掌握iText:轻松处理PDF文档-进阶篇


简体中文写入
如果你是第一次使用iText时,应该会遇到和我一样的情况,正常写入一段中文后,打开生成的pdf文档后,会发现里面并没有显示中文。这是因为iText本身对简体中文的支持有限,但可以通过引入额外的字体包来增强其对简体中文的支持。例如,可以使用iTextAsian.jar这个亚洲字体包,它包含了几种简单的亚洲字体,其中包括简体中文字体。只需要将iTextAsian.jar放到类路径下,并在报表文件中设置相应的字体,就能够正常显示中文信息。如果想要使用其他的自定义的字体,则需要进行相应的扩展。
即使是这样,iText对中文的支持还是有限,因为iText-Asian包支持的中文字体只有简体的STSong华文宋体和三种繁体,因此这里和大家分享两种方法:
- 直接使用iTextAsian.jar中的简体中文字体;
- 使用自定义的字体;
第一种:使用iTextAsian.jar中的简体中文字体
- 使用iTextAsian.jar中的简体中文字体,这种相对简单,先在pom.xml中引入iTextAsian.jar;
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext-asian</artifactId>
<version>5.2.0</version>
</dependency>- 通过字体工厂FontFactory中的静态工厂方法getFont(...)获取到字体后,在往document中添加文本段落的时候指定该字体即可;
@Test
public void test8() {
Font font = FontFactory.getFont("STSong-Light", "UniGB-UCS2-H", BaseFont.EMBEDDED, 12, Font.NORMAL);
Document document = new Document();
try {
PdfWriter.getInstance(document, new FileOutputStream("d:/test/hello.pdf"));
document.open();
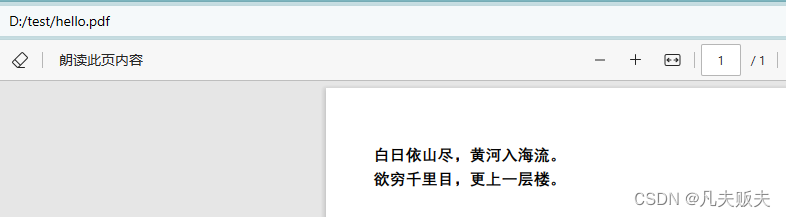
document.add(new Paragraph("白日依山尽,黄河入海流。", font));
document.add(new Paragraph("欲穷千里目,更上一层楼。", font));
document.close();
} catch (DocumentException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
第二种:自定义字体
这种方法相对灵活,也很简单,可以去一些设计类的网站上下载字体,我这里是从字体天下网下载一个字体,但是需要注意字体版权问题,我下载这个是商用免费,看着不错吧;

- 把下载好的字体文件放置到classpath一个固定目录下
- 然后使用字体工厂类的 FontFactory.register(...)注册自定义的字体;
- 注册完成后,使用字体工厂类的FontFactory.getFont(...)获取自定义的字体
- 剩下的就是在添加文本内容的时候指定该字体就可以了;
@Test
public void test9() {
URL resource = getClass().getClassLoader().getResource("HongLeiXingShuJianTi-2.otf");
FontFactory.register(resource.getPath(), "HongLeiXingShuJianTi-2.otf");
Font font = FontFactory.getFont("HongLeiXingShuJianTi-2.otf", BaseFont.IDENTITY_H, BaseFont.EMBEDDED, 20, Font.NORMAL);
Document document = new Document();
try {
PdfWriter.getInstance(document, new FileOutputStream("d:/test/hello.pdf"));
document.open();
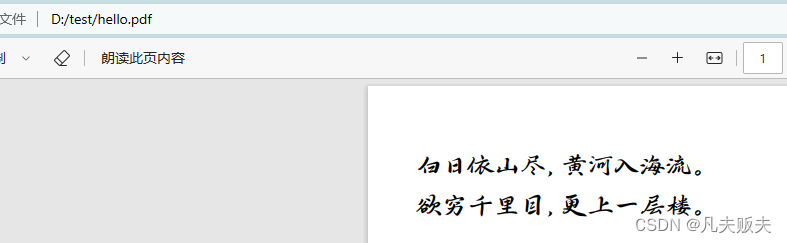
document.add(new Paragraph("白日依山尽,黄河入海流。", font));
document.add(new Paragraph("欲穷千里目,更上一层楼。", font));
document.close();
} catch (DocumentException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}字体效果:
读取文本和图片
使用iText读取文本是比较容易的,可以一下子全部读取,也可以逐页的读取,但是iText没有直接从pdf中提取图片的api。这点比较难受,难道不能提取出图片吗?当然不,可以这样做
步骤
- 定义一个pdf阅读器PdfReader;
- 再定义一个pdf内容解析器PdfReaderContentParser,构造方法接受一个pdf阅读器作为参数;
- 逐行进行内容解析,这里需要实现RenderListener接口,RenderListener接口有两个重要方法:renderText()和renderImage()
renderText(TextRenderInfo renderInfo): 这个方法在文本渲染时被调用。TextRenderInfo对象包含了关于文本渲染的所有信息,包括文本、字体、颜色等等。你可以通过这个方法来控制文本的渲染方式,例如设置文本的颜色、字体等。
renderImage(ImageRenderInfo renderInfo): 这个方法在图像渲染时被调用。ImageRenderInfo对象包含了关于图像渲染的所有信息,包括图像的路径、宽度和高度等。你可以通过这个方法来控制图像的渲染方式,例如设置图像的大小、位置等。
@Test
public void test10() {
try {
PdfReader pdfReader = new PdfReader(new FileInputStream("d:/test/hello.pdf"));
int numberOfPages = pdfReader.getNumberOfPages();
PdfReaderContentParser parser = new PdfReaderContentParser(pdfReader);
for (int i = 0; i < numberOfPages; i++) {
int finalI = i;
parser.processContent(i + 1, new RenderListener() {
@Override
public void beginTextBlock() {
}
@Override
public void renderText(TextRenderInfo renderInfo) {
System.out.println("---start text---");
String text = renderInfo.getText();
System.out.println(text);
System.out.println("---end text---");
}
@Override
public void endTextBlock() {
}
@Override
public void renderImage(ImageRenderInfo renderInfo) {
System.out.println("---start image---:");
PdfImageObject image = null;
try {
image = renderInfo.getImage();
} catch (IOException e) {
e.printStackTrace();
}
byte[] imageAsBytes = image.getImageAsBytes();
String fileType = image.getFileType();
String imageName = "d:/test/" + (finalI + 1) + "." + fileType;
FileUtil.writeBytes(imageAsBytes, imageName);
System.out.println("imageName:" + imageName);
System.out.println("---end image---");
}
});
}
} catch (IOException e) {
e.printStackTrace();
}
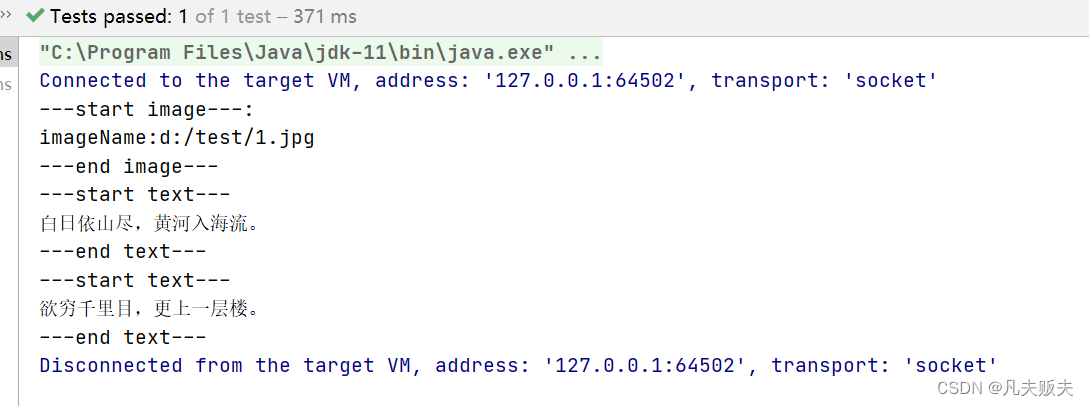
}
总结
注意:目标文档中,先是两行文本内容,然后才是一张图片。但是从提取日志来看,先提取出来的是图片,然后才是文本内容,因此,这里虽然可以从pdf中提取到图片,但是图片和文本的顺序是不能保证的,需要特别注意哦。
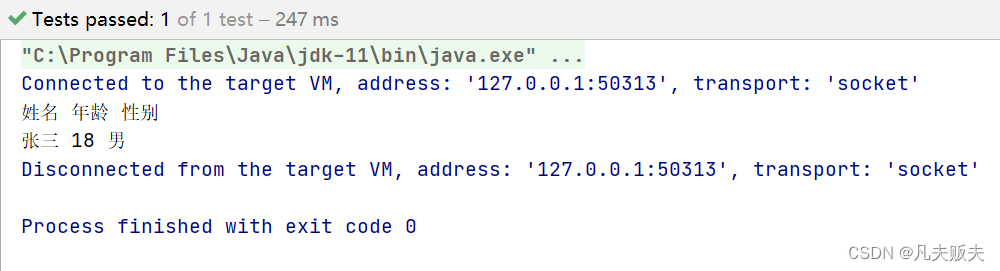
读取表格
读取目标文档截图:
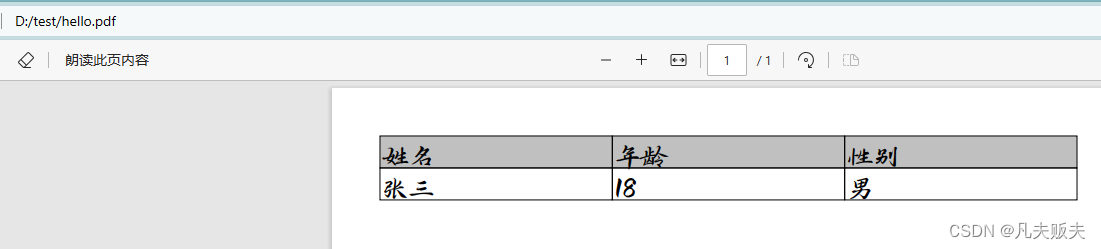
很遗憾,使用iText从pdf文档中读取表格内容,并没有像poi读取word中表格一样,可以逐行读取的API,读取表格内容和读取文本是一样的,不能读取出表格的样式内容。如图:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)