【算法】KMP 算法
本文介绍字符串的模式匹配算法之一——KMP 算法,包括其概述、代码实现等。
本文参考:《数据结构教程》第 5 版 李春葆 主编
有关字符串模式匹配的其它算法:
【算法】Brute-Force 算法
【算法】Boyer-Moore 算法
【算法】Rabin-Karp 算法
1.概述
KMP 算法是由 D.E.Knuth、J.H.Morris 和 V.R.Pratt 共同提出的,称之为 Knuth-Morris-Pratt 算法,简称 KMP 算法。该算法与 Brute-Force 算法相比有较大的改进,主要是消除了主串指针的回溯,从而使算法效率有了一定程度的提高。
有关串的模式匹配以及 Brute-Force 算法的相关知识可以参考【算法】Brute-Force 算法这篇文章。
1.1.求解模式串的 next 数组
(1)在 KMP 算法中,通过分析模式串 t 从中提取出加速匹配的有用信息。这种信息是对于 t 的每个字符 t j t_j tj(0≤ t ≤ m - 1,m 是 t 的长度)存在一个整数 k (k < j),使得模式串 t 中开头的 k 个字符 ( t 0 t 1 . . . t k − 1 t_0t_1...t_{k-1} t0t1...tk−1) 依次于 t j t_j tj 的前面前面 k 个字符 ( t j − k t j − k + 1 . . . t j − 1 t_{j-k}t_{j-k+1}...t_{j-1} tj−ktj−k+1...tj−1) 相同。如果这样的 k 有多个,取其中最大的一个。模式串 t 中每个位置 j 的字符都有这种信息,采用 next 数组表示,即 next[j] = MAX{k}。归纳起来,求模式串 t 的 next 数组的公式如下:

(2)例如模式串 t = “abacabab”,当 j = 7 即 t 7 t_7 t7 = ‘b’ 时,显然 MAX{k} = MAX{1, 3} = 3,即 t 0 t 1 t 2 t_0t_1t_2 t0t1t2 = “aba” = t 4 t 5 t 6 t_4t_5t_6 t4t5t6,如下图所示。这里也可以将 k 理解子串 t 0 t 1 . . . t j − 1 t_0t_1...t_{j-1} t0t1...tj−1 = t 0 t 1 t 2 t 3 t 4 t 5 t 6 t_0t_1t_2t_3t_4t_5t_6 t0t1t2t3t4t5t6 = “abacaba” 相同前后缀的最大长度。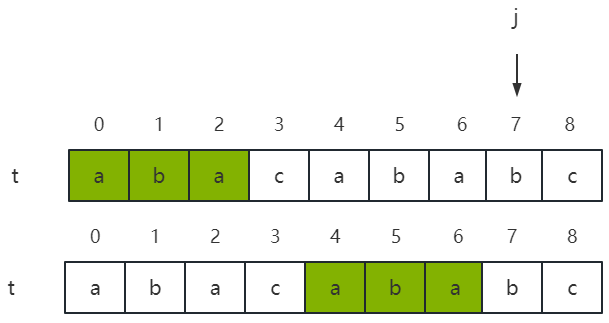
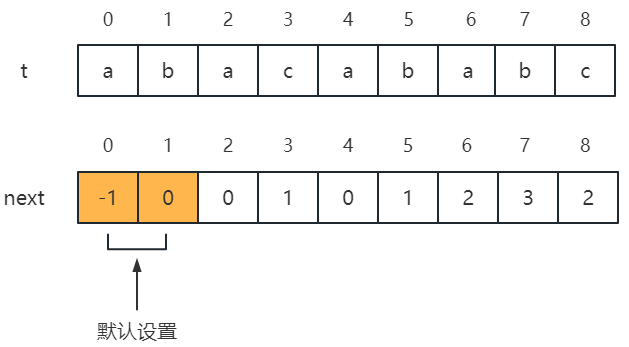
同时也可以求出 t 的 next 数组:
(3)next 数组的具体求解过程如下(采用动态规划的思想,也可以采用暴力法求解 next 数组,但效率较低):
- 默认设置:next[0] = -1,next[1] = 0(j = 1 时,在 1 ~ j - 1 的位置上没有字符);
- 如果 next[j] = k,则表示 t 0 t 1 . . . t k − 1 t_0t_1...t_{k-1} t0t1...tk−1 = t j − k t j − k + 1 . . . t j − 1 t_{j-k}t_{j-k+1}...t_{j-1} tj−ktj−k+1...tj−1:
-
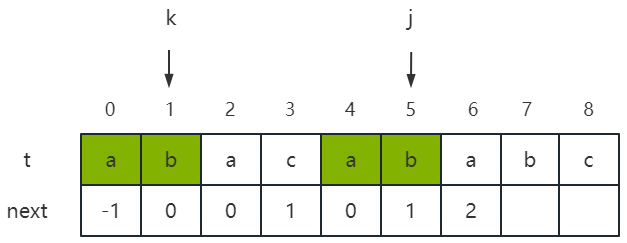
如果 t k t_k tk = t j t_j tj,即有 t 0 t 1 . . . t k − 1 t k t_0t_1...t_{k-1}t_k t0t1...tk−1tk = t j − k t j − k + 1 . . . t j − 1 t j t_{j-k}t_{j-k+1}...t_{j-1}t_j tj−ktj−k+1...tj−1tj,显然有 next[j + 1] = k + 1。以下图为例,next[5] = 1,即 j = 5、k = 1,而 t 5 t_5 t5 = t 1 t_1 t1,故 next[5 + 1] = 1 + 1,即 next[6] = 2;
-
如果 t k t_k tk ≠ t j t_j tj,说明 t j t_j tj 之前不存在长度为 next[j] + 1 的子串和开头字符起的子串相同,那么是否存在一个长度较短的子串和开头字符起的子串相同呢?
- 这里还是以 t = “abacabab” 为例,如下图所示,next[7] = 3,即 j = 7、k = 3;
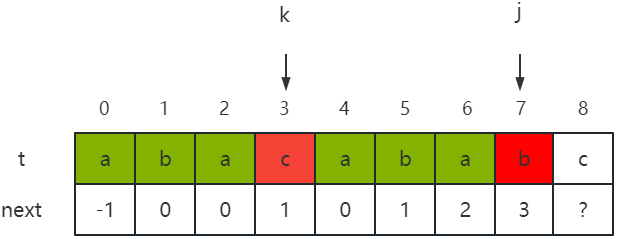
- 但是 t 3 t_3 t3 ≠ t 7 t_7 t7,即 c ≠ b,此时我们就需要重新找一个与开头字符起的子串相同的长度较短的子串,即要寻找 t 0 t 1 t 2 t_0t_1t_2 t0t1t2 的前缀与 t 4 t 5 t 6 t_4t_5t_6 t4t5t6 的后缀相同时的最大长度。而由于此时必有 t 0 t 1 t 2 t_0t_1t_2 t0t1t2 = t 4 t 5 t 6 t_4t_5t_6 t4t5t6,因此我们可以通过 next[k] = next[3] = 1 知道 “aba” 的相同前后缀的最大长度为 1,即 t 0 t 1 t 2 t_0t_1t_2 t0t1t2 的前缀与 t 4 t 5 t 5 t_4t_5t_5 t4t5t5 的后缀相同时的最大长度为 1,如下图所示:
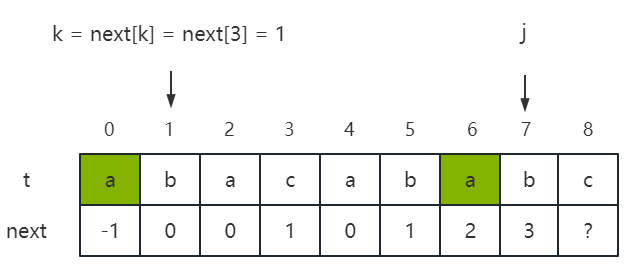
- 因此,当 t k t_k tk ≠ t j t_j tj 时,k 应该回退为 next[k],即置 k = next[k] = next[3] = 1。例如,在一轮判断中,由于 t k t_k tk = t 1 t_1 t1 = t j t_j tj = t 7 t_7 t7 = ‘b’,因此可以得知 next[7 + 1] = next[8] = k + 1 = 2,即 next[8] = 2,即 "abacabab"的相同前后缀的最大长度为 2;
- 这里还是以 t = “abacabab” 为例,如下图所示,next[7] = 3,即 j = 7、k = 3;
-
1.2.KMP 算法的模式匹配过程
(1)当求出模式串 t 的 next 数组表示的信息后,就可以用来消除主串指针的回溯。为了方便起见,这里以目标串 s = “aaaaab”,模式串 t = “aaab” 为例来进行说明(可按照上述方法求解 t 的 next 数组为 {-1, 0, 1, 2}):
- 第 1 趟匹配:用 i、j 分别扫描 s 和 t(初始时 i = 0,j = 0),若当前比较的字符相同则均递增 1,比较到 i = 3、j = 3 失败为止,此时 i 值不变,根据 next 数组修改 j = next[j] = next[3] = 2;
- 第 2 趟匹配:从 i = 3、j = 2 开始比较,这之后所有字符均相同;
- i、j 递增到 t 扫描完毕,此时 i = 6、j = 4,返回 i - t.length = 2,表示 t 是 s 的子串,且位置为 2。
(2)设目标串(也称为主串)s 的长度为 n,模式串(也成为子串)t 的长度为 m,在 KMP 算法中求 next 数组的时间复杂度为 O(m),在后面的匹配中因目标串 s 的下标 i 不减(即不回溯),比较次数可记为 n,所以 KMP算法的平均时间复杂度为 O(n + m),优于 BF 算法的 O(n * m)。但并不等于说任何情况下 KMP 算法都优于 BF 算法,当模式串的 next 数组中 next[0] = -1,而其它元素值均为 0 时,KMP 算法退化为 BF 算法。
2.代码实现
2.1.KMP 算法
KMP 算法的代码实现如下:
class Solution {
//获取字符串 t 的 next 数组
public int[] getNext(String t) {
int m = t.length();
int[] next = new int[m];
int j = 0;
int k = -1;
next[0] = -1;
while (j < m - 1) {
if (k == -1 || t.charAt(j) == t.charAt(k)) {
j++;
k++;
next[j] = k;
} else {
// k 回退
k = next[k];
}
}
return next;
}
public int kmp(String s, String t) {
//获取模式串 t 的 next 数组
int[] next = getNext(t);
int i = 0;
int j = 0;
while (i < s.length() && j < t.length()) {
if (j == -1 || s.charAt(i) == t.charAt(j)) {
i++;
j++;
} else {
// i 不变,j 后退
j = next[j];
}
}
if (j >= t.length()) {
//匹配成功
return i - t.length();
} else {
//匹配失败
return -1;
}
}
}
2.2.改进的 KMP 算法
(1)上述 KMP 算法中定义的 next 数组仍然存在缺陷。例如设目标串 s = “aaabaaaab”,模式串 t = “aaaa”,模式串 t 对应的 next 数组如下:
| j | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| t[j] | a | a | a | a | a |
| next[j] | -1 | 0 | 1 | 2 | 3 |
在匹配过程中,当 i = 3、j = 3 时, s 3 s_3 s3 ≠ t 3 t_3 t3,由 next[j] 可知还需进行 i = 3 / j = 2、i = 3 / j = 1、i = 3 / j = 0 的 3 次比较,总共需要 12 次字符比较。而实际上,因为模式串 t 中的 t 0 t_0 t0、 t 1 t_1 t1、 t 2 t_2 t2 字符和 t 3 t_3 t3 字符都相等,所以不需要再和目标串中的 s 3 s_3 s3 进行比较,可以将模式串依次向右滑动 4 个字符的位置,即直接进行 i = 4 / j = 0 的字符比较,此时总共需要 9 次字符比较。
(2)这就是说,若按前面的定义得到 next[j] = k,在模式串中有 t j t_j tj = t k t_k tk,当目标串中的字符 s i s_i si 和模式串中的字符 t j t_j tj 比较不同时, s i s_i si 一定和 t k t_k tk 也不相同,所以没有必要再将 s i s_i si 和 t k t_k tk 进行比较,而是直接将 s i s_i si 和 t n e x t [ k ] t_{next[k]} tnext[k] 进行比较,为此将 next[j] 修正为 improvedNext[j]。
(3)improvedNext 数组的定义是 improvedNext[0] = -1,当 t j t_j tj = t n e x t [ j ] t_{next[j]} tnext[j] 时,improvedNext[j] = improvedNext[next[j]],否则 improvedNext[j] = next[j]。改进后的代码实现如下所示(主要针对构建 next 数组部分):
class Solution {
//获取字符串 t 的 next 数组
public int[] getImprovedNext(String t) {
int m = t.length();
int[] improvedNext = new int[m];
int j = 0;
int k = -1;
improvedNext[0] = -1;
while (j < m - 1) {
if (k == -1 || t.charAt(j) == t.charAt(k)) {
j++;
k++;
//改进之处
if (t.charAt(j) != t.charAt(k)) {
improvedNext[j] = k;
} else {
improvedNext[j] = improvedNext[k];
}
} else {
// k 回退
k = improvedNext[k];
}
}
return improvedNext;
}
public int kmp(String s, String t) {
//获取模式串 t 的 next 数组
int[] next = getImprovedNext(t);
//其余代码与上面一样
//...
}
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)