为什么使用HashMap需要重写hashcode和equals方法?
一、先从散列表讲起
1、散列思想
散列表用的是数组支持按照下标随机访问数据的时候,时间复杂度是O(1)的特性
通过散列函数把元素的键值映射为下标,然后把数据存储在数组中对应下标的位置。当按照键值查询元素时,用同样的散列函数,将键值转化为数组下标,从对应的数组下标的位置取数据
2、散列函数
散列函数hash(key),其中key表示元素的键值,hash(key)的值表示经过散列函数计算得到的散列值
散列函数设计的基本要求:
- 散列函数计算得到的散列值是一个非负整数
- 如果
key1=key2,那hash(key1)==hash(key2) - 如果
key1!=key2,那hash(key1)!=hash(key2)
在真实的情况下,要想找到一个不同的key对应的散列值都不一样的散列函数,几乎是不可能的。即使是业界著名的MD5、SHA、CRC等哈希算法,也无法完全避免这种散列冲突。而且,因为数组的存储空间有限,也会加大散列冲突的概率
3、散列冲突
常用的散列冲突解决方法有两类,开放寻址法和链表法
1)、开放寻址法
开放寻址法的核心思想是,如果出现了散列冲突,就重新探测一个空闲位置,将其插入。那如何重新探测新的位置呢?一个比较简单的探测方法,线性探测
当往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止
下图中黄色的色块表示空闲位置,橙色的色块表示已经存储了数据: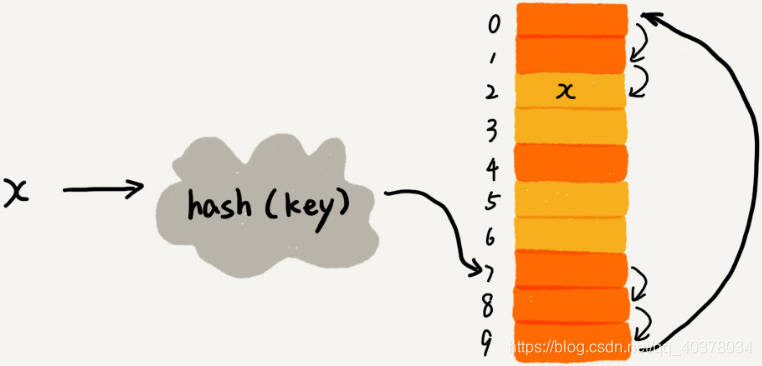
从图中可以看出,散列表的大小为10,在元素x插入散列表之前,已经6个元素插入到散列表中。x经过Hash算法之后,被散列到位置下标为7的位置,但是这个位置已经有数据了,所以就产生了冲突。于是就顺序地往后一个一个找,看有没有空闲的位置,遍历到尾部都没有找到空闲的位置,于是再从表头开始找,直到找到空闲位置2,于是将其插入到这个位置
在散列表中查找元素,通过散列函数求出要查找元素的键值对应的散列值,然后比较数组中下标为散列值的元素和要查找的元素。如果相等,则说明就是我们要找的元素;否则就顺序往后依次查找。如果遍历到数组中的空闲位置,还没有找到,就说明要查找的元素并没有在散列表中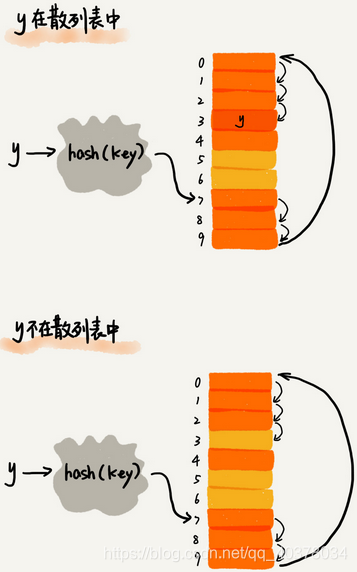
散列表还支持删除操作,对于使用线性探测法解决冲突的散列表,删除操作稍微有些特别。不能单纯地把要删除的元素设置为空。因为在查找的过程中,一旦通过线性探测方法,找到一个空闲位置,就可以认定散列表中不存在这个数据。但是,如果这个空闲位置是后来删除的,就会导致原来的查找算法失效。可以将删除的元素,特殊标记为deleted。当线性探测查找的时候,遇到标记为deleted的空间,并不是停下来,而是继续往下探测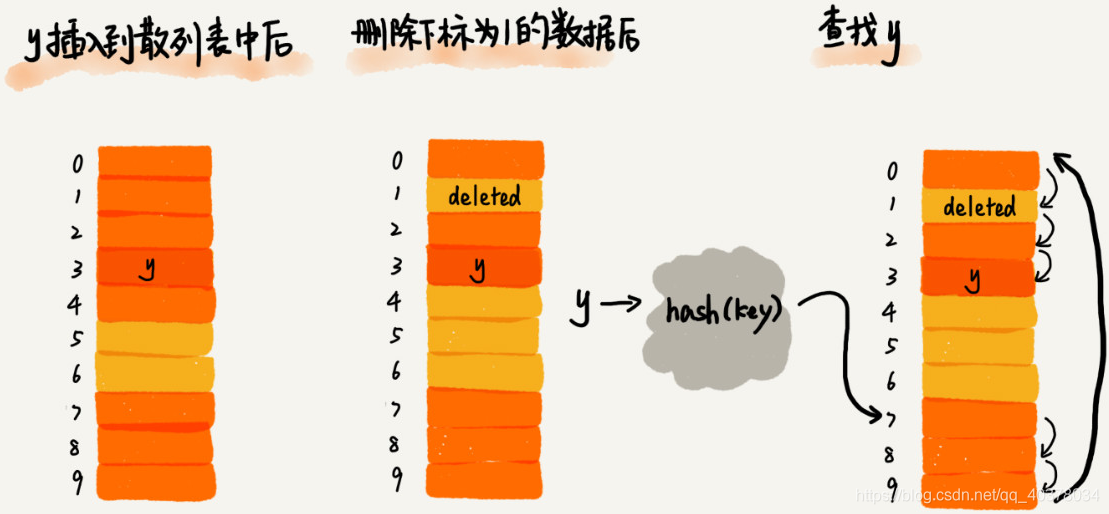
线性探测法其实存在很大问题。当散列表中插入的数据越来越多时,散列冲突发生的可能性就会越来越大,空闲位置会越来越少,线性探测的时间就会越来越久
散列表的装载因子 = 填入表中的元素个数 / 散列表的长度
装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降
2)、链表法
在散列表中,每个桶或者槽会对应一条链表,所有散列值相同的元素都放到相同槽位对应的链表中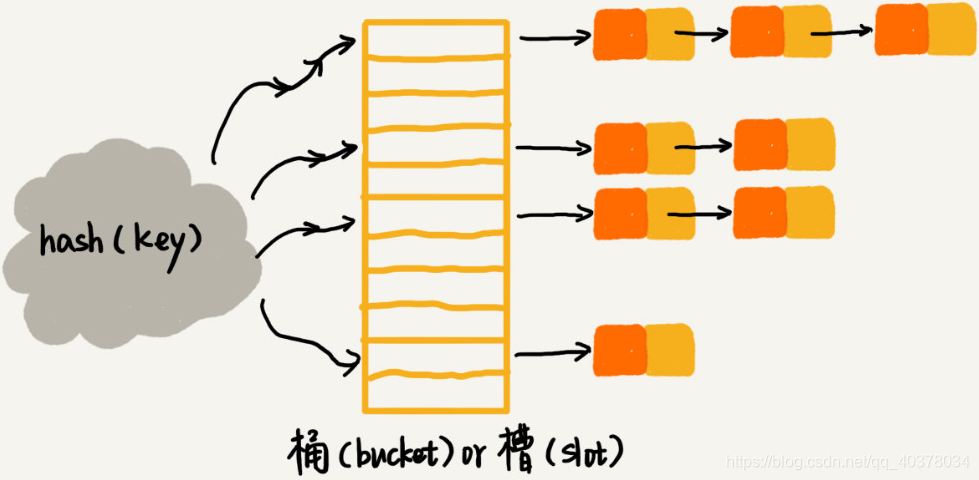
当插入的时候,只需要通过散列函数计算出对应的散列槽位,将其插入到对应链表中即可,所以插入的时间复杂度是O(1)
当查找、删除一个元素时,同样通过散列函数计算出对应的槽,然后遍历链表查找或者删除。查找或删除的时间复杂度跟链表的长度k成正比,也就是O(k)。对于散列比较均匀的散列函数来说,理论上,k=n/m,其中n表示散列中数据的个数,m表示散列表中槽的个数
二、为什么要重写hashcode和equals方法
如果k1和k2的id相同,即代表这两把钥匙相同,可以用第二把钥匙打开用第一把钥匙锁的门
class Key {
private Integer id;
public Integer getId() {
return id;
}
public Key(Integer id) {
this.id = id;
}
}
public class WithoutHashCode {
public static void main(String[] args) {
Key k1 = new Key(1);
Key k2 = new Key(1);
HashMap<Key, String> hashMap = new HashMap<>();
hashMap.put(k1, "Key with id is 1");
System.out.println(hashMap.get(k2));
}
}
运行结果:
null
解析:
当向HashMap中存入k1的时候,首先会调用Key这个类的hashcode方法,计算它的hash值,随后把k1放入hash值所指引的内存位置,在Key这个类中没有定义hashcode方法,就会调用Object类的hashcode方法,而Object类的hashcode方法返回的hash值是对象的地址。这时用k2去拿也会计算k2的hash值到相应的位置去拿,由于k1和k2的内存地址是不一样的,所以用k2拿不到k1的值
重写hashcode方法仅仅能够k1和k2计算得到的hash值相同,调用get方法的时候会到正确的位置去找,但当出现散列冲突时,在同一个位置有可能用链表的形式存放冲突元素,这时候就需要用到equals方法去对比了,由于没有重写equals方法,它会调用Object类的equals方法,Object的equals方法判断的是两个对象的内存地址是不是一样,由于k1和k2都是new出来的,k1和k2的内存地址不相同,所以这时候用k2还是达不到k1的值
什么时候需要重写hashcode和equals方法?
在HashMap中存放自定义的键时,就需要重写自定义对象的hashcode和equals方法
三、如何重写hashcode和equals方法
class Key {
private Integer id;
public Integer getId() {
return id;
}
public Key(Integer id) {
this.id = id;
}
@Override
public int hashCode() {
return id.hashCode();
}
@Override
public boolean equals(Object obj) {
if (obj == null || !(obj instanceof Key)) {
return false;
} else {
return this.getId().equals(((Key) obj).getId());
}
}
}
public class WithoutHashCode {
public static void main(String[] args) {
Key k1 = new Key(1);
Key k2 = new Key(1);
HashMap<Key, String> hashMap = new HashMap<>();
hashMap.put(k1, "Key with id is 1");
System.out.println(hashMap.get(k2));
}
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)