strings.isNullOrEmpty(json.getString("shards"))) {
return Result.error("请自定义分片信息");
}
if (Strings.isNullOrEmpty(json.getString("replica"))) {
return Result.error("请自定义分片信息");
}
String indexName = json.getString("indexName");
if (Strings.isNullOrEmpty(indexName)) {
return Result.error("请设置索引名称");
}
//创建请求
CreateIndexRequest request = new CreateIndexRequest(indexName);
//配置分片信息
Settings setting = Settings.builder()
.put("index.number_of_shards", 1)
.put("index.number_of_replicas", 1)
//指定索引默认分词器
//.put("index.analysis.analyzer.default.type", "ik_max_word");
.build();
request.settings(setting);
//配置映射信息
String mappingString = json.fluentRemove("shards")
.fluentRemove("replica")
.fluentRemove("indexName")
.toString();
request.mapping(mappingString, XContentType.JSON);
//这种方法在组装映射属性时太复杂,不推荐
//LinkedHashMap<String, Object> map = Maps.newLinkedHashMap();
//json.entrySet().forEach(a -> {
// String key = a.getKey();
// String value = a.getValue().toString();
// map.put(key, value);
//});
try {
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
boolean acknowledged = response.isAcknowledged();
boolean shardsAcknowledged = response.isShardsAcknowledged();
//boolean fragment = response.isFragment();
if (acknowledged && shardsAcknowledged) {
return Result.ok("ok");
} else {
return Result.error("创建索引出现异常");
}
} catch (IOException e) {
log.error("创建索引 {} 出现异常: {}", indexName, e);
return Result.error("创建索引出现异常");
}上述代码还包括了入参校验等,整个过程清晰明了,就是在创建对应请求 -> 构建请求体 -> 利用客户端发送请求 -> 获取响应,最后在响应中获取一下是否创建成功即可。唯一需要注意的是使用客户端对应的操作,这个也好理解。
创建索引:client.indices().create()
插入文档:client.index()
查询文档:client.search()
我们写好请求体利用Postman发送请求:
{
"indexName": "test1",
"shards": 1,
"replica": 1,
"properties": {
"username": {
"type": "keyword",
"index": true
},
"sexual": {
"type": "short",
"index": false
},
"location": {
"type": "text",
"index": true,
"analyzer": "ik_smart",
"fields": {
"keyword": {
"type": "keyword",
"index": true
}
}
},
"phonenumber": {
"type": "keyword"
}
}
}发送请求后返回了个ok,再去Kibana看看索引信息,一点毛病没有。
{
"test1" : {
"aliases" : { },
"mappings" : {
"properties" : {
"location" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
},
"analyzer" : "ik_smart"
},
"phonenumber" : {
"type" : "keyword"
},
"sexual" : {
"type" : "short",
"index" : false
},
"username" : {
"type" : "keyword"
}
}
},
"settings" : {
"index" : {
"creation_date" : "1681680443532",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "EGJn10oKQGetDwrK_spIiw",
"version" : {
"created" : "7050099"
},
"provided_name" : "test1"
}
}
}
}
4.2 插入/修改/删除文档
插入文档对应的是IndexRequest,指定索引库名称,构建插入文档json,想指定文档id就调用id()方法传入,不想就让客户端自动生成。
修改和删除文档的请求是UpdateRequest和DeleteRequest,就是这么简单。修改指的是增量修改,覆盖修改和插入文档操作一致,指定被覆盖的文档id即可;指定id和需要修改的字段doc,这个doc就是在构建IndexRequest,其中包含了需要修改字段的键值对。删除则只需传入文档id即可。
@PostMapping("/insertUserDetail")
public Result<?> insertUserDetail(@RequestBody EsUser user) {
//指定索引库名称进行操作
IndexRequest indexRequest = new IndexRequest("user");
indexRequest.source(JSONObject.toJSONString(user), XContentType.JSON);
//更新文档
//UpdateRequest updateRequest = new UpdateRequest();
//updateRequest.id(id);
//updateRequest.doc();
//client.update(updateRequest, RequestOptions.DEFAULT);
try {
client.index(indexRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("插入user索引出现异常: {}", e);
return Result.error("插入user索引出现异常");
}
return Result.ok("ok");
}4.3 查询文档
查询文档使用SearchRequest,和其他操作唯一的不同点就是要构建查询条件,说到底其实也是用ES API来组装条件json。整个过程就是创建查询请求、构建查询条件、发送请求、获取响应,是不是很眼熟?所以说RestHighLevelClient的使用很丝滑便捷,所有请求的结构都是一致的。
用match_all查询一下索引中所有的文档,先创建查询文档请求并指定索引、构建查询源、构建match_all查询条件、将查询条件传入查询源、将查询源传入查询请求、使用客户端发送请求。整个过程用代码实现一下:
@PostMapping("/queryAllUser")
public Result<?> queryAllUser() {
//指定索引库名称进行操作
SearchRequest searchRequest = new SearchRequest("user");
//组装查询条件并赋值
SearchSourceBuilder search = new SearchSourceBuilder();
//match_all
//MatchAllQueryBuilder builder1 = QueryBuilders.matchAllQuery();
MatchAllQueryBuilder builder = new MatchAllQueryBuilder();
search.query(builder);
searchRequest.source(search);
try {
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
HashMap<String, Object> resMap = Maps.newHashMapWithExpectedSize(2);
LinkedList<EsUser> resList = Lists.newLinkedList();
for (SearchHit hit : hits.getHits()) {
String str = hit.getSourceAsString();
log.info("hit: {}", str);
EsUser esUser = JSONObject.parseObject(str, EsUser.class);
resList.add(esUser);
}
resMap.put("count", hits.getTotalHits());
resMap.put("data", resList);
return Result.ok(resMap);
} catch (IOException e) {
log.error("查询user索引出现异常: {}", e);
return Result.error("查询user索引出现异常");
}
}match_all方法的构建可以使用QueryBuilders建造器或者直接new,建造器里集成了所有查询方法,使用起来方便好记一些。构建好MatchAllQueryBuilder后传入SearchSourceBuilder,查询条件便组装好了,将组装后的查询条件传给查询请求,就可以获取到相应结果。
response中我们可以获取很多有用的信息,最重要的便是查询命中文档SearchHits,从其中可以拿到命中文档列表SearchHit[],遍历该列表就可以获取命中文档。获取json字符串形式的文档source并解析成实体类,再想怎么使用就怎么使用吧。
再来构建个复杂一点的查询方法,我们构建个bool查询方法,创建terms查询并作为过滤器传入bool。但是看到代码大家会发现,整个逻辑也就那么回事,就是把json转换成调用API。
SearchRequest request = new SearchRequest();
request.indices("user");
SearchSourceBuilder builder = new SearchSourceBuilder();
//filter条件构建
BoolQueryBuilder bool = new BoolQueryBuilder();
TermsQueryBuilder terms = new TermsQueryBuilder("location", locations);
bool.filter(terms);
builder.query(bool);
request.source(builder);整了这么些我们把Kibana请求写法和API写法对比一下,先写一个完整的请求体,包括了查询方法、分页参数、排序方法。
GET /testindex/_search
{
"query": {
"match_all": {
}
},
"from": 0,
"size": 100,
"sort": [
{
"datetime":{
"order": "asc"
}
}
]
}再对应到高阶客户端API。
//指定索引库名称进行操作
SearchRequest searchRequest = new SearchRequest("user");
//组装查询条件并赋值
SearchSourceBuilder search = new SearchSourceBuilder();
MatchAllQueryBuilder builder = new MatchAllQueryBuilder();
search.query(builder);
//分页参数
Integer pageSize = json.getInteger("pageSize");
Integer pageNo = (json.getInteger("pageNo") - 1) * pageSize;
search.from(pageNo).size(pageSize);
search.sort("datetime", SortOrder.DESC);
searchRequest.source(search);对比一下得出了以下几点:
- GET /indexName/_search等各种索引操作类型,对应了SearchRequest的创建,创建了操作类型和操作索引。
- 最外层大括号,即整个请求体,对应了SearchSourceBuilder。
- 查询方法、分页参数、排序规则等的创建,即是在填充SearchSourceBuilder。
- 具体的查询方法,例如match_all,对应了MatchAllQueryBuilder等一众查询方法。
你能想到ElasticSearch的所有操作,都能用RestHighLevelClient实现!以后再构建请求时只需要记住,把该加的东西加在正确的地方。那我们再举一反三一下,用滚动查询时应该如何构建?Kibana里指定滚动查询是在GET方法后面加上?scroll=10m,刚刚说指定请求是使用SearchRequest,其中也确实有个scroll()方法来指定滚动查询生效时间,可以说是一通百通了。
//创建游标查询,指定存活时间
searchRequest.scroll(new Scroll(new TimeValue(10, TimeUnit.MINUTES)));4.4 聚合
最后来介绍聚合在高阶客户端中的实现,和查询流程其实差不多,也是构建聚合再传入,主要讲讲如何获取聚合结果。我们先构建个Terms聚合,从response中获取聚合结果集合看看。
//bucket聚合构建,词频统计
TermsAggregationBuilder agg = AggregationBuilders.terms("location").field("location.keyword");
builder.aggregation(agg);
request.source(builder);
//获取聚合结果
List<Aggregation> aggregations = response.getAggregations().asList();试着遍历这个集合,你会发现没法从里面的Aggregation获取任何有用的信息。这是为啥?由于我们可能会创建很多个聚合,而聚合又有毛毛多的种类,ES显然不愿意每个聚合类型都提供一个GET方法,而是鼓励大家获取每个聚合结果后自行作类型转换——首先是因为Aggregation是所有聚合类型的父类,直接转换不会出现编译错误。其次是这种方式胜在操作者心知肚明,根据自定义的聚合名称获取聚合,再转换成使用得聚合类型,风险是相对较小的;假定你使用了Terms聚合,却不小心使用了比如getSum()(不存在这个方法!!!是虚构的!!!)获取了Sum聚合,编译期不会出现问题,在获取结果时因为我们使用的聚合根本不是Sum,运行时就可能会引起bug,最好还是将bug暴露在编译期哈。
举个栗子,我们使用Terms聚合来统计地区词频,如果传入location参数统计指定地区、不传入则统计所有地区。即下面这段代码逻辑,如果指定地区就构建filter并传入,先查询再对查询结果进行聚合。
//如指定地区则返回指定地区
//未指定则返回所有地区
String location = json.getString("location");
if (!Strings.isNullOrEmpty(location)) {
log.info("查询指定地区");
BoolQueryBuilder bool = new BoolQueryBuilder();
TermQueryBuilder term = new TermQueryBuilder("location.keyword", location);
bool.filter(term);
builder.query(bool);
}Terms聚合结果里有许多个桶Bucket,Bucket里存放了字段名和词频,我们构建Terms聚合并获取结果组装返回。
//bucket聚合构建,词频统计
TermsAggregationBuilder agg = AggregationBuilders.terms("location").field("location.keyword");
builder.aggregation(agg);
request.source(builder);
//获取结果
Terms terms = (Terms) aggregations.get("location");
bucketMap = Maps.newHashMapWithExpectedSize(10);
for (Terms.Bucket bucket : terms.getBuckets()) {
bucketMap.put(bucket.getKeyAsString(), bucket.getDocCount());
}
aggList.put(terms.getName(), bucketMap);最后的返回值如下:
"aggs": {
"location": {
"陕西省西安市": "2",
"广州省深圳市": "1",
"天津市": "1",
"北京市": "1",
"影分身": "1",
"湖北省武汉市": "1"
}
}
至此ES基础、高级特性及整合SpringBoot圆满完结了,相信你已经掌握了ES的基本原理、基本操作、SpringBoot高级客户端的整合,其实还有很多知识点可以讲,包括强大的脚本功能(脚本确实是一把双刃剑,效率低下但用起来很爽,可以突破ES提供的基础DSL语法,利用Groovy自定义查询、算分、插入逻辑)、分片策略(多主分片和副本分片如何合理分布在集群内不同机器上,实现索引的高可用)、路由策略(新增文档时如何指定新增到哪台机器上、查询时如何根据路由实现快速查询)、性能调优等技巧,本人学艺不精就不卖弄了,以后学到了再跟大家分享。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)