mysql: 常用函数总结以及高级函数用法
rand() 随机select rand();
数值型函数
| 函数名称 | 作 用 |
|---|---|
| ABS | 求绝对值 |
| SQRT | 求二次方根 |
| MOD | 求余数 |
| CEIL 和 CEILING | 两个函数功能相同,都是返回不小于参数的最小整数,即向上取整 |
| FLOOR | 向下取整,返回值转化为一个BIGINT |
| RAND | 生成一个0~1之间的随机数,传入整数参数是,用来产生重复序列 |
| ROUND | 对所传参数进行四舍五入 |
| SIGN | 返回参数的符号 |
| POW 和 POWER | POW 和 POWER |
| SIN | 求正弦值 |
| ASIN | 求反正弦值,与函数 SIN 互为反函数 |
| COS | 求余弦值 |
| ACOS | 求反余弦值,与函数 COS 互为反函数 |
| TAN | 求正切值 |
| ATAN | 求反正切值,与函数 TAN 互为反函数 |
| COT | 求余切值 |
字符串函数
| 函数名称 | 作 用 |
|---|---|
| LENGTH | 计算字符串长度函数,返回字符串的字节长度 |
| CONCAT | 合并字符串函数,返回结果为连接参数产生的字符串,参数可以使一个或多个。如果有任何一个参数为null,则返回值为null |
| INSERT | 替换字符串函数 |
| LOWER/UPPER | 将字符串中的字母转换为 小写/大写 |
| LEFT | 从左侧字截取符串,返回字符串左边的若干个字符 |
| RIGHT | 从右侧字截取符串,返回字符串右边的若干个字符 |
| TRIM | 删除字符串左右两侧的空格 |
| REPLACE | 字符串替换函数,返回替换后的新字符串 |
| SUBSTRING | 截取字符串,返回从指定位置开始的指定长度的字符换 |
| REVERSE | 字符串反转(逆序)函数,返回与原始字符串顺序相反的字符串 |
日期和时间函数
| 函数名称 | 作 用 |
|---|---|
| CURDATE 和 CURRENT_DATE | 两个函数作用相同,返回当前系统的日期值 |
| CURTIME 和 CURRENT_TIME | 两个函数作用相同,返回当前系统的时间值 |
| NOW 和 SYSDATE | 两个函数作用相同,返回当前系统的日期和时间值 |
| UNIX_TIMESTAMP | 获取UNIX时间戳函数,返回一个以 UNIX 时间戳为基础的无符号整数 |
| FROM_UNIXTIME | 将 UNIX 时间戳转换为时间格式,与UNIX_TIMESTAMP互为反函数 |
| MONTH | 获取指定日期中的月份 |
| MONTHNAME | 获取指定日期中的月份英文名称 |
| DAYNAME | 获取指定曰期对应的星期几的英文名称 |
| DAYOFWEEK | 获取指定日期对应的一周的索引位置值 |
| WEEK | 获取指定日期是一年中的第几周,返回值的范围是否为 0〜52 或 1〜53 |
MySQL 字符串函数
| 函数 | 描述 | 实例 |
|---|---|---|
| ASCII(s) | 返回字符串 s 的第一个字符的 ASCII 码。 | 返回 CustomerName 字段第一个字母的 ASCII 码:SELECT ASCII(CustomerName) AS NumCodeOfFirstCharFROM Customers |
| CHAR_LENGTH(s) | 返回字符串 s 的字符数 | 返回字符串 RUNOOB 的字符数SELECT CHAR_LENGTH("RUNOOB") AS LengthOfString |
| CHARACTER_LENGTH(s) | 返回字符串 s 的字符数 | 返回字符串 RUNOOB 的字符数SELECT CHARACTER_LENGTH("RUNOOB") AS LengthOfString; |
| CONCAT( s1,s2…sn) | 合并多个字符串,需要注意,返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL | 合并多个字符串,,:SELECT CONCAT("SQL", "Tutorial", "is", "fun!")AS ConcatenatedString; |
| CONCAT_WS(x, s1,s2…sn) | 同 CONCAT(s1,s2,…) 函数,但是每个字符串之间要加上 x,x 可以是分隔符,需要注意的是分隔符不能为null,如果为null,则返回结果为null | 合并多个字符串,并添加分隔符,:SELECT CONCAT_WS("-", "SQL", "Tutorial", "is", "fun!")AS ConcatenatedString; |
| FIELD(s,s1,s2…) | 返回第一个字符串 s 在字符串列表(s1,s2…)中的位置:从1开始 | 返回字符串 c 在列表值中的位置:SELECT FIELD("c", "a", "b", "c", "d", "e"); |
| ELT(N,str1,str2,str3,…) | 返回对应位置的字符串。如果N = 1,则返回str1;如果N = 2,则返回str2,依此类推。 如果N小于1或大于参数个数,则返回NULL。 ELT是FIELD的补充。 | SELECT ELT(1, 'ej', 'Heja', 'hej', 'foo'); |
| FIND_IN_SET(s1,s2) | 返回在字符串s2中与s1匹配的字符串的位置:从1开始 | 返回字符串 c 在指定字符串中的位置:SELECT FIND_IN_SET("c", "a,b,c,d,e"); |
| FORMAT(x,n) | 函数可以将数字 x 进行格式化 “#,###.##”, 将 x 保留到小数点后 n 位,最后一位四舍五入。 | 格式化数字 “#,###.##” 形式:SELECT FORMAT(250500.5634, 2); -- 输出 250,500.56 |
| INSERT(s1,x,len,s2) | 字符串 s2 替换 s1 的 x 位置开始长度为 len 的字符串 | 从字符串第一个位置开始的 6 个字符替换为 runoob:SELECT INSERT("google.com", 1, 6, "runoob"); -- 输出:runoob.com |
| LOCATE(s1,s) | 从字符串 s 中获取 s1 的开始位置 | 获取 b 在字符串 abc 中的位置:SELECT LOCATE('st','myteststring'); -- 5 |
| LCASE(s) | 将字符串 s 的所有字母变成小写字母 | 字符串 RUNOOB 转换为小写:SELECT LCASE('RUNOOB') -- runoob |
| LOWER(s) | 将字符串 s 的所有字母变成小写字母 | 字符串 RUNOOB 转换为小写SELECT LOWER('RUNOOB') -- runoob |
| UCASE(s) | 将字符串转换为大写 | 将字符串 runoob 转换为大写:SELECT UCASE("runoob"); -- RUNOOB |
| UPPER(s) | 将字符串转换为大写 | 将字符串 runoob 转换为大写:SELECT UPPER("runoob"); -- RUNOOB |
| LEFT(s,n) | 返回字符串 s 的前 n 个字符 | 返回字符串 runoob 中的前两个字符:SELECT LEFT('runoob',2) -- ru |
| RIGHT(s,n) | 返回字符串 s 的后 n 个字符 | 返回字符串 runoob 的后两个字符:SELECT RIGHT('runoob',2) -- ob |
| LPAD(s1,len,s2) | 在字符串 s1 的开始处填充字符串 s2,使字符串长度达到 len | 将字符串 xx 填充到 abc 字符串的开始处:SELECT LPAD('abc',5,'xx') -- xxabc |
| RPAD(s1,len,s2) | 在字符串 s1 的结尾处添加字符串 s2,使字符串的长度达到 len | 将字符串 xx 填充到 abc 字符串的结尾处:SELECT RPAD('abc',5,'xx') -- abcxx |
| TRIM(s) | 去掉字符串 s 开始和结尾处的空格 | 去掉字符串 RUNOOB 的首尾空格:SELECT TRIM(' RUNOOB ') AS TrimmedString; |
| LTRIM(s) | 去掉字符串 s 左侧的空格 | 去掉字符串 RUNOOB开始处的空格:SELECT LTRIM(" RUNOOB") AS LeftTrimmedString;-- RUNOOB |
| RTRIM(s) | 去掉字符串 s 结尾处的空格 | 去掉字符串 RUNOOB 的末尾空格:·SELECT RTRIM("RUNOOB ") AS RightTrimmedString; – RUNOOB· |
| MID(s,n,len) | 从字符串 s 的 n 位置截取长度为 len 的子字符串,同 SUBSTRING(s,n,len) | 从字符串 RUNOOB 中的第 2 个位置截取 3个 字符SELECT MID("RUNOOB", 2, 3) AS ExtractString; -- UNO |
| POSITION(s1 IN s) | 从字符串 s 中获取 s1 的开始位置 | 返回字符串 abc 中 b 的位置:SELECT POSITION('b' in 'abc') -- 2 |
| REPEAT(s,n) | 将字符串 s 重复 n 次 | 将字符串 runoob 重复三次:SELECT REPEAT('runoob',3) -- runoobrunoobrunoob |
| REPLACE(s,s1,s2) | 将字符串 s2 替代字符串 s 中的字符串 s1 | 将字符串 abc 中的字符 a 替换为字符 x:SELECT REPLACE('abc','a','x') --xbc |
| REVERSE(s) | 将字符串s的顺序反过来 | 将字符串 abc 的顺序反过来:SELECT REVERSE('abc') -- cba |
| SPACE(n) | 返回 n 个空格 | 返回 10 个空格:SELECT SPACE(10); |
| STRCMP(s1,s2) | 比较字符串 s1 和 s2,如果 s1 与 s2 相等返回 0 ,如果 s1>s2 返回 1,如果 s1<s2 返回 -1 | 比较字符串:SELECT STRCMP("runoob", "runoob"); -- 0 |
| SUBSTR(s, start, length) | 从字符串 s 的 start 位置截取长度为 length 的子字符串 | 从字符串 RUNOOB 中的第 2 个位置截取 3个 字符 SELECT SUBSTR("RUNOOB", 2, 3) AS ExtractString; -- UNO |
| SUBSTRING(s, start, length) | 从字符串 s 的 start 位置截取长度为 length 的子字符串 | 从字符串 RUNOOB 中的第 2 个位置截取 3个 字符:SELECT SUBSTRING("RUNOOB", 2, 3) AS ExtractString; -- UNO |
| SUBSTRING_INDEX(s, delimiter, number) | 返回从字符串 s 的第 number 个出现的分隔符 delimiter 之后的子串。如果 number 是正数,返回第 number 个字符左边的字符串。如果 number 是负数,返回第(number 的绝对值(从右边数))个字符右边的字符串。 | SELECT SUBSTRING_INDEX('a*b','*',1) -- a SELECT SUBSTRING_INDEX('a*b','*',-1) -- b SELECT SUBSTRING_INDEX(SUBSTRING_INDEX('a*b*c*d*e','*',3),'*',-1) -- c |
MySQL 数字函数
| 函数名 | 描述 | 实例 |
|---|---|---|
| ABS(x) | 返回 x 的绝对值 | 返回 -1 的绝对值:SELECT ABS(-1) -- 返回1 |
| ACOS(x) | 求 x 的反余弦值(参数是弧度) | SELECT ACOS(0.25); |
| ASIN(x) | 求反正弦值(参数是弧度) | SELECT ASIN(0.25); |
| ATAN(x) | 求反正切值(参数是弧度) | SELECT ATAN(2.5); |
| ATAN2(n, m) | 求反正切值(参数是弧度) | SELECT ATAN2(-0.8, 2); |
| AVG(expression) | 返回一个表达式的平均值,expression 是一个字段 | 返回 Products 表中Price 字段的平均值SELECT AVG(Price) AS AveragePrice FROM Products; |
| CEIL(x) | 返回大于或等于 x 的最小整数 | SELECT CEIL(1.5) -- 返回2 |
| CEILING(x) | 返回大于或等于 x 的最小整数 | SELECT CEILING(1.5); -- 返回2 |
| FLOOR(x) | 返回小于或等于 x 的最大整数 | 小于或等于 1.5 的整数:SELECT FLOOR(1.5) -- 返回1 |
| COS(x) | 求余弦值(参数是弧度) | SELECT COS(2); |
| COT(x) | 求余切值(参数是弧度) | SELECT COT(6); |
| COUNT(expression) | 返回查询的记录总数,expression 参数是一个字段或者 * 号 | 返回 Products 表中 products 字段总共有多少条记录:SELECT COUNT(ProductID) AS NumberOfProducts FROM Products; |
| DEGREES(x) | 将弧度转换为角度 | SELECT DEGREES(3.1415926535898) -- 180 |
| n DIV m | 整除,n 为被除数,m 为除数 | 计算 10 除于 5:SELECT 10 DIV 5; -- 2 |
| EXP(x) | 返回 e 的 x 次方 | 计算 e 的三次方SELECT EXP(3) -- 20.085536923188 |
| GREATEST(expr1, expr2, expr3, …) | 返回列表中的最大值 | 返回以下数字列表中的最大值:SELECT GREATEST(3, 12, 34, 8, 25); -- 34返回以下字符串列表中的最大值:SELECT GREATEST("Google", "Runoob", "Apple"); -- Runoob |
| LEAST(expr1, expr2, expr3, …) | 返回列表中的最小值 | 返回以下数字列表中的最小值:SELECT LEAST(3, 12, 34, 8, 25); -- 3返回以下字符串列表中的最小值:SELECT LEAST("Google", "Runoob", "Apple"); -- Apple |
| LN | 返回数字的自然对数,以 e 为底。 | 返回 2 的自然对数:SELECT LN(2); -- 0.6931471805599453 |
| LOG(x) 或 LOG(base, x) | 返回自然对数(以 e 为底的对数),如果带有 base 参数,则 base 为指定带底数。 | SELECT LOG(20.085536923188) -- 3SELECT LOG(2, 4); -- 2 |
| LOG10(x) | 返回以 10 为底的对数 | SELECT LOG10(100) -- 2 |
| LOG2(x) | 返回以 2 为底的对数 | 返回以 2 为底 6 的对数:SELECT LOG2(6); -- 2.584962500721156 |
| MAX(expression) | 返回字段 expression 中的最大值 | 返回数据表 Products 中字段 Price 的最大值SELECT MAX(Price) AS LargestPrice FROM Products; |
| MIN(expression) | 返回字段 expression 中的最小值 | 返回数据表 Products 中字段 Price 的最小值SELECT MIN(Price) AS MinPrice FROM Products; |
| MOD(x,y) | 返回 x 除以 y 以后的余数 | 5 除于 2 的余数:SELECT MOD(5,2) -- 1 |
| PI() | 返回圆周率(3.141593) | SELECT PI() --3.141593 |
| POW(x,y) | 返回 x 的 y 次方 | 2 的 3 次方:SELECT POW(2,3) -- 8 |
| POWER(x,y) | 返回 x 的 y 次方 | 2 的 3 次方:SELECT POWER(2,3) -- 8 |
| RADIANS(x) | 将角度转换为弧度 | 180 度转换为弧度:SELECT RADIANS(180) -- 3.1415926535898 |
| RAND() | 返回 0 到 1 的随机数 | SELECT RAND() --0.93099315644334 |
| ROUND(x,y) | 返回离 y位数 最近的整数(四舍五入) | SELECT ROUND(1.23456) --1 |
| TRUNCATE(x,y) | 返回数值 x 保留到小数点后 y 位的值(与 ROUND 最大的区别是不会进行四舍五入) | SELECT TRUNCATE(1.23456,3) -- 1.234 |
| SIGN(x) | 返回 x 的符号,x 是负数、0、正数分别返回 -1、0 和 1 | SELECT SIGN(-10) -- (-1) |
| SIN(x) | 求正弦值(参数是弧度) | SELECT SIN(RADIANS(30)) -- 0.5 |
| SQRT(x) | 返回x的平方根 | 25 的平方根:SELECT SQRT(25) -- 5 |
| SUM(expression) | 返回指定字段的总和 | 计算 OrderDetails 表中字段 Quantity 的总和:SELECT SUM(Quantity) AS TotalItemsOrdered FROM OrderDetails; |
| TAN(x) | 求正切值(参数是弧度) | SELECT TAN(1.75); -- -5.52037992250933 |
MySQL 日期函数
| 函数名 | 描述 | 实例 |
|---|---|---|
| ADDDATE(d,n) | 计算起始日期 d 加上 n 天的日期 | SELECT ADDDATE("2017-06-15", INTERVAL 10 DAY);->2017-06-25 SELECT ADDDATE("2017-06-15", 10) |
| ADDTIME(t,n) | n 是一个时间表达式,时间 t 加上时间表达式 n | 加 5 秒:SELECT ADDTIME('2011-11-11 11:11:11', 5);->2011-11-11 11:11:16 (秒) 添加 2 小时, 10 分钟, 5 秒:SELECT ADDTIME("2020-06-15 09:34:21", "2:10:5"); -> 2020-06-15 11:44:26 |
| CURDATE() | 返回当前日期 | SELECT CURDATE();-> 2018-09-19 |
| CURRENT_DATE() | 返回当前日期 | SELECT CURRENT_DATE();-> 2018-09-19 |
| CURRENT_TIME | 返回当前时间 | SELECT CURRENT_TIME();-> 19:59:02 |
| CURRENT_TIMESTAMP() | 返回当前日期和时间 | SELECT CURRENT_TIMESTAMP()-> 2018-09-19 20:57:43 |
| CURTIME() | 返回当前时间 | SELECT CURTIME();-> 19:59:02 |
| DATE() | 从日期或日期时间表达式中提取日期值 | SELECT DATE("2017-06-15"); -> 2017-06-15 |
| DATEDIFF(d1,d2) | 计算日期 d1->d2 之间相隔的天数 | SELECT DATEDIFF('2001-01-01','2001-02-02')-> -32 |
| DATE_ADD(d,INTERVAL expr type) | 计算起始日期 d 加上一个时间段后的日期,type 值可以是:https://www.runoob.com/mysql/mysql-functions.html | SELECT DATE_ADD("2017-06-15", INTERVAL 10 DAY); |
| DATE_FORMAT(d,f) | 按表达式 f的要求显示日期 d | `SELECT DATE_FORMAT(‘2011-11-11 11:11:11’,‘%Y-%m-%d %r’)-> |
| DATE_SUB(date,INTERVAL expr type) | 函数从日期减去指定的时间间隔。 | Orders 表中 OrderDate 字段减去 2 天:SELECT OrderId,DATE_SUB(OrderDate,INTERVAL 2 DAY) AS OrderPayDateFROM Orders |
| DAY(d) | 返回日期值 d 的日期部分 | SELECT DAY("2017-06-15"); -> 15 |
| DAYNAME(d) | 返回日期 d 是星期几,如 Monday,Tuesday | SELECT DAYNAME('2011-11-11 11:11:11')->Friday |
| DAYOFMONTH(d) | 计算日期 d 是本月的第几天 | SELECT DAYOFMONTH('2011-11-11 11:11:11')->11 |
| DAYOFWEEK(d) | 日期 d 今天是星期几,1 星期日,2 星期一,以此类推 | SELECT DAYOFWEEK('2011-11-11 11:11:11')->6 |
| DAYOFYEAR(d) | 计算日期 d 是本年的第几天 | SELECT DAYOFYEAR('2011-11-11 11:11:11')->315 |
| EXTRACT(type FROM d) | 从日期 d 中获取指定的值,type 指定返回的值。type可取值为:https://www.runoob.com/mysql/mysql-functions.html | SELECT EXTRACT(MINUTE FROM '2011-11-11 11:11:11') -> 11 |
| FROM_DAYS(n) | 计算从 0000 年 1 月 1 日开始 n 天后的日期 | SELECT FROM_DAYS(1111) -> 0003-01-16 |
| HOUR(t) | 返回 t 中的小时值 | SELECT HOUR('1:2:3')-> 1 |
| LAST_DAY(d) | 返回给给定日期的那一月份的最后一天 | SELECT LAST_DAY("2017-06-20");-> 2017-06-30 |
| LOCALTIME() | 返回当前日期和时间 | SELECT LOCALTIME()-> 2018-09-19 20:57:43 |
| LOCALTIMESTAMP() | 返回当前日期和时间 | SELECT LOCALTIMESTAMP()-> 2018-09-19 20:57:43 |
| MAKEDATE(year, day-of-year | 基于给定参数年份 year 和所在年中的天数序号 day-of-year 返回一个日期 | SELECT MAKEDATE(2017, 3);-> 2017-01-03 |
| MAKETIME(hour, minute, second) | 组合时间,参数分别为小时、分钟、秒 | SELECT MAKETIME(11, 35, 4);-> 11:35:04 |
| MICROSECOND(date) | 返回日期参数所对应的微秒数 | SELECT MICROSECOND("2017-06-20 09:34:00.000023");-> 23 |
| MINUTE(t) | 返回 t 中的分钟值 | SELECT MINUTE('1:2:3')-> 2 |
| MONTHNAME(d) | 返回日期当中的月份名称,如 November | SELECT MONTHNAME('2011-11-11 11:11:11')-> November |
| MONTH(d) | 返回日期d中的月份值,1 到 12 | SELECT MONTH('2011-11-11 11:11:11')->11 |
| NOW() | 返回当前日期和时间 | SELECT NOW()-> 2018-09-19 20:57:43 |
| PERIOD_ADD(period, number) | 为 年-月 组合日期添加一个时段 | SELECT PERIOD_ADD(201703, 5); -> 201708 |
| PERIOD_DIFF(period1, period2) | 返回两个时段之间的月份差值 | SELECT PERIOD_DIFF(201710, 201703);-> 7 |
| QUARTER(d) | 返回日期d是第几季节,返回 1 到 4 | SELECT QUARTER('2011-11-11 11:11:11')-> 4 |
| SECOND(t) | 返回 t 中的秒钟值 | SELECT SECOND('1:2:3')-> 3 |
| SEC_TO_TIME(s) | 将以秒为单位的时间 s 转换为时分秒的格式 | SELECT SEC_TO_TIME(4320)-> 01:12:00 |
| STR_TO_DATE(string, format_mask) | 将字符串转变为日期 | SELECT STR_TO_DATE("August 10 2017", "%M %d %Y");-> 2017-08-10 |
| SUBDATE(d,n) | 日期 d 减去 n 天后的日期 | SELECT SUBDATE('2011-11-11 11:11:11', 1)->2011-11-10 11:11:11 (默认是天) |
| SUBTIME(t,n) | 时间 t 减去 n 秒的时间 | SELECT SUBTIME('2011-11-11 11:11:11', 5)->2011-11-11 11:11:06 (秒) |
| SYSDATE() | 返回当前日期和时间 | SELECT SYSDATE()-> 2018-09-19 20:57:43 |
| TIME(expression) | 提取传入表达式的时间部分 | SELECT TIME("19:30:10");-> 19:30:10 |
| TIME_FORMAT(t,f) | 按表达式 f 的要求显示时间 t | SELECT TIME_FORMAT('11:11:11','%r')11:11:11 AM |
| TIME_TO_SEC(t) | 将时间 t 转换为秒 | SELECT TIME_TO_SEC('1:12:00')-> 4320 |
| TIMEDIFF(time1, time2) | 计算时间差值 | SELECT TIMEDIFF("13:10:11", "13:10:10");-> 00:00:01 |
| TIMESTAMP(expression, interval) | 单个参数时,函数返回日期或日期时间表达式;有2个参数时,将参数加和 | SELECT TIMESTAMP("2017-07-23", "13:10:11");-> 2017-07-23 13:10:11 |
| TO_DAYS(d) | 计算日期 d 距离 0000 年 1 月 1 日的天数 | SELECT TO_DAYS('0001-01-01 01:01:01')-> 366 |
| WEEK(d) | 计算日期 d 是本年的第几个星期,范围是 0 到 53 | SELECT WEEK('2011-11-11 11:11:11')-> 45 |
| WEEKDAY(d) | 日期 d 是星期几,0 表示星期一,1 表示星期二 | SELECT WEEKDAY("2017-06-15");-> 3 |
| WEEKOFYEAR(d) | 算日期 d 是本年的第几个星期,范围是 0 到 53 | SELECT WEEKOFYEAR('2011-11-11 11:11:11')-> 45 |
| YEAR(d) | 返回年份 | SELECT YEAR("2017-06-15");-> 2017 |
| YEARWEEK(date, mode) | 返回年份及第几周(0到53),mode 中 0 表示周天,1表示周一,以此类推 | SELECT YEARWEEK("2017-06-15");-> 201724 |
| TIMESTAMPDIFF | 计算两个日期相差的天数、月数、年数 | SELECT TIMESTAMPDIFF(类型,开始时间,结束时间) |

MySQL自带的日期函数TIMESTAMPDIFF计算两个日期相差的秒数、分钟数、小时数、天数、周数、季度数、月数、年数,当前日期增加或者减少一天、一周等等。
SELECT TIMESTAMPDIFF(类型,开始时间,结束时间)
相差的秒数:
SELECT TIMESTAMPDIFF(SECOND,'1993-03-23 00:00:00',DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%S'))
相差的分钟数:
SELECT TIMESTAMPDIFF(MINUTE,'1993-03-23 00:00:00',DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%S'))
相差的小时数:
SELECT TIMESTAMPDIFF(HOUR,'1993-03-23 00:00:00 00:00:00',DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%S'))
相差的天数:
SELECT TIMESTAMPDIFF(DAY,'1993-03-23 00:00:00',DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%S'))
相差的周数:
SELECT TIMESTAMPDIFF(WEEK,'1993-03-23 00:00:00',DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%S'))
相差的季度数:
SELECT TIMESTAMPDIFF(QUARTER,'1993-03-23 00:00:00',DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%S'))
相差的月数:
SELECT TIMESTAMPDIFF(MONTH,'1993-03-23 00:00:00',DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%S'))
相差的年数:
SELECT TIMESTAMPDIFF(YEAR,'1993-03-23 00:00:00',DATE_FORMAT(NOW(), '%Y-%m-%d %H:%i:%S'))
获取当前日期:
SELECT NOW()
SELECT CURDATE()
当前日期增加一天:
SELECT DATE_SUB(CURDATE(),INTERVAL -1 DAY)
当前日期减少一天:
SELECT DATE_SUB(CURDATE(),INTERVAL 1 DAY)
当前日期增加一周:
SELECT DATE_SUB(CURDATE(),INTERVAL -1 WEEK)
当前日期增加一月:
SELECT DATE_SUB(CURDATE(),INTERVAL -1 MONTH)
SELECT DATE_SUB(NOW(),INTERVAL -1 MONTH)
FRAC_SECOND 毫秒
SECOND 秒
MINUTE 分钟
HOUR 小时
DAY 天
WEEK 星期
MONTH 月
QUARTER 季度
YEAR 年
MySQL 高级函数
| 函数名 | 描述 | 实例 |
|---|---|---|
| BIN(x) | 返回 x 的二进制编码 | 15 的 2 进制编码:SELECT BIN(15); -- 1111 |
| BINARY(s) | 将字符串 s 转换为二进制字符串 | SELECT BINARY "RUNOOB";-> RUNOOB |
| CASE when THEN else end | CASE 表示函数开始,END 表示函数结束。如果 condition1 成立,则返回 result1, 如果 condition2 成立,则返回 result2,当全部不成立则返回 result,而当有一个成立之后,后面的就不执行了。 | SELECT CASE WHEN 1 > 0 THEN '1 > 0' WHEN 2 > 0 THEN '2 > 0' ELSE '3 > 0' END->1 > 0 |
| CAST(x AS type) | 转换数据类型 | 字符串日期转换为日期:SELECT CAST("2017-08-29" AS DATE);-> 2017-08-29 字符串转换为数字SELECT CAST("2" AS signed); |
| COALESCE(expr1, expr2, …, expr_n) | 返回参数中的第一个非空表达式(从左向右) | SELECT COALESCE(NULL, NULL, NULL, 'runoob.com', NULL, 'google.com');-> runoob.com |
| CONNECTION_ID() | 返回唯一的连接 ID | SELECT CONNECTION_ID();-> 4292835 |
| CONV(x,f1,f2) | 返回 f1 进制数变成 f2 进制数 | SELECT CONV(15, 10, 2);-> 1111 |
| CONVERT(s USING cs) | 函数将字符串 s 的字符集变成 cs | SELECT CHARSET('ABC') ->utf-8 SELECT CHARSET(CONVERT('ABC' USING gbk))->gbk |
| CURRENT_USER() | 返回当前用户 | SELECT CURRENT_USER();-> guest@% |
| DATABASE() | 返回当前数据库名 | SELECT DATABASE(); -> runoob |
| IF(expr,v1,v2) | 如果表达式 expr 成立,返回结果 v1;否则,返回结果 v2。 | SELECT IF(1 > 0,'正确','错误') ->正确 |
| IFNULL(v1,v2) | 如果 v1 的值不为 NULL,则返回 v1,否则返回 v2。 | SELECT IFNULL(null,'Hello Word')->Hello Word |
| ISNULL(expression) | 判断表达式是否为 NULL | SELECT ISNULL(NULL);->1 |
| LAST_INSERT_ID() | 返回最近生成的 AUTO_INCREMENT 值 | SELECT LAST_INSERT_ID();->6 |
| NULLIF(expr1, expr2) | 比较两个字符串,如果字符串 expr1 与 expr2 相等 返回 NULL,否则返回 expr1 | SELECT NULLIF(25, 25);-> |
| SESSION_USER() | 返回当前用户 | SELECT SESSION_USER();-> guest@% |
| SYSTEM_USER() | 返回当前用户 | SELECT SYSTEM_USER();-> guest@% |
| USER() | 返回当前用户 | SELECT USER();-> guest@% |
| VERSION() | 返回数据库的版本号 | SELECT VERSION()-> 5.7.30-log |
项目中学习到的新函数用法
group_concat()
1、功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
2、语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator ‘分隔符’] )
说明:通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。
MySql数据库查询时,使用group_concat报错“Row XXX was cut by GROUP_CONCAT()”,单独查询不会报错,当我要查询的数据更新到另外个表中的字段时,会报这个错,网上查了下是因为GROUP_CONCAT有个最大长度的限制,超过最大长度就会被截断掉,可以通过
show variables like "group_concat_max_len";
-- SET GLOBAL group_concat_max_len=102400;
-- SET group_concat_max_len=102400;
select GROUP_CONCAT(DISTINCT data_code order by data_code desc separator '_') from sip_dic_info c where c.data_type = 'BC_02';

类型转换cast 或者convert
SELECT CAST("2017-08-29" AS DATE);
SELECT CAST("2" AS signed);
select CONVERT('12332',signed); // 有多个重载函数

binary:二进制类型;
char:字符类型;
date:日期类型;
time:时间类型;
datetime:日期时间类型;
decimal:浮点型;
signed:整型;
unsigned:无符号整型。
批量插入之replace语句/insert into… on duplicate key update语句
-
replace into 表名l (id,字段1) values (1,‘2’),(2,‘3’),…(x,‘y’);
-
insert into 表名 values(列值1,列值2,列值3…) on duplicate key update 列名1=值/values(列名1),列名2=列值/valules(列名2)…
用法总结
1:on duplicate key update 语句根据主键id或唯一键来判断当前插入是否已存在。
2:记录已存在时,只会更新on duplicate key update之后指定的字段。
3:如果同时传递了主键和唯一键,以主键为判断存在依据,唯一键字段内容可以被修改。
4:唯一键大小写敏感时,大小写不同的值被认为是两个值,执行插入。参见下文中的大小写敏感问题
参考链接
二者
结论:
1:唯一性索引冲突时,两种方式都会增加数据表AUTO_INCREMENT的值。
2:replace遇到主键/唯一索引冲突是先删除再插入,无冲突直接进行insert。
总结从上面的测试结果看出,相同之处:
(1),没有key的时候,replace与insert … on deplicate key udpate相同。
(2),有key的时候,都保留主键值,并且auto_increment自动+1
不同之处:有key的时候,replace是delete老记录,而录入新的记录,所以原有的所有记录会被清除,这个时候,如果replace语句的字段不全的话,有些原有的比如例子中c字段的值会被自动填充为默认值。
注意事项:
ON DUPLICATE KEY 如果a=1 OR b=2与多个行向匹配,则只有一个行被更新。通常,您应该尽量避免对带有多个唯一关键字的表使用ON DUPLICATE KEY子句。
REPLACE可能影响3条以上的记录,这是因为在表中有超过一个的唯一索引。在这种情况下,REPLACE将考虑每一个唯一索引,并对每一个索引对应的重复记录都删除,然后插入这条新记录。假设有一个table1表,有3个字段a, b, c。它们都有一个唯一索引。
您可以在UPDATE子句中使用VALUES(col_name)函数从INSERT…UPDATE语句的INSERT部分引用列值。换句话说,如果没有发生重复关键字冲突,则UPDATE子句中的VALUES(col_name)可以引用被插入的col_name的值。本函数特别适用于多行插入。VALUES()函数只在INSERT…UPDATE语句中有意义,其它时候会返回NULL。
INSERT INTO table (a,b,c) VALUES (1,2,3),(4,5,6) ON DUPLICATE KEY UPDATE c=VALUES(a)+VALUES(b);
参考博客 https://blog.csdn.net/taoy86/article/details/89322202
values() 可以替换下面{ expression | DEFAULT }
openGauss 的语法是 ON DUPLICATE KEY UPDATE {column_name = { expression | DEFAULT} } [, …]。
PostgreSQL 的语法是 ON CONFLICT [ conflict_target ] DO UPDATE SET { column_name = { expression | DEFAULT } }。
ELT - 返回对应位置的字符串。
ELT(N,str1,str2,str3,…)
select convert(elt(floor(10*rand())+1,'11','13','17','19','21','23','29','31','37','41'),decimal(8,2));
select elt(floor(2*rand())+1,'02','03')
concat_ws
concat_ws('-',IF(ISNULL(p.begin_road_segment_name),'',p.begin_road_segment_name),IF(ISNULL(p.end_road_segment_name),'',p.end_road_segment_name)) roadSegmentName
substring_index函数的语法及其用法
1)语法:substring_index(string,sep,num)即substring_index(字符串,分隔符,序号)
参数说明
string:用于截取目标字符串的字符串。可为字段,表达式等。
sep:分隔符,string存在且用于分割的字符,比如“,”、“.”等。
num:序号,为非0整数。若为整数则表示从左到右数,若为负数则从右到左数。比如“www.mysql.com”截取字符‘www’,分割符为“.”,从左到右序号为1,即substring_index(“www.mysql.com”,‘.’,1);若从右开始获取“com”则为序号为-1即substring_index(“www.mysql.com”,‘.’,-1)
2)用于截取目标字符串。
例:现有一个学生信息表student,详细地址address储存省、市、县等由逗号隔开的地址信息,比如“XX省,XX市,XX区,…,XXX号”。由于某种原因没有学生所在省信息需要获取,同时获取学生姓名name,性别sex,年龄age。
select name,sex,age,substring_index(address,',',1) as province
from student
建议索引
select count(distinct status)/count(*) ,count(distinct prodict_id)/couont(1) from product;
哪个字段更接近1就更适合放在组合索引前面
如果索引没有命中会行锁会会变成表锁
索引命中就是行锁
innodb存储引擎B+树索引可分为聚集索引和非聚集索引(辅助索引或者耳机索引)
这两种索引内部都是B+树,聚集索引的叶子节点存放一整行数据
其中主键索引是一种聚集索引,非聚集索引都是辅助索引,如复合索引,前缀索引,唯一索引
聚集索引就是按照每张表主键构建一颗B+树,同时叶子节点存放整个表行记录数据,也将聚集索引的叶子节点称为数据项,这个特性决定了索引组织中数据也是索引的一部分
InnoDB的行锁是通过锁住索引来实现,没有没有使用到索引,会将整个聚集索引都锁柱,相当于缩表
回表
通过辅助索引(二级索引)拿到主键后再回到主键索引查询的过程就叫做回表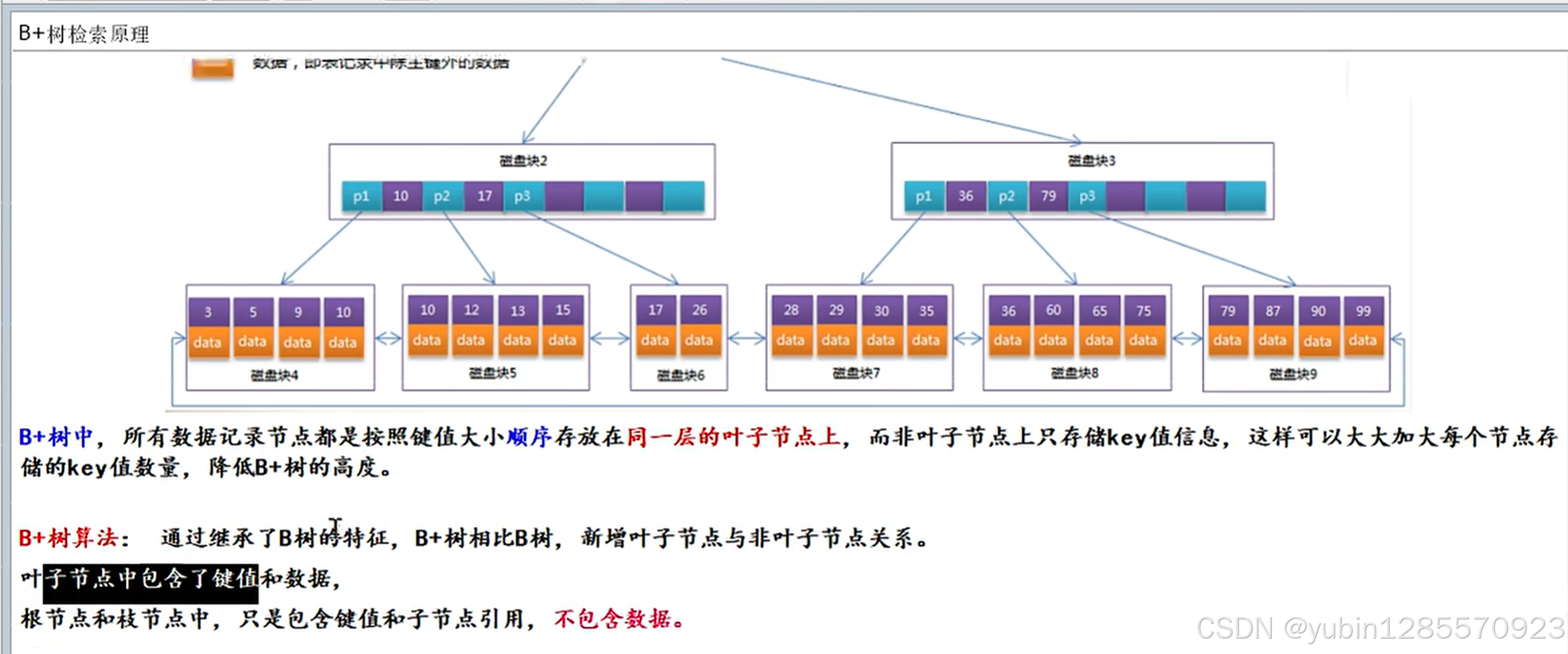
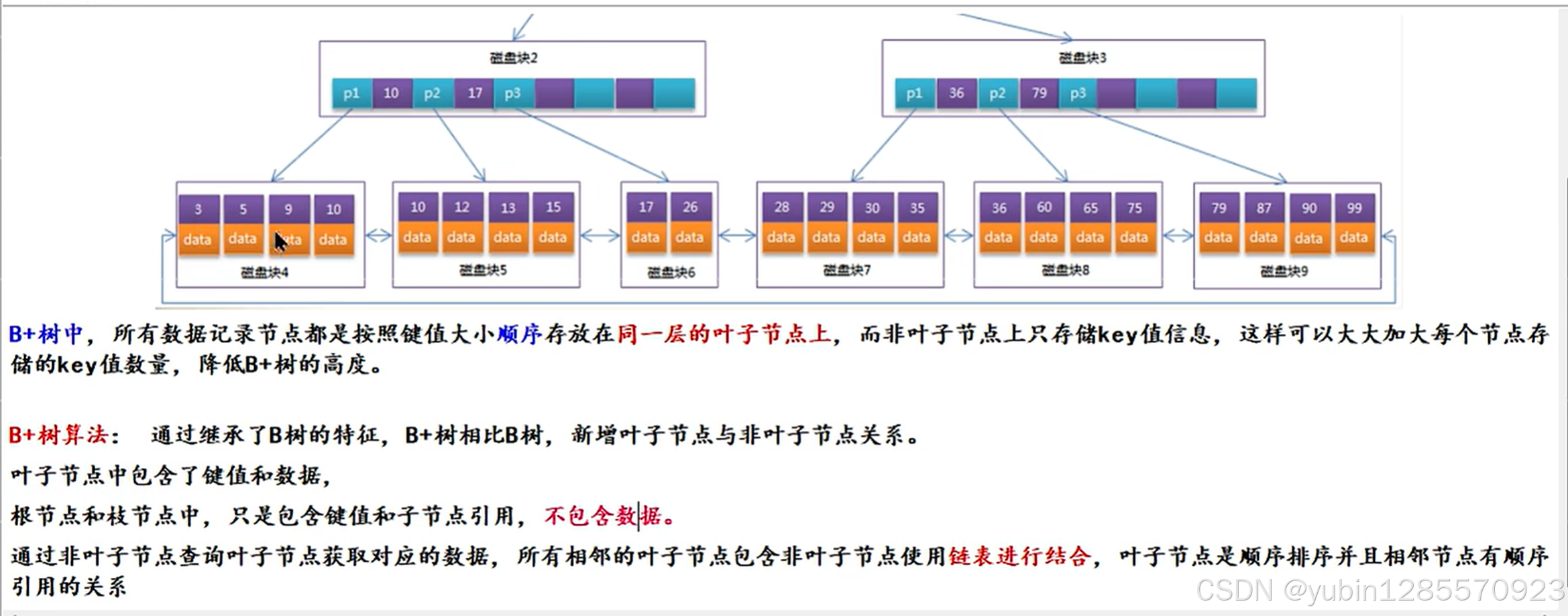
千万数据分页优化
利用延迟关联或者子查询优化超多分页场景
mysql并不是跳过offset行,而是取offset+n行,然后返回放弃前offset行,返回n行,当offset特别大的时候,效率就非常低,要不控制返回的总页数,要不对超过特定阈值也进行sql改写
正解:先快速定位需要获取的id然后再 关联
select t1.* from 表1 as t1 ,(select id from 表1 where 条件 limit 10000 ,20)as t2 where t1.id = t2.id;
1方案一
先找到索引树中开始位子的id,再根据id进行查找行数据
select a.empno,a.ename,a.job,a.sal,b.deptno,b.dname from emp a join dept b on a.deptno= b.deptno where a.id >=(
select id from emp order by id limit 4999999,1
) order by a.id limit 30;
方案二:避免使用偏移量offset ,可以外部传进入
select a.empno,a.ename,a.job,a.sal,b.deptno,b.dname from emp a join dept b on a.deptno= b.deptno where a.id >4999999 order by a.id limit 30;
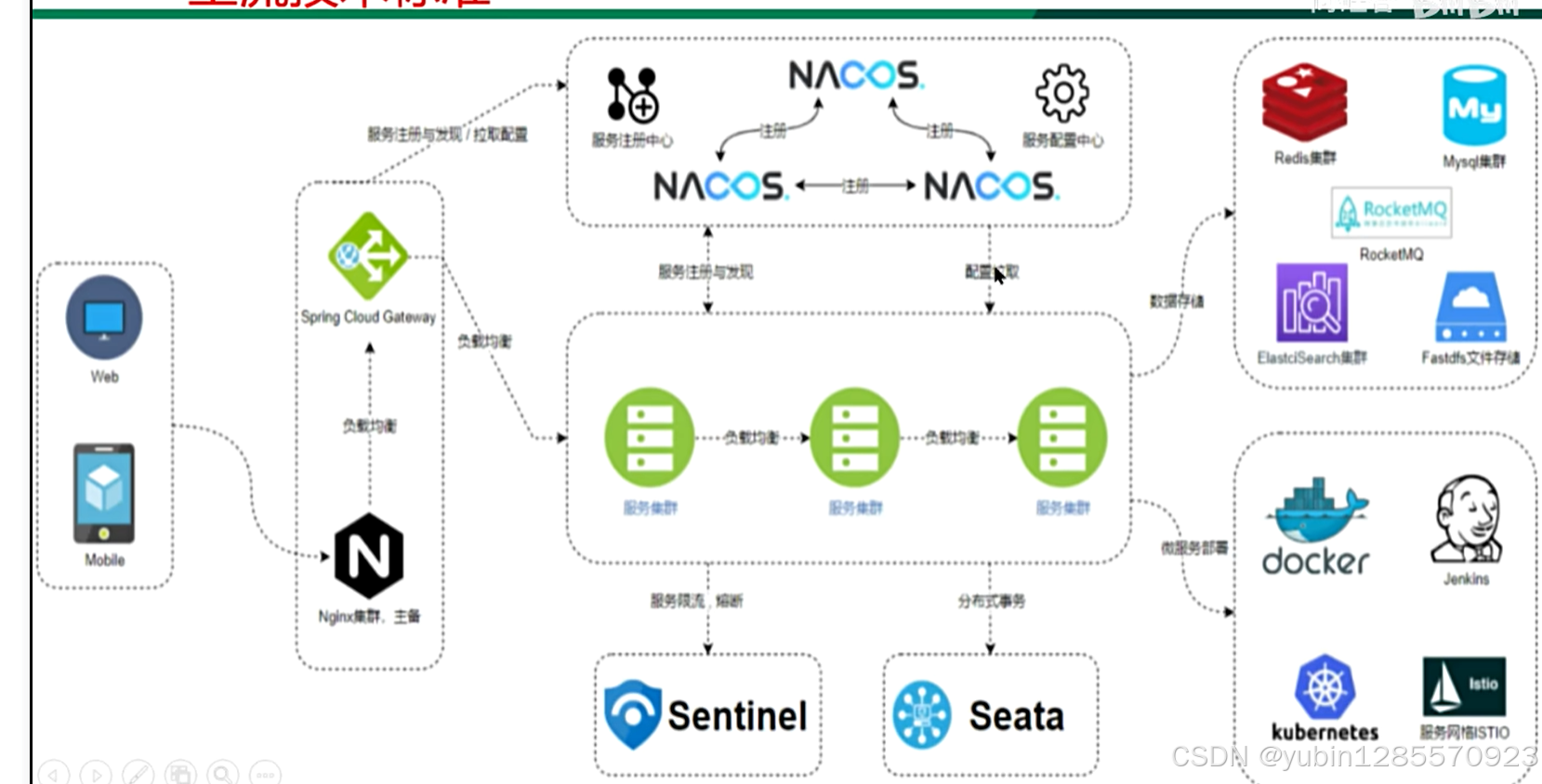
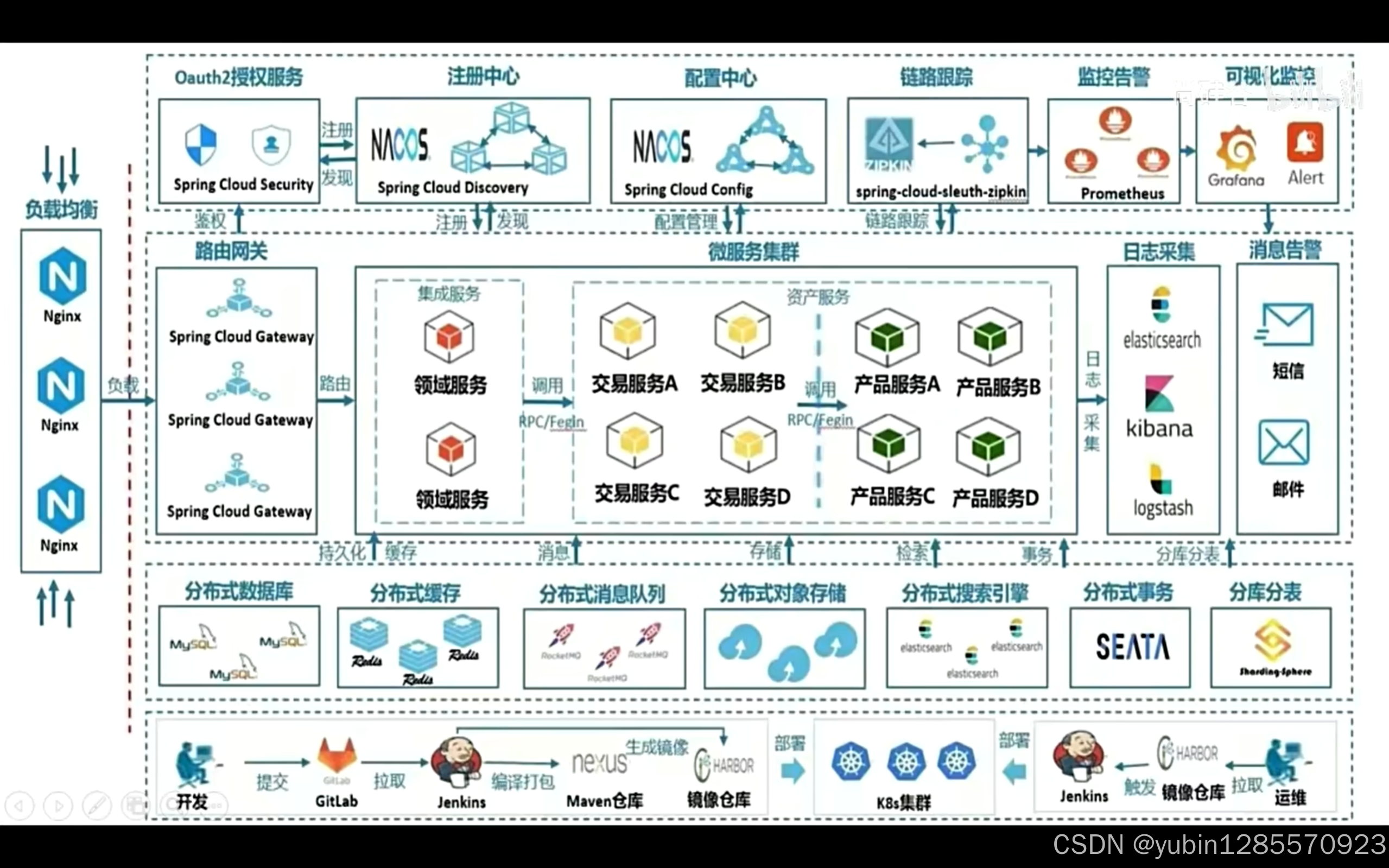
项目架构

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)