TSRFormer: Table Structure Recognition with Transformers ----论文阅读
TSRFormer,可以从各种表格图像中稳健地识别具有几何变形的复杂表格的结构,可以处理几何扭曲甚至弯曲的表格,有边框和无边框的表格。此方法是把表格分隔线预测当作线回归问题而不是图像分割问题,并提出了一种新的基于 DETR 的分隔线预测方法,称为 Separator REgression TRansformer (SepRETR),直接从表格图像中预测分割线。在分割线预测之后,使用基于简单关系网络
TSRFormer

这篇论文是对论文 RobusTabNet1 的改进,是同一个作者写的,以下内容以本论文为主,部分细节来源于 RobusTabNet 论文。
TSRFormer,可以从各种表格图像中稳健地识别具有几何变形的复杂表格的结构,可以处理几何扭曲甚至弯曲的表格,有边框和无边框的表格。
此方法是把表格分隔线预测当作线回归问题而不是图像分割问题,并提出了一种新的基于 DETR 的分隔线预测方法,称为 Separator REgression TRansformer (SepRETR),直接从表格图像中预测分割线。在分割线预测之后,使用基于简单关系网络的单元合并模块来恢复合并单元。
TSRFormer 包含两部分:1)基于两阶段DETR的分割回归模块,用于从输入表格图像中直接预测行/列分割线(直线和曲线); 2)基于关系网络的单元格合并模块,通过合并由相交的行和列分割线生成的相邻单元格来恢复合并单元格。这两部分共享ResNet18-FPN生成的P2特征。
SepRETR
为了使两阶段 DETR 框架高效且有效地用于分离线预测任务,提出了两项改进:
- 先验增强匹配策略,以解决 DETR 的慢收敛问题;
- 一个新的交叉注意力模块,直接从高分辨率卷积特征图中采样特征,从而以低计算成本实现高定位精度。

在分割模块中,有两个分支分别预测行线和列线。每个分支包括三个模块:
- 特征增强模块,生成上下文增强的特征图;
- 一个基于 SepRETR 的分割线预测模块;
- 辅助分隔线分割模块
以下以行线为例
特征增强模块
一些重要的视觉特征,如线和单元格内容的对齐,提供了有用的提示,以指示分隔线是否存在于表中的某个位置。然而,ResNet-FPN 主干输出的特征图中不包含这些特征,因为输出卷积特征图上的每个特征向量只包含从其有效感受野中提取的局部上下文信息。基于这样的卷积特征图,分割模块很难找到线,所以使用空间 CNN 来增强特征,让特征图具有这些行线或者列线的特征。
首先,通过3x3的卷积和三个重复的下采样块(每一个块都是由1x2的最大池化层、3x3的卷积层和ReLU激活函数组成),生成一个下采样的特征图(高不变,对宽进行下采样)
然后,使用两个级联的 SCNN(spatial CNN)通过在整个特征图中向右和向左方向传播上下文信息来进一步增强其特征表示能力。以向右方向为例,SCNN 模块沿宽度方向将特征图分成 W 32 \frac{W}{32} 32W 个切片,从左到右逐个切片传播信息。对于每个切片,首先将其送到 9×1 的卷积层,然后通过逐元素加法与下一个切片合并。在 SCNN 模块的帮助下,输出的上下文增强特征图中的每个像素都可以利用双向的结构信息来获得更好的表示能力。
基于 SepRETR 的分割线预测模块
使用三个平行的曲线分别表示每个行分隔符的上边界、中心线和下边界。每条曲线由 K=15 个点表示。对于每个行分隔符,通过 SepRETR 直接预测其 3K 个点的 y 坐标。
SepRETR 包含两个模块:一个参考点检测模块和一个用于分割线回归的 DETR 解码器。参考点检测模块首先尝试从增强的特征图中预测每个行分割线的参考点。检测到的参考点的特征被视为object query,并输入到 DETR 解码器中,为每个 query 生成增强的embedding。然后,这些增强的 query embeddings 通过前馈网络独立解码为分割线坐标和类标签。这两个模块共享同一个特征(由1x1卷积核一个上采样层生成的)。
参考点检测
该模块尝试在原始图像的宽度方向上( x i = W 16 × i x_i = \frac{W}{16} \times i xi=16W×i)为每个行分割线在固定位置预测参考点。将当前列中的每个像素输入到一个 sigmoid 分类器中以预测一个分数来估计参考点位于其位置的概率。然后使用 7×1 最大池化层来应用NMS以删除重复的参考点。之后,选择前 100 个行参考点,并通过 0.05 的分数阈值进一步过滤。剩余的行参考点作为行分割线回归模块中的 DETR 解码器的 object query。
分割线回归
为了效率,不使用 transformer 编码器来增强 CNN 主干输出的特征。相反,将高分辨率特征图的固定位置(与参考点的固定位置相同)的列连接起来以创建一个新的下采样特征映射。然后,在其位置处提取的行参考点的特征被当作 object query,并输入到一个 3 层transformer 解码器中。增强后的特征使用两个前馈网络分别做分类和回归。
先验增强匹配
给定一组来自输入图像的预测及其对应的标签,DETR 使用匈牙利算法将标签分配给系统预测。然而,发现DETR中原始的二分匹配算法在训练阶段不稳定,即一个 query 可以在不同的训练时期与同一图像中的不同 object 进行匹配,这显着减慢了模型的收敛速度。论文发现在第一阶段检测到的大多数参考点在不同的训练时期始终位于其相应行分隔符的顶部和底部边界之间,因此利用这些先验信息将每个参考点与其最接近的 GT 分割线匹配。这样,匹配结果在训练过程中会变得稳定。生成一个代价矩阵来度量参考点和GT之间的距离。如果参考点位于 GT 分隔符的上下边界之间,则代价设置为从该参考点到该分隔符的 GT 参考点的距离。否则,设置为INF。基于这个成本矩阵,我们使用匈牙利算法来产生参考点和GT分离器之间的最佳二分匹配。在得到最优匹配结果后,我们进一步移除代价INF的参考点以绕过不合理的标签分配。 实验表明,SepRETR 的收敛速度在我们之前增强的二分匹配策略下变得更快。
辅助分割

辅助分支目的是预测每个像素是否位于任何分隔符的区域中。添加了一个四倍的上采样操作,然后是一个 1×1 卷积层和一个 sigmoid 分类器,来预测一个二进制mask图。
基于关系网络的单元格合并模块

在分割线预测之后,我们将行线与列线相交以生成单元格网格,并使用关系网络通过合并一些相邻单元格来恢复合并单元格。
首先使用 RoI Align 根据每个单元的边界框从 P2 中提取 7×7×C 的特征图,然后将其输入到每层有 512 个节点的两层 MLP 中,生成一个 512 维特征向量。这些单元格特征可以排列在一个有“行”和“列”的网格中,形成一个N行M列的特征图,然后使用三个特征增强模块来增强特征以获得上下文信息,再使用关系网络2(Relationship Proposal Networks)来预测相邻单元格之间的关系。
其中每个特征增强块包含三个并行分支,分别是行级最大池层、列级最大池层和 3x3 卷积层。这三个分支的输出特征图连接在一起,并通过一个 1×1 的卷积层进行卷积以进行降维。在关系网络中,对于每对相邻单元,将它们的特征和18 维空间兼容性特征拼接起来。然后使用一个二分类器来预测这两个单元是否应该合并(分类器是用一个2 层 MLP 实现的,每个隐藏层有 512 个节点和一个 sigmoid 激活函数)。相邻单元格只考虑四邻域。
需要注意的点:
- Merge Module 需要使用 Split Module 的输出去做 ROIAlign 抽取特征并进一步预测相邻单元格关系,此时 ROIAlign 需要的是水平矩形,但是 Split Module 输出的分割线有可能是曲线,此时水平矩形的生成方法如下:预测分割线时可以得到该线的中心线和上、下边界,此时会把行列分割线的这些上下边界求交点并得到内缩框,由于表格分割线在空白区域可以任意移动位置且表格结构不变,这里 Merge Module 采用内缩框的最小外接矩形来做 ROIAlign。
- 因为每个单元格会和上下左右四个单元格做预测,所以每对单元格会重复预测两次,在推理阶段,取最大值作为这对单元格的最终合并分数。
- 因为分割模型预测的表格结构和实际的表格结构不一定完全一样,所以需要使用预测的表格单元格和实际的表格单元格进行匹配来生成预测的单元格之间的关系。如果预测的单元格和实际的单元格的满足以下关系,则把预测的单元格归入此实际的单元格
A r e a ( b d e t ∩ b g t ) A r e a ( b d e t ) > 0.5 \frac{Area(b_{det} \cap b_{gt})}{Area(b_{det})} > 0.5 Area(bdet)Area(bdet∩bgt)>0.5
然后每个检测的单元格和它的四邻域单元格构建关系对。如果关系对中的两个单元格被分配到同一个真实单元格框中,将这个关系对赋予一个正标签,否则给出一个负标签。在训练期间,忽略了所有包含未分配给任何真实单元格的单元格的负关系对,然后采用OHEM方法选择硬样本来训练单元格合并模块。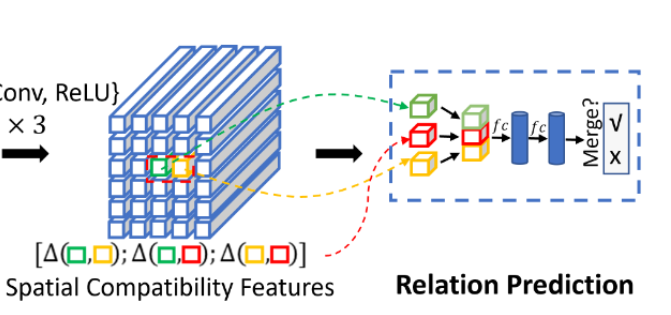
18维的空间特征(即上图红色立方体)
假设绿色块对应单元格边界框坐标为 b i = { x i , y i , w i , h i } b_i = \{x^i, y^i,w^i, h^i \} bi={xi,yi,wi,hi}, 黄色块对应单元格边界框坐标 b j = { x j , y j , w j , h j } b_j= \{x^j, y^j,w^j, h^j \} bj={xj,yj,wj,hj},用 b i j b_{ij} bij 来表示 b i b_i bi 和 b j b_j bj 的并集,用 l i j l_{ij} lij 来表示 18 维空间特征。
l i j l_{ij} lij 是用来度量两个单元格的相对比例和位置关系的,由三个 6 维的向量拼接得到,分别是 b i b_i bi 和 b j b_j bj、 b i b_i bi 和 b i j b_{ij} bij、 b j b_j bj 和 b i j b_{ij} bij 的框增量,例如 b i b_i bi 和 b j b_j bj 的框增量定义为 Δ ( b i , b j ) = ( t x i j , t y i j , t w i j , t h i j , t x j i , t x j i ) \Delta(b_i, b_j) = (t_x^{ij}, t_y^{ij}, t_w^{ij}, t_h^{ij}, t_x^{ji},t_x^{ji}) Δ(bi,bj)=(txij,tyij,twij,thij,txji,txji)
t x i j = ( x i − x j ) / w i , t y i j = ( y i − y j ) / h i , t w i j = log ( w i − w j ) , t h i j = log ( h i − h j ) , t x j i = ( x j − x i ) / w j , t y j i = ( y j − y i ) / h j . \begin{aligned} t_x^{ij} = (x^i - x^j) / w^i, & \quad t_y^{ij} = (y^i - y^j) / h^i , \\ t_w^{ij} = \log(w^i - w^j), & \quad t_h^{ij} = \log(h^i - h^j), \\ t_x^{ji} = (x^j - x^i) / w^j, & \quad t_y^{ji} = (y^j - y^i) / h^j. \end{aligned} txij=(xi−xj)/wi,twij=log(wi−wj),txji=(xj−xi)/wj,tyij=(yi−yj)/hi,thij=log(hi−hj),tyji=(yj−yi)/hj.
损失函数
L = λ ( L r e f r o w + L r e f c o l ) + L a u x r o w + L a u x c o l + L l i n e r o w + L l i n e c o l + L m e r g e L = \lambda (L_{ref}^{row} + L_{ref}^{col}) + L_{aux}^{row} + L_{aux}^{col} + L_{line}^{row} + L_{line}^{col} + L_{merge} L=λ(Lrefrow+Lrefcol)+Lauxrow+Lauxcol+Llinerow+Llinecol+Lmerge
以行为参考
参考点检测
focal loss 的变体
L r e f r o w = − 1 N r ∑ i = 1 H { ( 1 − p i ) α l o g ( p i ) , p i ∗ = 1 ( 1 − p i ∗ ) β p i α l o g ( 1 − p i ) , o t h e r w i s e L_{ref}^{row} = - \frac{1}{N_r}\sum_{i=1}^{H} \begin{cases} (1-p_i)^\alpha log(p_i), & p_i^* = 1 \\ (1-p_i^*)^\beta p_i^\alpha log(1 - p_i), & otherwise \end{cases} Lrefrow=−Nr1i=1∑H{(1−pi)αlog(pi),(1−pi∗)βpiαlog(1−pi),pi∗=1otherwise
其中 N r N_r Nr 是行分割线的数量, α \alpha α 和 β \beta β 分别设置为 2 和 4 在 CornerNet3中, p i p_i pi 和 p i ∗ p_i^* pi∗ 分别是行分割线上的第 i 个点。
把 ( y k , x τ ) (y_k, x_{\tau}) (yk,xτ) 作为在垂线 x = x τ x=x_\tau x=xτ 与当前行分割先的交叉点, w k w_k wk 作为上下边界的厚度,则 p i ∗ p_i^* pi∗ 可以表示为:
p i ∗ = { e x p ( − ( i − y k ) 2 2 σ k 2 ) , i f i ∈ ( y k − w k 2 , y k + w k 2 ) 0 , o t h e r w i s e p_i^* = \begin{cases} exp(-\frac{(i-y_k)^2}{2\sigma_k^2}), & if \; i \in (y_k - \frac{w_k}{2}, y_k + \frac{w_k}{2}) \\ 0, & otherwise \end{cases} pi∗={exp(−2σk2(i−yk)2),0,ifi∈(yk−2wk,yk+2wk)otherwise
其中 σ k = w k 2 2 l n ( 10 ) \sigma_k = \sqrt{\frac{w_k^2}{2ln(10)}} σk=2ln(10)wk2
分割线回归
c i c_i ci 和 l i l_i li 分别代表行分割线的类别和位置, σ ^ \hat{\sigma} σ^ 为最优二分匹配的结果。
L l i n e r o w = ∑ i = 1 Q [ L c l s ( c i , c σ ( i ) ^ ∗ ) + 1 { c i ≠ ∅ } L r e g ( l i , l σ ^ ( i ) ∗ ) ] L_{line}^{row} = \sum_{i=1}^Q[L_{cls}(c_i, c_{\hat{\sigma_{(i)}}}^*) + \mathbf{1}_{\{c_i \neq \emptyset \}} L_{reg}(l_i, l_{\hat{\sigma}(i)} ^ *)] Llinerow=i=1∑Q[Lcls(ci,cσ(i)^∗)+1{ci=∅}Lreg(li,lσ^(i)∗)]
𝐿 𝑐 𝑙 𝑠 𝐿_{𝑐𝑙𝑠} Lcls is focal loss and 𝐿 𝑟 𝑒 𝑔 𝐿_{𝑟𝑒𝑔} Lreg is L1 loss
辅助分割
分割损失:像素二分类
L a u x r o w = 1 ∣ S r o w ∣ ∑ ( x , y ∈ S r o w B C E ( M r o w ( x , y ) , M r o w ∗ ( x , y ) ) L_{aux}^{row} = \frac{1}{|S_{row}|} \sum_{(x,y \in S_{row} } BCE(M_{row}(x, y), M_{row}^*(x, y)) Lauxrow=∣Srow∣1(x,y∈Srow∑BCE(Mrow(x,y),Mrow∗(x,y))
单元格合并
L m e r g e = 1 ∣ S r e l ∣ ∑ i ∈ S r e l B C E ( P i , P i ∗ ) L_{merge} = \frac{1}{|S_{rel}|} \sum_{i \in S_{rel}} BCE(P_i, P_i^*) Lmerge=∣Srel∣1i∈Srel∑BCE(Pi,Pi∗)
S r e l S_{rel} Srel 关系对的数量
效果

-
Chixiang Ma, Weihong Lin, Lei Sun, Qiang Huo:
Robust Table Detection and Structure Recognition from Heterogeneous Document Images. Pattern Recognit. 133: 109006 (2023) ↩︎ -
Ji Zhang, Mohamed Elhoseiny, Scott Cohen, Walter Chang, Ahmed M. Elgammal: Relationship Proposal Networks. CVPR 2017: 5226-5234 ↩︎
-
Hei Law, Jia Deng: CornerNet: Detecting Objects as Paired Keypoints. ECCV (14) 2018: 765-781 ↩︎

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)